本系列根据WAVE SUMMIT 2022深度学习开发者峰会「AI大模型 智领未来」论坛嘉宾分享整理。本文整理自百度人工智能技术委员会主席、百度地图首席研发架构师黄际洲的主题演讲——“地理-语言”预训练大模型文心ERNIE-GeoL及应用。

首先介绍一下我们在实践中的一个发现,就是做好POI检索系统,需要语义与空间双轮驱动。我们以一个真实的示例为例进行说明。用户输入的查询是『三灶观音山公园』,我们返回给用户的唯一结果是位于广东珠海的『观音山郊野公园』。从文本匹配上看,这个POI的名称是“观音山郊野公园”,与用户输入的查询“观音山公园”,不仅在语义上存在一定的转义风险,而且我们还能发现这个POI地址并不含有“三灶”。如果加上空间相关性,就会发现距其7.2公里外有“三灶镇”,从语义与空间联合匹配的角度上,我们才能最终推断出用户想找的是位于广东珠海的这个名为『观音山郊野公园』的POI。
实现语义与空间的双轮驱动,其中一种可行的方案是学习并建模『地理-语言』之间的关联。第一类方法是通过有监督学习的方式,对地理信息和文本信息进行特征融合,并在特定任务中学习这两类特征之间的关系。由于这类方法往往基于有限的标注数据进行训练,所以泛化性较弱。第二类方法是通过预训练的方式,在训练过程中通过预训练任务的设计直接学习『地理-语言』之间的关联。这类方法可以利用海量未标注数据进行训练,泛化性较强。
接下来,为大家介绍一下我们全新研发的“地理-语言”跨模态预训练大模型文心ERNIE-GeoL,它主要聚焦于通过预训练的方式学习地理与语言之间的关联。
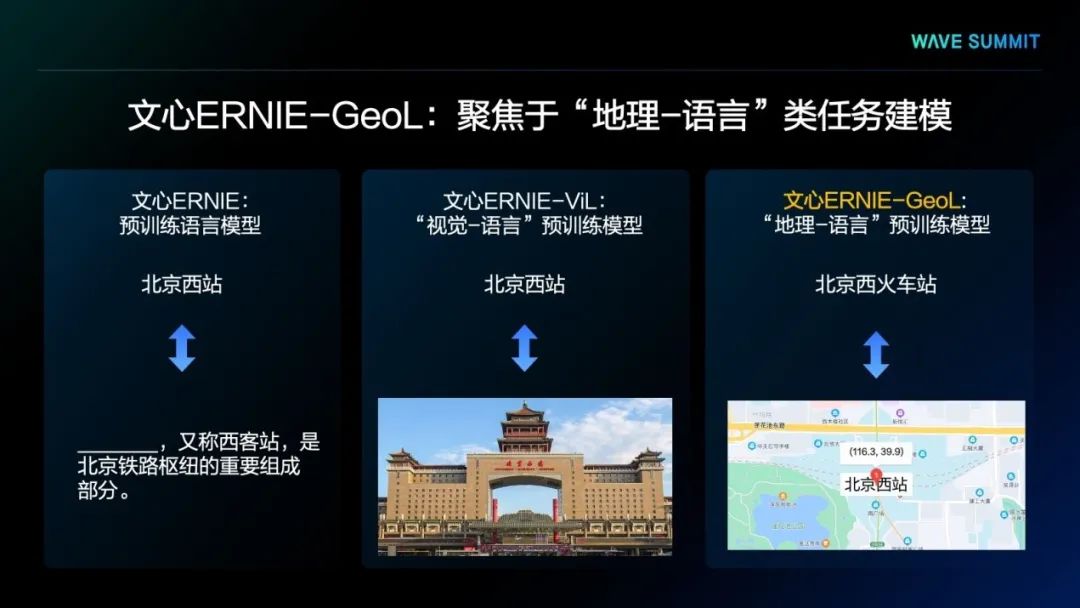
文心ERNIE-GeoL主要聚焦于“地理-语言”类任务建模。以“北京西站”为例,预训练语言模型文心ERNIE学习的是北京西站与其所在文本中的上下文之间的关联。视觉-语言预训练模型文心ERNIE-ViL学习的是北京西站与其对应图像之间的关联。而文心ERNIE-GeoL学习的则是北京西站POI的不同文本描述,例如“北京西火车站”,与其在现实世界中的地理位置之间的关联。
预训练数据构建
