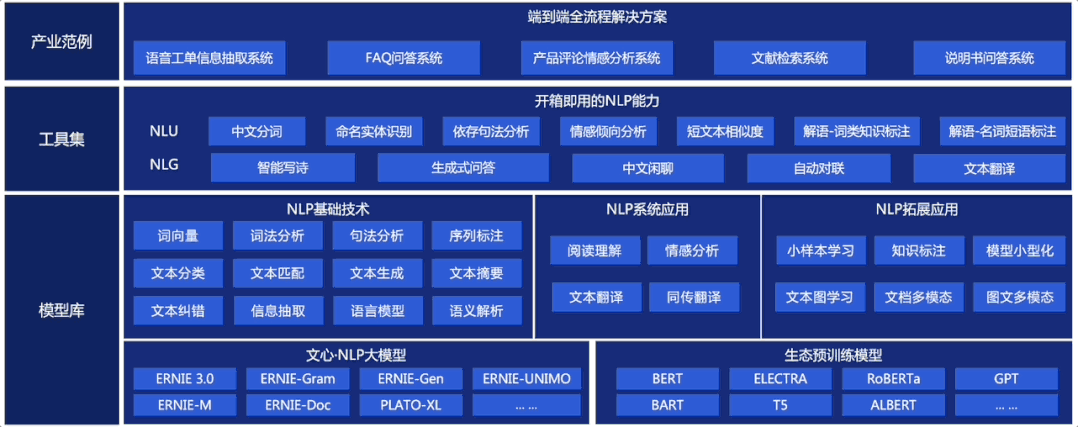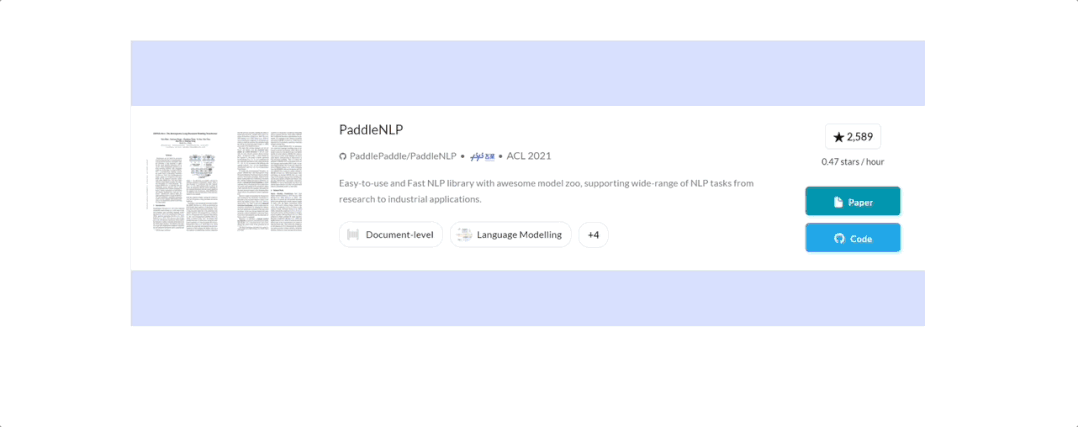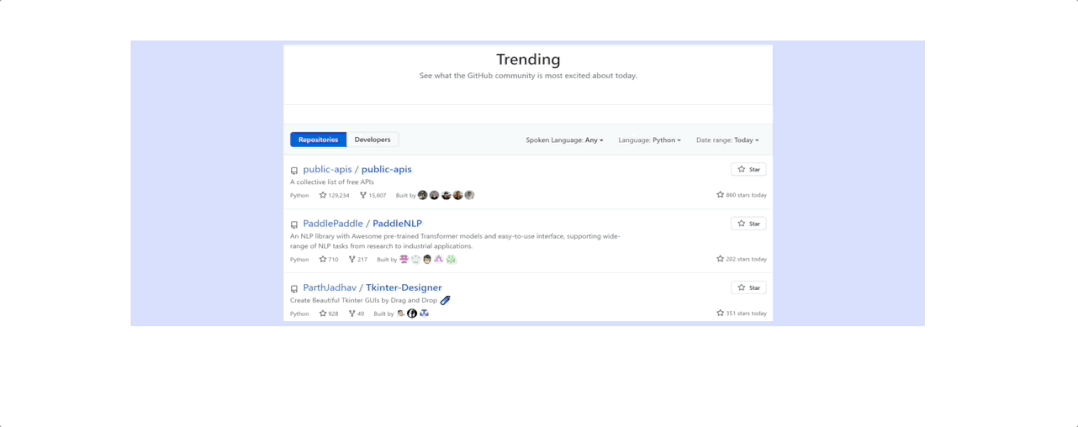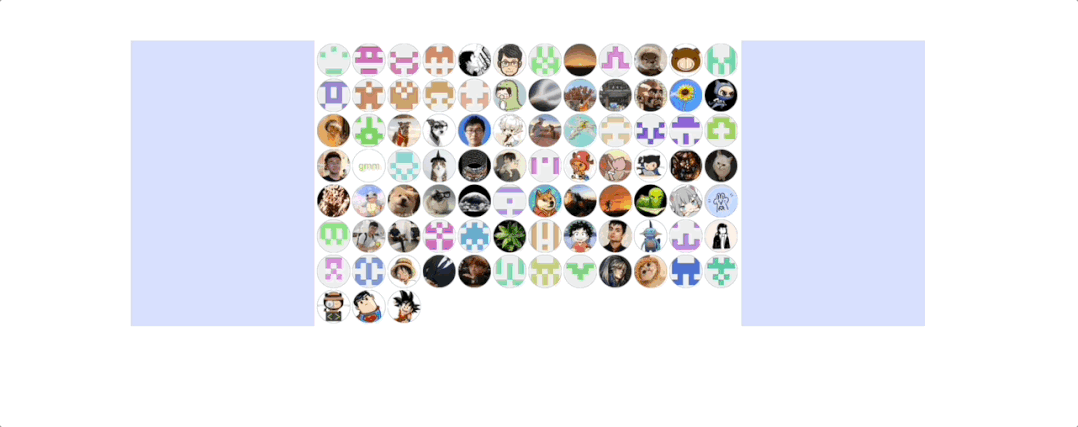
PaddleNLP v2.3带来两大重磅能力:
