自2018年以来,BERT、ERNIE、GPT等大规模预训练模型快速发展,在NLP、多模态、生物医学领域取得了巨大突破。超大预训练模型的参数规模从十亿、百亿扩展到千亿、万亿,模型大小突破单卡显存,甚至单机多卡显存限制。大模型具备标注数据更少、模型效果更优、创造能力更强和灵活定制场景等优势。因此,如何将超大预训练模型在生产环境中全量部署,并获得完整的模型效果,成为了业界关注的焦点。
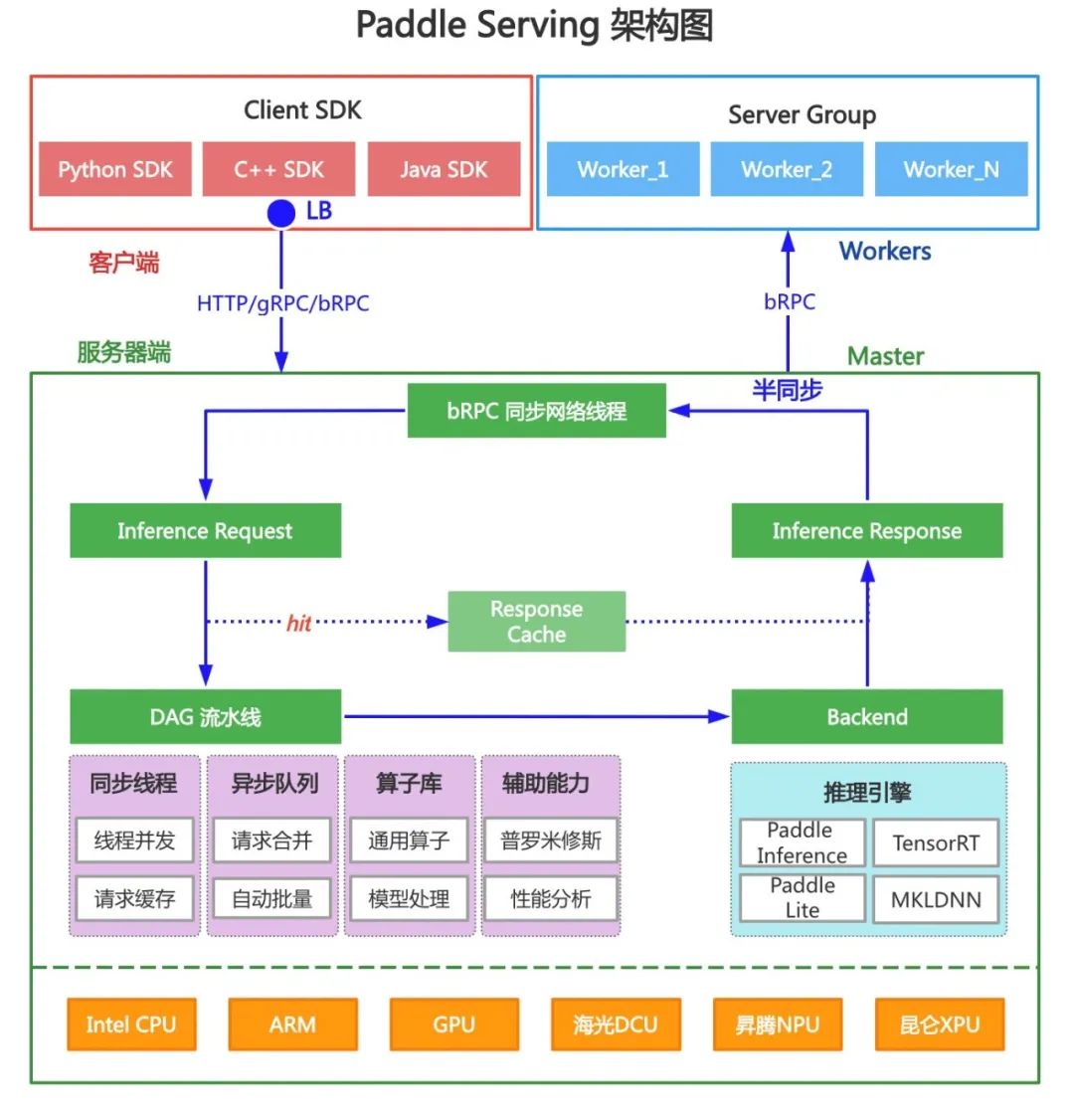
Paddle Serving作为飞桨(PaddlePaddle)开源的服务化部署框架,为了更好解决超大预训练模型在生产环境中全量部署,发布v0.9.0版本——多机多卡分布式推理框架。支持自然语言理解、对话、跨模态生成等大不同种类的大模型结构,实现高速推理,让大模型真正落成应用。
旸谷社区——百度新发布基于文心大模型的创意社区,是Paddle Serving落地的一个典型应用。旸谷社区采用Paddle Serving分布式推理框架部署百亿、千亿级参数超大模型,在该社区成功部署上线了百度自研的4个大模型(智能作画『人人都是艺术家』、智能对话『AI聊吧』、智能创作『歌词生成』和故事生成『AI造梦师』),大模型产业级应用已启动。
左右滑动扫码体验
解决单卡显存瓶颈
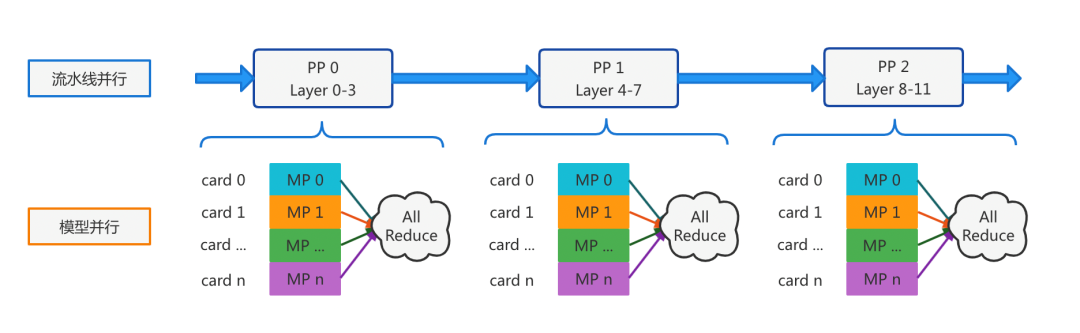
针对大模型占用显存量超过GPU单卡显存上限,甚至超过单机多卡显存上限的问题,借鉴分布式训练中模型并行、流水线并行技术,将大模型结构切分成多个子图,每个子图所占显存不超过单卡显存上限,将Tensor计算和不同层计算切分到多个GPU卡上,并插入集合通讯算子实现子图间参数同步。因此,大模型推理计算演绎成基于子图拓扑的多机多卡分布式推理。
