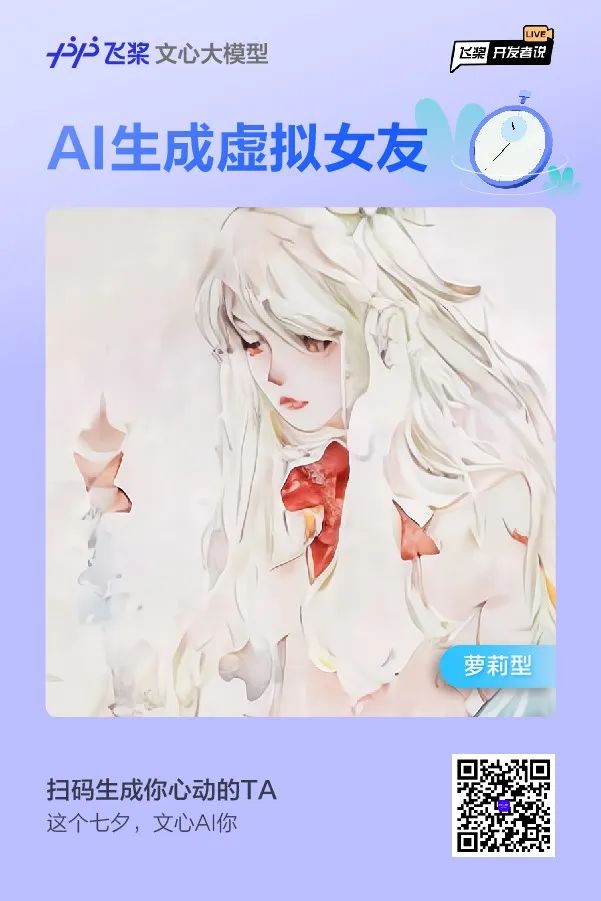
一年一度的情人节——七夕又来了。每到这一天,都有很多程序员整活,用代码给女朋友表白。而对于更多的开发者来说,七夕可能只是写代码的平凡一天,下班回到家躺在床上开始思考同一个问题,我的女朋友在哪里呢?我的女朋友长什么样子呢?
飞桨开发者技术专家(PPDE)杨登辉就给单身汪带来了福音,用AI生成理想型女友,并让她开口说话、唱歌。
觉得这些都不适合你?还想让AI女友和你聊天?给你唱歌?那就跟着开发者一起,用飞桨生成专属于你的理想型AI女友吧~
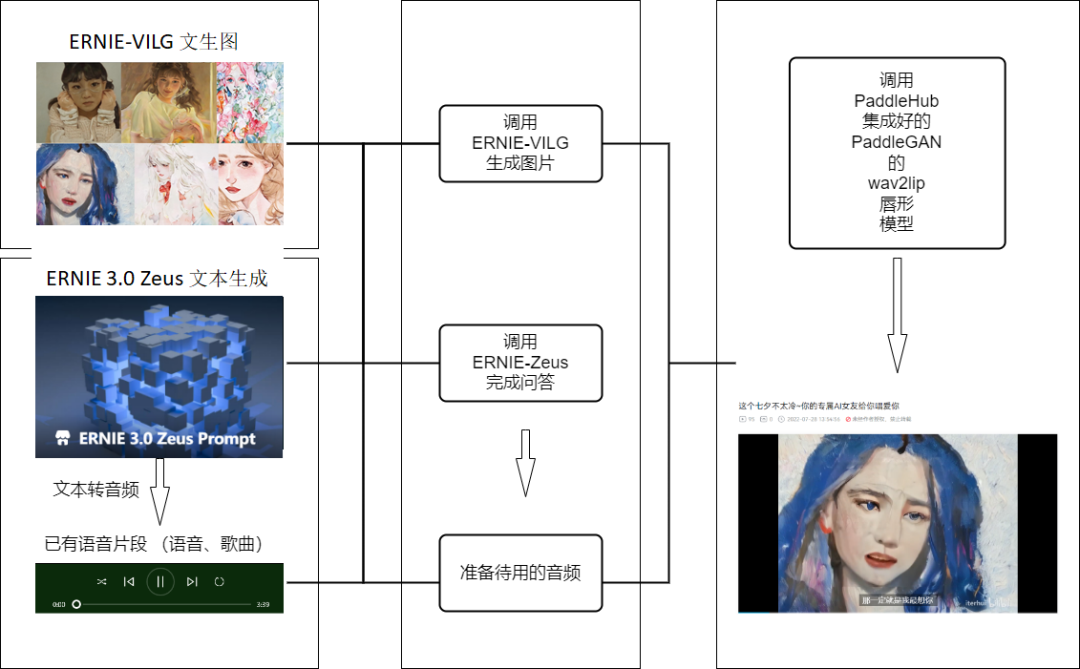
生成AI女友共需要四步:
3.开口说话:使用飞桨语音模型库PaddleSpeech完成文本转语音;
使用API Key与SK获取Token
文心大模型将任务封装为API供我们使用,而调用API需要我们获取API Key(AK)和Secret Key(SK),因此我们需要获取Token。
当然,这里AK和SK肯定和你们的不一样,如果有需要,可以自行前往申请,点击下方链接,即可获取!
https://wenxin.baidu.com/younger/apiDetail?id=20008
import requests
import json
# 执行代码前填入你的AK和SK
# 'client_id':'xxxxxxxxxxxxxx'
# 'client_secret':'xxxxxxxxxxx'
# 获取token
token = requests.request('POST',
'https://wenxin.baidu.com/younger/portal/api/oauth/token',
data={
'grant_type':'client_credentials',
'client_id':'your ak',
'client_secret':'your sk'},
timeout=3)
token = json.loads(token.text)['data']
token
# 如果代码没有问题,下面的输出应该是这样的
# 'xx.xxxxxxxxxxxxxxxxxxxxxxx.xxxxxxxxxx.xxxxxxxxxxxxxx.xxxxxxxxxxxxxxxxxxxxxxxxxxxxx-xxxxx' 调用文心ERNIE-ViLG API
大家可以根据自己的需要进行多次尝试,尽量使用比较简洁明了的文本即可。比如:美丽 可爱 漂亮 大方 仙女 女朋友。
