文心大模型首场技术开放日已经圆满结束。在本次活动中,文心大模型背后的“技术天团”首次集中亮相,分享大模型技术发展趋势洞察、文心大模型最新技术突破及产业应用实践,为技术爱好者带来一场干货满满的AI技术盛宴。
本篇文章整理自百度技术委员会主席吴华《文心大模型:知识增强的NLP模型详解》直播分享。
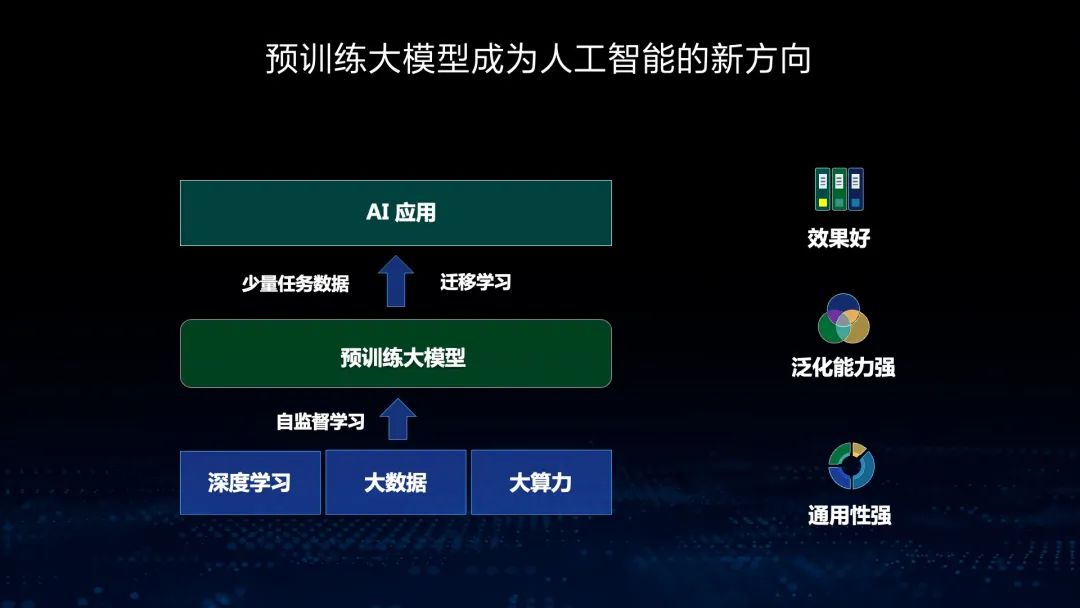
预训练大模型能够充分地挖掘大规模无标注数据的潜力,从海量数据中学习知识与规律,就像我们人类的通识教育。从出生开始,我们接受的都是通识教育,到上大学以后,才接受专业教育。在应用大模型以后,通过大模型加任务数据微调的方式,能获得非常好的效果,这已经成为了新的研发范式。
