交通领域的应用智能化不断往纵深发展,其中最为成熟的车牌识别早已融入人们的日常生活之中,在高速公路电子收费系统、停车场等场景中随处可见。一些企业在具体业务中倾向采用开源方案降低研发成本,但现有公开的方案中少有完成端到端的车牌应用范例。
本次飞桨产业实践范例库开源车牌识别场景应用,提供了从技术方案、模型训练优化,到模型部署的全流程可复用方案,降低产业落地门槛。
场景难点
车牌在图像中的尺度差异大、在车辆上的悬挂位置不固定;
车牌图像质量层次不齐: 角度倾斜、图片模糊、光照不足、过曝等问题严重;
项目方案
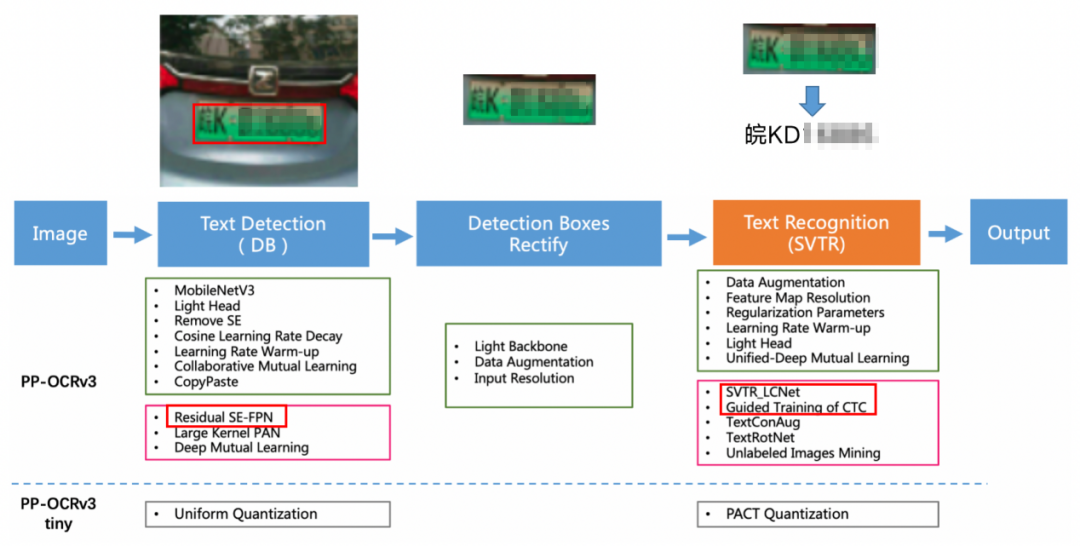
CCPD(Chinese City Parking Dataset)数据集包含蓝底车牌和新能源车牌,覆盖场景包括各类文字形态(倾斜、模糊)与气候环境(如阴雨天、雪天等),其中新能源车牌训练集数量为5769张。CCPD数据标签体现在图片文件名,其命名规范如图2所示。范例中我们通过转换脚本将上述规则转换为PaddleOCR的数据标注格式并划分数据集。
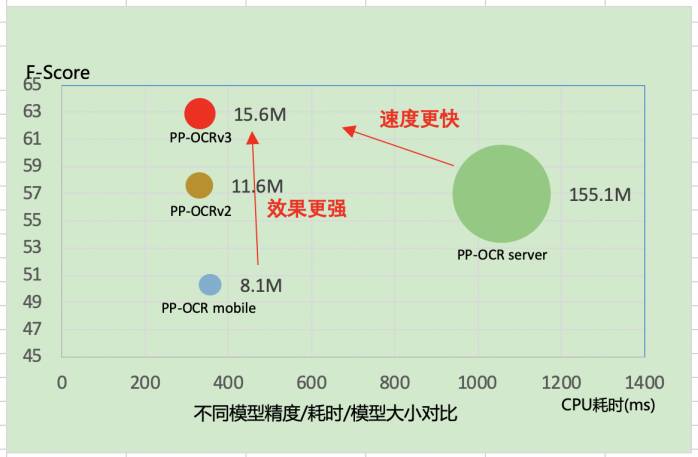
在少量数据的情况下,优秀的预训练模型能够带来更好的精度和泛化性。本范例选择PaddleOCR最新发布的PP-OCRv3模型完成数据微调。PP-OCRv3在PP-OCRv2的基础上,端到端指标H-means在中文场景再提升5%, 英文数字模型提升11%,如图3所示。
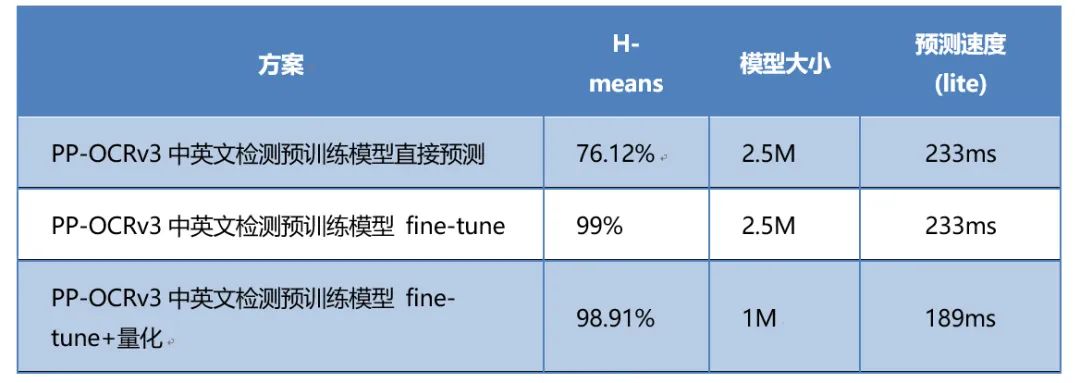
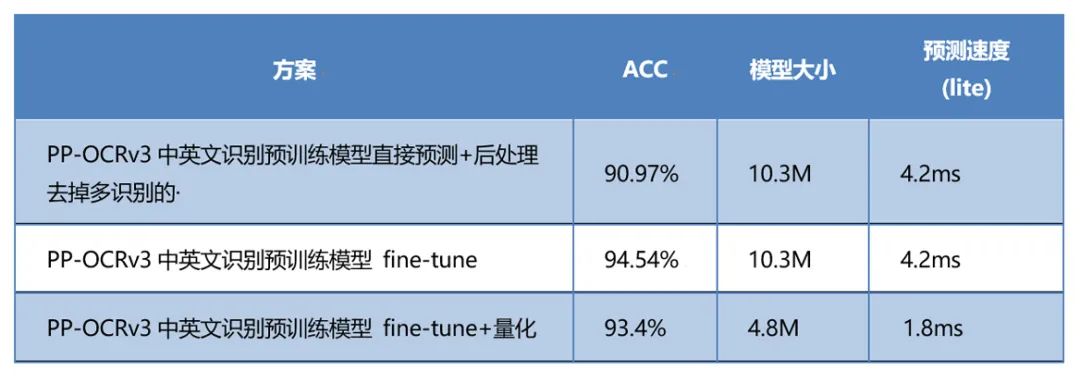
PP-OCRv3中英文超轻量预训练模型直接预测
基于PP-OCRv3的策略在CCPD数据集中微调
基于PP-OCRv3的策略在CCPD数据集中微调后量化
边缘部署和端侧部署是车牌识别的常见部署方式,PaddleLite轻量化推理引擎是飞桨专为手机、IOT端提供的高效推理能力。本范例采用PaddleLite的cpp推理,在骁龙855上完成示例演示,最终端到端预测速度为224ms。
飞桨产业实践范例,致力于加速AI在产业落地的前进路径,减少理论技术与产业应用的差距。范例来源于产业真实业务场景,通过完整的代码实现,提供从数据准备到模型部署的方案过程解析,堪称产业落地的“自动导航”。
精彩课程预告
为了让小伙伴们更便捷地应用车牌识别范例教程,我们邀请了百度高级研发工程师于5月25日20:00-21:00为大家深度解析从数据准备、方案设计到模型优化部署的开发全流程,手把手教大家进行代码实践。欢迎小伙伴们扫码进群,免费获取直播课和回放视频链接,更有机会免费获取企业专享资源包。
扫码报名直播课
加入技术交流群
参考文献
[1] Xu Z, Yang W, Meng A, et al. Towards end-to-end license platedetection and recognition: A large dataset and baseline[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 255-271.

