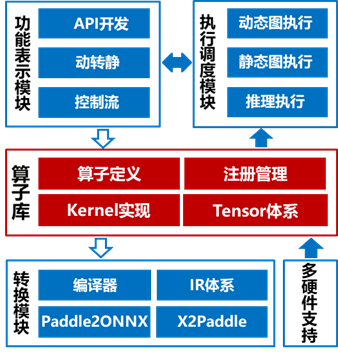
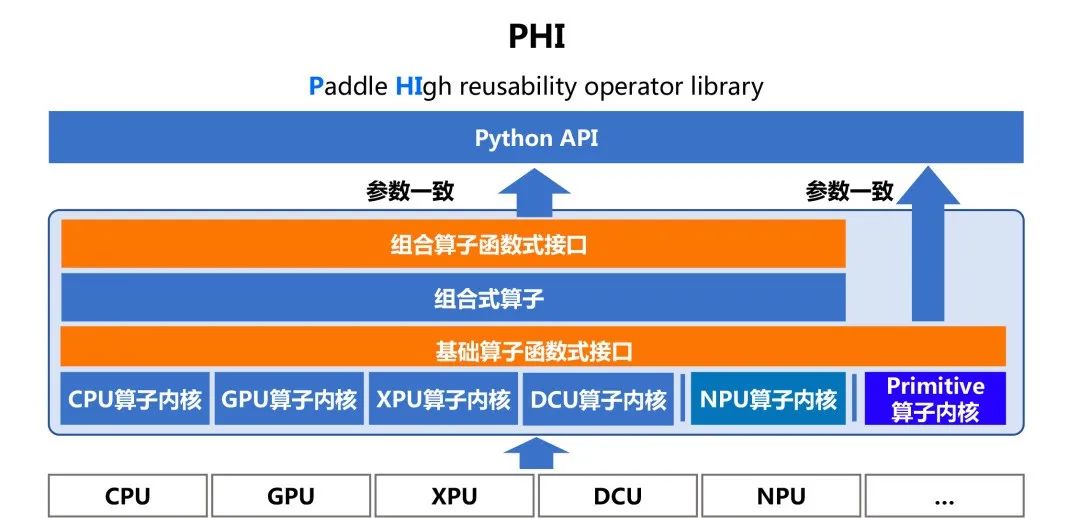
2022年5月,飞桨框架2.3版本正式发布,设计实现了高可复用算子库PHI(Paddle High reusability operator library)。新算子库提供了百余个与Python开发接口保持一致的C++运算类API,可大幅降低框架原生算子和自定义算子的开发成本。
PHI架构简介
基于PHI的低成本算子开发
其次,在降低新硬件接入成本方面,目前主要有两套机制:
本文主要介绍降低算子开发成本相关的内容,即配置式算子定义、函数式算子内核和基于C++运算API的插件式算子开发相关设计。
配置式算子定义
算子定义用于描述算子的输入、属性、输出信息,并声明其相关联的执行组件, “配置式”是指将这些信息通过配置文件的方式进行管理,与框架底层数据类型解耦,做到独立简洁,易于维护。配置式算子定义有什么优势呢?接下来从以下几个角度简要介绍一下。
(1)简洁性
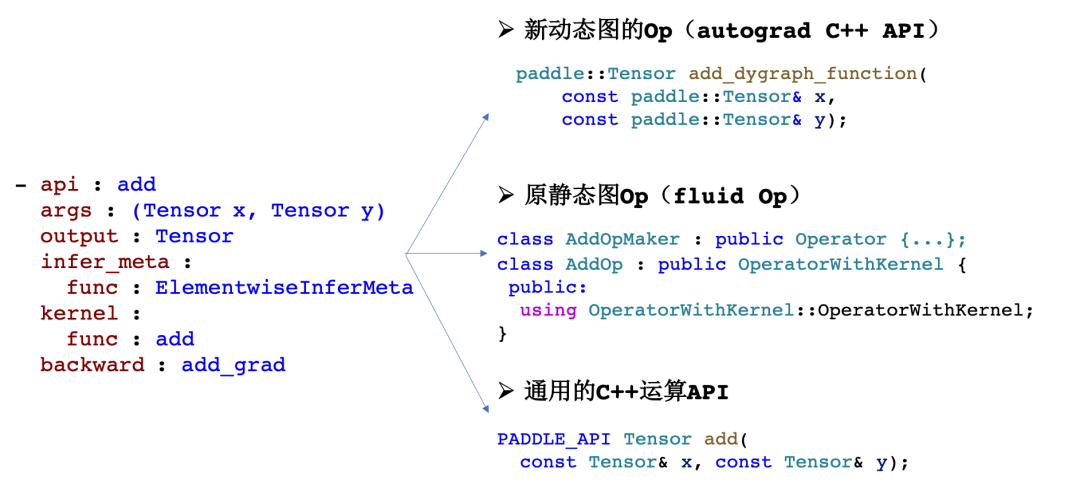
PHI算子库的算子定义方式相比之前有较大的升级。以Transpose[1]为例进行对比,原来的算子定义方式是基于类进行实现,新增TransposeOp类,实现维度推导类方法,同时新增TransposeOpMaker,定义算子的输入、输出和属性;而新的PHI算子定义方式整体是配置式的,只需要像“完型填空”一样,将关键的信息填写到对应条目之后即可。通过对比,可以看出新的算子定义方式无论是简洁性还是清晰度相比之前都有较大的改善。
// 原来的算子定义方式
class TransposeOp : public framework::OperatorWithKernel {
public:
using framework::OperatorWithKernel::OperatorWithKernel;
void InferShape(framework::InferShapeContext *ctx) const override {...}
};
class TransposeOpMaker : public framework::OpProtoAndCheckerMaker {
public:
void Make() override {
AddInput(
"X",
"(Tensor) The input tensor, tensors with rank up to 6 are supported.");
AddOutput("Out", "(Tensor)The output tensor.");
AddAttr<std::vector<int>>(
"axis",
"(vector<int>) A list of values, and the size of the list should be "
"the same with the input tensor rank. This operator permutes the input "
"tensor's axes according to the values given.");
AddComment(R"DOC(Transpose Operator.)DOC");
}
};
// PHI算子定义方式
- api : transpose
args : (Tensor x, int[] axis)
output : Tensor
infer_meta :
func : TransposeInferMeta
kernel :
func : transpose
backward : transpose_grad(2)灵活性
配置式算子定义在灵活性上也有明显的优势。配置式的算子定义是与实现无关的,我们可以基于算子的配置,结合具体的框架实现和使用场景,自动生成相应的算子形态,降低框架架构和算子升级的成本,同时也能够降低算子库的维护成本。现阶段我们基于一份配置式算子定义,自动生成了3套用于不同场景的“算子”,以add为例,现在在编译时可以自动生成动态图算子、静态图算子和通用C++ API三套实现。