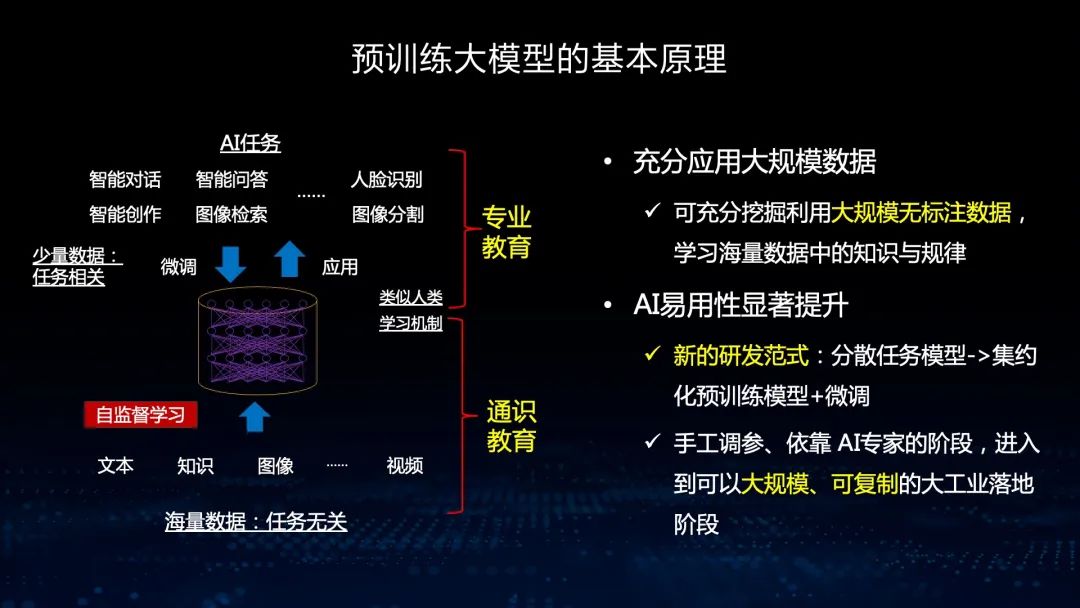
拥有了预训练大模型后,我们可以从之前的手工调参依赖AI专家的阶段进入大规模可复制的大工业落地阶段。
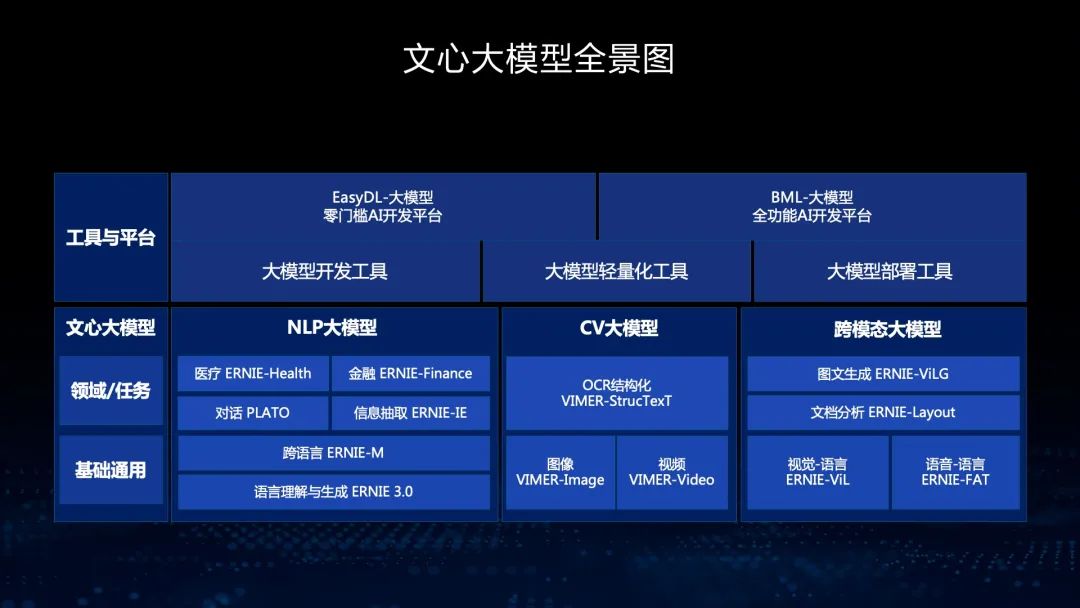
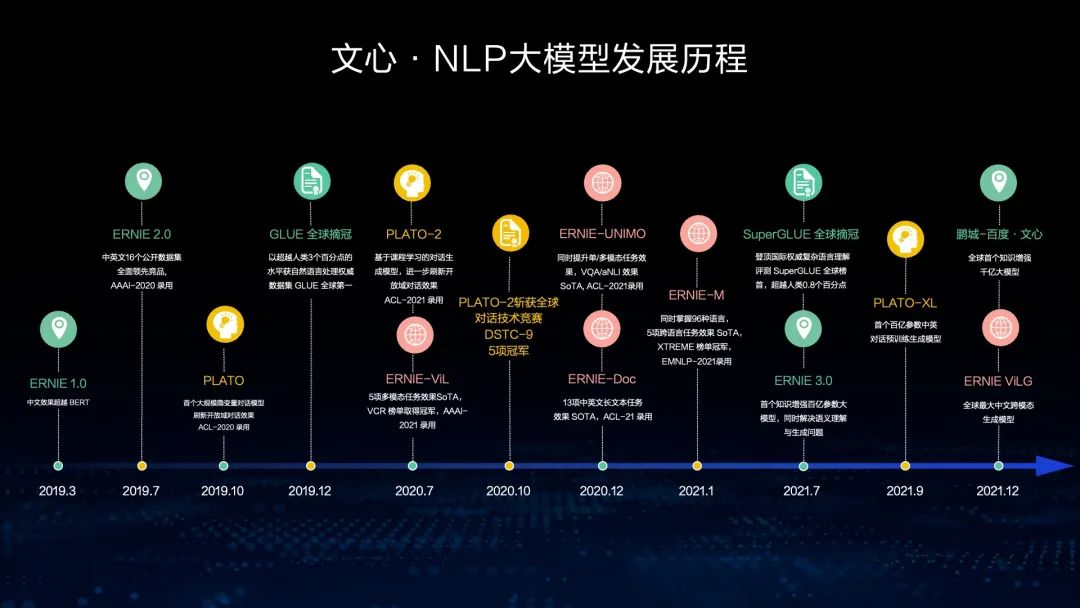
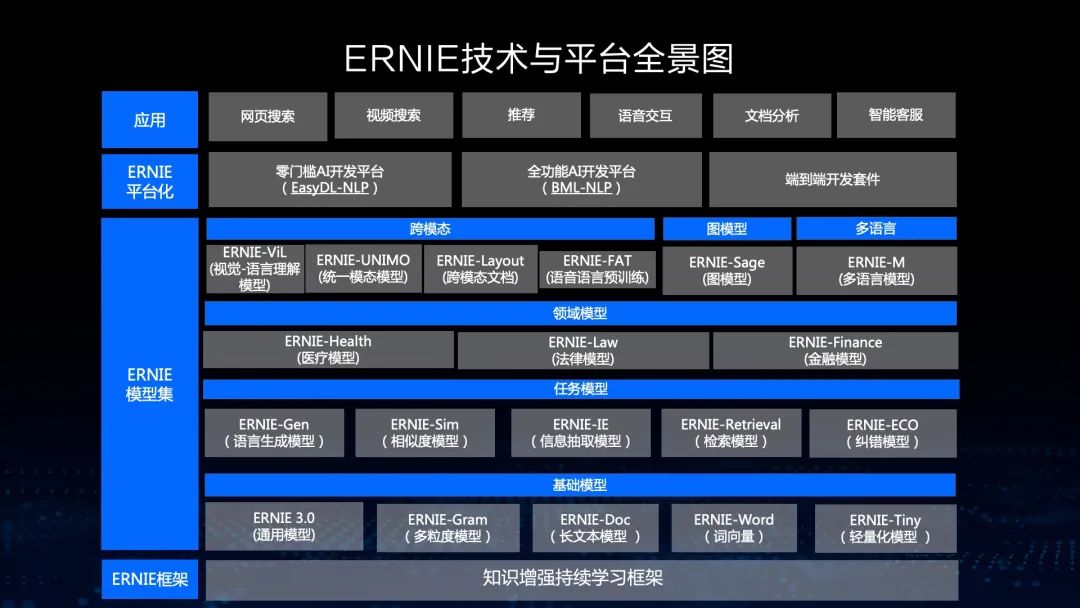
这是我们文心大模型的全景图,包括NLP大模型、CV大模型和跨模态大模型,在此基础上,我们开发了大模型的开发工具、轻量化工具和大规模部署工具,而且我们支持零门槛的AI开发平台以及全功能AI开发平台。
知识增强大模型
文心ERNIE
接下来,首先让我们解读知识增强大模型文心ERNIE。
