近几年,随着语义分割任务的蓬勃发展,我们可以轻松地使用优秀的语义分割模型为特定的下游任务提供置信度高的语义信息。例如Zhai等人[3]使用语义分割模型得到的信息来优化ORB-SLAM2,使其能在在动态环境中保持稳定和最佳的定位性能。Chen等人[2]则使用语义分割模型提取待匹配图像的语义信息,给特征点匹配提供鲁棒的语义约束,提高特征点匹配的准确率。同时,从语义分割的结果中提取的语义约束,构建等式约束的光束法平差来优化3D结构和相机位姿。实验的结果表明利用语义信息辅助SfM可以在相同的效率下达到更好的重建精度。该论文的思路值得我们学习,同时我也注意到文中使用的模型是DeeplabV3+。在今年年初我所看到的一个视频中,在cityscapes-C上同时运行SegFormer和DeeplabV3+,视频中的SegFormer的鲁棒性比DeeplabV3+好很多,于是,我打算使用飞桨图像分割开发套件PaddleSeg中提供的SegFormer模型对论文的数据集进行训练,为SfM提供更精确和稳定的语义约束。
项目介绍
SegFormer模型介绍
PaddleSeg提供了基于飞桨实现的SegFormer模型[4],该模型将Transformer与轻量级多层感知 (MLP) 解码器相结合,表现SOTA,性能优于SETR、Auto-Deeplab和OCRNet等网络。此外,PaddleSeg提供了SegFormer-B0到 SegFormer-B5 一系列模型,以SegFormer-B4为例,该模型有64M参数,在ADE20K数据集上实现了50.3%的mIoU,比之前的最佳方法的参数小5倍,精度提高了2.2%。
关于模型的详细介绍请参考:
https://arxiv.org/abs/2105.15203
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.5/configs/segformer
https://aistudio.baidu.com/aistudio/projectdetail/3728553
数据集介绍
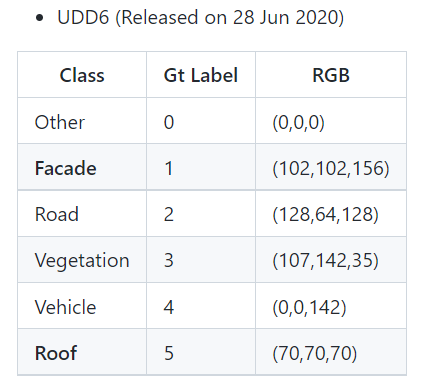
UDD6共包含有建筑外立面、道路、植被、汽车、建筑屋顶和其他6类,数据的示例如下图所示。
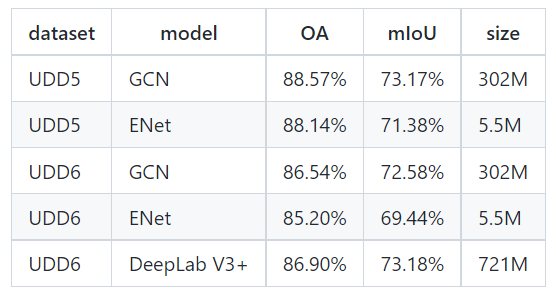
UDD6数据集有训练集160张和验证集45张,没有测试集。各个作为基准的分割模型对UDD6数据的验证数据集测试效果如下图所示,可以看到效果最好的是DeeplabV3+,mIoU为73.18%,模型的size为731M。
UDD6数据集地址:
基于PaddleSeg
使用SegFormer分割航空遥感影像
点击阅读原文获得项目链接
⭐ 欢迎大家fork&star ⭐
https://aistudio.baidu.com/aistudio/projectdetail/3565870
第一步 下载PaddleSeg套件
用户可以从Github下载PaddleSeg,为了便于国内用户下载,飞桨也提供了Gitee下载方式。
!git clone https://gitee.com/paddlepaddle/PaddleSeg
第二步 准备UDD6数据集
数据集已经挂载在项目上,通过以下命令进行数据集解压。
!mkdir work/UDD6
!unzip -oq data/data75675/UDD6.zip -d work/UDD6/
同时,由于UDD6数据中图像大小为 (4096, 2160) 所以训练之前先进行crop处理成(1024, 1024)小块的图像以减少IO的占用。切割的代码process_data.py的代码在work文件夹下,可以指定切割的大小、步长以及线程池的数量以加快效率,运行以下命令处理。
%cd work/
!python process_data.py --tag val #处理验证集
!python process_data.py --tag train #处理训练集
第三步 安装依赖项
由于我们在AI Studio中已经安装了paddlepaddle-gpu的库,所以接下来只需要运行以下命令安装和数据处理相关的依赖项即可。
%cd /home/aistudio/PaddleSeg
