本系列根据WAVE SUMMIT 2022深度学习开发者峰会「AI大模型 智领未来」论坛嘉宾分享整理。本文整理自百度计算机视觉首席科学家王井东的主题演讲:文心大模型 · CV基础大模型及应用。
文心VIMER-UFO 2.0
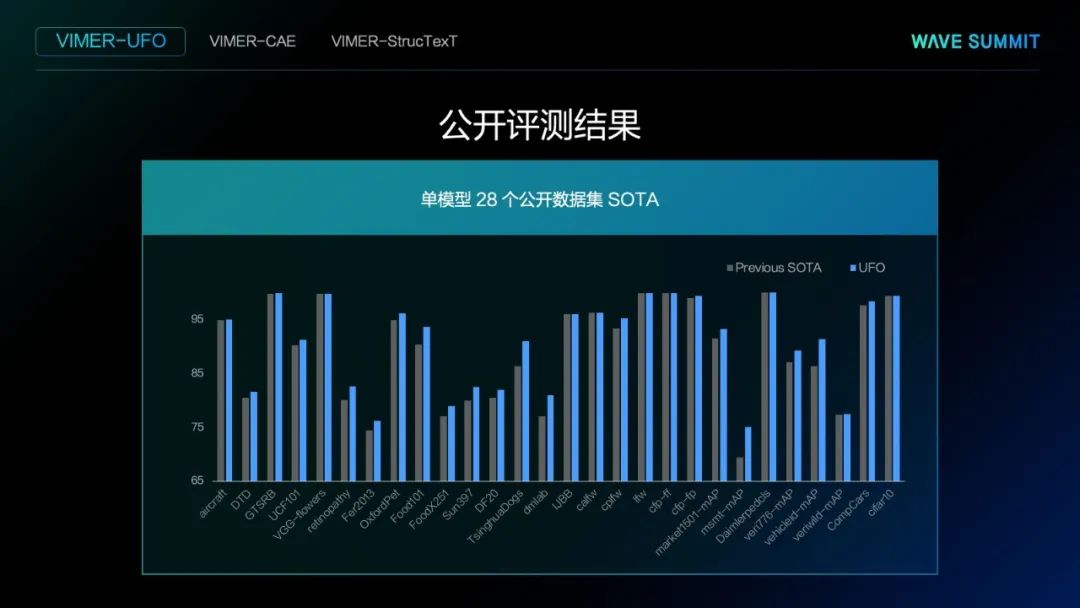
文心VIMER-UFO 2.0是面向多任务的视觉表征学习大模型。在计算机视觉里,有各种各样的计算机视觉任务,通常的做法是为每一个任务设计一个模型、训练一个模型。在这个工作里,我们希望训练一个能够同时做多项任务的大模型。
易部署。这是区别于其他很多大模型的重要一点。训练得到的网络结构不仅包含大模型,还可以得到多个小模型。轻量的小模型能够很容易地部署在设备端。
这项工作中的网络结构是基于飞桨MoE训练框架训练得到的。下面向大家展开介绍一下,我们是如何实现上面介绍的三个特点的:
多任务联合优化
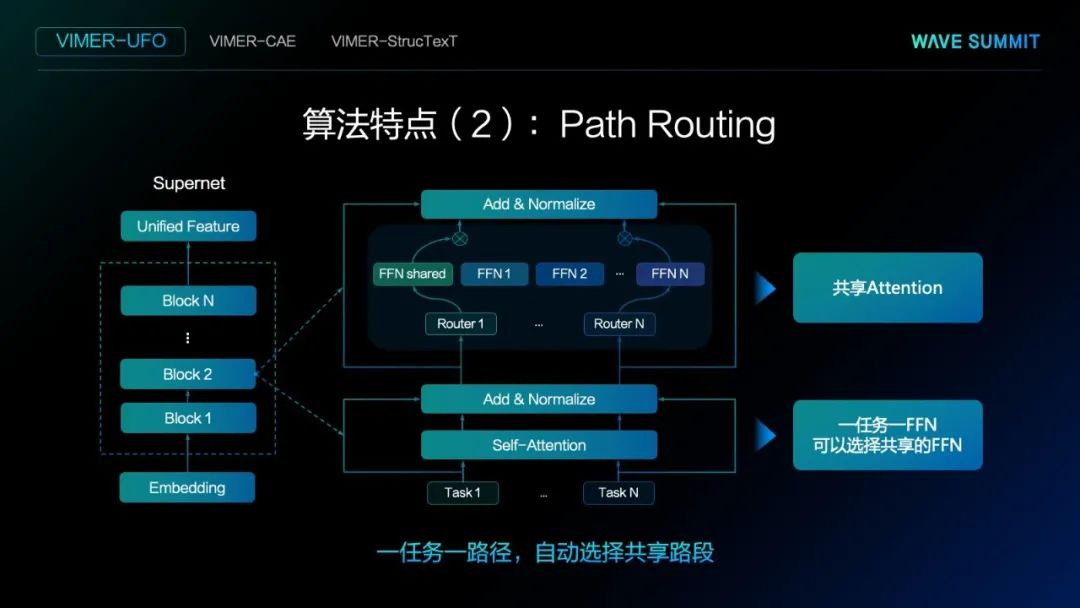
Path Routing
我们希望每个任务都有自己的路径,都有自己的子网络。那如何得到这个结果呢?在实际的设计里,网络结构基于Transformer结构,不同的任务会共享所谓的Attention层。在FFN层里,为每个任务都提供了一个独特的FFN,除此之外,每个任务也有机会去选择共享FFN。共享FFN即每个任务都有可能选择同一个FFN。
随机结构剪裁
在深度神经网络里,网络层比较深,这样使得计算量、参数量都会比较大。为了得到刚才提到的轻量模型,我们采取了随机深度的方法。除此之外,还有随机宽度,即减少或者随机地挑选一些channel进行优化。同时,在attention层里也有多个head,实际head的数目在训练过程里也随机可选。
