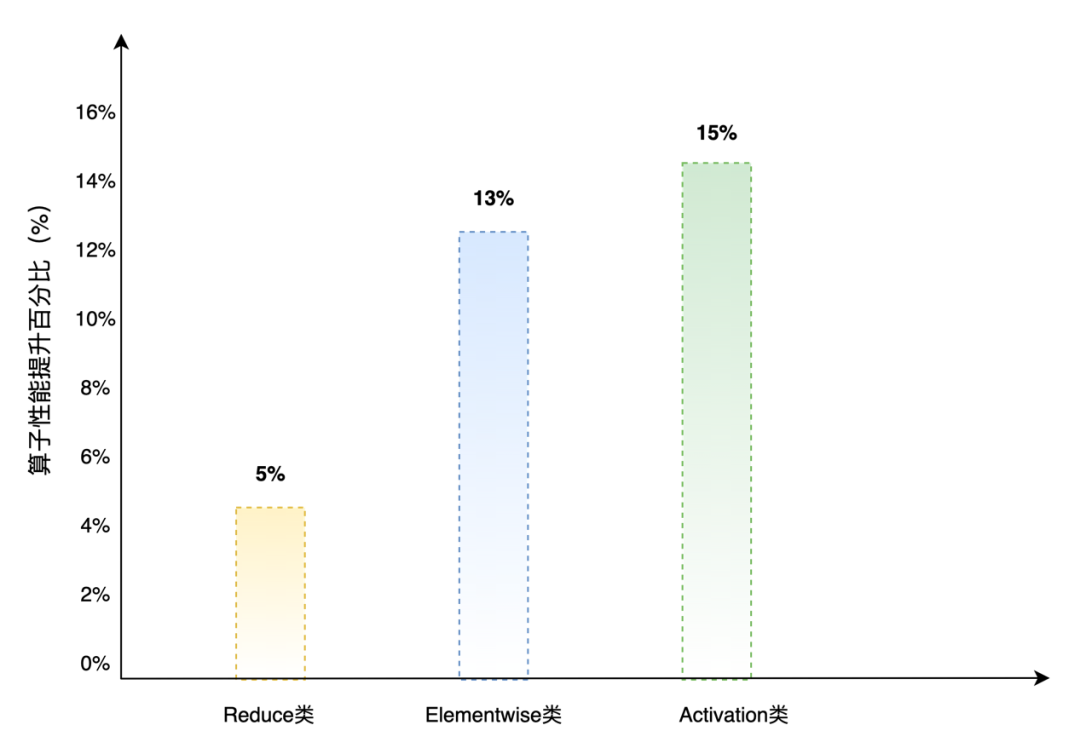随着深度学习的蓬勃发展,其应用领域也愈加丰富,对深度学习框架的计算算子需求也随之增多。一个成熟的框架,其算子数目通常达到几百甚至上千。面对同样繁荣发展的AI硬件(加速器)市场,在算子适配层面,深度学习框架与硬件的通常做法是,对每个算子在各个硬件平台上全部单独实现。这导致了各硬件的算子代码无法系统性复用,甚至相同的优化策略也要在不同硬件平台上重复实现。无论是框架还是硬件,其开发成本都是巨大的。
KP设计思想
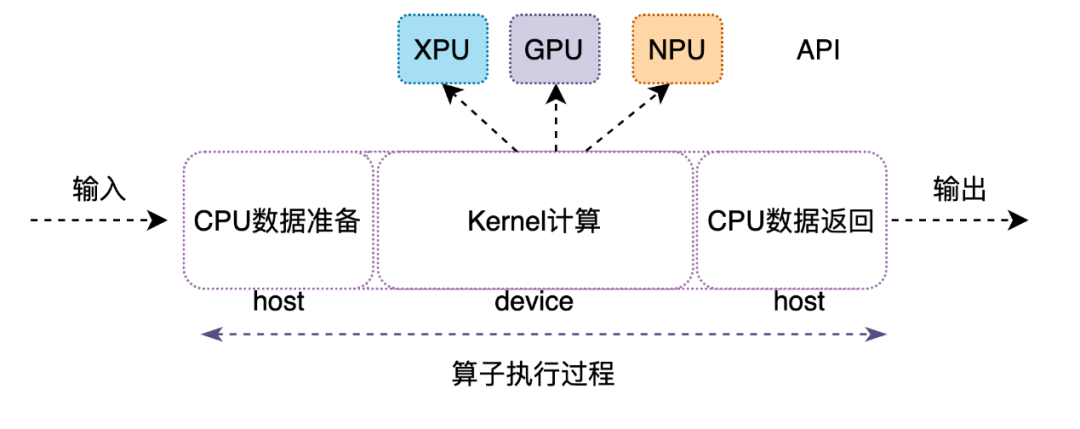
图1 算子执行流程
在设计理念上,KP采用分层结构,将算子在硬件上的实现分成2层结构。
不同平台的API内部实现略有差异,主要依赖于当前AI处理器的硬件特性,将同一硬件适配的API放置到固定文件,通过编译宏进行头文件控制,保证不同硬件间的独立性,从而达到屏蔽硬件细节的效果。
数据读写类API,用于完成全局内存与寄存器间的数据搬运工作。
数据计算类API进行通用数据计算,例如加法, 求和,排序等操作。
图3 reduce API功能展示图
使用KP加速算子开发
代码复用,降低开发量
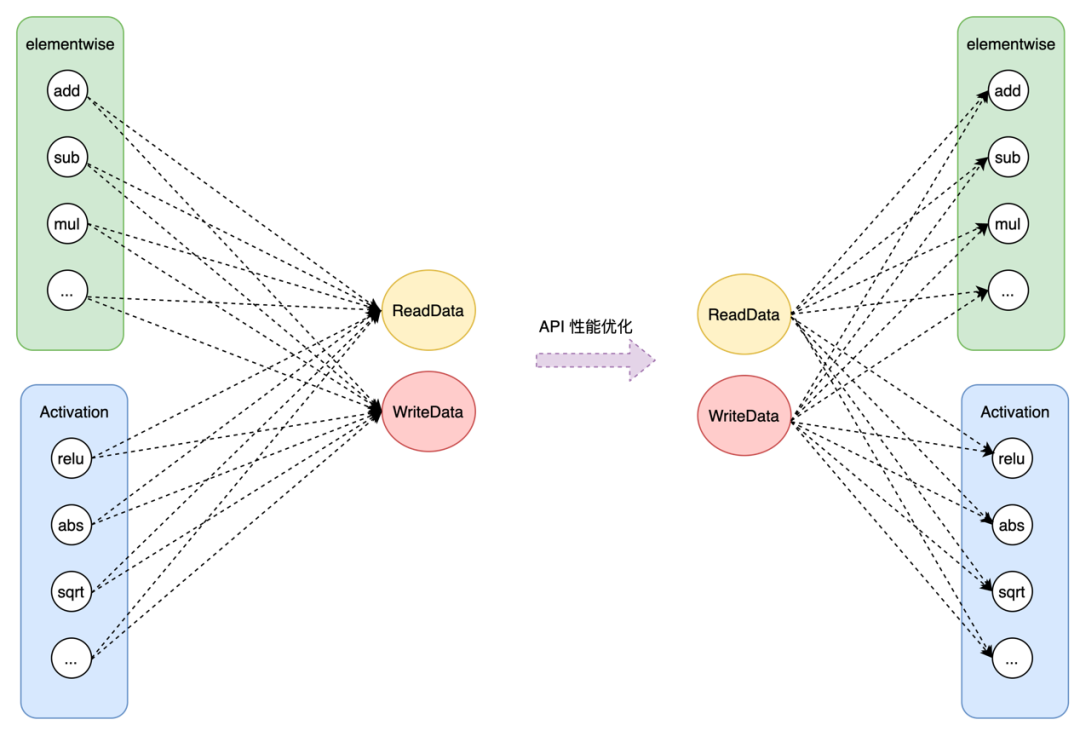
此外compare类与elementwise类算子的Kernel实现流程基本一致,首先将数据存全局内存读取到寄存器,然后根据特定计算规则对读取的数据进行计算,最后将计算结果写回到全局内存,具体Kernel实现差别只有计算规则不同。若每个算子都单独实现一份Kernel代码,将会导致大量的冗余代码存在,占用大量的人力,后续的Kernel的性能优化依旧需要逐个Kernel进行优化,工程量巨大。KP通过抽象操作规则,将数据操作定义为Functor并以函数模板的的形式传入,能够实现通用Kernel代码的复用,实现同类算子功能的快速支持。
简洁易维护
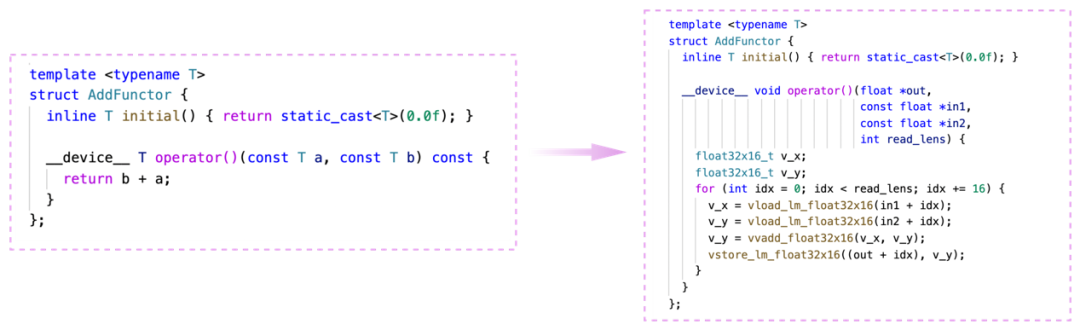