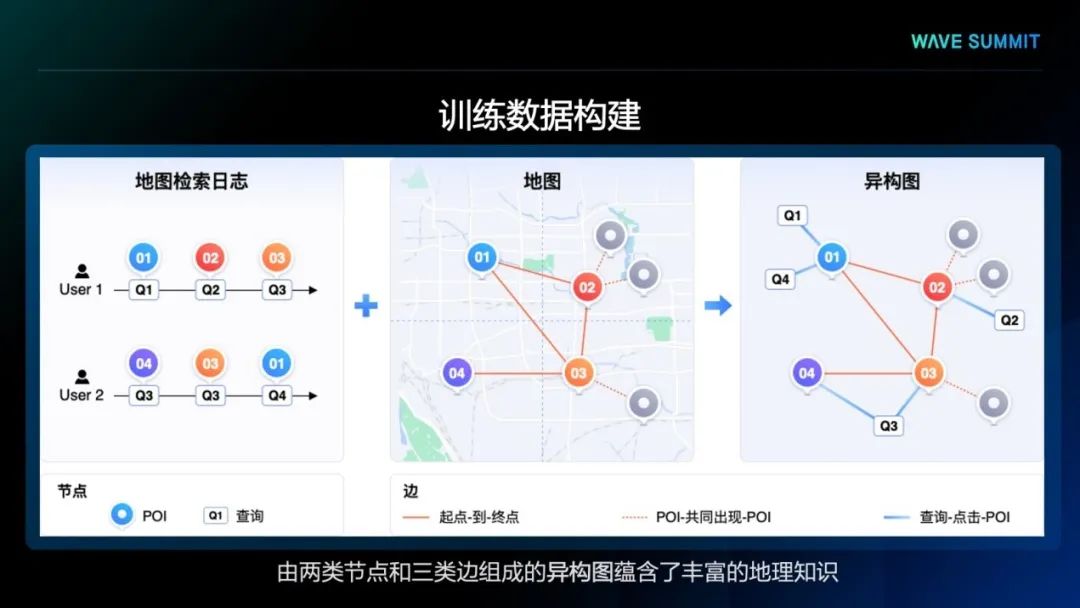
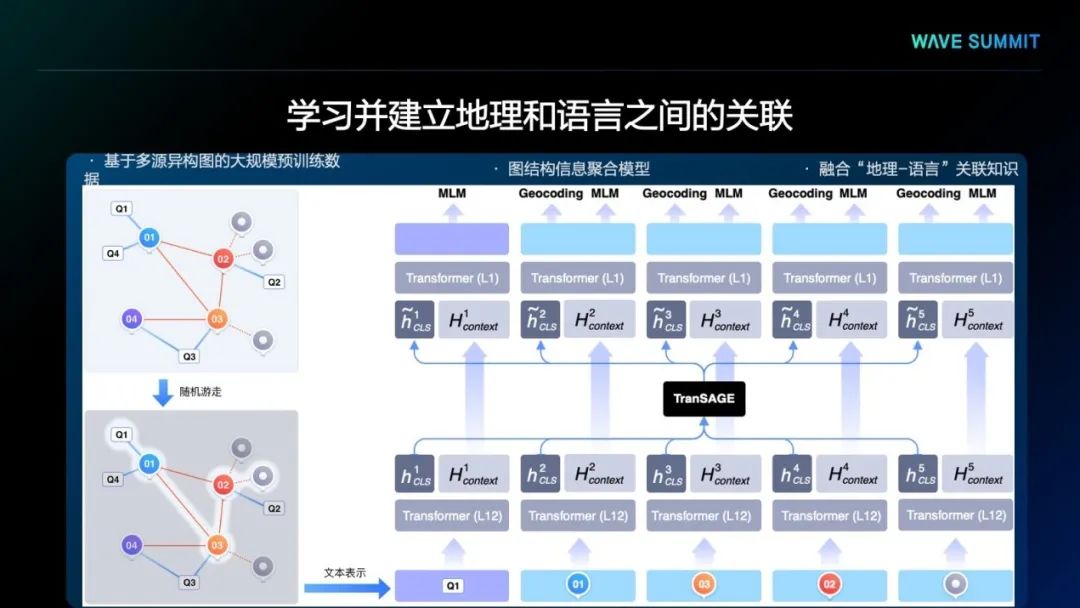
首先,文心ERNIE-GeoL以百度地图的用户搜索日志和POI数据库作为数据源,基于图桨PGL,利用其中蕴含的空间关系构建了包含了两种节点(POI和查询)和三种边的异构图。其中的三种边分别是:
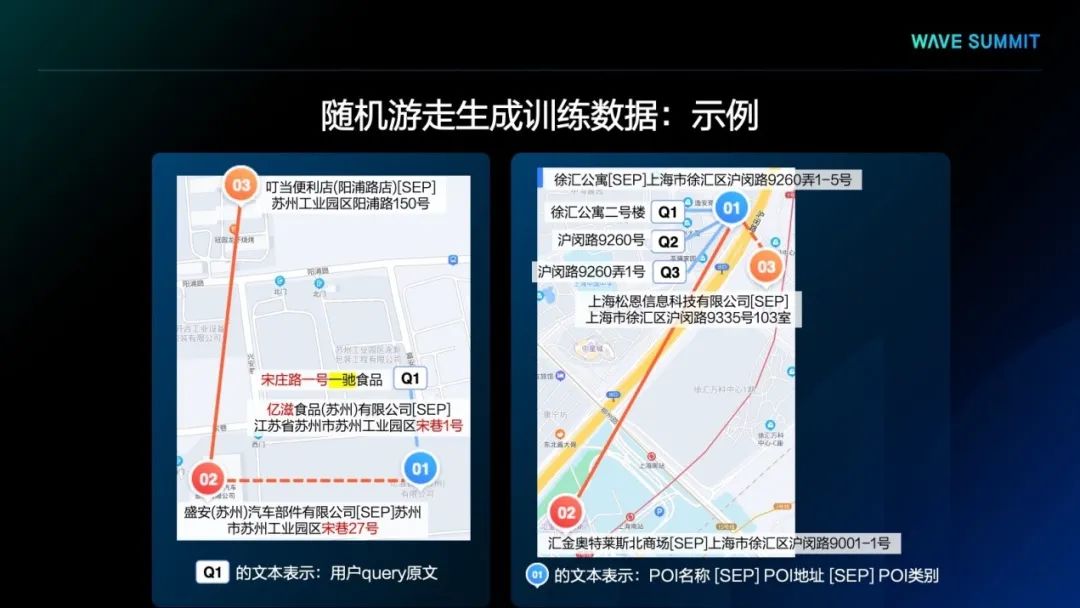
在此异构图的基础上,我们使用随机游走算法自动生成大量节点序列作为预训练数据。上图是两个真实的预训练数据示例,可以看到其中包含了丰富的地名与空间知识。通过第一个示例可以看出,用户输入的查询是“宋庄路一号一驰食品”,其中的“宋庄路一号”是“宋巷1号”的口语化表达,而“一驰食品”对应的正确POI名称是“亿滋食品”。从这类数据中,经过预训练,模型就可以学习到口语化地名描述和标准地名表述之间的关系。在第二个示例中,对于同样的POI,比如01这个POI,不管是查询1、查询2、查询3,即Q1、Q2、Q3,都是对同一POI的不同描述,经过预训练,模型就可以学习到不同文本描述与POI信息间的关系。
模型结构
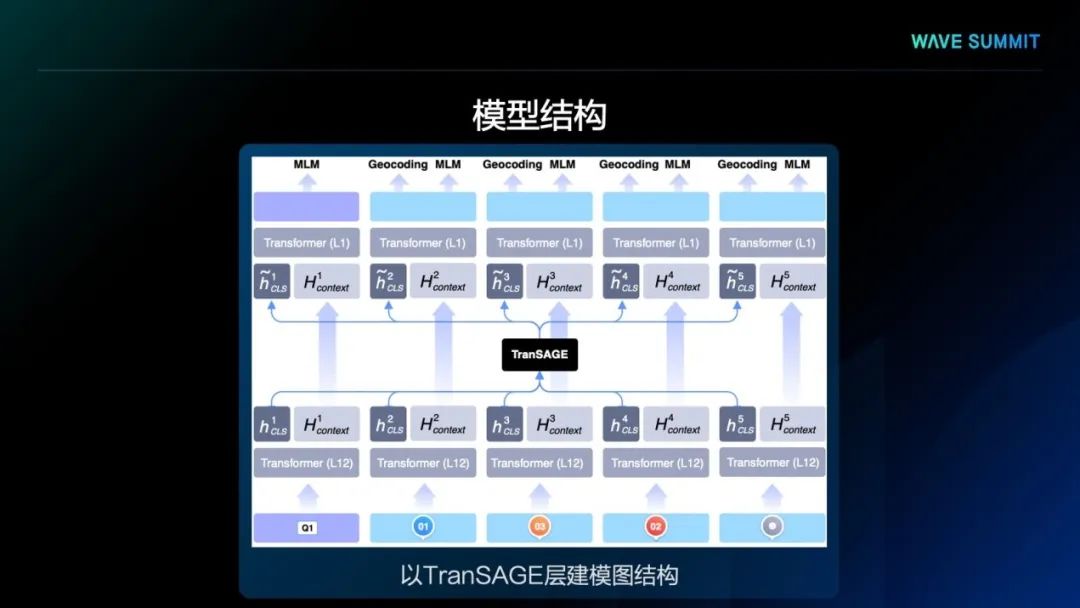
为了更有效地学习按这种方式构建的数据中蕴含的地理知识,需要对其中的图结构进行充分建模。为此,我们在设计文心ERNIE-GeoL的模型结构时,专门引入了一个TranSAGE聚合层,用于充分学习训练数据中的图结构,同时将不同模态的数据映射到统一的表示空间。
预训练目标
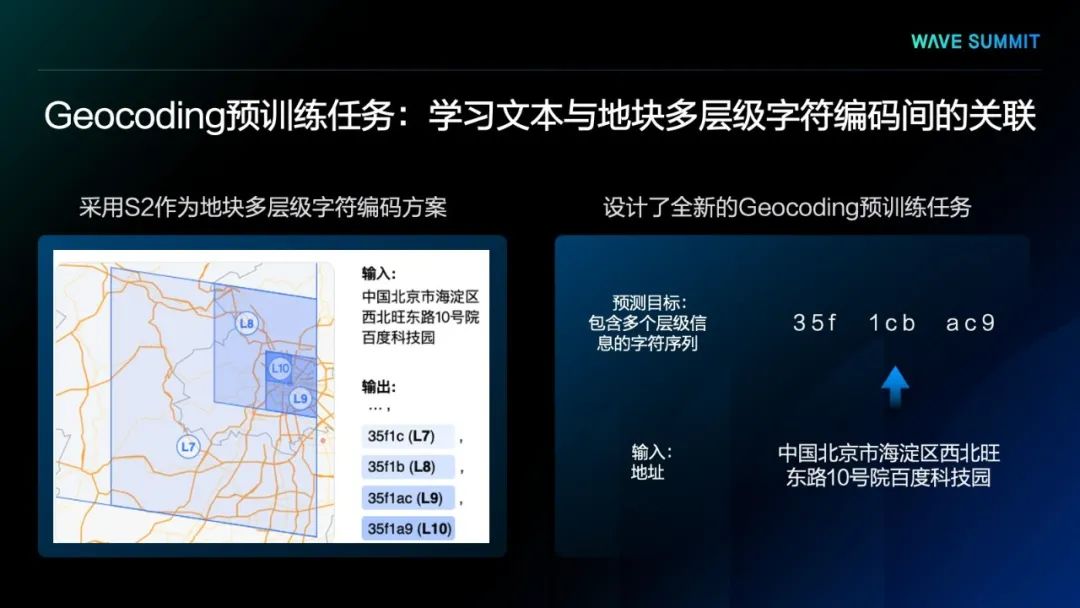
为了让模型充分学习『地理位置-语言』间的关联,我们设计了一个全新的预训练任务,用于学习文本与地理坐标关联的Geocoding预训练任务。该任务首先采用S2的方案将输入文本对应的坐标映射为多层级地块编码。随后,我们使模型按预测地块编码中每一个字符的方式,一次性地预测出多个层级的地块表示。