(3)复用性优势
配置式算子定义在复用方面也可以较为简洁地实现。一方面,不同算子的输出Meta信息(维度、类型、布局等)推导函数是可以复用的,例如一些算子都可以复用UnchangedInferMeta实现,即直接继承输入的Meta信息,在配置时指定同一个函数名即可。
- api : conj
args : (Tensor x)
output : Tensor
infer_meta :
func : UnchangedInferMeta
kernel :
func : conj
backward : conj_grad
- api : atan
args : (Tensor x)
output : Tensor
infer_meta :
func : UnchangedInferMeta
kernel :
func : atan
backward : atan_grad
另一方面,如果运算本身可以复用,也可以直接声明调用相应算子,从而省去细节配置,例如,zeros_like[2]可以复用full_like[2]实现:
- api : zeros_like
args : (Tensor x, DataType dtype=DataType::UNDEFINED, Place place = {})
output : Tensor
invoke : full_like(x, 0, dtype, place)
函数式算子内核
函数式算子内核是指使用“函数”的形式去实现一个算子的内核计算函数,现有的深度学习框架在算子内核形式上,基本上可以分为两类,一类是仿函数类+Context输入的形式,一类是函数形式,飞桨本次升级是从仿函数类+Context输入形式的算子内核改为函数形式的。那么,使用函数式内核范式有什么好处呢?接下来从以下几个角度简要进行介绍。
(1)学习理解成本低
“函数”是基本的编程范式,是广大开发者都熟悉的概念,“函数”的输入、计算、输出均有直观清晰的表示,相较于仿函数类+Context输入的形式理解门槛较低。对比示例如下:
这里的仿函数类指的是通过重载operator`()`,使一个类或者结构体具有类似函数的行为,而Context输入是指将内核所需要的所有信息都“打包”到一个Context数据结构中,在内核中进行“解包”操作,将对应元素取出,然后再进行运算。仍以Transpose运算为例:
template <typename DeviceContext, typename T>
class TransposeKernel : public framework::OpKernel<T> {
public:
void Compute(const framework::ExecutionContext& context) const override {
auto* x = context.InputVar("X");
auto* out = context.OutputVar("Out");
std::vector<int> axis = context.Attr<std::vector<int>>("axis");
// Kernel Implementation
}
};
函数式内核的输入、参数和输出均直接作为参数出现,进入函数内部直接实现相应计算即可。仍以Transpose运算为例:
template <typename T, typename Context>
void TransposeKernel(const Context& ctx,
const DenseTensor& x,
const std::vector<int>& axis,
DenseTensor* out) {
// Kernel Implementation
}
显然,函数式内核形式是更加清晰直接的。
(2)复用便捷
函数式内核之间的复用是比较便捷且直接的,函数之间互相调用即可,而仿函数类+Context输入的形式就会比较繁琐,首先要将欲复用内核的输入、属性和输出等封装到一个类似Context的数据结构中,然后再去调用,这个过程一方面流程复杂,另一方面这些准备工作会引入调度开销,从而影响算子的性能。函数式内核复用的便捷性能够有效地提升开发效率,降低代码维护成本。因为当复用方式比较复杂的时候,可能会导致大家拷贝相应的代码去达到“复用”的目的,长期发展导致框架中存在较多的冗余代码。