KP内封装了通用计算操作,将复杂的计算和数据搬运流程下沉到了简单的接口之下,开发者仅需要使用简单的API调用即可完成复杂的功能支持,使用KP实现的Kernel代码具有极度简洁,可维护性高等特点。以softmax为例,使用KP替换softmax原有Kernel实现,替换后的softmax与替换前相比,整体Kernel性能保持一致,而在某些数据规模下,性能还优于原始Kernel实现。使用KP实现的softmax Kernel代码量从之前的155行减少为30行,大幅降低了Kernel开发的工作量,同时替换后的 softmax 代码逻辑更加简洁清晰,与softmax的计算公式高度一致,代码可读性和易维护性明显增强。
图5 KP softmax Kernel实现
高性能实现
目前基于主流AI加速器实现的算子性能主要受访存和计算两个方面的约束,为保证Kernel性能,KP在设计之初就针对API特性进行了优化调整。对于IO类接口,KP设计了Block边界模板参数,除非指定,所有Block默认是非边界Block,仅在边界Block中添加边界判断和处理,通过减少不必要的分支判断,可以有效的提升API性能。此外为提升IO类API的访存效率,ReadData、WriteData等API提供了向量化数据读取参数VecSize,保证AI加速器的每个Core能够一次读取多个数据,以保证访存类API具有较高的访存效率,配合Block边界模板参数可进一步提升Kernel性能。
在进行计算类API优化时,为充分发挥编译器优化效果,在数据计算展开时,增加了Program unroll操作,数据循环操作能够在编译阶段实现循环展开,降低判断操作产生的时间开销。使用KP实现的elementwise类、activation类、reduce类等算子在适配前后性能分别有5%~15%的提升。
图7 使用KP后,三类重点算子性能提升幅度
KP加速硬件适配实战
昆仑芯2代产品适配
降低硬件感知度,减少硬件适配开发成本
以昆仑芯2代AI芯片CR20为例,如果采用传统算子开发方式接入飞桨框架,需根据新硬件特性在飞桨中添加相应的host端代码,完成elementwise, reduce, activation三类约70个算子的功能支持约需添加约10,800行代码;而通过KP完成这三类算子的功能支持仅需添加707行代码,代码适配量可减少93.4%。