按这种方式,模型利用注意力机制可以学习到输入中,描述不同层级地理概念的文本和其对应的地理编码之间的映射关系,从而使模型充分且高效地学习文本与地理坐标的关联,加强模型在处理不完整或不规范地理描述文本时的鲁棒性。
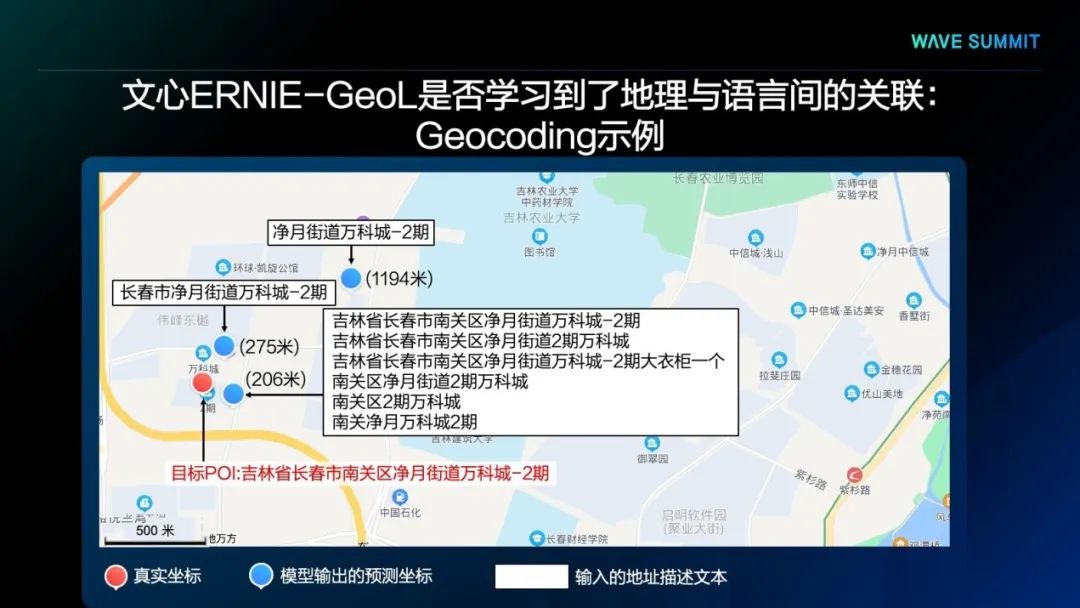
此外,我们以Geocoding任务为例,再次验证文心ERNIE-GeoL对地理-语言之间关联的学习情况,即文心ERNIE-GeoL是否能够为同一POI的各种不同描述,准确地预测出与之对应的地理坐标。上图中,该任务的输入为目标POI的不同文本描述,输出的则是模型预测出的地理坐标。从该示例中我们可以看出,文心ERNIE-GeoL具有较强的鲁棒性,可以处理关于同一地点的不同形式的文本描述,并且能够排除无关词(例如图中“大衣柜一个”)的干扰,准确地预测出与之对应的地理坐标。
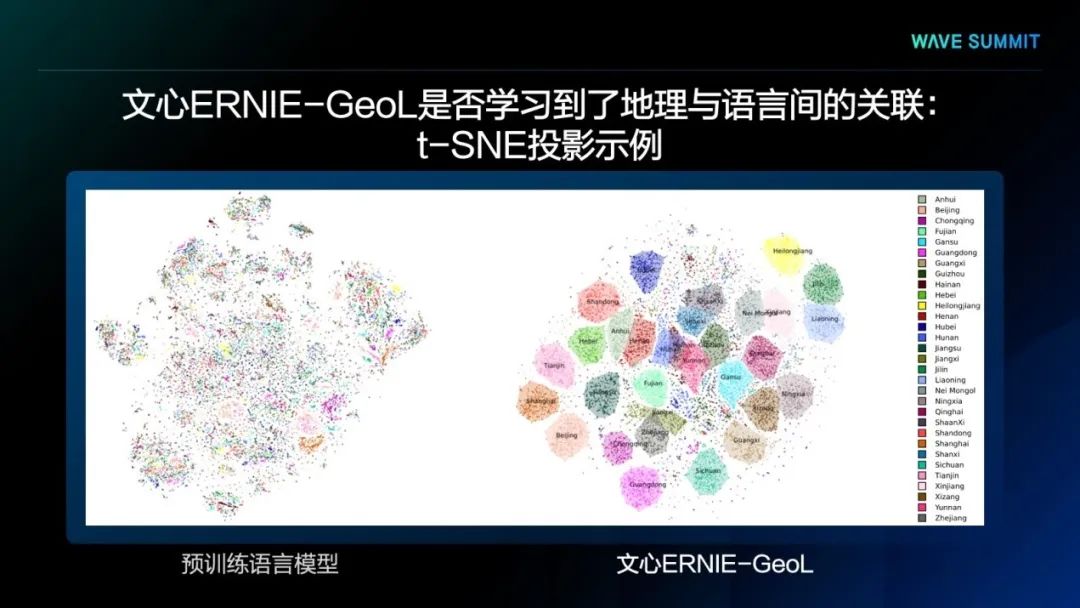
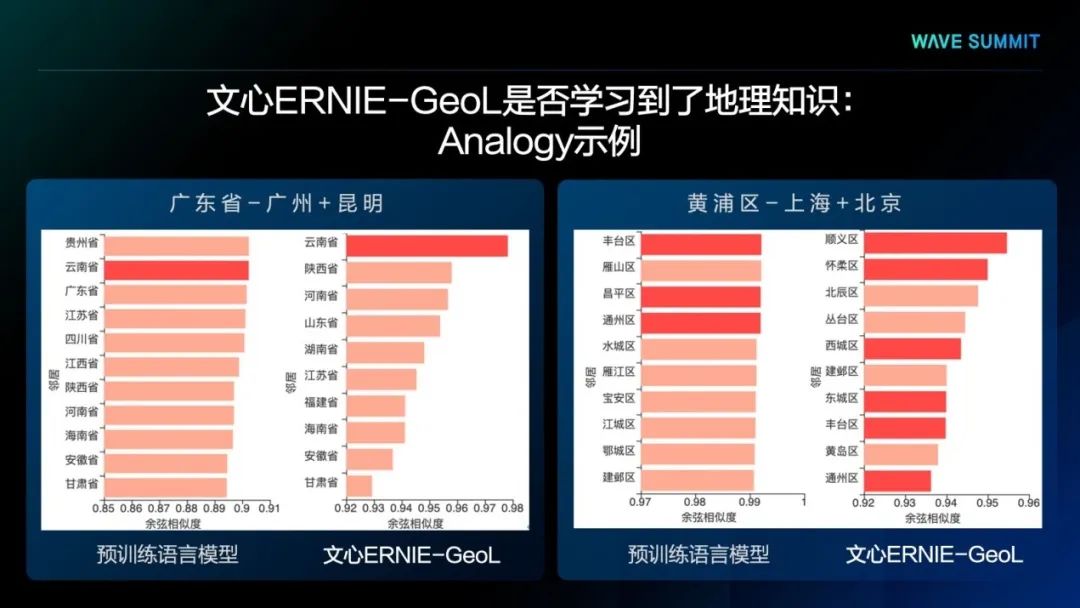
最后,借鉴著名的“king – man+woman≈queen”类比示例,我们也设计了两个类比示例来验证文心ERNIE-GeoL对于地理类比关系的学习效果。
上图左侧的示例用来测试模型是否学习到了“一个省的省会”的关系。在该测试中,查询设置为“广东省-广州+昆明”,候选设置为所有中国省级行政单位的名称。从图中的结果可以看出,文心ERNIE-GeoL以最高的相似度得分输出了正确的目标省份“云南省”。上图右侧的示例用来测试模型是否学习到了“一个城市的下级行政区划”的关系。我们首先将查询设置为“黄埔区-上海+北京”,候选设置为所有中国城市的下级区域名称。然后用预训练模型将查询和候选分别表示为向量并计算各个候选向量和查询向量之间的余弦相似度。从中可以看出,在排名前10的候选中,文心ERNIE-GeoL召回的正确区域比预训练语言模型多出一倍。此外,在这两幅图中,与文心ERNIE-GeoL预测的结果相比,预训练语言模型的预测结果之间的区分度较低。