!pip install -r requirements.txt
第四步 数据集列表生成
由于PaddleSeg套件是根据文件名列表.txt文件来进行数据集的定义,所以需要生成训练集和验证集的列表文件。
套件中包含划分数据集生成文件名列表的代码。该代码使用帮助文档网址:
https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.5/docs/data/marker/marker_cn.md
运行以下命令即可。
# 训练数据集txt生成
!python tools/split_dataset_list.py \
../work/UDD6 train_sub train_labels_sub \
--split 1.0 0.0 0.0 \
--format JPG png \
--label_class Other Facade Road Vegetation Vehicle Roof
!mv ../work/UDD6/train.txt ../work/UDD6/train_true.txt # 修改文件名
# 验证数据集txt生成
!python tools/split_dataset_list.py \
../work/UDD6 val_sub val_labels_sub \
--split 0.0 1.0 0.0 \
--format JPG png \
--label_class Other Facade Road Vegetation Vehicle Roof
!rm ../work/UDD6/train.txt #删除第二次运行生成的train.txt
!mv ../work/UDD6/train_true.txt ../work/UDD6/train.txt # 将文件名改回来
第五步 环境配置和YML文件准备
运行以下代码,指定一张可用的显卡。
!export CUDA_VISIBLE_DEVICES=0
我们使用的是SegFormer-B3这个模型,配置文件segformer_b3_UDD.yml在work文件夹下,可以修改batch_size、iters、learning_rate等超参数,运行以下命令将配置文件复制到configs文件夹中。
!cp ../work/segformer_b3_UDD.yml configs/
第六步 开始训练
执行如下命令调用train.py脚本启动训练,在训练过程中会将最佳模型保存在output/best_model文件夹下。
!python train.py \
--config configs/segformer_b3_UDD.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output
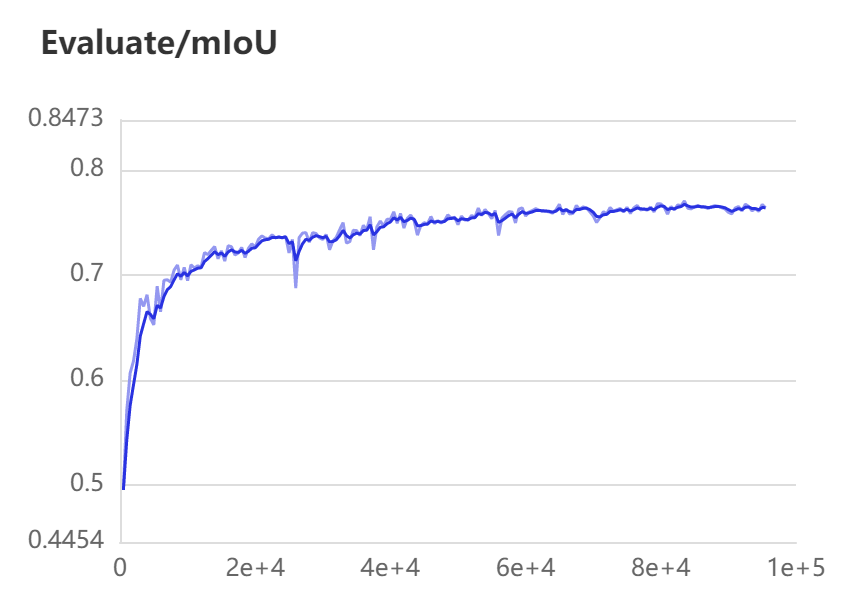
在训练过程中,验证集的mIoU指标变化情况如下图所示。
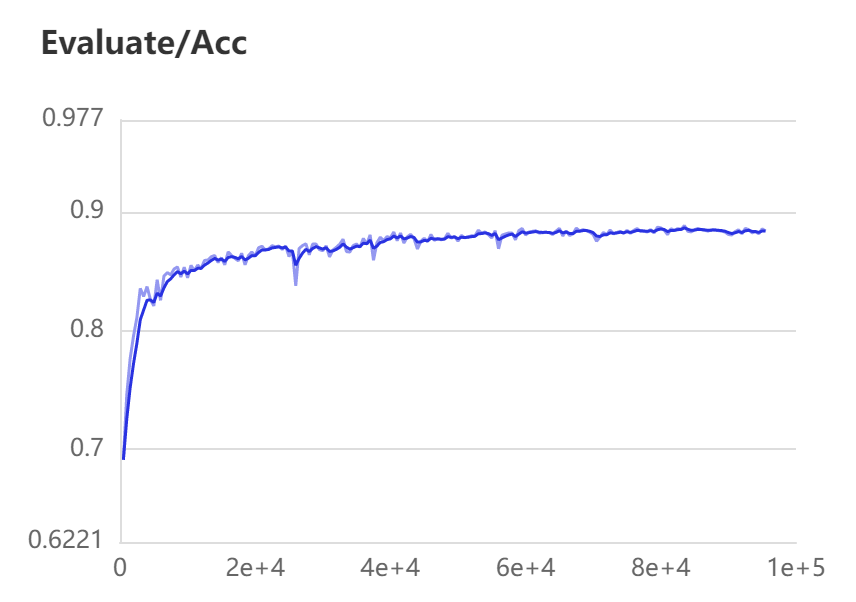
验证集的Acc指标变化情况如下图所示。
第七步 结果预测与评估
执行以下命令调用val.py,使用训练出来的权重对验证集进行预测和评估。
!python val.py \
--config configs/segformer_b3_UDD.yml \
--model_path ./output/best_model/model.pdparams
预测的结果在UDD6数据集中mIOU达到74.50% ,相较于原论文使用DeepLabV3+的mIOU为73.18%,高1.32%。
同时,可以使用训练好的权重对我们自己的航拍影像进行预测,执行如下命令即可。其中image_path是待预测图像所在文件夹路径。
!python predict.py \
--config ../work/segformer_b3_UDD.yml \
--model_path ./output/best_model/model.pdparams \
--image_path ../work/demo \
--save_dir ../work/result \
--is_slide \
--crop_size 1024 1024 \