上文介绍的文心VIMER-UFO 2.0是面向多任务的、有监督的一个方法,而无标注情况下,则需要采取自监督视觉表征学习方法。
文心VIMER-CAE
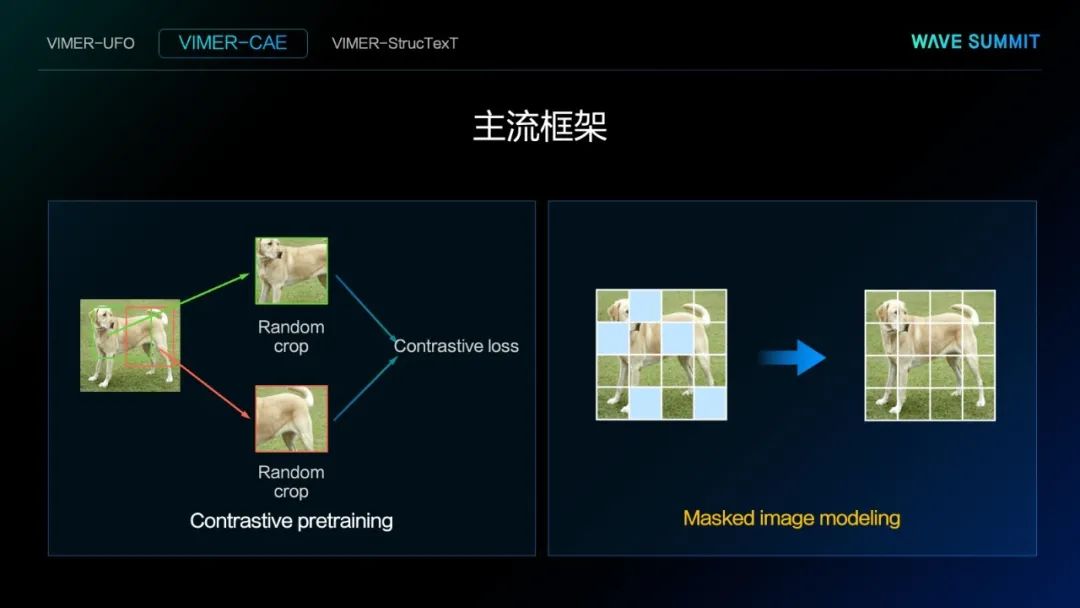
过去几年里,计算机视觉里主要有两大类自监督表征学习的方法:
Masked image modeling:如上图右侧所示,Masked image modeling是最近一年在计算机视觉里关注度比较高的一种方法。该方法通过随机将图像里的一些图像块Mask处理,然后把这些Mask部分预测出来。
Context Autoencoder的特点来源于深度学习里非常重要的共识——即希望解决视觉任务在高维的隐空间里做任务。基于以上出发点,我们希望掩码部分是在高维空间里预测出来,再通过解码器得到掩码的目标。
算法实际是希望编码器只做表征学习,比如:编码器只学习可见区域的表征,剩余其他部分只做预训练任务,而不再对可见区域做表征学习任务,如此就把表征学习和任务解决区分开,使得编码器能力更强。
如上图所示,文心VIMER-CAE编码器通过对图像块进行编码,得到它的表征,利用表征进行搜索。第一个例子中,最左边对应“查询”图像块,第一行查询的是运动员腿部,可以得到运动员腿部对应的图像块。第二行查询的是胡须,可以看到搜索得到的图像基本都是和胡须相关。这是非常有意思的一件事情,因为在学习编码器的时候并没有任何标注信息,但仍然能够学到如此有意义的语义信息。
除此之外,第四行和其他四个例子是不同的。第四行实际是关于场景类,不像腿部、胡须或车灯,说明这样的方法不仅能处理object,也可以处理stuff。
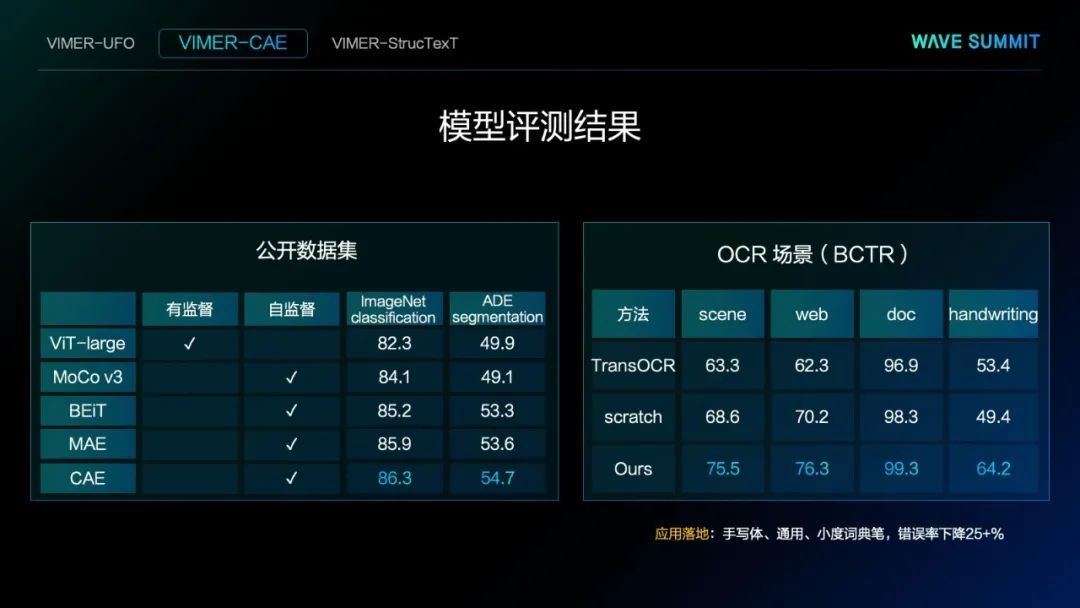