图1 信息抽取应用场景示例
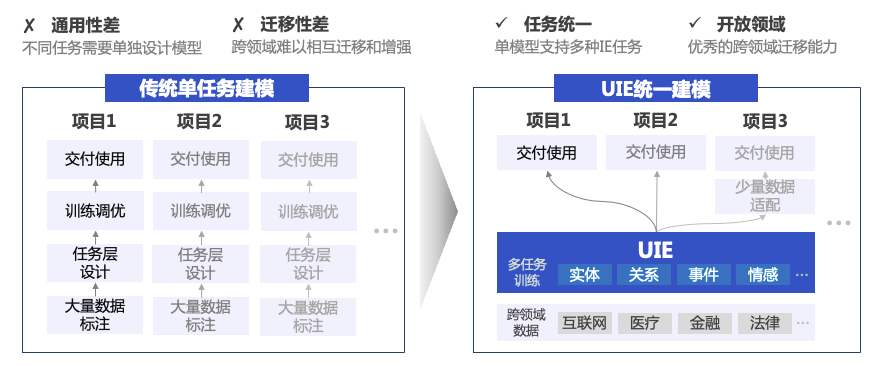
多任务统一建模
零样本抽取和少样本快速迁移能力
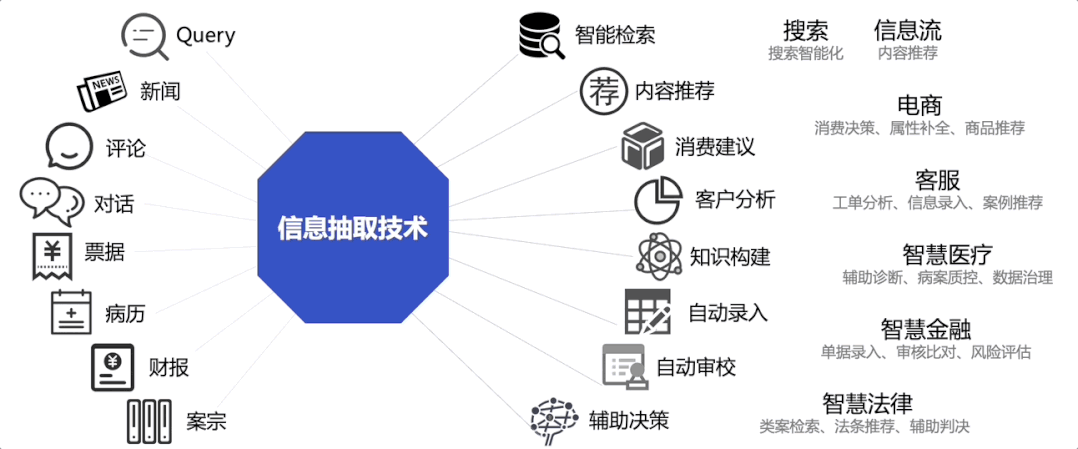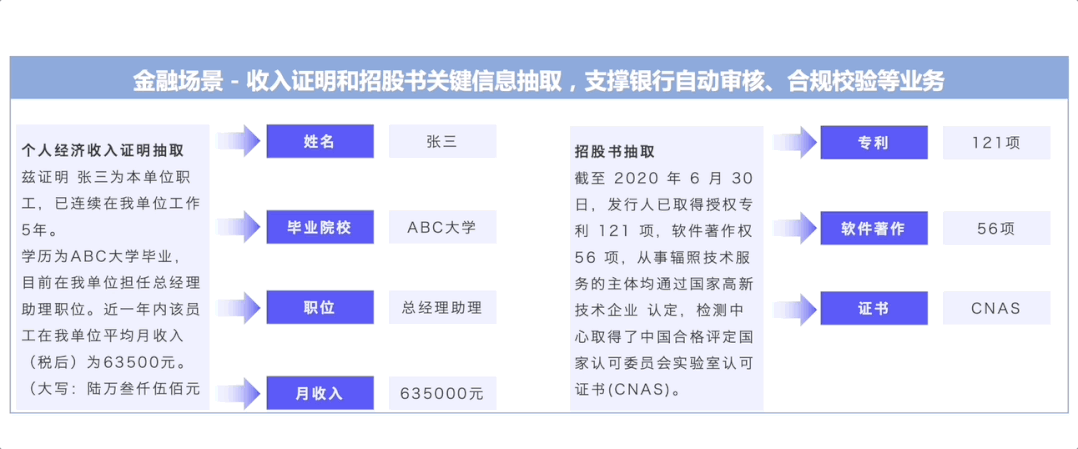