下移子图拓扑到推理引擎层
通过以上的改进,新框架推理的模型规模越大性能提升越明显,与原方案相比,推理千亿参数ERNIE模型耗时下降70%。
提升服务并发吞吐
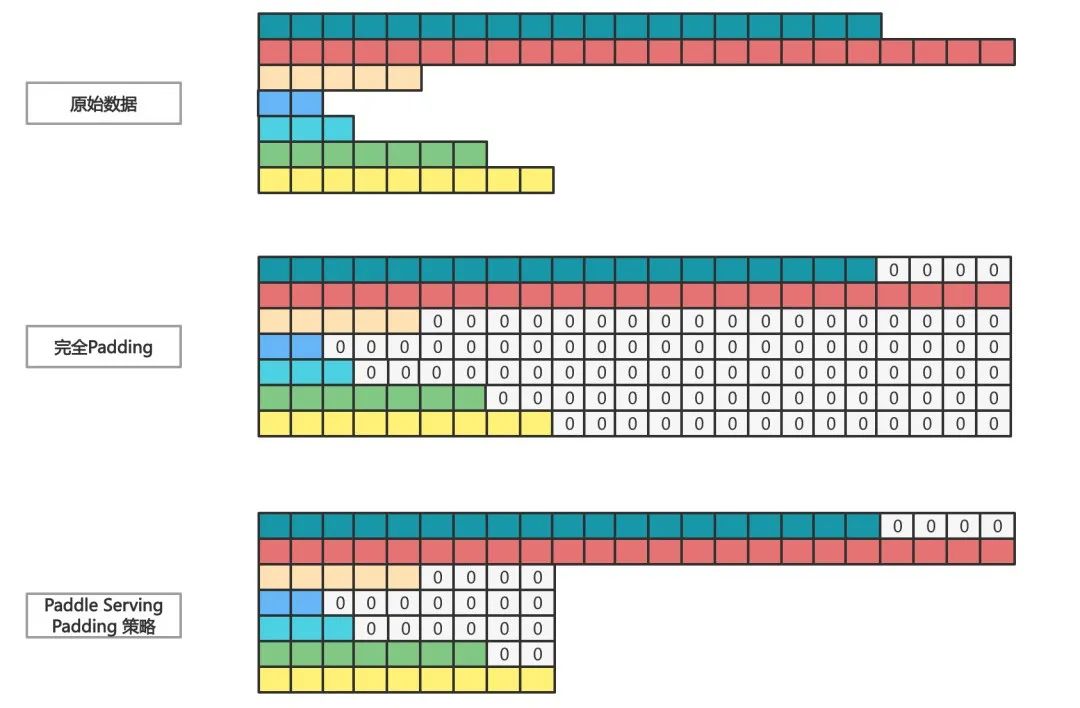
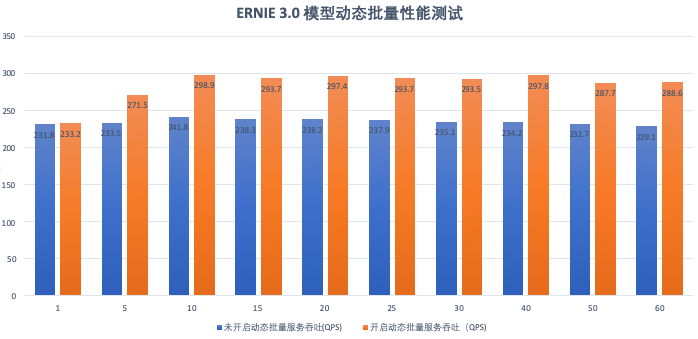
通常,大模型分布式推理优化技术包括动态批量、低精度fp16、TensorRT加速、fused优化和显存Cache等,Paddle Serving不仅采用了这些优化方法,同时也做了改进升级。例如动态批量技术在多个服务化推理框架中均有实现,原理是将多个请求shape维度相同但数值不同的Tensor自动Padding补0对齐,合并成一个大矩阵批量推理,充分利用GPU Kernel多Block、多线程特性,提升计算吞吐。
Paddle Serving动态批量技术的不同之处有2点。
第一,实现复杂的二维变长Tensor自动批量,如Transformer模型结构输入参数有二维变长Tensor。
策略1:评估数据绝对长度的差值,当两批数据长度的绝对值差的字节数小于1024字节时(可配置),自动Padding补齐后合并Batch。
策略2:评估数据的相似度,以两组数据Shape各个维度的乘积作为相似度,当相似度大于50%(可配置),自动Padding补齐后合并Batch。
异常处理
大模型部署面临的异常问题有3个:硬件故障、网络异常、服务异常等。整体异常处理预案如下:
单机网络异常:服务实例迁移
Master与Worker之间链接异常:采用短链接,半同步以及异常检测。
健康状态检查:定时端口检测&预测结果检测
服务夯住/挂掉:服务重启&supervise拉起
Benchmark
8*A100-SXM4-40GB, 160 core Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz, 10000Gbps network
总结
Paddle Serving多机多卡分布式推理方案有良好的通用性和扩展性,能广泛支持不同种类的模型结构,实现高速推理,目前已支撑了如自然语言理解、对话、跨模态生成等大模型的实时在线应用。使用该方案实现大规模服务化部署,让大模型真正落成应用。
部署方案
线上部署
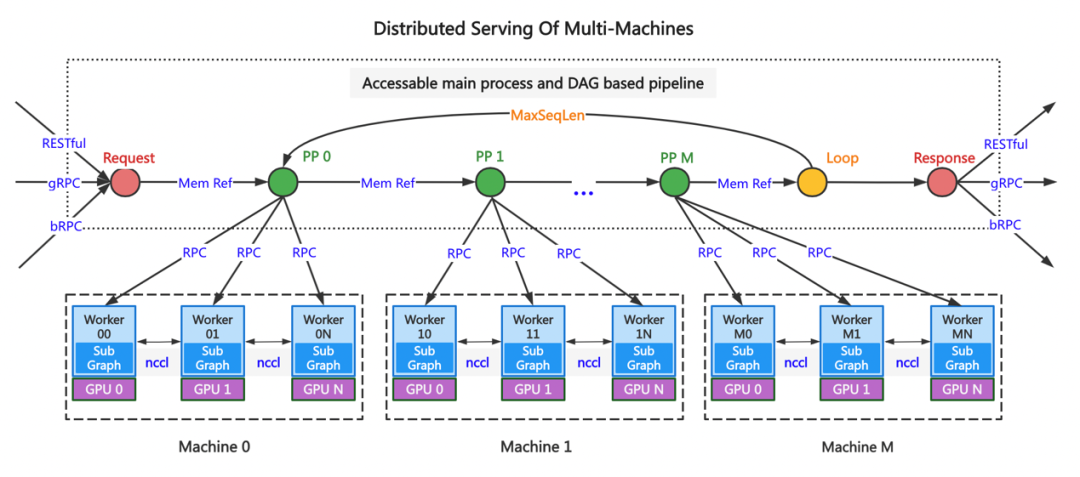
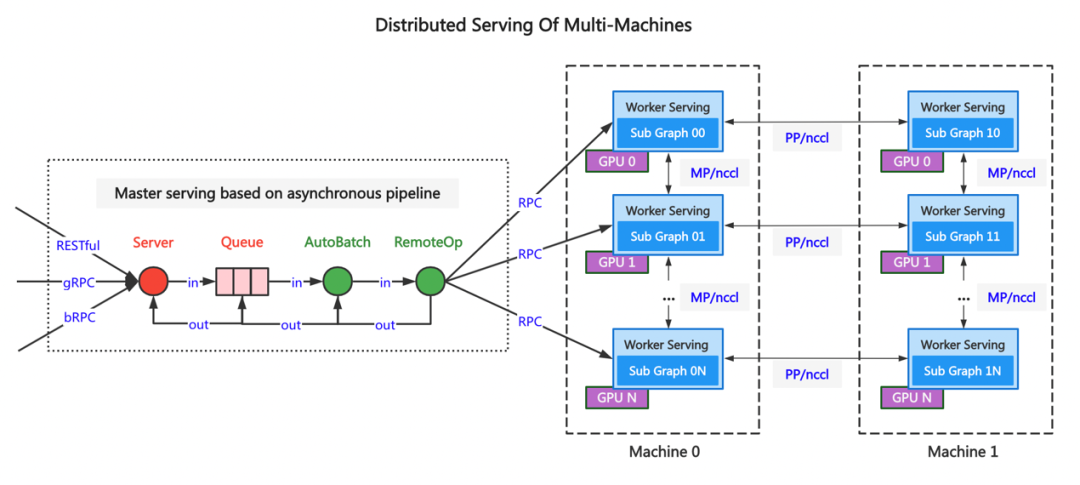
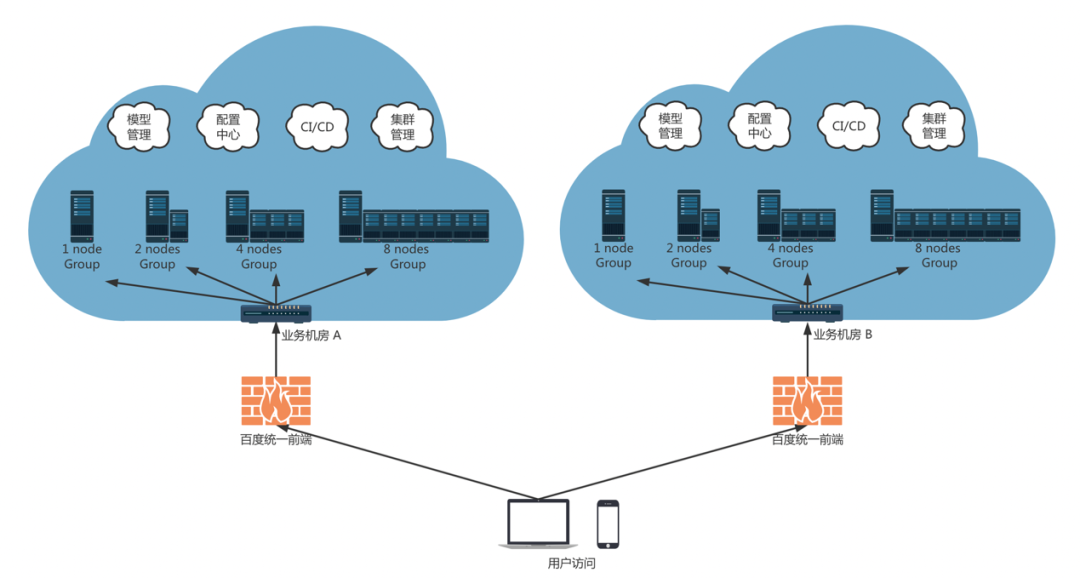
在2022WAVE SUMMIT 2022深度学习开发者峰会期间,文心大模型旸谷社区的大模型应用采用Paddle Serving分布式推理框架部署上线,为大模型大规模应用奠定了基础。Paddle Serving多机多卡分布式推理框架的整体部署方案设计复杂,多地多中心、多机多卡组合、多级负载均衡、流量调度和异常故障处理等。整体部署思路如下图所示,与常规服务化部署的差异在于构建分布式部署的结构化思路。
部署案例
⭐ 点击阅读原文获得 ⭐