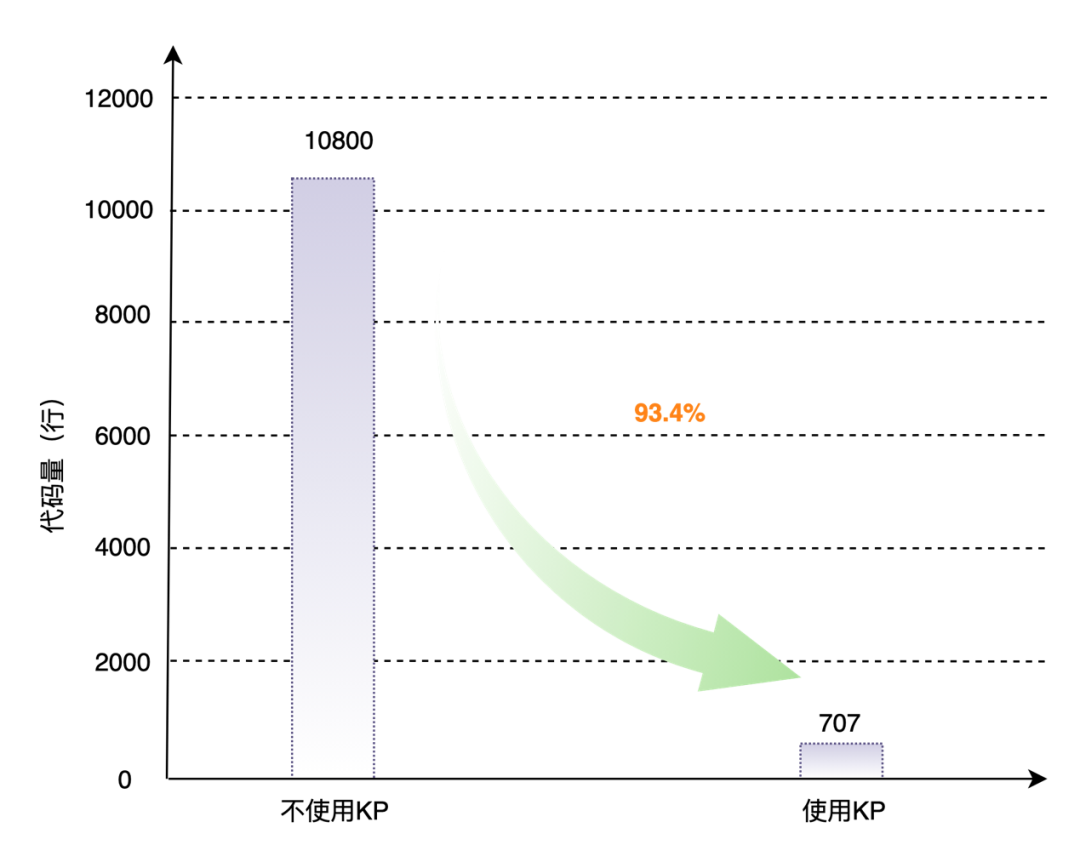 图8 KP昆仑芯2代芯片上三类重点算子适配代码量
图8 KP昆仑芯2代芯片上三类重点算子适配代码量
一处优化多处受益
为充分展示特定平台下的KP内部性能优化效果及优化细节,此处以CR20为例进行阐述。CR20包含8个CLUSTER,CLUSTER是细粒度可编程处理器,用于加速深度学习中非计算密集型的算子。每个CLUSTER包含64个XPU Core和256KB的Shared Memory,每个XPU Core有8KB的local memory,支持scalar运算并且具备512bit的SIMD计算能力。CLUSTER具有非常好的通用性和可编程性,用户可以根据需求来灵活实现各种函数,昆仑芯产品上大部分的AI操作都是由这个计算单元来实现,类似于NVIDIA GPU的CUDA Core。
 图10 昆仑芯XPU-R架构图
图10 昆仑芯XPU-R架构图
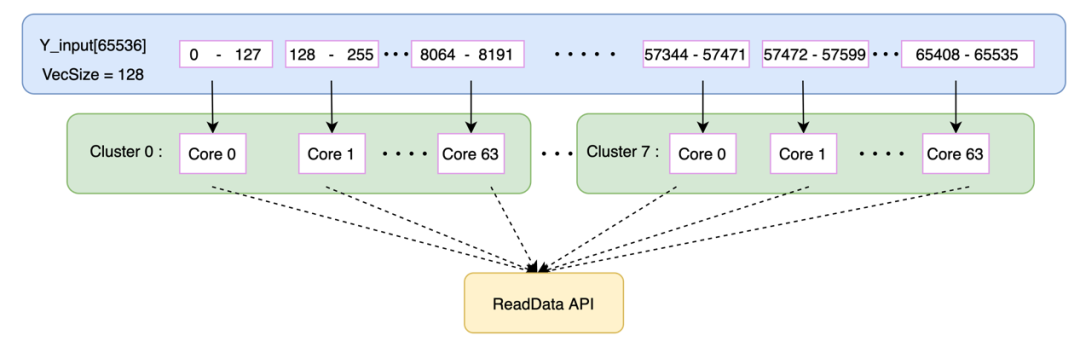
昆仑芯2代芯片的编程是采用SIMT的并行计算模型,将计算任务下发到多个CLUSTER和Core上进行并行计算。为提升数据访存效率,结合XPU编程模型和KP访存类API功能需求,我们对输入数据进行分块处理,使得输入数据尽可能的均分到每个Core上去处理,从而最大限度保证资源均衡。以broadcast_add为例:
输入规模:{x_input[1],y_input[65536]}
VecSize=input_len/(CLUSTER_num*core_num)=128
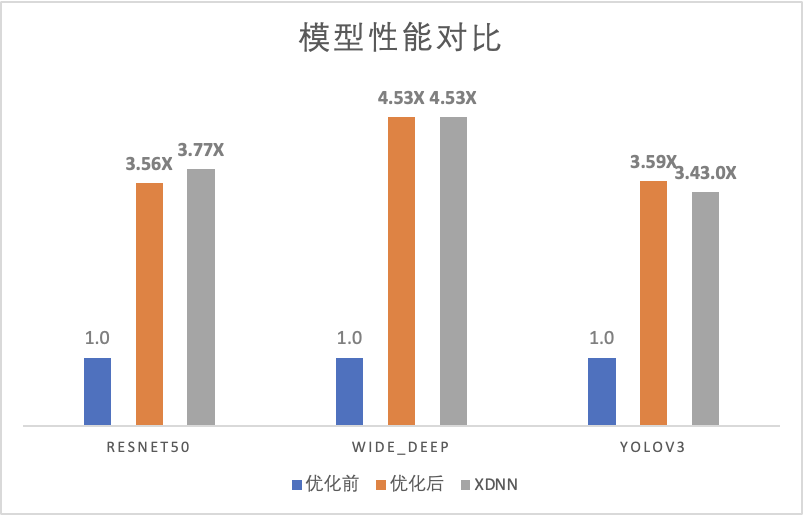
基于XPU的硬件特性和编程模型,通过对XPU Core进行合理的任务划分,以及采用SIMD指令等方式来对KP进行优化后,调用该API的算子性能都同步得到优化,实现了一处优化多处收益的优化效果。通过实际测试,优化后算子和模型性能相比原KP都有大幅提高,且能接近甚至达到XDNN(XPU Deep Neural Network Library,昆仑芯深度神经网络高性能优化加速算子库)的性能。
图14 优化前后的模型性能对比
总结
