2021年7月15日,DeepMind公司在Nature杂志上发表了题为"Highly accurate protein structure prediction with AlphaFold"的文章,系统介绍了一种端到端的从蛋白质序列预测蛋白质三维结构的神经网络算法—AlphaFold2。该算法预测的蛋白质结构能达到原子水平的准确度,被Science评选为2021年十大科学突破之首。虽然DeepMind公司开源了AlphaFold2推理代码,但是其训练代码一直未开源。从DeepMind公司发表的AlphaFold2论文看,完整从头训练AlphaFold2需要使用128张TPUv3训练11天,对计算资源的消耗是巨大的。科研机构和普通公司想要基于AlphaFold2探索解决蛋白领域的更多问题,例如蛋白质设计,新靶点发现等,也更加困难。因此,如何搭建一套性能更优、更加节省算力资源、支持适配国产硬件的蛋白结构预测模型,就成为亟待解决的问题。
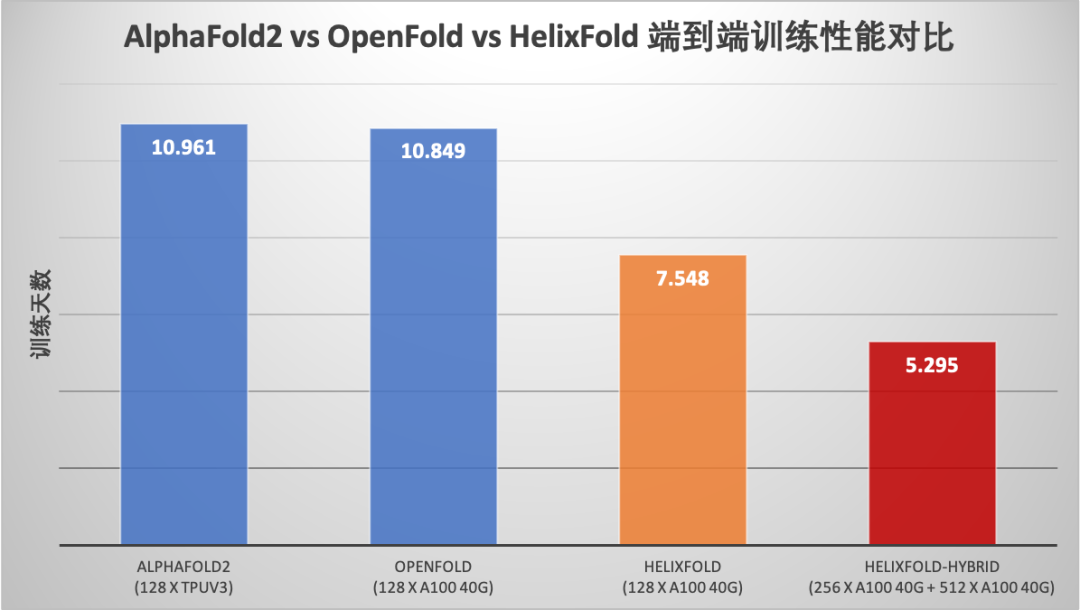
在飞桨强大的高性能并行计算能力支持下,飞桨螺旋桨PaddleHelix 生物计算团队发布了蛋白结构预测模型HelixFold,围绕着显存峰值、训练速度、分布式策略进行了全面性能优化。通过与原版AlphaFold2模型和哥伦比亚大学Mohammed AlQuraishi 教授团队基于PyTorch复现的OpenFold模型的性能对比测试显示,HelixFold模型的训练性能相比AlphaFold2提升106.97%,相比 OpenFold 提升104.86%。
HelixFold 与AlphaFold2、OpenFold 端到端训练速度对比
HelixFold 之所以能够得到如此大的性能提升,源于如下几项技术创新:
分支并行与混合并行策略
AlphaFold2在使用 TPUv3训练模型时,每张卡上的 batch size只设置为 1,限制了数据样本维度扩卡加速训练的可能性。HelixFold创新性的提出分支并行(Branch Parallelism, BP)策略,将不同的网络模型分支放在不同的卡上并行计算,从而在 initial training 阶段大幅提高了模型并行效率和训练速度。并且,分支并行与已有的动态轴并行 (Dynamic Axial Parallelism, DAP) 和数据并行(Data Parallelism, DP) 结合使用,通过 BP-DAP-DP 三维混合并行,进一步加快了模型的整体训练速度。
算子融合优化技术和张量融合低频次访存技术
多维度显存优化方案
在性能大幅度提升的同时,HelixFold 从头端到端完整训练可以达到 AlphaFold2论文媲美的精度。在包含87个蛋白的CASP14数据集和包含371个蛋白的CAMEO数据集上,HelixFold模型 TM-score 指标分别达到0.8771和0.8885,与原版 AlphaFold2准确率相当甚至更优。
GitHub地址:https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold
更多性能优化细节和数据分析参考技术报告:
HelixFold: An Efficient Implementation of AlphaFold2 using PaddlePaddle
https://arxiv.org/abs/2207.05477
拓展阅读:

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