我们将这个方法在公开的数据集里做了测试,如上图左侧所示方法都是基于ViT-Large,它们编码器的计算量完全一样。第一行结果使用的是有监督方法,下面四行使用的是自监督方法,可以看到,自监督的结果比有监督的结果好很多。第三、四、五行,均基于Masked image modeling方法实现,除文心VIMER-CAE外的两项工作来自于微软和Facebook。可以看到,文心VIMER-CAE无论在分类还是分割的结果都比以前的方法表现要优越。
上图右侧展示了垂类OCR场景的结果,也是标准公开数据的结果,目前这个方法已经应用落地,在手写体、通用、小度词典笔等场景中,错误率下降25%。
文心 VIMER-StrucText 2.0
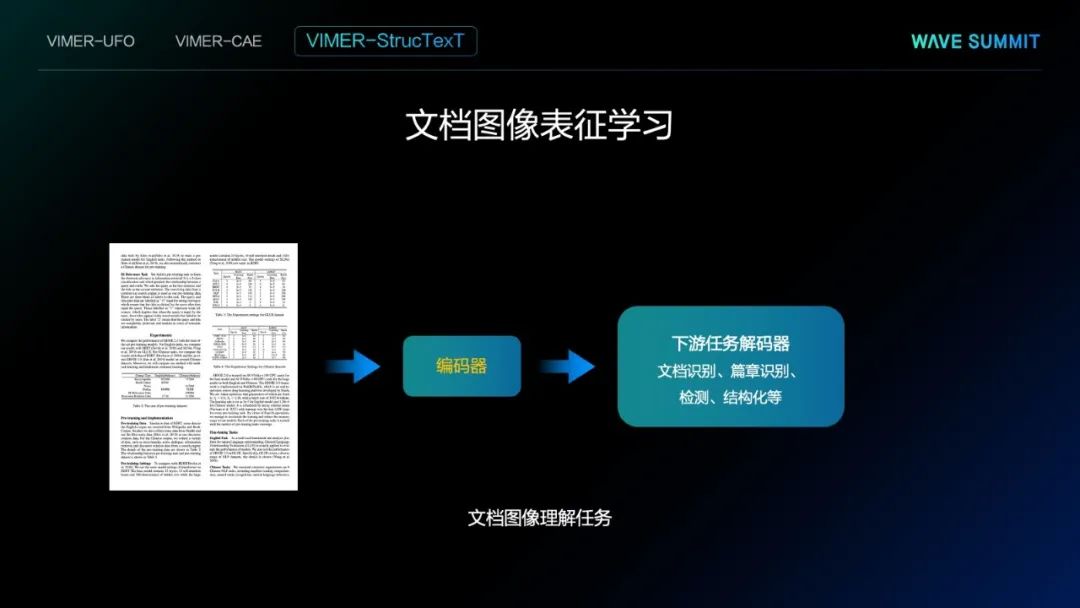
最后,再给大家分享一类特殊的图像——文档图像的处理方法,这个方法也是和文心VIMER-CAE非常相关。我们知道,在文档图像中有非常多的任务,例如:识别、版式分析等,同样也需要编码器。
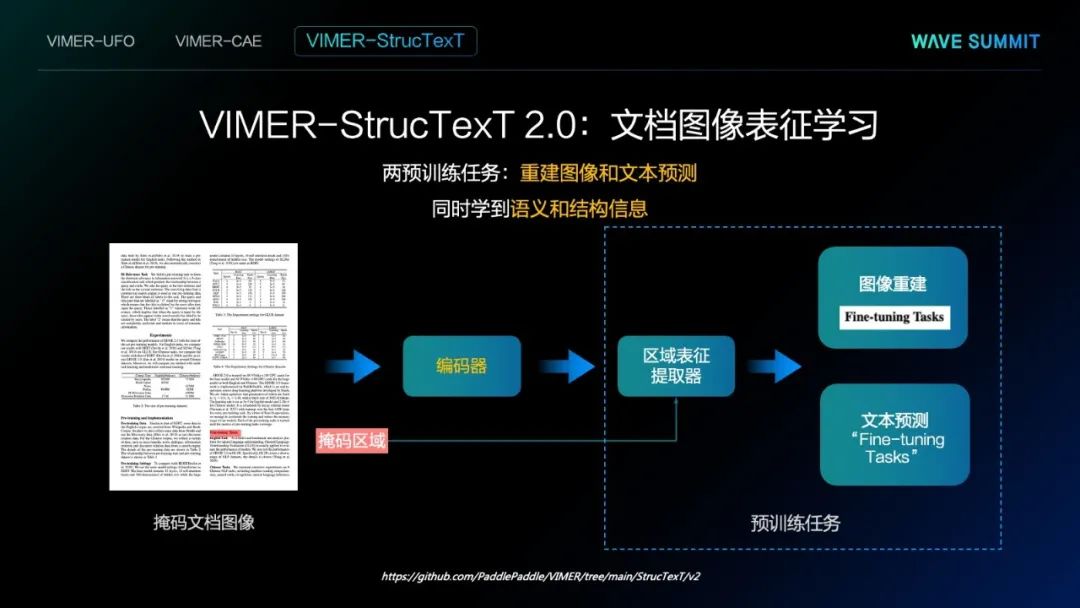
上图展示了文心VIMER-StrucText 2.0方法的流程图。与文心VIMER-CAE相关的地方在于,这两种方法都会把文档图像Mask掉一部分区域后,根据其他部分信息预测掩码区域的部分信息。比如说,这里面有两个任务,图像重建的任务,即直接把Mask部分图像重建出来。除此之外,还要预测Mask部分对应的文字,使得这样的方法学到的编码器,同时能够学到语义的信息,也能够得到结构的信息。
文档图像预训练,编码器学习最近几年也有不少的方法。我们做了简单的比较,大概把方法分成了三大类:
最后,与大家简单分享一下文心VIMER-StrucText 2.0方法在实际场景里的应用。如上图左侧示例所展示,这样的方法相比于StrucTexT 1.0而言,信息抽取流程能够大幅简化,不再需要依靠单独的OCR处理器输入OCR结果,使得效率至少能够提高30%。