文心ERNIE:持续学习框架
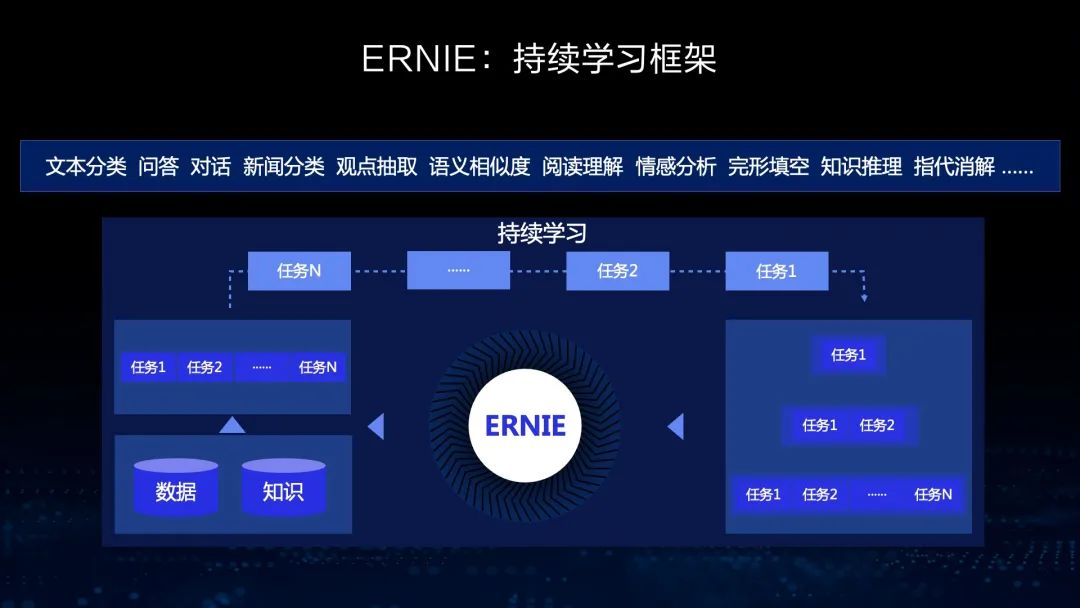
能够从大规模知识图谱和海量无结构数据中学习,突破异构数据统一表达的瓶颈问题。
能够融合自编码和自回归结构,既可以做语言理解,也可以做语言生成。
基于飞桨4D混合并行技术,能够更高效地支持超大规模模型的预训练。
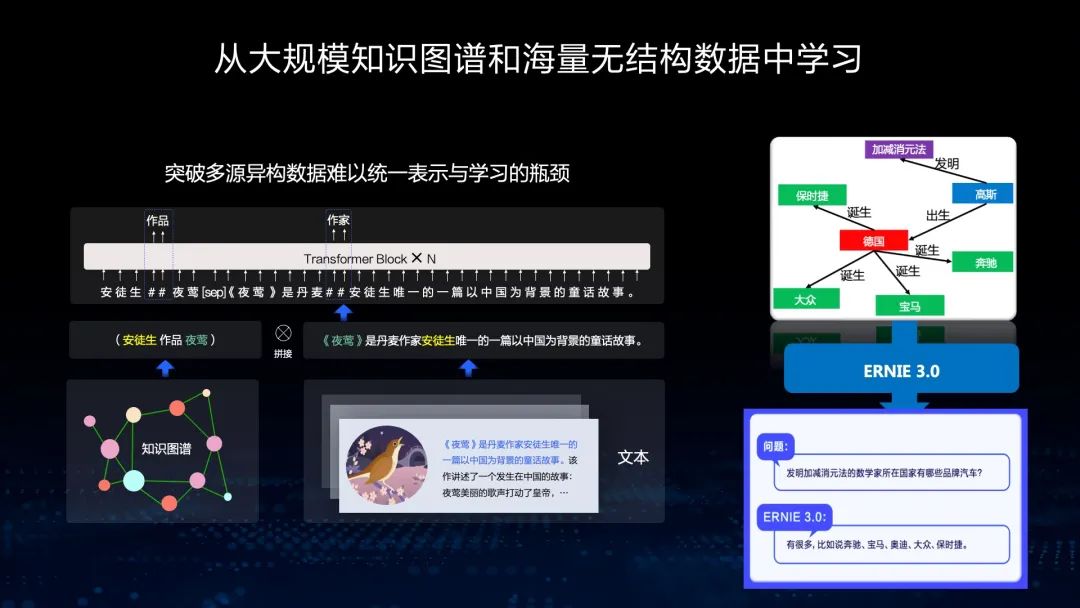
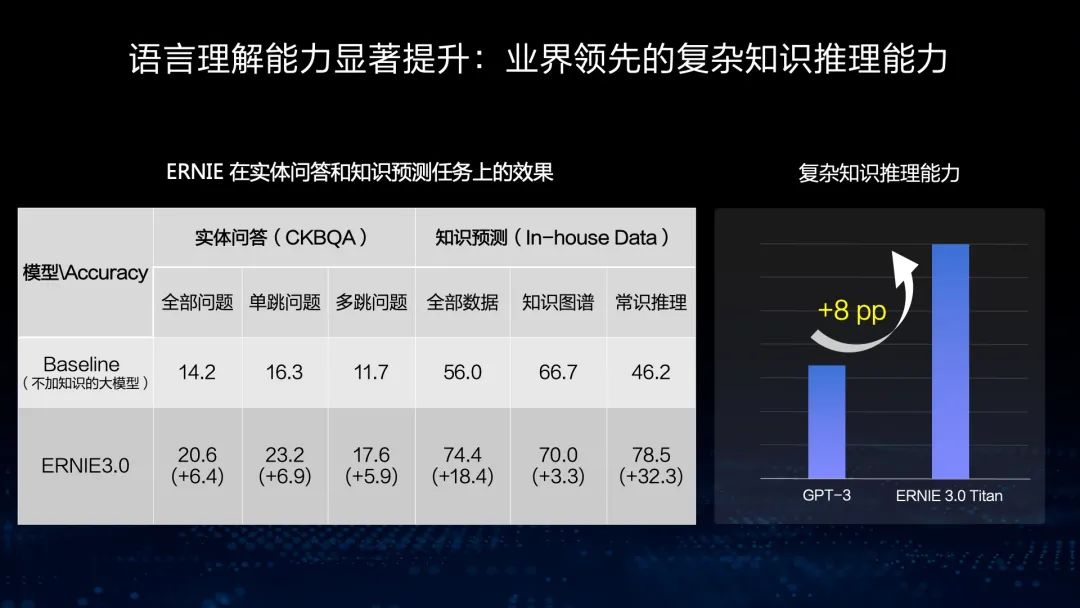
首先,我们来看第一个特色,从大规模知识图谱和海量无结构数据中学习。从这个例子可以看出,我们同时输入大规模图谱和相应无标注、无结构化的文本,通过文本的Mask,能够推理这个知识图谱里的关系,从而使这个模型具有知识推理能力。