目前,文心ERNIE-ViLG API支持的油画、水彩画、中国画三种风格,这三种风格文字不能进行更改,但你可以选择使用其中一种风格生成图片,更改对应的[x]即可。
油画: 'style': style[0]
水彩画: 'style': style[1]
中国画: 'style': style[2]
url = "https://wenxin.baidu.com/younger/portal/api/rest/1.0/ernievilg/v1/txt2img"
style = ['油画','水彩画','中国画']
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded"
}
# 你想要的女朋友是什么样的呢?
# 我的是这样的!
# 不超过16个字
desp = '漂亮,美丽,小仙女,女朋友'
# access_token 前面生成的token
# text 你需要生成的图像的文本
# style 哪一种风格
payload={
'access_token': token,
'text': desp[:16],
'style': style[2],
}
response = requests.request("POST", url, data=payload, headers = headers,timeout = 30)
out = json.loads(response.text)
print(out)
task_id = out["data"]["taskId"]
print(task_id) 最终获取到Task id,拿到Task id才可以执行下一个代码块获取得到的图像文件。
获取返回的图片
这里要记得等待几分钟,再执行代码,毕竟一张图的生成是需要时间的!
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
import requests
url = "https://wenxin.baidu.com/younger/portal/api/rest/1.0/ernievilg/v1/getImg"
payload={
'access_token': token,
'taskId': task_id
}
response = requests.request("POST", url, data=payload)
# 获取图片的路径
img = json.loads(response.text)["data"]["imgUrls"]
# 默认是生成十张图片
if (len(img)!=10):
print("图片正在生成中,请耐心等待,稍后重新运行代码......")