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
交通领域的应用智能化不断往纵深发展,其中最为成熟的车牌识别早已融入人们的日常生活之中,在高速公路电子收费系统、停车场等场景中随处可见。一些企业在具体业务中倾向采用开源方案降低研发成本,但现有公开的方案中少有完成端到端的车牌应用范例。
本次飞桨产业实践范例库开源车牌识别场景应用,提供了从技术方案、模型训练优化,到模型部署的全流程可复用方案,降低产业落地门槛。
场景难点
车牌在图像中的尺度差异大、在车辆上的悬挂位置不固定;
车牌图像质量层次不齐: 角度倾斜、图片模糊、光照不足、过曝等问题严重;
项目方案
CCPD(Chinese City Parking Dataset)数据集包含蓝底车牌和新能源车牌,覆盖场景包括各类文字形态(倾斜、模糊)与气候环境(如阴雨天、雪天等),其中新能源车牌训练集数量为5769张。CCPD数据标签体现在图片文件名,其命名规范如图2所示。范例中我们通过转换脚本将上述规则转换为PaddleOCR的数据标注格式并划分数据集。
在少量数据的情况下,优秀的预训练模型能够带来更好的精度和泛化性。本范例选择PaddleOCR最新发布的PP-OCRv3模型完成数据微调。PP-OCRv3在PP-OCRv2的基础上,端到端指标H-means在中文场景再提升5%, 英文数字模型提升11%,如图3所示。
PP-OCRv3中英文超轻量预训练模型直接预测
基于PP-OCRv3的策略在CCPD数据集中微调
基于PP-OCRv3的策略在CCPD数据集中微调后量化
边缘部署和端侧部署是车牌识别的常见部署方式,PaddleLite轻量化推理引擎是飞桨专为手机、IOT端提供的高效推理能力。本范例采用PaddleLite的cpp推理,在骁龙855上完成示例演示,最终端到端预测速度为224ms。
飞桨产业实践范例,致力于加速AI在产业落地的前进路径,减少理论技术与产业应用的差距。范例来源于产业真实业务场景,通过完整的代码实现,提供从数据准备到模型部署的方案过程解析,堪称产业落地的“自动导航”。
精彩课程预告
为了让小伙伴们更便捷地应用车牌识别范例教程,我们邀请了百度高级研发工程师于5月25日20:00-21:00为大家深度解析从数据准备、方案设计到模型优化部署的开发全流程,手把手教大家进行代码实践。欢迎小伙伴们扫码进群,免费获取直播课和回放视频链接,更有机会免费获取企业专享资源包。
扫码报名直播课
加入技术交流群
参考文献
[1] Xu Z, Yang W, Meng A, et al. Towards end-to-end license platedetection and recognition: A large dataset and baseline[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 255-271.
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~