上述两个定性分析的结果表明,在省会关系和城市区划关系的类比中,文心ERNIE-GeoL的预测和召回更好,结果区分度更高。这也表明文心ERNIE-GeoL在一定程度上学会了不同地理实体之间的空间关系和语义关系。
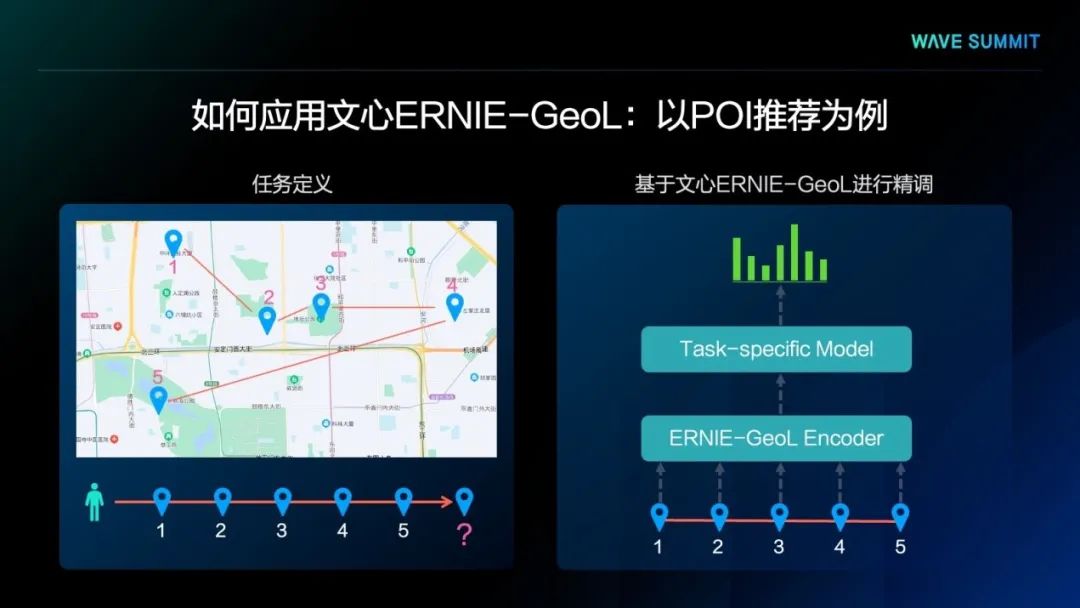
文心ERNIE-GeoL
应用效果
文心ERNIE-GeoL已经在百度地图的业务中广泛应用落地,大幅提升了业务效果。下面介绍它在百度地图一些业务中的实际应用效果。
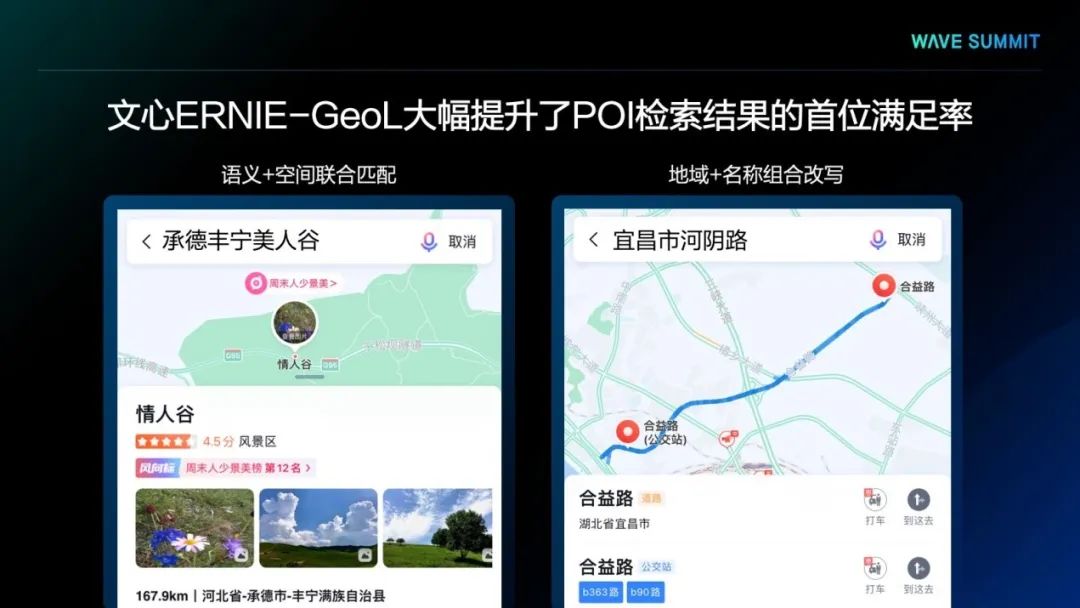
首先,应用文心ERNIE-GeoL后,POI检索结果的首位满足率得到了显著提升,下面是两个典型的例子。在左边的示例中,用户搜索的是承德丰宁美人谷,而承德丰宁在现实世界中只有一个情人谷,并没有美人谷,通过使用文心ERNIE-GeoL,POI检索模型获得了更强的语义+空间联合匹配的能力,从而将用户实际想去的情人谷作为唯一结果在首位返回。而在右边的例子中,用户搜索的是“宜昌市河阴路”。分开来看,宜昌市与河阴路都真实存在于现实世界,但是在宜昌市却没有河阴路。通过使用文心ERNIE-GeoL,业务模型获得了地域+名称组合改写的能力,可以将“河阴路”纠错成“合益路”,并将该结果在首位返回给用户。
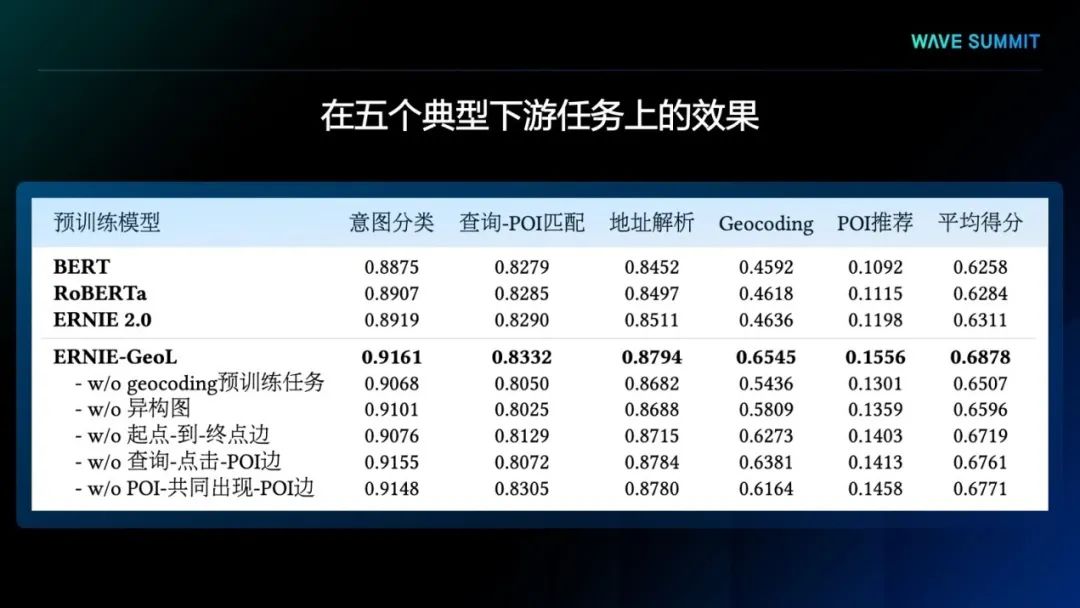
其次,文心ERNIE-GeoL也大幅提升了地址解析和Geocoding等地理位置相关任务的效果。与之前效果已经很好的基线模型相比,应用文心ERNIE-GeoL后,这两个任务的效果都绝对提升了5%。从表格中给出的3个真实例子中可以看出,对于复杂的地址输入,经文心ERNIE-GeoL精调的模型不仅可以完全正确地将地址中的成分进行解析,还可以通过细粒度的标签设置,对地址中多个POI的位置关系进行解析。例如西旁、旁边、对面等文字会被识别成方位辅助描述用词。同时该地址解析模型也可以将文本中与地址无关的成分进行准确解析。例如第三个例子中的『最好用中通快递谢谢』。我们还可以看出,经文心ERNIE-GeoL精调的Geocoding模型可以准确识别地址中要定位的真正POI。例如第一个示例中有两个POI,模型选择了正确的POI进行坐标预测。此外,该模型还能够将不规范的POI描述与定位基准POI进行准确关联,例如在第二个例子中,『小馋嘴快递代收便利店』可以被准确地定位到『小馋嘴零食便利店』。