--stride 512 512参考文献

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
近几年,随着语义分割任务的蓬勃发展,我们可以轻松地使用优秀的语义分割模型为特定的下游任务提供置信度高的语义信息。例如Zhai等人[3]使用语义分割模型得到的信息来优化ORB-SLAM2,使其能在在动态环境中保持稳定和最佳的定位性能。Chen等人[2]则使用语义分割模型提取待匹配图像的语义信息,给特征点匹配提供鲁棒的语义约束,提高特征点匹配的准确率。同时,从语义分割的结果中提取的语义约束,构建等式约束的光束法平差来优化3D结构和相机位姿。实验的结果表明利用语义信息辅助SfM可以在相同的效率下达到更好的重建精度。该论文的思路值得我们学习,同时我也注意到文中使用的模型是DeeplabV3+。在今年年初我所看到的一个视频中,在cityscapes-C上同时运行SegFormer和DeeplabV3+,视频中的SegFormer的鲁棒性比DeeplabV3+好很多,于是,我打算使用飞桨图像分割开发套件PaddleSeg中提供的SegFormer模型对论文的数据集进行训练,为SfM提供更精确和稳定的语义约束。
项目介绍
SegFormer模型介绍
PaddleSeg提供了基于飞桨实现的SegFormer模型[4],该模型将Transformer与轻量级多层感知 (MLP) 解码器相结合,表现SOTA,性能优于SETR、Auto-Deeplab和OCRNet等网络。此外,PaddleSeg提供了SegFormer-B0到 SegFormer-B5 一系列模型,以SegFormer-B4为例,该模型有64M参数,在ADE20K数据集上实现了50.3%的mIoU,比之前的最佳方法的参数小5倍,精度提高了2.2%。
关于模型的详细介绍请参考:
https://arxiv.org/abs/2105.15203
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.5/configs/segformer
https://aistudio.baidu.com/aistudio/projectdetail/3728553
数据集介绍
UDD6共包含有建筑外立面、道路、植被、汽车、建筑屋顶和其他6类,数据的示例如下图所示。
UDD6数据集有训练集160张和验证集45张,没有测试集。各个作为基准的分割模型对UDD6数据的验证数据集测试效果如下图所示,可以看到效果最好的是DeeplabV3+,mIoU为73.18%,模型的size为731M。
UDD6数据集地址:
基于PaddleSeg
使用SegFormer分割航空遥感影像
点击阅读原文获得项目链接
⭐ 欢迎大家fork&star ⭐
https://aistudio.baidu.com/aistudio/projectdetail/3565870
第一步 下载PaddleSeg套件
用户可以从Github下载PaddleSeg,为了便于国内用户下载,飞桨也提供了Gitee下载方式。
!git clone https://gitee.com/paddlepaddle/PaddleSeg
第二步 准备UDD6数据集
数据集已经挂载在项目上,通过以下命令进行数据集解压。
!mkdir work/UDD6
!unzip -oq data/data75675/UDD6.zip -d work/UDD6/
同时,由于UDD6数据中图像大小为 (4096, 2160) 所以训练之前先进行crop处理成(1024, 1024)小块的图像以减少IO的占用。切割的代码process_data.py的代码在work文件夹下,可以指定切割的大小、步长以及线程池的数量以加快效率,运行以下命令处理。
%cd work/
!python process_data.py --tag val #处理验证集
!python process_data.py --tag train #处理训练集
第三步 安装依赖项
由于我们在AI Studio中已经安装了paddlepaddle-gpu的库,所以接下来只需要运行以下命令安装和数据处理相关的依赖项即可。
%cd /home/aistudio/PaddleSeg