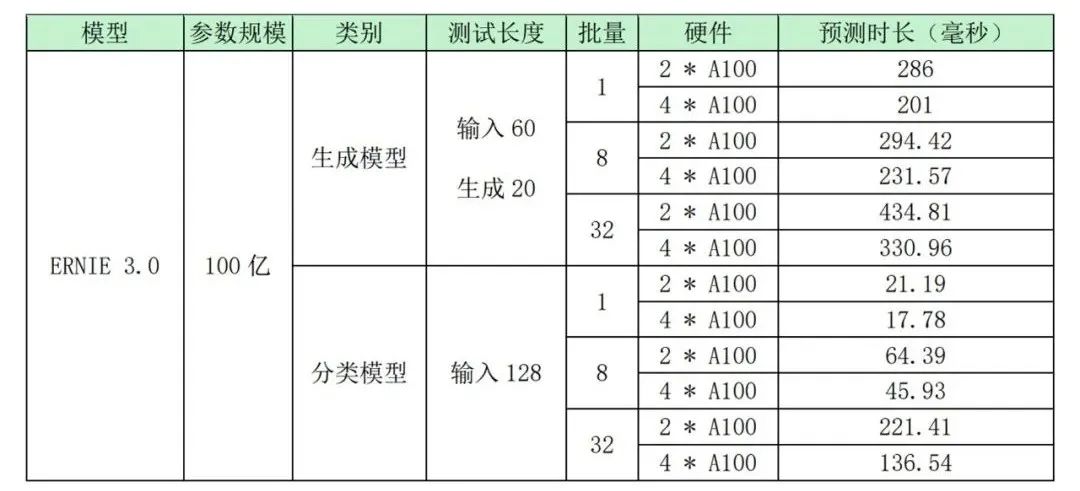
ERNIE 3.0百亿参数模型部署案例
知识问答任务示例
更多阅读
走进官网
Paddle Serving官网:
飞桨文心大模型官网:
加入社群

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
自2018年以来,BERT、ERNIE、GPT等大规模预训练模型快速发展,在NLP、多模态、生物医学领域取得了巨大突破。超大预训练模型的参数规模从十亿、百亿扩展到千亿、万亿,模型大小突破单卡显存,甚至单机多卡显存限制。大模型具备标注数据更少、模型效果更优、创造能力更强和灵活定制场景等优势。因此,如何将超大预训练模型在生产环境中全量部署,并获得完整的模型效果,成为了业界关注的焦点。
Paddle Serving作为飞桨(PaddlePaddle)开源的服务化部署框架,为了更好解决超大预训练模型在生产环境中全量部署,发布v0.9.0版本——多机多卡分布式推理框架。支持自然语言理解、对话、跨模态生成等大不同种类的大模型结构,实现高速推理,让大模型真正落成应用。
旸谷社区——百度新发布基于文心大模型的创意社区,是Paddle Serving落地的一个典型应用。旸谷社区采用Paddle Serving分布式推理框架部署百亿、千亿级参数超大模型,在该社区成功部署上线了百度自研的4个大模型(智能作画『人人都是艺术家』、智能对话『AI聊吧』、智能创作『歌词生成』和故事生成『AI造梦师』),大模型产业级应用已启动。
左右滑动扫码体验
解决单卡显存瓶颈