基于以上的数学推导,我们可以借助于Full和Multiply这两个已有的Kernel实现反向逻辑,并完成相应的注册。
// square前向内核实现及注册
template <typename T, typename Context>
void SquareKernel(const Context& dev_ctx,
const DenseTensor& x,
DenseTensor* out) {
PowKernel<T>(dev_ctx, x, 2, out);
}
PD_REGISTER_KERNEL(
square, CPU, ALL_LAYOUT, phi::SquareKernel, float, double, int, int64_t) {}
// square反向内核实现及注册
template <typename T, typename Context>
void SquareGradKernel(const Context& dev_ctx,
const DenseTensor& x,
const DenseTensor& out_grad,
DenseTensor* x_grad) {
MultiplyKernel<T>(dev_ctx,
out_grad,
Multiply<T>(dev_ctx, Full<T>(dev_ctx, {1}, 2.0), x),
x_grad);
}
PD_REGISTER_KERNEL(square_grad,
CPU, ALL_LAYOUT, phi::SquareGradKernel, float, double, int, int64_t) {}
通过以上示例可以看到,当我们对性能要求没有那么极致的情况下,可以通过组合方式实现前反向逻辑,而不需要太关注硬件相关的实现逻辑。
(3)复用性能高
在复用性能方面的优势,主要体现在以下两个方面:
一方面,函数式内核天然具备低成本复用的优势。如前文所述,仿函数类+Context输入形式的内核,在复用时会不可避免地引入一些额外的准备工作,这些准备工作会影响算子的性能。因此一般来讲,仿函数类+Context形式的内核复用是比较少的。而函数式内核则没有这样的问题,可以灵活地服务于各处需要使用该运算的实现。
另一方面,编译器静态内核分发避免运行时动态开销。目前我们采用的函数式算子形式是以设备类型和数据类型作为模板参数的,借用了模板编程的形式在编译期完成设备类型及数据类型的静态分发,这可能使函数形式稍微复杂了一些,但可以避免在运行时复用引入动态分发的开销。深度学习框架在调用算子时,需要分发到特定设备的运算内核,才能在该设备上进行运算。如果这个分发的过程是动态的,即在运行时查找到需要的设备内核去调用,会有对应开销;如果是静态的,即在编译时就生成不同设备执行的代码,从而可以去掉运行时的查找过程,提升性能。例如假设有一个名为A的算子内核可以被其它算子内核复用,动静态分发的差别通过下述伪码简要介绍:
// 动态内核分发
A() {
判断满足CPU执行条件:// 运行时判断
全局映射表中查找是否存在A_CPU()内核;// 运行时查找
找到A_CPU()并调用
判断满足GPU执行条件:
全局映射表中查找是否存在A_CPU()内核;
找到A_CPU()并调用
}
// 静态内核分发
// 编译时生成了A<CPU>和A<GPU>的函数内核,通过实际Device模板参数匹配所需内核,无需运行时判断查找
A<Device>()
基于C++运算API的插件式算子开发
PADDLE_API Tensor abs(const Tensor& x);
PADDLE_API Tensor acos(const Tensor& x);
PADDLE_API Tensor acosh(const Tensor& x);
PADDLE_API Tensor add(const Tensor& x, const Tensor& y);
...