为了更好地满足智慧物流、智慧城市等合作伙伴对地址解析的高准确率需求,百度地图开放平台现已提供GC ERNIE-GeoL版,欢迎扫描下方二维码使用!

相关阅读:
扫码关注服务号 获取更多大模型精彩资讯

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
本系列根据WAVE SUMMIT 2022深度学习开发者峰会「AI大模型 智领未来」论坛嘉宾分享整理。本文整理自百度人工智能技术委员会主席、百度地图首席研发架构师黄际洲的主题演讲——“地理-语言”预训练大模型文心ERNIE-GeoL及应用。
首先介绍一下我们在实践中的一个发现,就是做好POI检索系统,需要语义与空间双轮驱动。我们以一个真实的示例为例进行说明。用户输入的查询是『三灶观音山公园』,我们返回给用户的唯一结果是位于广东珠海的『观音山郊野公园』。从文本匹配上看,这个POI的名称是“观音山郊野公园”,与用户输入的查询“观音山公园”,不仅在语义上存在一定的转义风险,而且我们还能发现这个POI地址并不含有“三灶”。如果加上空间相关性,就会发现距其7.2公里外有“三灶镇”,从语义与空间联合匹配的角度上,我们才能最终推断出用户想找的是位于广东珠海的这个名为『观音山郊野公园』的POI。
实现语义与空间的双轮驱动,其中一种可行的方案是学习并建模『地理-语言』之间的关联。第一类方法是通过有监督学习的方式,对地理信息和文本信息进行特征融合,并在特定任务中学习这两类特征之间的关系。由于这类方法往往基于有限的标注数据进行训练,所以泛化性较弱。第二类方法是通过预训练的方式,在训练过程中通过预训练任务的设计直接学习『地理-语言』之间的关联。这类方法可以利用海量未标注数据进行训练,泛化性较强。
接下来,为大家介绍一下我们全新研发的“地理-语言”跨模态预训练大模型文心ERNIE-GeoL,它主要聚焦于通过预训练的方式学习地理与语言之间的关联。