在右图的知识问答过程图可以看到,ERNIE具有增强的知识推理能力。
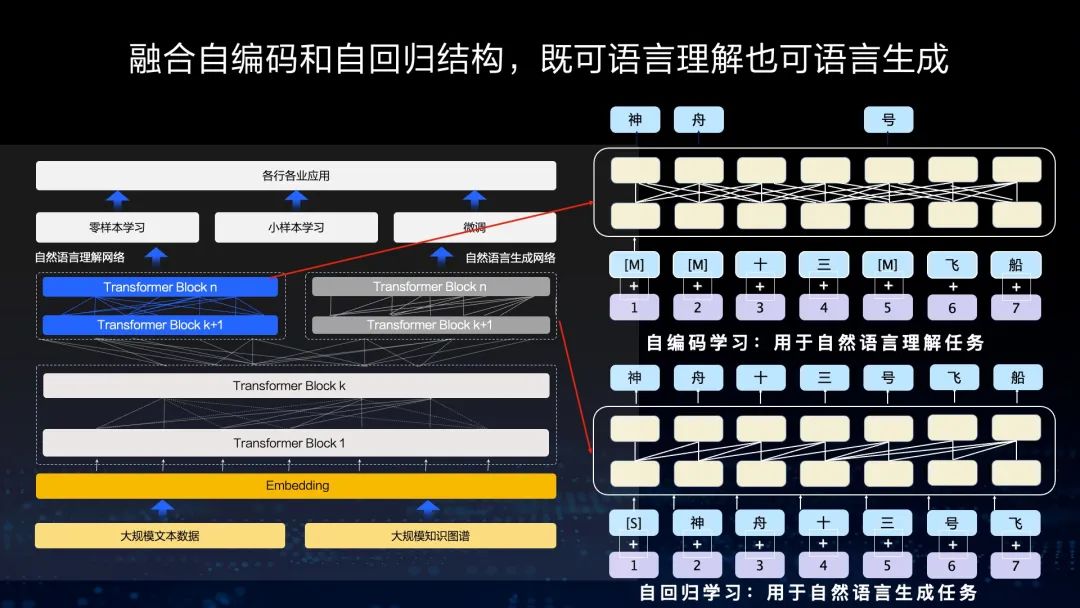
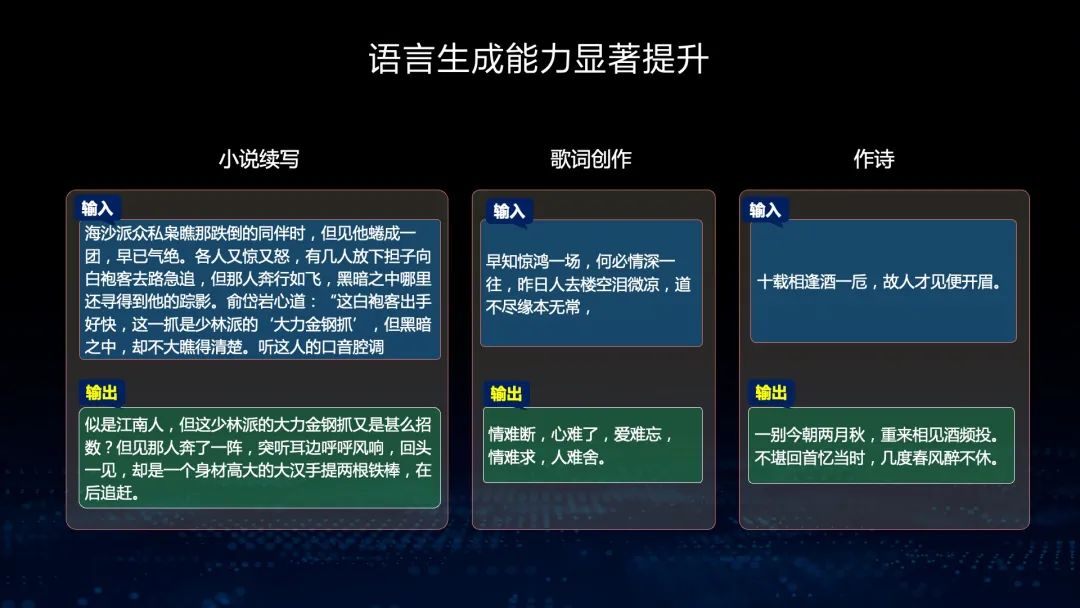
第二个特色是我们融合了自编码和自回归的结构,使模型既可以做语言理解,也可以做语言生成。在做语言理解时,我们可以让模型拥有上下文相关的信息,从而做语言理解。在生成的时候,由于模型只看到了上文,所以只能基于自回归的方式学习。因此,在一个框架中同时能够拥有语言理解和语言生成两种能力非常重要。
第三个特色是基于飞桨的4D混合并行。4D混合并行是指训练的时候同时有4种不同并行方式:数据并行、模型并行、流水线并行和分组参数切片。