深度学习框架在高性能算子的具体实现上,目前主流的方式是针对不同硬件单独开发及优化,同一个算子提供多个硬件的实现版本,在编译时或运行时根据实际运行设备选择执行。这会使得各个算子间的代码无法系统性复用,并且类似的性能优化方法需要在不同硬件上重复实现,导致算子开发成本高,性能优化难度大,硬件迁移成本高等问题。
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
随着深度学习的蓬勃发展,其应用领域也愈加丰富,对深度学习框架的计算算子需求也随之增多。一个成熟的框架,其算子数目通常达到几百甚至上千。面对同样繁荣发展的AI硬件(加速器)市场,在算子适配层面,深度学习框架与硬件的通常做法是,对每个算子在各个硬件平台上全部单独实现。这导致了各硬件的算子代码无法系统性复用,甚至相同的优化策略也要在不同硬件平台上重复实现。无论是框架还是硬件,其开发成本都是巨大的。
KP设计思想
图1 算子执行流程
在设计理念上,KP采用分层结构,将算子在硬件上的实现分成2层结构。
不同平台的API内部实现略有差异,主要依赖于当前AI处理器的硬件特性,将同一硬件适配的API放置到固定文件,通过编译宏进行头文件控制,保证不同硬件间的独立性,从而达到屏蔽硬件细节的效果。
数据读写类API,用于完成全局内存与寄存器间的数据搬运工作。
数据计算类API进行通用数据计算,例如加法, 求和,排序等操作。
图3 reduce API功能展示图
使用KP加速算子开发
代码复用,降低开发量
此外compare类与elementwise类算子的Kernel实现流程基本一致,首先将数据存全局内存读取到寄存器,然后根据特定计算规则对读取的数据进行计算,最后将计算结果写回到全局内存,具体Kernel实现差别只有计算规则不同。若每个算子都单独实现一份Kernel代码,将会导致大量的冗余代码存在,占用大量的人力,后续的Kernel的性能优化依旧需要逐个Kernel进行优化,工程量巨大。KP通过抽象操作规则,将数据操作定义为Functor并以函数模板的的形式传入,能够实现通用Kernel代码的复用,实现同类算子功能的快速支持。
简洁易维护