针对大模型占用显存量超过GPU单卡显存上限,甚至超过单机多卡显存上限的问题,借鉴分布式训练中模型并行、流水线并行技术,将大模型结构切分成多个子图,每个子图所占显存不超过单卡显存上限,将Tensor计算和不同层计算切分到多个GPU卡上,并插入集合通讯算子实现子图间参数同步。因此,大模型推理计算演绎成基于子图拓扑的多机多卡分布式推理。
下移子图拓扑到推理引擎层
通过以上的改进,新框架推理的模型规模越大性能提升越明显,与原方案相比,推理千亿参数ERNIE模型耗时下降70%。
提升服务并发吞吐
通常,大模型分布式推理优化技术包括动态批量、低精度fp16、TensorRT加速、fused优化和显存Cache等,Paddle Serving不仅采用了这些优化方法,同时也做了改进升级。例如动态批量技术在多个服务化推理框架中均有实现,原理是将多个请求shape维度相同但数值不同的Tensor自动Padding补0对齐,合并成一个大矩阵批量推理,充分利用GPU Kernel多Block、多线程特性,提升计算吞吐。
Paddle Serving动态批量技术的不同之处有2点。
第一,实现复杂的二维变长Tensor自动批量,如Transformer模型结构输入参数有二维变长Tensor。
策略1:评估数据绝对长度的差值,当两批数据长度的绝对值差的字节数小于1024字节时(可配置),自动Padding补齐后合并Batch。
策略2:评估数据的相似度,以两组数据Shape各个维度的乘积作为相似度,当相似度大于50%(可配置),自动Padding补齐后合并Batch。
异常处理
大模型部署面临的异常问题有3个:硬件故障、网络异常、服务异常等。整体异常处理预案如下:
单机网络异常:服务实例迁移
Master与Worker之间链接异常:采用短链接,半同步以及异常检测。
健康状态检查:定时端口检测&预测结果检测
服务夯住/挂掉:服务重启&supervise拉起
Benchmark
8*A100-SXM4-40GB, 160 core Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz, 10000Gbps network
总结
Paddle Serving多机多卡分布式推理方案有良好的通用性和扩展性,能广泛支持不同种类的模型结构,实现高速推理,目前已支撑了如自然语言理解、对话、跨模态生成等大模型的实时在线应用。使用该方案实现大规模服务化部署,让大模型真正落成应用。
部署方案
线上部署
在2022WAVE SUMMIT 2022深度学习开发者峰会期间,文心大模型旸谷社区的大模型应用采用Paddle Serving分布式推理框架部署上线,为大模型大规模应用奠定了基础。Paddle Serving多机多卡分布式推理框架的整体部署方案设计复杂,多地多中心、多机多卡组合、多级负载均衡、流量调度和异常故障处理等。整体部署思路如下图所示,与常规服务化部署的差异在于构建分布式部署的结构化思路。
部署案例
⭐ 点击阅读原文获得 ⭐
ERNIE 3.0百亿参数模型部署案例
知识问答任务示例
更多阅读
走进官网
Paddle Serving官网:
飞桨文心大模型官网:
加入社群
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~