扫码获得模型开源链接
拓展阅读:
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
本系列根据WAVE SUMMIT 2022深度学习开发者峰会「AI大模型 智领未来」论坛嘉宾分享整理。本文整理自百度计算机视觉首席科学家王井东的主题演讲:文心大模型 · CV基础大模型及应用。
文心VIMER-UFO 2.0
文心VIMER-UFO 2.0是面向多任务的视觉表征学习大模型。在计算机视觉里,有各种各样的计算机视觉任务,通常的做法是为每一个任务设计一个模型、训练一个模型。在这个工作里,我们希望训练一个能够同时做多项任务的大模型。
易部署。这是区别于其他很多大模型的重要一点。训练得到的网络结构不仅包含大模型,还可以得到多个小模型。轻量的小模型能够很容易地部署在设备端。
这项工作中的网络结构是基于飞桨MoE训练框架训练得到的。下面向大家展开介绍一下,我们是如何实现上面介绍的三个特点的:
多任务联合优化
Path Routing
我们希望每个任务都有自己的路径,都有自己的子网络。那如何得到这个结果呢?在实际的设计里,网络结构基于Transformer结构,不同的任务会共享所谓的Attention层。在FFN层里,为每个任务都提供了一个独特的FFN,除此之外,每个任务也有机会去选择共享FFN。共享FFN即每个任务都有可能选择同一个FFN。
随机结构剪裁
在深度神经网络里,网络层比较深,这样使得计算量、参数量都会比较大。为了得到刚才提到的轻量模型,我们采取了随机深度的方法。除此之外,还有随机宽度,即减少或者随机地挑选一些channel进行优化。同时,在attention层里也有多个head,实际head的数目在训练过程里也随机可选。