2021年7月15日,DeepMind公司在Nature杂志上发表了题为"Highly accurate protein structure prediction with AlphaFold"的文章,系统介绍了一种端到端的从蛋白质序列预测蛋白质三维结构的神经网络算法—AlphaFold2。该算法预测的蛋白质结构能达到原子水平的准确度,被Science评选为2021年十大科学突破之首。虽然DeepMind公司开源了AlphaFold2推理代码,但是其训练代码一直未开源。从DeepMind公司发表的AlphaFold2论文看,完整从头训练AlphaFold2需要使用128张TPUv3训练11天,对计算资源的消耗是巨大的。科研机构和普通公司想要基于AlphaFold2探索解决蛋白领域的更多问题,例如蛋白质设计,新靶点发现等,也更加困难。因此,如何搭建一套性能更优、更加节省算力资源、支持适配国产硬件的蛋白结构预测模型,就成为亟待解决的问题。
在飞桨强大的高性能并行计算能力支持下,飞桨螺旋桨PaddleHelix 生物计算团队发布了蛋白结构预测模型HelixFold,围绕着显存峰值、训练速度、分布式策略进行了全面性能优化。通过与原版AlphaFold2模型和哥伦比亚大学Mohammed AlQuraishi 教授团队基于PyTorch复现的OpenFold模型的性能对比测试显示,HelixFold模型的训练性能相比AlphaFold2提升106.97%,相比 OpenFold 提升104.86%。
HelixFold 与AlphaFold2、OpenFold 端到端训练速度对比
HelixFold 之所以能够得到如此大的性能提升,源于如下几项技术创新:
分支并行与混合并行策略
AlphaFold2在使用 TPUv3训练模型时,每张卡上的 batch size只设置为 1,限制了数据样本维度扩卡加速训练的可能性。HelixFold创新性的提出分支并行(Branch Parallelism, BP)策略,将不同的网络模型分支放在不同的卡上并行计算,从而在 initial training 阶段大幅提高了模型并行效率和训练速度。并且,分支并行与已有的动态轴并行 (Dynamic Axial Parallelism, DAP) 和数据并行(Data Parallelism, DP) 结合使用,通过 BP-DAP-DP 三维混合并行,进一步加快了模型的整体训练速度。
算子融合优化技术和张量融合低频次访存技术
多维度显存优化方案
在性能大幅度提升的同时,HelixFold 从头端到端完整训练可以达到 AlphaFold2论文媲美的精度。在包含87个蛋白的CASP14数据集和包含371个蛋白的CAMEO数据集上,HelixFold模型 TM-score 指标分别达到0.8771和0.8885,与原版 AlphaFold2准确率相当甚至更优。
GitHub地址:https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold
更多性能优化细节和数据分析参考技术报告:
HelixFold: An Efficient Implementation of AlphaFold2 using PaddlePaddle
https://arxiv.org/abs/2207.05477
拓展阅读:
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~