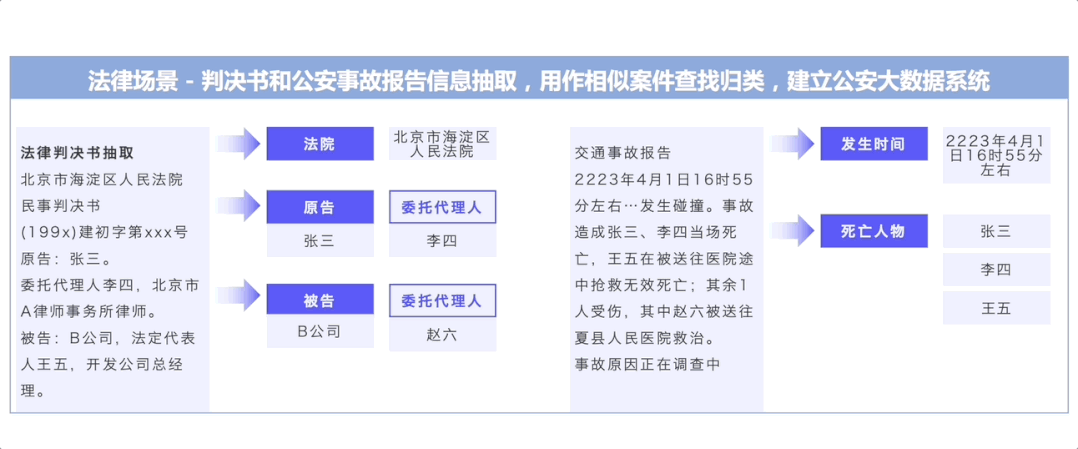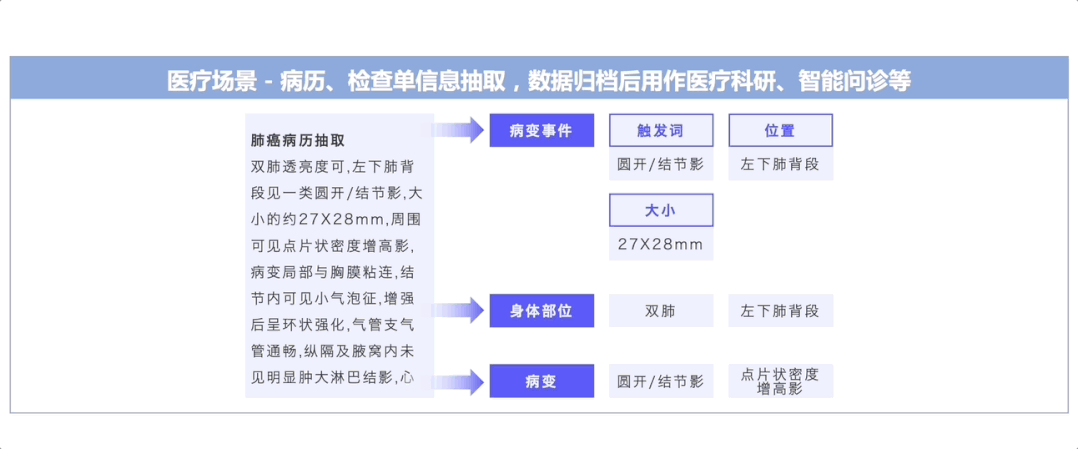
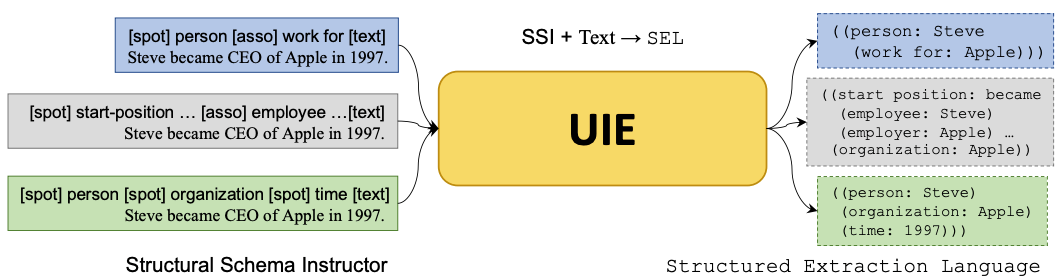
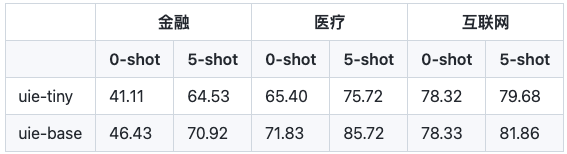
UIE开创了基于Prompt的信息抽取多任务统一建模方式,通过大规模多任务预训练学习的通用抽取能力,可以实现不限定行业领域和抽取目标,零样本快速冷启动。例如在金融领域客户收入证明信息抽取(下图左)中,无需训练数据,即可全部抽取正确。针对复杂抽取需求,标注少量数据微调即完成任务适配,大大降低标注门槛和成本。例如医疗报告结构化(下图中)和报销单信息抽取(下图右)中,仅标注了几条样本,F1值就取得大幅提升,真是太实用了!