这里以Linear[5]为例介绍如何实现外部自定义算子的前向与反向逻辑。
首先看Linear的前向逻辑。从数学的定义来讲,Linear前向逻辑即x和weight做matmul的乘法后,再加上bias就可以得到前向结果,同样可以基于一行的实现把前向逻辑定义清楚,代码示例如下:
std::vector<paddle::Tensor> PhiLinearForward(const paddle::Tensor& x,
const paddle::Tensor& weight,
const paddle::Tensor& bias) {
return {paddle::add(paddle::matmul(x, weight), bias)};
}
std::vector<paddle::Tensor> PhiLinearBackward(const paddle::Tensor& x,
const paddle::Tensor& weight,
const paddle::Tensor& bias,
const paddle::Tensor& out_grad) {
auto x_grad = paddle::matmul(out_grad, weight, false, true);
auto flatten_x = paddle::reshape(x, {-1, weight.shape()[0]});
auto flatten_out_grad = paddle::reshape(out_grad, {-1, weight.shape()[1]});
auto weight_grad = paddle::matmul(flatten_x, flatten_out_grad, true, false);
std::vector<int64_t> axis;
for (size_t i = 0; i+1 < x.shape().size(); ++i) {
axis.emplace_back(i);
}
auto bias_grad = paddle::experimental::sum(out_grad, axis);
return {x_grad, weight_grad, bias_grad};
}
通过以上示例可以看到,自定义算子机制在结合PHI C++ API之后,开发更加便捷。在实现过程中只需要了解真正的正向和反向的计算过程,而不需要关心底层实现,仅需要关心数学逻辑,而不需要关心底层硬件相关的实现逻辑。
结语
更多阅读
参考资料

关注【飞桨PaddlePaddle】公众号
2022年5月,飞桨框架2.3版本正式发布,设计实现了高可复用算子库PHI(Paddle High reusability operator library)。新算子库提供了百余个与Python开发接口保持一致的C++运算类API,可大幅降低框架原生算子和自定义算子的开发成本。
PHI架构简介
基于PHI的低成本算子开发
其次,在降低新硬件接入成本方面,目前主要有两套机制:
本文主要介绍降低算子开发成本相关的内容,即配置式算子定义、函数式算子内核和基于C++运算API的插件式算子开发相关设计。
配置式算子定义
算子定义用于描述算子的输入、属性、输出信息,并声明其相关联的执行组件, “配置式”是指将这些信息通过配置文件的方式进行管理,与框架底层数据类型解耦,做到独立简洁,易于维护。配置式算子定义有什么优势呢?接下来从以下几个角度简要介绍一下。
(1)简洁性
PHI算子库的算子定义方式相比之前有较大的升级。以Transpose[1]为例进行对比,原来的算子定义方式是基于类进行实现,新增TransposeOp类,实现维度推导类方法,同时新增TransposeOpMaker,定义算子的输入、输出和属性;而新的PHI算子定义方式整体是配置式的,只需要像“完型填空”一样,将关键的信息填写到对应条目之后即可。通过对比,可以看出新的算子定义方式无论是简洁性还是清晰度相比之前都有较大的改善。
// 原来的算子定义方式
class TransposeOp : public framework::OperatorWithKernel {
public:
using framework::OperatorWithKernel::OperatorWithKernel;
void InferShape(framework::InferShapeContext *ctx) const override {...}
};
class TransposeOpMaker : public framework::OpProtoAndCheckerMaker {
public:
void Make() override {
AddInput(
"X",
"(Tensor) The input tensor, tensors with rank up to 6 are supported.");
AddOutput("Out", "(Tensor)The output tensor.");
AddAttr<std::vector<int>>(
"axis",
"(vector<int>) A list of values, and the size of the list should be "
"the same with the input tensor rank. This operator permutes the input "
"tensor's axes according to the values given.");
AddComment(R"DOC(Transpose Operator.)DOC");
}
};
// PHI算子定义方式
- api : transpose
args : (Tensor x, int[] axis)