上文介绍的文心VIMER-UFO 2.0是面向多任务的、有监督的一个方法,而无标注情况下,则需要采取自监督视觉表征学习方法。
文心VIMER-CAE
过去几年里,计算机视觉里主要有两大类自监督表征学习的方法:
Masked image modeling:如上图右侧所示,Masked image modeling是最近一年在计算机视觉里关注度比较高的一种方法。该方法通过随机将图像里的一些图像块Mask处理,然后把这些Mask部分预测出来。
Context Autoencoder的特点来源于深度学习里非常重要的共识——即希望解决视觉任务在高维的隐空间里做任务。基于以上出发点,我们希望掩码部分是在高维空间里预测出来,再通过解码器得到掩码的目标。
算法实际是希望编码器只做表征学习,比如:编码器只学习可见区域的表征,剩余其他部分只做预训练任务,而不再对可见区域做表征学习任务,如此就把表征学习和任务解决区分开,使得编码器能力更强。
如上图所示,文心VIMER-CAE编码器通过对图像块进行编码,得到它的表征,利用表征进行搜索。第一个例子中,最左边对应“查询”图像块,第一行查询的是运动员腿部,可以得到运动员腿部对应的图像块。第二行查询的是胡须,可以看到搜索得到的图像基本都是和胡须相关。这是非常有意思的一件事情,因为在学习编码器的时候并没有任何标注信息,但仍然能够学到如此有意义的语义信息。
除此之外,第四行和其他四个例子是不同的。第四行实际是关于场景类,不像腿部、胡须或车灯,说明这样的方法不仅能处理object,也可以处理stuff。