文心ERNIE-GeoL主要聚焦于“地理-语言”类任务建模。以“北京西站”为例,预训练语言模型文心ERNIE学习的是北京西站与其所在文本中的上下文之间的关联。视觉-语言预训练模型文心ERNIE-ViL学习的是北京西站与其对应图像之间的关联。而文心ERNIE-GeoL学习的则是北京西站POI的不同文本描述,例如“北京西火车站”,与其在现实世界中的地理位置之间的关联。
预训练数据构建
首先,文心ERNIE-GeoL以百度地图的用户搜索日志和POI数据库作为数据源,基于图桨PGL,利用其中蕴含的空间关系构建了包含了两种节点(POI和查询)和三种边的异构图。其中的三种边分别是:
在此异构图的基础上,我们使用随机游走算法自动生成大量节点序列作为预训练数据。上图是两个真实的预训练数据示例,可以看到其中包含了丰富的地名与空间知识。通过第一个示例可以看出,用户输入的查询是“宋庄路一号一驰食品”,其中的“宋庄路一号”是“宋巷1号”的口语化表达,而“一驰食品”对应的正确POI名称是“亿滋食品”。从这类数据中,经过预训练,模型就可以学习到口语化地名描述和标准地名表述之间的关系。在第二个示例中,对于同样的POI,比如01这个POI,不管是查询1、查询2、查询3,即Q1、Q2、Q3,都是对同一POI的不同描述,经过预训练,模型就可以学习到不同文本描述与POI信息间的关系。
模型结构
为了更有效地学习按这种方式构建的数据中蕴含的地理知识,需要对其中的图结构进行充分建模。为此,我们在设计文心ERNIE-GeoL的模型结构时,专门引入了一个TranSAGE聚合层,用于充分学习训练数据中的图结构,同时将不同模态的数据映射到统一的表示空间。
预训练目标
为了让模型充分学习『地理位置-语言』间的关联,我们设计了一个全新的预训练任务,用于学习文本与地理坐标关联的Geocoding预训练任务。该任务首先采用S2的方案将输入文本对应的坐标映射为多层级地块编码。随后,我们使模型按预测地块编码中每一个字符的方式,一次性地预测出多个层级的地块表示。