output : Tensor
infer_meta :
func : TransposeInferMeta
kernel :
func : transpose
backward : transpose_grad(2)灵活性
配置式算子定义在灵活性上也有明显的优势。配置式的算子定义是与实现无关的,我们可以基于算子的配置,结合具体的框架实现和使用场景,自动生成相应的算子形态,降低框架架构和算子升级的成本,同时也能够降低算子库的维护成本。现阶段我们基于一份配置式算子定义,自动生成了3套用于不同场景的“算子”,以add为例,现在在编译时可以自动生成动态图算子、静态图算子和通用C++ API三套实现。
(3)复用性优势
配置式算子定义在复用方面也可以较为简洁地实现。一方面,不同算子的输出Meta信息(维度、类型、布局等)推导函数是可以复用的,例如一些算子都可以复用UnchangedInferMeta实现,即直接继承输入的Meta信息,在配置时指定同一个函数名即可。
- api : conj
args : (Tensor x)
output : Tensor
infer_meta :
func : UnchangedInferMeta
kernel :
func : conj
backward : conj_grad
- api : atan
args : (Tensor x)
output : Tensor
infer_meta :
func : UnchangedInferMeta
kernel :
func : atan
backward : atan_grad
另一方面,如果运算本身可以复用,也可以直接声明调用相应算子,从而省去细节配置,例如,zeros_like[2]可以复用full_like[2]实现:
- api : zeros_like
args : (Tensor x, DataType dtype=DataType::UNDEFINED, Place place = {})
output : Tensor
invoke : full_like(x, 0, dtype, place)
函数式算子内核
函数式算子内核是指使用“函数”的形式去实现一个算子的内核计算函数,现有的深度学习框架在算子内核形式上,基本上可以分为两类,一类是仿函数类+Context输入的形式,一类是函数形式,飞桨本次升级是从仿函数类+Context输入形式的算子内核改为函数形式的。那么,使用函数式内核范式有什么好处呢?接下来从以下几个角度简要进行介绍。
(1)学习理解成本低
“函数”是基本的编程范式,是广大开发者都熟悉的概念,“函数”的输入、计算、输出均有直观清晰的表示,相较于仿函数类+Context输入的形式理解门槛较低。对比示例如下:
这里的仿函数类指的是通过重载operator`()`,使一个类或者结构体具有类似函数的行为,而Context输入是指将内核所需要的所有信息都“打包”到一个Context数据结构中,在内核中进行“解包”操作,将对应元素取出,然后再进行运算。仍以Transpose运算为例:
template <typename DeviceContext, typename T>
class TransposeKernel : public framework::OpKernel<T> {
public:
void Compute(const framework::ExecutionContext& context) const override {
auto* x = context.InputVar("X");
auto* out = context.OutputVar("Out");
std::vector<int> axis = context.Attr<std::vector<int>>("axis");
// Kernel Implementation
}
};
函数式内核的输入、参数和输出均直接作为参数出现,进入函数内部直接实现相应计算即可。仍以Transpose运算为例:
template <typename T, typename Context>
void TransposeKernel(const Context& ctx,
const DenseTensor& x,
const std::vector<int>& axis,
DenseTensor* out) {
// Kernel Implementation
}
显然,函数式内核形式是更加清晰直接的。
(2)复用便捷
函数式内核之间的复用是比较便捷且直接的,函数之间互相调用即可,而仿函数类+Context输入的形式就会比较繁琐,首先要将欲复用内核的输入、属性和输出等封装到一个类似Context的数据结构中,然后再去调用,这个过程一方面流程复杂,另一方面这些准备工作会引入调度开销,从而影响算子的性能。函数式内核复用的便捷性能够有效地提升开发效率,降低代码维护成本。因为当复用方式比较复杂的时候,可能会导致大家拷贝相应的代码去达到“复用”的目的,长期发展导致框架中存在较多的冗余代码。
基于以上的数学推导,我们可以借助于Full和Multiply这两个已有的Kernel实现反向逻辑,并完成相应的注册。
// square前向内核实现及注册
template <typename T, typename Context>
void SquareKernel(const Context& dev_ctx,
const DenseTensor& x,
DenseTensor* out) {
PowKernel<T>(dev_ctx, x, 2, out);
}
PD_REGISTER_KERNEL(
square, CPU, ALL_LAYOUT, phi::SquareKernel, float, double, int, int64_t) {}