这四种技术支持了文心大规模的模型训练,因此我们能够节省50%的时间,同时在千亿模型上完成3750亿Token的训练,使我们拥有大规模的文心ERNIE模型。

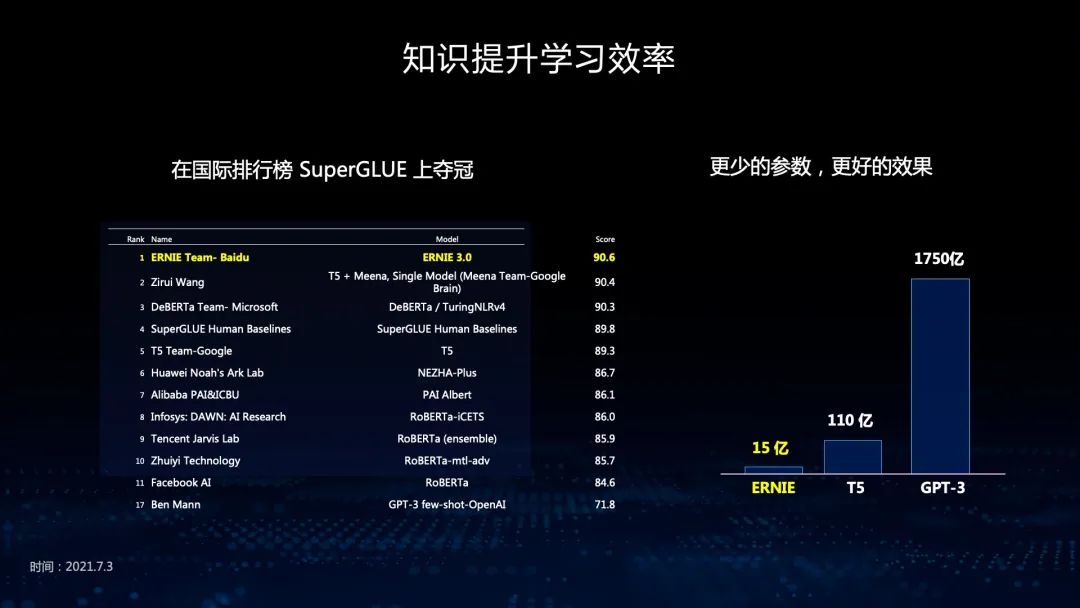
在Fine-tuning任务上,文心ERNIE可以用在不同任务中,用任务数据做微调。文心ERNIE在21类54个Fine-tuning任务中取得领先。这些任务分布很广泛,有语言理解、语言生成、知识推理等。同时,文心ERNIE在零样本和小样本学习的能力也非常好,尤其是在文本分类、阅读理解、知识推理、指代消解等任务中取得全面领先。
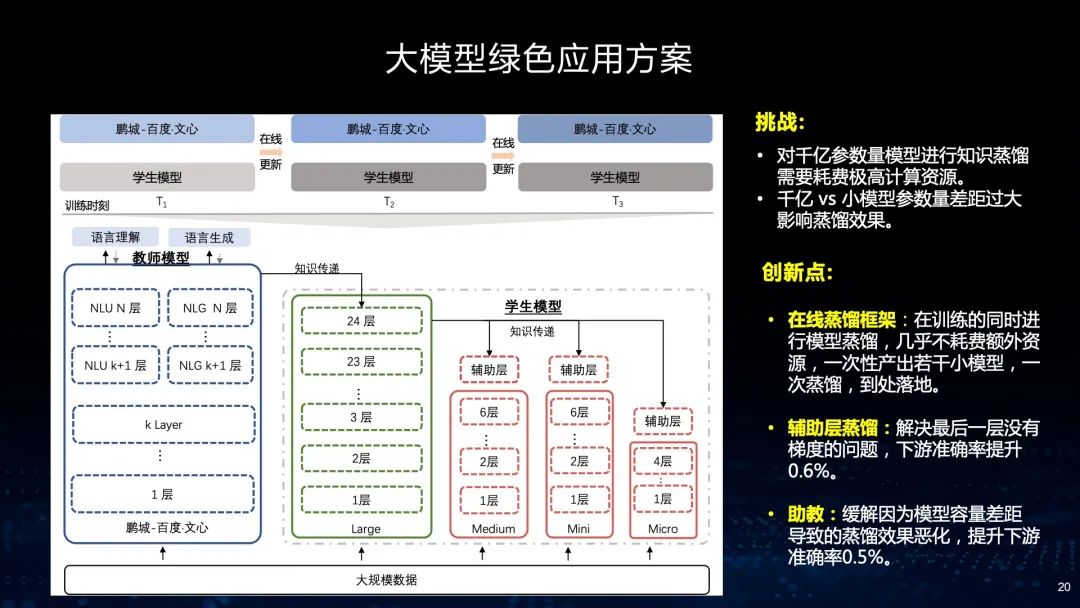