按这种方式,模型利用注意力机制可以学习到输入中,描述不同层级地理概念的文本和其对应的地理编码之间的映射关系,从而使模型充分且高效地学习文本与地理坐标的关联,加强模型在处理不完整或不规范地理描述文本时的鲁棒性。
此外,我们以Geocoding任务为例,再次验证文心ERNIE-GeoL对地理-语言之间关联的学习情况,即文心ERNIE-GeoL是否能够为同一POI的各种不同描述,准确地预测出与之对应的地理坐标。上图中,该任务的输入为目标POI的不同文本描述,输出的则是模型预测出的地理坐标。从该示例中我们可以看出,文心ERNIE-GeoL具有较强的鲁棒性,可以处理关于同一地点的不同形式的文本描述,并且能够排除无关词(例如图中“大衣柜一个”)的干扰,准确地预测出与之对应的地理坐标。
最后,借鉴著名的“king – man+woman≈queen”类比示例,我们也设计了两个类比示例来验证文心ERNIE-GeoL对于地理类比关系的学习效果。
上图左侧的示例用来测试模型是否学习到了“一个省的省会”的关系。在该测试中,查询设置为“广东省-广州+昆明”,候选设置为所有中国省级行政单位的名称。从图中的结果可以看出,文心ERNIE-GeoL以最高的相似度得分输出了正确的目标省份“云南省”。上图右侧的示例用来测试模型是否学习到了“一个城市的下级行政区划”的关系。我们首先将查询设置为“黄埔区-上海+北京”,候选设置为所有中国城市的下级区域名称。然后用预训练模型将查询和候选分别表示为向量并计算各个候选向量和查询向量之间的余弦相似度。从中可以看出,在排名前10的候选中,文心ERNIE-GeoL召回的正确区域比预训练语言模型多出一倍。此外,在这两幅图中,与文心ERNIE-GeoL预测的结果相比,预训练语言模型的预测结果之间的区分度较低。
上述两个定性分析的结果表明,在省会关系和城市区划关系的类比中,文心ERNIE-GeoL的预测和召回更好,结果区分度更高。这也表明文心ERNIE-GeoL在一定程度上学会了不同地理实体之间的空间关系和语义关系。
文心ERNIE-GeoL
应用效果
文心ERNIE-GeoL已经在百度地图的业务中广泛应用落地,大幅提升了业务效果。下面介绍它在百度地图一些业务中的实际应用效果。