!pip install -r requirements.txt
第四步 数据集列表生成
由于PaddleSeg套件是根据文件名列表.txt文件来进行数据集的定义,所以需要生成训练集和验证集的列表文件。
套件中包含划分数据集生成文件名列表的代码。该代码使用帮助文档网址:
https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.5/docs/data/marker/marker_cn.md
运行以下命令即可。
# 训练数据集txt生成
!python tools/split_dataset_list.py \
../work/UDD6 train_sub train_labels_sub \
--split 1.0 0.0 0.0 \
--format JPG png \
--label_class Other Facade Road Vegetation Vehicle Roof
!mv ../work/UDD6/train.txt ../work/UDD6/train_true.txt # 修改文件名
# 验证数据集txt生成
!python tools/split_dataset_list.py \
../work/UDD6 val_sub val_labels_sub \
--split 0.0 1.0 0.0 \
--format JPG png \
--label_class Other Facade Road Vegetation Vehicle Roof
!rm ../work/UDD6/train.txt #删除第二次运行生成的train.txt
!mv ../work/UDD6/train_true.txt ../work/UDD6/train.txt # 将文件名改回来
第五步 环境配置和YML文件准备
运行以下代码,指定一张可用的显卡。
!export CUDA_VISIBLE_DEVICES=0
我们使用的是SegFormer-B3这个模型,配置文件segformer_b3_UDD.yml在work文件夹下,可以修改batch_size、iters、learning_rate等超参数,运行以下命令将配置文件复制到configs文件夹中。
!cp ../work/segformer_b3_UDD.yml configs/
第六步 开始训练
执行如下命令调用train.py脚本启动训练,在训练过程中会将最佳模型保存在output/best_model文件夹下。
!python train.py \
--config configs/segformer_b3_UDD.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output
在训练过程中,验证集的mIoU指标变化情况如下图所示。
验证集的Acc指标变化情况如下图所示。
第七步 结果预测与评估
执行以下命令调用val.py,使用训练出来的权重对验证集进行预测和评估。
!python val.py \
--config configs/segformer_b3_UDD.yml \
--model_path ./output/best_model/model.pdparams
预测的结果在UDD6数据集中mIOU达到74.50% ,相较于原论文使用DeepLabV3+的mIOU为73.18%,高1.32%。
同时,可以使用训练好的权重对我们自己的航拍影像进行预测,执行如下命令即可。其中image_path是待预测图像所在文件夹路径。
!python predict.py \
--config ../work/segformer_b3_UDD.yml \
--model_path ./output/best_model/model.pdparams \
--image_path ../work/demo \
--save_dir ../work/result \
--is_slide \
--crop_size 1024 1024 \
--stride 512 512参考文献
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~