# 存图片的目录
init_mkdir()
# 展示十张生成的图片并保存
for i in img:
i = i["image"]
#使用requests直接get 下载图片使用
r = requests.get(i)
ii = i.split('/')[-1]+'.png'
out_ii = 'output-img/' + ii
with open(out_ii, 'wb') as f:
f.write(r.content)
f.close()
img_ = Image.open(out_ii)
plt.show()
plt.imshow(img_) 文心ERNIE 3.0 Zeus 文本生成
文心ERNIE 3.0 Zeus是全新发布的融合任务相关知识的千亿大模型,该模型大幅刷新各类NLP任务最好效果,在各类公开数据集及真实场景上,零样本与小样本能力均取得显著提升,当前API为开发者提供大模型的探索和体验。
在文本框中输入一句或者一段话,模型就会根据输入的内容进行后文续写。这里的文本你可以随意输入,比如:que = ”你喜欢我吗?“
import requests
url =
"https://wenxin.baidu.com/younger/portal/api/rest/1.0/ernie/3.0/zeus"
que =
'你喜欢我吗?'
text =
'问题:' + que +
'?' +
' ' +
'回答:'
payload={
'text': text,
'seq_len':
256,
'task_prompt':
'',
'dataset_prompt':
'',
'access_token': token,
'topk':
10,
'stop_token':
''
}
response = requests.request(
"POST", url, data=payload)
print(response.text)
answer = json.loads(response.text)[
"data"][
"result"]
print(answer)
使用PaddleSpeech文本转语音,将文心ERNIE 3.0 Zeus生成的文本转换成语音格式。
# 安装库,大概需要1-2分钟
!pip install pytest-runner
!pip install paddlespeech
# 下载nltk数据包,如果项目中有就不用下载了
%cd /home/aistudio
!wget -P data https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
!tar zxvf data/nltk_data.tar.gz
# 一定是GPU版本才可以运行起来
# 在文本中加上前缀我,后缀你
if ('我' not in answer):
answer = '我好好好' + answer
if ('你' not in answer):
answer = answer + '你'
# 黏人一点,dddd
text = '臭宝,'+ answer + '呀,我要一直和你在一起,超幸福的'
from paddlespeech.cli.tts.infer import TTSExecutor
audio_path = "/home/aistudio/output.wav"
tts = TTSExecutor()
tts(text=text, output="/home/aistudio/output.wav") 当然。还可以让她唱歌给你听~
小编这里采用了王心凌的《爱你》这首歌,截取了歌曲的一个片段。
# 用来剪切音频和转换mp3为wav
!pip install pydub
!pip install moviepy
# 音频片段剪切
from moviepy.editor import *
from pydub import AudioSegment
filepath = 'aini.mp3'
music = AudioSegment.from_mp3(file=filepath)
sound_time = music.duration_seconds
# 使用切片截取, 单位毫秒, 1s -> 1000ms
out_music = music[37500: 88000]
out_mp3_path = "aini_sub.mp3"
# 导出
out_music.export(out_f=out_mp3_path, format='mp3') # 可以指定bitrate为64k比特率 None为源文件
sound = AudioSegment.from_mp3(out_mp3_path)
out_song_path = 'aini_sub.wav'
sound.export(out_song_path, format="wav")调用PaddleHub中封装好的wav2lip模型,简单方便。
# 报错就多运行几次
!pip install -U pip --user
# 升级paddlehub防止版本出错
!pip install -U paddlehub
# 运行时长由你的语音的长度决定
import paddlehub as hub
module = hub.Module(name="wav2lip")
# 你想要作为女朋友的照片
face_input_path = "demo.png"
# 上面生成的音频的路径
audio_input_path = audio_path
module.wav2lip_transfer(
face=face_input_path,
audio=audio_input_path,
output_dir='./transfer_result/',
use_gpu=True)
点击下方链接,来看一下最终效果吧
这个项目借助文心大模型生成人物图片并实现问答,同时还可以结合PaddleSpeech进行文本转语音,将语音与上文实现的人像唇形相结合,最终生成一个可以唱歌的AI女友。当然,目前唇形的实现还略微粗糙,但图一乐足够了~


关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
一年一度的情人节——七夕又来了。每到这一天,都有很多程序员整活,用代码给女朋友表白。而对于更多的开发者来说,七夕可能只是写代码的平凡一天,下班回到家躺在床上开始思考同一个问题,我的女朋友在哪里呢?我的女朋友长什么样子呢?