说明:0-shot表示无训练数据直接预测,5-shot表示基于5条标注数据进行模型微调。uie-tiny和uie-base分别表示6层和12层的UIE模型。
便捷易用
# 实体抽取
from pprint import pprint
from paddlenlp import Taskflow
schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
>>>
[{'时间': [{'end': 6, 'probability': 0.9857378532924486, 'start': 0, 'text': '2月8日上午'}],
'赛事名称': [{'end': 23,'probability': 0.8503089953268272,'start': 6,'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'选手': [{'end': 31,'probability': 0.8981548639781138,'start': 28,'text': '谷爱凌'}]}]
# 事件抽取
schema = {'地震触发词': ['地震强度', '时间', '震中位置', '震源深度']} # Define the schema for event extraction
ie.set_schema(schema) # Reset schema
ie('中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。')
>>>
[{'地震触发词':
[{'end': 58,'probability': 0.9987181623528585,'start': 56,'text': '地震',
'relations':
{'地震强度': [{'end': 56,'probability': 0.9962985320905915,'start': 52,'text': '3.5级'}],
'时间': [{'end': 22,'probability': 0.9882578028575182,'start': 11,'text': '5月16日06时08分'}],
'震中位置': [{'end': 50,'probability': 0.8551417444021787,'start': 23,'text': '云南临沧市凤庆县(北纬24.34度,东经99.98度)'}],
'震源深度': [{'end': 67,'probability': 0.999158304648045,'start': 63,'text': '10千米'}]}
}]
}]
文心大模型ERNIE
轻量级模型开源
PaddleNLP开源的信息抽取能力背后,除了大一统信息抽取技术UIE外,还得益于文心产业级知识增强大模型——文心ERNIE 3.0的底座支撑。我们知道,知识对于信息抽取任务至关重要。而文心ERNIE3.0不仅参数量大,还吸纳了千万级别实体的知识图谱,可以说是中文NLP方面最有“知识量”的SOTA底座。
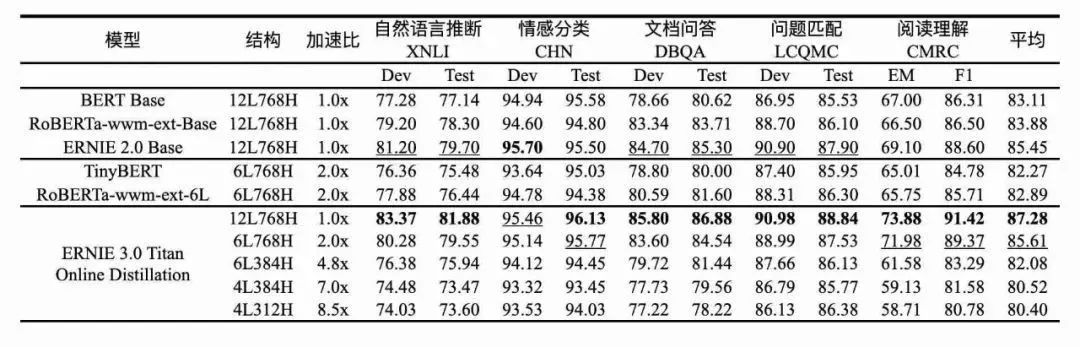
近日,这个6层中文SOTA预训练模型也开源了!此外,PaddleNLP v2.3还提供了该模型完整的推理部署工具链,包含PaddleSlim裁剪量化压缩方案、Paddle Inference CPU、GPU高性能推理部署和Paddle Serving服务化部署能力,可以做到精度无损的情况下实现8.8倍的加速提升,一站式满足多场景的产业部署需求。
直播课预告
5.18-5.19日每晚20:30,百度高工将带来直播讲解,剖析信息抽取行业应用痛点,解读PaddleNLP信息抽取方案,并手把手带您进行项目实战。此外,还将带来ERNIE 3.0压缩部署和产业实践,欢迎大家扫码进群,获取课程链接!