我们将这个方法在公开的数据集里做了测试,如上图左侧所示方法都是基于ViT-Large,它们编码器的计算量完全一样。第一行结果使用的是有监督方法,下面四行使用的是自监督方法,可以看到,自监督的结果比有监督的结果好很多。第三、四、五行,均基于Masked image modeling方法实现,除文心VIMER-CAE外的两项工作来自于微软和Facebook。可以看到,文心VIMER-CAE无论在分类还是分割的结果都比以前的方法表现要优越。
上图右侧展示了垂类OCR场景的结果,也是标准公开数据的结果,目前这个方法已经应用落地,在手写体、通用、小度词典笔等场景中,错误率下降25%。
文心 VIMER-StrucText 2.0
最后,再给大家分享一类特殊的图像——文档图像的处理方法,这个方法也是和文心VIMER-CAE非常相关。我们知道,在文档图像中有非常多的任务,例如:识别、版式分析等,同样也需要编码器。
上图展示了文心VIMER-StrucText 2.0方法的流程图。与文心VIMER-CAE相关的地方在于,这两种方法都会把文档图像Mask掉一部分区域后,根据其他部分信息预测掩码区域的部分信息。比如说,这里面有两个任务,图像重建的任务,即直接把Mask部分图像重建出来。除此之外,还要预测Mask部分对应的文字,使得这样的方法学到的编码器,同时能够学到语义的信息,也能够得到结构的信息。
文档图像预训练,编码器学习最近几年也有不少的方法。我们做了简单的比较,大概把方法分成了三大类:
最后,与大家简单分享一下文心VIMER-StrucText 2.0方法在实际场景里的应用。如上图左侧示例所展示,这样的方法相比于StrucTexT 1.0而言,信息抽取流程能够大幅简化,不再需要依靠单独的OCR处理器输入OCR结果,使得效率至少能够提高30%。
扫码获得模型开源链接
拓展阅读:
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~