模型的训练与部署一直是AI应用的核心。针对深度学习算法在工业化落地过程中的应用与挑战,百度飞桨与Arm合作,针对Arm Cortex-M处理器的深度学习应用场景,完成了飞桨模型在Cortex-M硬件上的适配。百度与Arm的此次合作,填补了飞桨模型在Cortex-M硬件上的适配空白,同时也增加了Cortex-M硬件上的深度学习模型数量,为开发者提供了更多的部署方案。
本期,小编将带大家重温百度飞桨开发者说之“Arm 虚拟硬件平台的飞桨模型部署实战”直播课程的主要内容,与大家共同回顾在AVH上部署飞桨模型的端到端流程。
本次课程也是首次展示如何将飞桨模型直接部署在含有Arm Cortex-M处理器IP的AVH平台上。通过此次课程,你不仅可以深入学习如何使用飞桨训练获得更高效的训练模型和推理模型,还会了解到如何通过深度学习编译TVM将飞桨模型编译为适配在Arm Cortex-M上运行的目标代码,并将其部署在含有Cortex-M55的AVH平台上。
更多精彩内容欢迎点击课程回放链接:
本次直播课程内容主要涵盖以下五个部分:
第一部分 课程概述
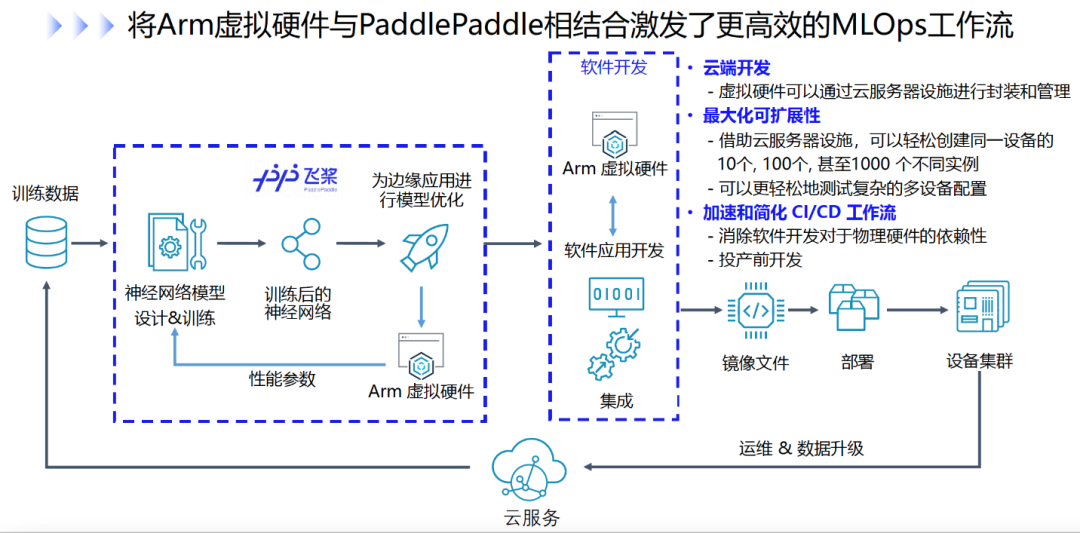