飞桨开发者技术专家(PPDE)杨登辉就给单身汪带来了福音,用AI生成理想型女友,并让她开口说话、唱歌。
觉得这些都不适合你?还想让AI女友和你聊天?给你唱歌?那就跟着开发者一起,用飞桨生成专属于你的理想型AI女友吧~
生成AI女友共需要四步:
3.开口说话:使用飞桨语音模型库PaddleSpeech完成文本转语音;
使用API Key与SK获取Token
文心大模型将任务封装为API供我们使用,而调用API需要我们获取API Key(AK)和Secret Key(SK),因此我们需要获取Token。
当然,这里AK和SK肯定和你们的不一样,如果有需要,可以自行前往申请,点击下方链接,即可获取!
https://wenxin.baidu.com/younger/apiDetail?id=20008
import requests
import json
# 执行代码前填入你的AK和SK
# 'client_id':'xxxxxxxxxxxxxx'
# 'client_secret':'xxxxxxxxxxx'
# 获取token
token = requests.request('POST',
'https://wenxin.baidu.com/younger/portal/api/oauth/token',
data={
'grant_type':'client_credentials',
'client_id':'your ak',
'client_secret':'your sk'},
timeout=3)
token = json.loads(token.text)['data']
token
# 如果代码没有问题,下面的输出应该是这样的
# 'xx.xxxxxxxxxxxxxxxxxxxxxxx.xxxxxxxxxx.xxxxxxxxxxxxxx.xxxxxxxxxxxxxxxxxxxxxxxxxxxxx-xxxxx' 调用文心ERNIE-ViLG API
大家可以根据自己的需要进行多次尝试,尽量使用比较简洁明了的文本即可。比如:美丽 可爱 漂亮 大方 仙女 女朋友。
目前,文心ERNIE-ViLG API支持的油画、水彩画、中国画三种风格,这三种风格文字不能进行更改,但你可以选择使用其中一种风格生成图片,更改对应的[x]即可。
油画: 'style': style[0]
水彩画: 'style': style[1]
中国画: 'style': style[2]
url = "https://wenxin.baidu.com/younger/portal/api/rest/1.0/ernievilg/v1/txt2img"
style = ['油画','水彩画','中国画']
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded"
}
# 你想要的女朋友是什么样的呢?
# 我的是这样的!
# 不超过16个字
desp = '漂亮,美丽,小仙女,女朋友'
# access_token 前面生成的token
# text 你需要生成的图像的文本
# style 哪一种风格
payload={
'access_token': token,
'text': desp[:16],
'style': style[2],
}
response = requests.request("POST", url, data=payload, headers = headers,timeout = 30)
out = json.loads(response.text)
print(out)
task_id = out["data"]["taskId"]
print(task_id) 最终获取到Task id,拿到Task id才可以执行下一个代码块获取得到的图像文件。
获取返回的图片
这里要记得等待几分钟,再执行代码,毕竟一张图的生成是需要时间的!
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
import requests
url = "https://wenxin.baidu.com/younger/portal/api/rest/1.0/ernievilg/v1/getImg"
payload={
'access_token': token,
'taskId': task_id
}
response = requests.request("POST", url, data=payload)
# 获取图片的路径
img = json.loads(response.text)["data"]["imgUrls"]
# 默认是生成十张图片
if (len(img)!=10):
print("图片正在生成中,请耐心等待,稍后重新运行代码......")