众所周知,大模型的训练成本及使用成本非常高,在实际业务落地应用中面临着相当大的挑战。首先,对千亿模型进行知识蒸馏需要耗费非常高的计算资源,而且,如果从千亿的规模蒸馏到几亿或几千万的数据量,差距过大,影响蒸馏的效果。针对这个问题,我们提出了在线蒸馏的框架,能够降低计算资源的消耗。同时,我们采取辅助蒸馏的方式,首先从千亿规模蒸馏到几十亿,然后到几亿。通过这个过程,我们能使模型蒸馏的效率和效果都得到很好的提升。
从这个实际应用案例中能看到,我们实现了搜索15亿的大模型无损蒸馏,并把这个模型应用在搜索排序的场景中。实际上,在这个过程中,我们将多个教师模型进行蒸馏,使效果得到了非常大的提升。
刚才介绍了文心ERNIE的学习框架以及学习效果。接下来,我将针对知识增强大模型里其他的跨语言大模型、跨模态大模型以及图模型进行解读。
跨语言大模型 文心ERNIE-M
在跨语言的学习过程中,中文和英文这类语种的语料资源较为丰富,然而对于很多小语种来说,比如泰语,我们的资源是不够丰富的。那么,如何利用资源丰富的语种来帮助资源缺乏的语种实现性能提升呢?我们采用了用少量平行语料和大量非平行语料通过回译的机制进行学习的方式来实现。
在这个过程中,我们使用统一模型建模了96种语言,并在5类语言任务上刷新世界最好结果。例如在自然语言推断、语义相似度、阅读理解、命名实体识别、跨语言检索等任务中,我们都获得了极大提升,同时在权威跨语言理解榜单XTREME上获得了第一。
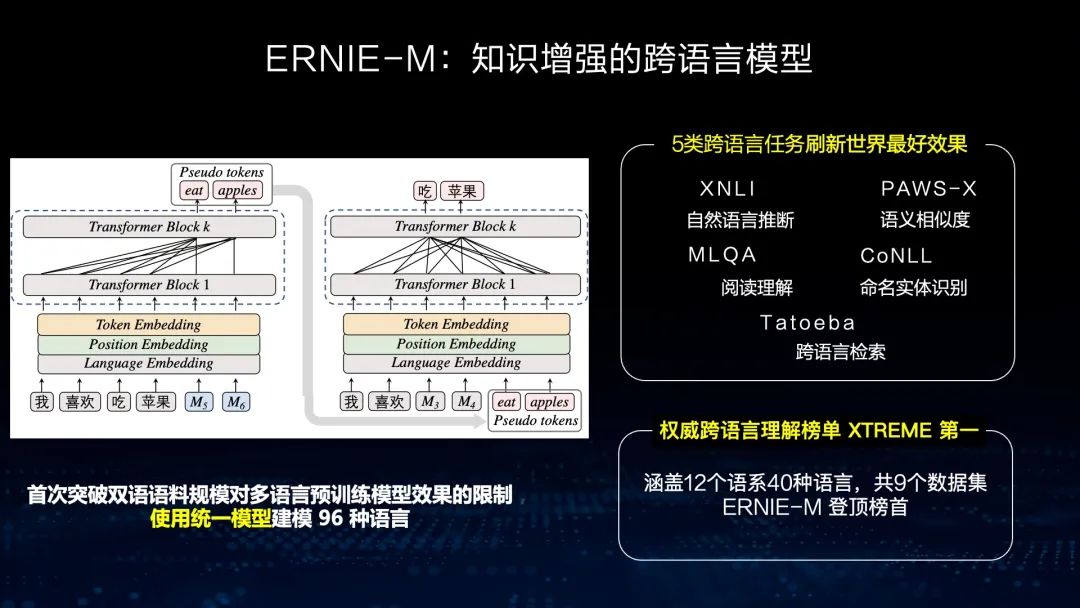