简要介绍在物联网时代下,深度学习应用在工业化落地过程中所面临的种种挑战,并详细分析AVH如何与飞桨相结合激发更高效的 MLOps工作流,从而加速边缘侧机器学习应用的开发。
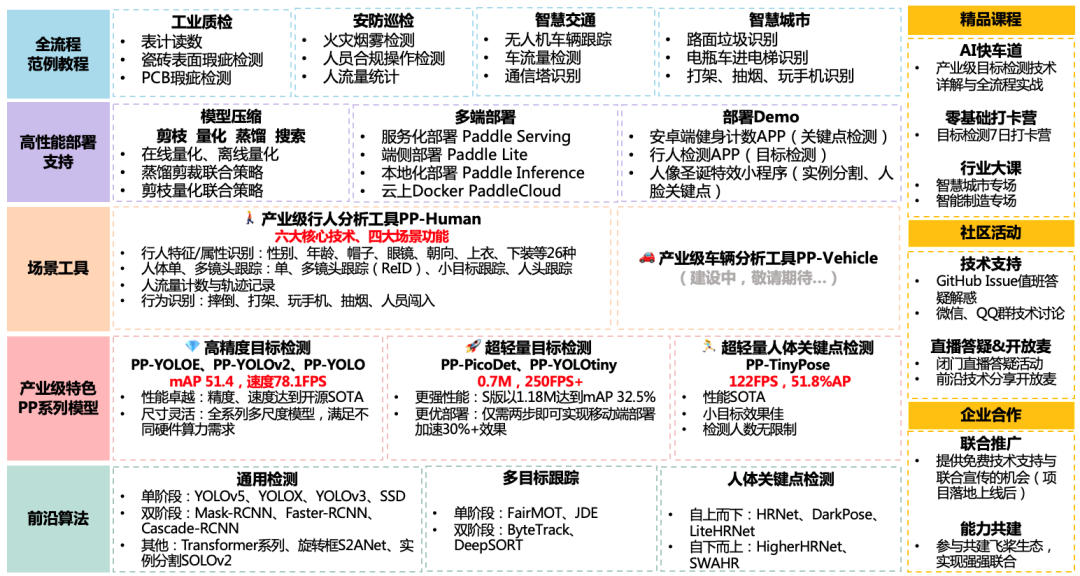
针对计算机视觉领域的目标检测任务(Detection),详细介绍百度飞桨的 PaddleDetection开发套件的特点与优势,并深入讲解了PP-PicoDet模型如何与Cortex-M处理器适配的应用案例。
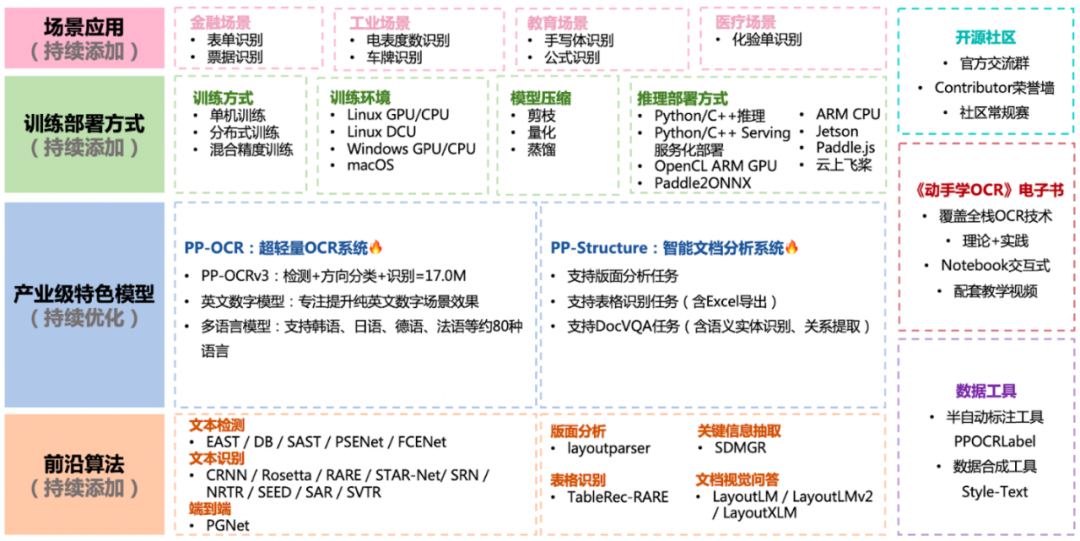
针对计算机视觉领域的文字识别(OCR),详细介绍了百度飞桨的PaddleOCR开发套件的特点与优势,并深入讲解了PP-OCRv3模型如何与Cortex-M处理器适配的应用案例。
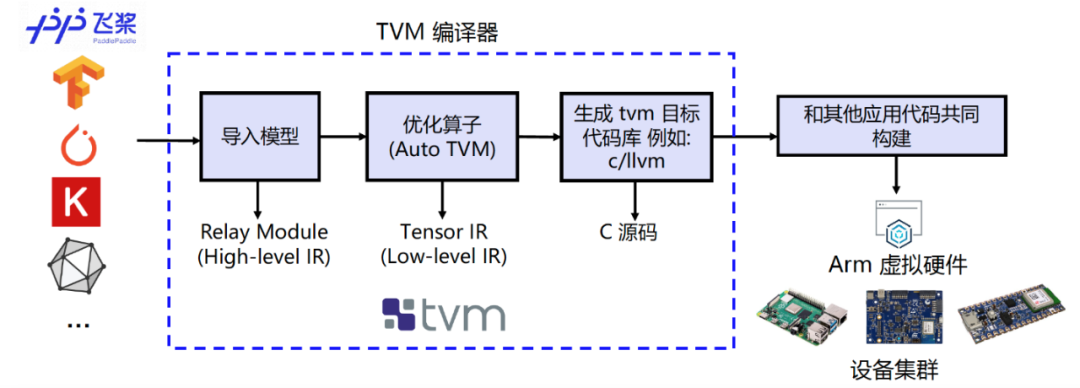
简要介绍深度学习编译器TVM的基本概念以及其与飞桨前端、CMSIS-NN后端的适配,并说明如何借助TVM编译器完成对飞桨推理模型的编译转换,使其成为适配在Cortex-M处理器上运行的代码。
图 4:编译流程示意图

不熟悉OCR?想要提前解锁了解更多关于OCR的前沿理论和代码实践?