// square反向内核实现及注册
template <typename T, typename Context>
void SquareGradKernel(const Context& dev_ctx,
const DenseTensor& x,
const DenseTensor& out_grad,
DenseTensor* x_grad) {
MultiplyKernel<T>(dev_ctx,
out_grad,
Multiply<T>(dev_ctx, Full<T>(dev_ctx, {1}, 2.0), x),
x_grad);
}
PD_REGISTER_KERNEL(square_grad,
CPU, ALL_LAYOUT, phi::SquareGradKernel, float, double, int, int64_t) {}
通过以上示例可以看到,当我们对性能要求没有那么极致的情况下,可以通过组合方式实现前反向逻辑,而不需要太关注硬件相关的实现逻辑。
(3)复用性能高
在复用性能方面的优势,主要体现在以下两个方面:
一方面,函数式内核天然具备低成本复用的优势。如前文所述,仿函数类+Context输入形式的内核,在复用时会不可避免地引入一些额外的准备工作,这些准备工作会影响算子的性能。因此一般来讲,仿函数类+Context形式的内核复用是比较少的。而函数式内核则没有这样的问题,可以灵活地服务于各处需要使用该运算的实现。
另一方面,编译器静态内核分发避免运行时动态开销。目前我们采用的函数式算子形式是以设备类型和数据类型作为模板参数的,借用了模板编程的形式在编译期完成设备类型及数据类型的静态分发,这可能使函数形式稍微复杂了一些,但可以避免在运行时复用引入动态分发的开销。深度学习框架在调用算子时,需要分发到特定设备的运算内核,才能在该设备上进行运算。如果这个分发的过程是动态的,即在运行时查找到需要的设备内核去调用,会有对应开销;如果是静态的,即在编译时就生成不同设备执行的代码,从而可以去掉运行时的查找过程,提升性能。例如假设有一个名为A的算子内核可以被其它算子内核复用,动静态分发的差别通过下述伪码简要介绍:
// 动态内核分发
A() {
判断满足CPU执行条件:// 运行时判断
全局映射表中查找是否存在A_CPU()内核;// 运行时查找
找到A_CPU()并调用
判断满足GPU执行条件:
全局映射表中查找是否存在A_CPU()内核;
找到A_CPU()并调用
}
// 静态内核分发
// 编译时生成了A<CPU>和A<GPU>的函数内核,通过实际Device模板参数匹配所需内核,无需运行时判断查找
A<Device>()
基于C++运算API的插件式算子开发
PADDLE_API Tensor abs(const Tensor& x);
PADDLE_API Tensor acos(const Tensor& x);
PADDLE_API Tensor acosh(const Tensor& x);
PADDLE_API Tensor add(const Tensor& x, const Tensor& y);
...
这里以Linear[5]为例介绍如何实现外部自定义算子的前向与反向逻辑。
首先看Linear的前向逻辑。从数学的定义来讲,Linear前向逻辑即x和weight做matmul的乘法后,再加上bias就可以得到前向结果,同样可以基于一行的实现把前向逻辑定义清楚,代码示例如下:
std::vector<paddle::Tensor> PhiLinearForward(const paddle::Tensor& x,
const paddle::Tensor& weight,
const paddle::Tensor& bias) {
return {paddle::add(paddle::matmul(x, weight), bias)};
}
std::vector<paddle::Tensor> PhiLinearBackward(const paddle::Tensor& x,
const paddle::Tensor& weight,
const paddle::Tensor& bias,
const paddle::Tensor& out_grad) {
auto x_grad = paddle::matmul(out_grad, weight, false, true);
auto flatten_x = paddle::reshape(x, {-1, weight.shape()[0]});
auto flatten_out_grad = paddle::reshape(out_grad, {-1, weight.shape()[1]});
auto weight_grad = paddle::matmul(flatten_x, flatten_out_grad, true, false);
std::vector<int64_t> axis;
for (size_t i = 0; i+1 < x.shape().size(); ++i) {
axis.emplace_back(i);
}
auto bias_grad = paddle::experimental::sum(out_grad, axis);
return {x_grad, weight_grad, bias_grad};
}
通过以上示例可以看到,自定义算子机制在结合PHI C++ API之后,开发更加便捷。在实现过程中只需要了解真正的正向和反向的计算过程,而不需要关心底层实现,仅需要关心数学逻辑,而不需要关心底层硬件相关的实现逻辑。
结语
更多阅读
参考资料
关注【飞桨PaddlePaddle】公众号