# 存图片的目录
init_mkdir()
# 展示十张生成的图片并保存
for i in img:
i = i["image"]
#使用requests直接get 下载图片使用
r = requests.get(i)
ii = i.split('/')[-1]+'.png'
out_ii = 'output-img/' + ii
with open(out_ii, 'wb') as f:
f.write(r.content)
f.close()
img_ = Image.open(out_ii)
plt.show()
plt.imshow(img_) 文心ERNIE 3.0 Zeus 文本生成
文心ERNIE 3.0 Zeus是全新发布的融合任务相关知识的千亿大模型,该模型大幅刷新各类NLP任务最好效果,在各类公开数据集及真实场景上,零样本与小样本能力均取得显著提升,当前API为开发者提供大模型的探索和体验。
在文本框中输入一句或者一段话,模型就会根据输入的内容进行后文续写。这里的文本你可以随意输入,比如:que = ”你喜欢我吗?“
import requests
url =
"https://wenxin.baidu.com/younger/portal/api/rest/1.0/ernie/3.0/zeus"
que =
'你喜欢我吗?'
text =
'问题:' + que +
'?' +
' ' +
'回答:'
payload={
'text': text,
'seq_len':
256,
'task_prompt':
'',
'dataset_prompt':
'',
'access_token': token,
'topk':
10,
'stop_token':
''
}
response = requests.request(
"POST", url, data=payload)
print(response.text)
answer = json.loads(response.text)[
"data"][
"result"]
print(answer)
使用PaddleSpeech文本转语音,将文心ERNIE 3.0 Zeus生成的文本转换成语音格式。
# 安装库,大概需要1-2分钟
!pip install pytest-runner
!pip install paddlespeech
# 下载nltk数据包,如果项目中有就不用下载了
%cd /home/aistudio
!wget -P data https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
!tar zxvf data/nltk_data.tar.gz
# 一定是GPU版本才可以运行起来
# 在文本中加上前缀我,后缀你
if ('我' not in answer):
answer = '我好好好' + answer
if ('你' not in answer):
answer = answer + '你'
# 黏人一点,dddd
text = '臭宝,'+ answer + '呀,我要一直和你在一起,超幸福的'
from paddlespeech.cli.tts.infer import TTSExecutor
audio_path = "/home/aistudio/output.wav"
tts = TTSExecutor()
tts(text=text, output="/home/aistudio/output.wav") 当然。还可以让她唱歌给你听~
小编这里采用了王心凌的《爱你》这首歌,截取了歌曲的一个片段。
# 用来剪切音频和转换mp3为wav
!pip install pydub
!pip install moviepy
# 音频片段剪切
from moviepy.editor import *
from pydub import AudioSegment
filepath = 'aini.mp3'
music = AudioSegment.from_mp3(file=filepath)
sound_time = music.duration_seconds
# 使用切片截取, 单位毫秒, 1s -> 1000ms
out_music = music[37500: 88000]
out_mp3_path = "aini_sub.mp3"
# 导出
out_music.export(out_f=out_mp3_path, format='mp3') # 可以指定bitrate为64k比特率 None为源文件
sound = AudioSegment.from_mp3(out_mp3_path)
out_song_path = 'aini_sub.wav'
sound.export(out_song_path, format="wav")调用PaddleHub中封装好的wav2lip模型,简单方便。
# 报错就多运行几次
!pip install -U pip --user
# 升级paddlehub防止版本出错
!pip install -U paddlehub
# 运行时长由你的语音的长度决定
import paddlehub as hub
module = hub.Module(name="wav2lip")
# 你想要作为女朋友的照片
face_input_path = "demo.png"
# 上面生成的音频的路径
audio_input_path = audio_path
module.wav2lip_transfer(
face=face_input_path,
audio=audio_input_path,
output_dir='./transfer_result/',
use_gpu=True)
点击下方链接,来看一下最终效果吧
这个项目借助文心大模型生成人物图片并实现问答,同时还可以结合PaddleSpeech进行文本转语音,将语音与上文实现的人像唇形相结合,最终生成一个可以唱歌的AI女友。当然,目前唇形的实现还略微粗糙,但图一乐足够了~
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~