欢迎大家扫描右方二维码关注公众号,免费领取由百度飞桨PaddleOCR团队携手学术界产业界技术专家同仁共建的覆盖从检测识别到文档分析的OCR全栈技术书籍《动手学OCR》。

本期部署实践课程使用的是托管在AWS/AWS China亚马逊机器镜像AMI中的 Corstone和Cortex CPU虚拟硬件。
欢迎各位开发者扫描下方二维码,即刻注册AVH第三方硬件平台,抢先体验AVH为你的嵌入式开发之旅所带来的极致便捷!还有更多在AVH第三方硬件平台上进行开发的有趣实例等着大家。
使用公司邮箱或学校邮箱注册申请,审批更高效哦!
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
模型的训练与部署一直是AI应用的核心。针对深度学习算法在工业化落地过程中的应用与挑战,百度飞桨与Arm合作,针对Arm Cortex-M处理器的深度学习应用场景,完成了飞桨模型在Cortex-M硬件上的适配。百度与Arm的此次合作,填补了飞桨模型在Cortex-M硬件上的适配空白,同时也增加了Cortex-M硬件上的深度学习模型数量,为开发者提供了更多的部署方案。
本期,小编将带大家重温百度飞桨开发者说之“Arm 虚拟硬件平台的飞桨模型部署实战”直播课程的主要内容,与大家共同回顾在AVH上部署飞桨模型的端到端流程。
本次课程也是首次展示如何将飞桨模型直接部署在含有Arm Cortex-M处理器IP的AVH平台上。通过此次课程,你不仅可以深入学习如何使用飞桨训练获得更高效的训练模型和推理模型,还会了解到如何通过深度学习编译TVM将飞桨模型编译为适配在Arm Cortex-M上运行的目标代码,并将其部署在含有Cortex-M55的AVH平台上。
更多精彩内容欢迎点击课程回放链接:
本次直播课程内容主要涵盖以下五个部分:
第一部分 课程概述
简要介绍在物联网时代下,深度学习应用在工业化落地过程中所面临的种种挑战,并详细分析AVH如何与飞桨相结合激发更高效的 MLOps工作流,从而加速边缘侧机器学习应用的开发。
针对计算机视觉领域的目标检测任务(Detection),详细介绍百度飞桨的 PaddleDetection开发套件的特点与优势,并深入讲解了PP-PicoDet模型如何与Cortex-M处理器适配的应用案例。
针对计算机视觉领域的文字识别(OCR),详细介绍了百度飞桨的PaddleOCR开发套件的特点与优势,并深入讲解了PP-OCRv3模型如何与Cortex-M处理器适配的应用案例。
简要介绍深度学习编译器TVM的基本概念以及其与飞桨前端、CMSIS-NN后端的适配,并说明如何借助TVM编译器完成对飞桨推理模型的编译转换,使其成为适配在Cortex-M处理器上运行的代码。
图 4:编译流程示意图
不熟悉OCR?想要提前解锁了解更多关于OCR的前沿理论和代码实践?
欢迎大家扫描右方二维码关注公众号,免费领取由百度飞桨PaddleOCR团队携手学术界产业界技术专家同仁共建的覆盖从检测识别到文档分析的OCR全栈技术书籍《动手学OCR》。
本期部署实践课程使用的是托管在AWS/AWS China亚马逊机器镜像AMI中的 Corstone和Cortex CPU虚拟硬件。
欢迎各位开发者扫描下方二维码,即刻注册AVH第三方硬件平台,抢先体验AVH为你的嵌入式开发之旅所带来的极致便捷!还有更多在AVH第三方硬件平台上进行开发的有趣实例等着大家。
使用公司邮箱或学校邮箱注册申请,审批更高效哦!
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~