入群福利
获取PaddleNLP团队整理的10G重磅NLP学习大礼包
获取5月18-19日直播课程链接
参考资料

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
PaddleNLP v2.3带来两大重磅能力:
图1 信息抽取应用场景示例
多任务统一建模
零样本抽取和少样本快速迁移能力
UIE开创了基于Prompt的信息抽取多任务统一建模方式,通过大规模多任务预训练学习的通用抽取能力,可以实现不限定行业领域和抽取目标,零样本快速冷启动。例如在金融领域客户收入证明信息抽取(下图左)中,无需训练数据,即可全部抽取正确。针对复杂抽取需求,标注少量数据微调即完成任务适配,大大降低标注门槛和成本。例如医疗报告结构化(下图中)和报销单信息抽取(下图右)中,仅标注了几条样本,F1值就取得大幅提升,真是太实用了!
说明:0-shot表示无训练数据直接预测,5-shot表示基于5条标注数据进行模型微调。uie-tiny和uie-base分别表示6层和12层的UIE模型。
便捷易用
# 实体抽取
from pprint import pprint
from paddlenlp import Taskflow
schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
>>>
[{'时间': [{'end': 6, 'probability': 0.9857378532924486, 'start': 0, 'text': '2月8日上午'}],
'赛事名称': [{'end': 23,'probability': 0.8503089953268272,'start': 6,'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'选手': [{'end': 31,'probability': 0.8981548639781138,'start': 28,'text': '谷爱凌'}]}]
# 事件抽取
schema = {'地震触发词': ['地震强度', '时间', '震中位置', '震源深度']} # Define the schema for event extraction
ie.set_schema(schema) # Reset schema
ie('中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。')
>>>
[{'地震触发词':
[{'end': 58,'probability': 0.9987181623528585,'start': 56,'text': '地震',
'relations':
{'地震强度': [{'end': 56,'probability': 0.9962985320905915,'start': 52,'text': '3.5级'}],
'时间': [{'end': 22,'probability': 0.9882578028575182,'start': 11,'text': '5月16日06时08分'}],
'震中位置': [{'end': 50,'probability': 0.8551417444021787,'start': 23,'text': '云南临沧市凤庆县(北纬24.34度,东经99.98度)'}],
'震源深度': [{'end': 67,'probability': 0.999158304648045,'start': 63,'text': '10千米'}]}
}]
}]
文心大模型ERNIE
轻量级模型开源
PaddleNLP开源的信息抽取能力背后,除了大一统信息抽取技术UIE外,还得益于文心产业级知识增强大模型——文心ERNIE 3.0的底座支撑。我们知道,知识对于信息抽取任务至关重要。而文心ERNIE3.0不仅参数量大,还吸纳了千万级别实体的知识图谱,可以说是中文NLP方面最有“知识量”的SOTA底座。
近日,这个6层中文SOTA预训练模型也开源了!此外,PaddleNLP v2.3还提供了该模型完整的推理部署工具链,包含PaddleSlim裁剪量化压缩方案、Paddle Inference CPU、GPU高性能推理部署和Paddle Serving服务化部署能力,可以做到精度无损的情况下实现8.8倍的加速提升,一站式满足多场景的产业部署需求。
直播课预告
5.18-5.19日每晚20:30,百度高工将带来直播讲解,剖析信息抽取行业应用痛点,解读PaddleNLP信息抽取方案,并手把手带您进行项目实战。此外,还将带来ERNIE 3.0压缩部署和产业实践,欢迎大家扫码进群,获取课程链接!
入群福利
获取PaddleNLP团队整理的10G重磅NLP学习大礼包
获取5月18-19日直播课程链接
参考资料
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~