KP内封装了通用计算操作,将复杂的计算和数据搬运流程下沉到了简单的接口之下,开发者仅需要使用简单的API调用即可完成复杂的功能支持,使用KP实现的Kernel代码具有极度简洁,可维护性高等特点。以softmax为例,使用KP替换softmax原有Kernel实现,替换后的softmax与替换前相比,整体Kernel性能保持一致,而在某些数据规模下,性能还优于原始Kernel实现。使用KP实现的softmax Kernel代码量从之前的155行减少为30行,大幅降低了Kernel开发的工作量,同时替换后的 softmax 代码逻辑更加简洁清晰,与softmax的计算公式高度一致,代码可读性和易维护性明显增强。
图5 KP softmax Kernel实现
高性能实现
目前基于主流AI加速器实现的算子性能主要受访存和计算两个方面的约束,为保证Kernel性能,KP在设计之初就针对API特性进行了优化调整。对于IO类接口,KP设计了Block边界模板参数,除非指定,所有Block默认是非边界Block,仅在边界Block中添加边界判断和处理,通过减少不必要的分支判断,可以有效的提升API性能。此外为提升IO类API的访存效率,ReadData、WriteData等API提供了向量化数据读取参数VecSize,保证AI加速器的每个Core能够一次读取多个数据,以保证访存类API具有较高的访存效率,配合Block边界模板参数可进一步提升Kernel性能。
在进行计算类API优化时,为充分发挥编译器优化效果,在数据计算展开时,增加了Program unroll操作,数据循环操作能够在编译阶段实现循环展开,降低判断操作产生的时间开销。使用KP实现的elementwise类、activation类、reduce类等算子在适配前后性能分别有5%~15%的提升。
图7 使用KP后,三类重点算子性能提升幅度
KP加速硬件适配实战
昆仑芯2代产品适配
降低硬件感知度,减少硬件适配开发成本
以昆仑芯2代AI芯片CR20为例,如果采用传统算子开发方式接入飞桨框架,需根据新硬件特性在飞桨中添加相应的host端代码,完成elementwise, reduce, activation三类约70个算子的功能支持约需添加约10,800行代码;而通过KP完成这三类算子的功能支持仅需添加707行代码,代码适配量可减少93.4%。
图8 KP昆仑芯2代芯片上三类重点算子适配代码量
一处优化多处受益