首先,应用文心ERNIE-GeoL后,POI检索结果的首位满足率得到了显著提升,下面是两个典型的例子。在左边的示例中,用户搜索的是承德丰宁美人谷,而承德丰宁在现实世界中只有一个情人谷,并没有美人谷,通过使用文心ERNIE-GeoL,POI检索模型获得了更强的语义+空间联合匹配的能力,从而将用户实际想去的情人谷作为唯一结果在首位返回。而在右边的例子中,用户搜索的是“宜昌市河阴路”。分开来看,宜昌市与河阴路都真实存在于现实世界,但是在宜昌市却没有河阴路。通过使用文心ERNIE-GeoL,业务模型获得了地域+名称组合改写的能力,可以将“河阴路”纠错成“合益路”,并将该结果在首位返回给用户。
其次,文心ERNIE-GeoL也大幅提升了地址解析和Geocoding等地理位置相关任务的效果。与之前效果已经很好的基线模型相比,应用文心ERNIE-GeoL后,这两个任务的效果都绝对提升了5%。从表格中给出的3个真实例子中可以看出,对于复杂的地址输入,经文心ERNIE-GeoL精调的模型不仅可以完全正确地将地址中的成分进行解析,还可以通过细粒度的标签设置,对地址中多个POI的位置关系进行解析。例如西旁、旁边、对面等文字会被识别成方位辅助描述用词。同时该地址解析模型也可以将文本中与地址无关的成分进行准确解析。例如第三个例子中的『最好用中通快递谢谢』。我们还可以看出,经文心ERNIE-GeoL精调的Geocoding模型可以准确识别地址中要定位的真正POI。例如第一个示例中有两个POI,模型选择了正确的POI进行坐标预测。此外,该模型还能够将不规范的POI描述与定位基准POI进行准确关联,例如在第二个例子中,『小馋嘴快递代收便利店』可以被准确地定位到『小馋嘴零食便利店』。
为了更好地满足智慧物流、智慧城市等合作伙伴对地址解析的高准确率需求,百度地图开放平台现已提供GC ERNIE-GeoL版,欢迎扫描下方二维码使用!
相关阅读:
扫码关注服务号 获取更多大模型精彩资讯
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~