为充分展示特定平台下的KP内部性能优化效果及优化细节,此处以CR20为例进行阐述。CR20包含8个CLUSTER,CLUSTER是细粒度可编程处理器,用于加速深度学习中非计算密集型的算子。每个CLUSTER包含64个XPU Core和256KB的Shared Memory,每个XPU Core有8KB的local memory,支持scalar运算并且具备512bit的SIMD计算能力。CLUSTER具有非常好的通用性和可编程性,用户可以根据需求来灵活实现各种函数,昆仑芯产品上大部分的AI操作都是由这个计算单元来实现,类似于NVIDIA GPU的CUDA Core。
图10 昆仑芯XPU-R架构图
昆仑芯2代芯片的编程是采用SIMT的并行计算模型,将计算任务下发到多个CLUSTER和Core上进行并行计算。为提升数据访存效率,结合XPU编程模型和KP访存类API功能需求,我们对输入数据进行分块处理,使得输入数据尽可能的均分到每个Core上去处理,从而最大限度保证资源均衡。以broadcast_add为例:
输入规模:{x_input[1],y_input[65536]}
VecSize=input_len/(CLUSTER_num*core_num)=128
基于XPU的硬件特性和编程模型,通过对XPU Core进行合理的任务划分,以及采用SIMD指令等方式来对KP进行优化后,调用该API的算子性能都同步得到优化,实现了一处优化多处收益的优化效果。通过实际测试,优化后算子和模型性能相比原KP都有大幅提高,且能接近甚至达到XDNN(XPU Deep Neural Network Library,昆仑芯深度神经网络高性能优化加速算子库)的性能。
图14 优化前后的模型性能对比
总结
深度学习框架在高性能算子的具体实现上,目前主流的方式是针对不同硬件单独开发及优化,同一个算子提供多个硬件的实现版本,在编译时或运行时根据实际运行设备选择执行。这会使得各个算子间的代码无法系统性复用,并且类似的性能优化方法需要在不同硬件上重复实现,导致算子开发成本高,性能优化难度大,硬件迁移成本高等问题。
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~