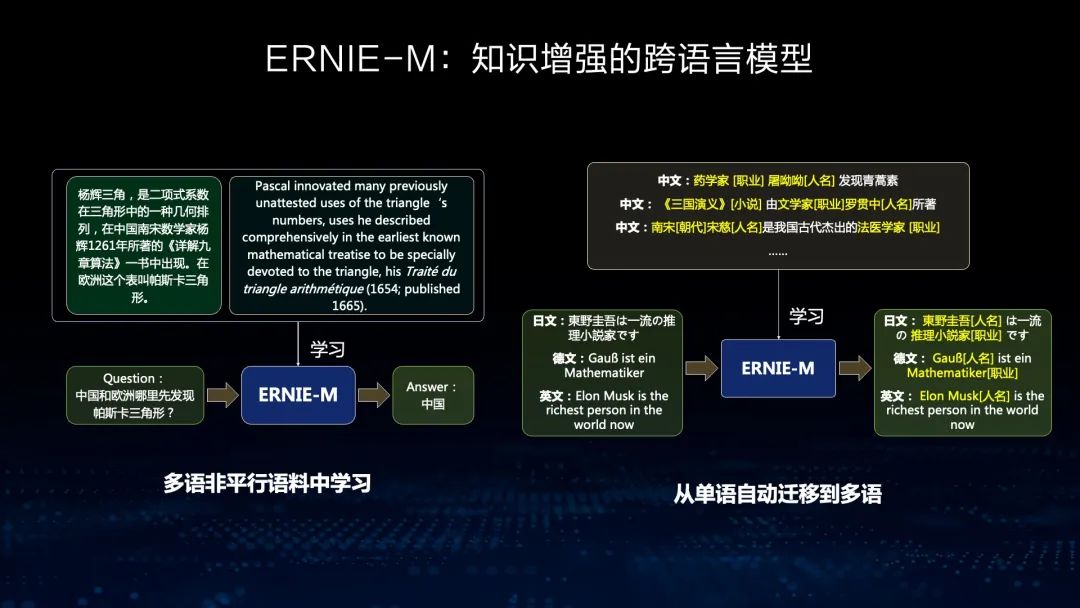
看一个例子,我们通过用非平行语料来学习各个语种中语义的关联,同时将标注丰富语种中的知识(比如中文中一些命名实体的标注)通过跨语言模型迁移到其他语种中,从而实现语言知识的迁移,并提高其他语种下游任务的效果。
跨模态大模型 文心ERNIE-ViL
在文心ERNIE-ViL中,我们在跨模态模型中首次引入了场景知识。引入场景知识的目的是为了理解图像中细粒度的语义,比如说房子、车子和人之间的关系,以及车的颜色等。通过构建场景图的方式,模型能够对图像进行细粒度的语义理解,从而在跨模态任务上取得最好的效果,比如视觉问答、视觉常识推理、图像检索等。我们在权威视觉常识推理任务VCR榜单上也排名第一。
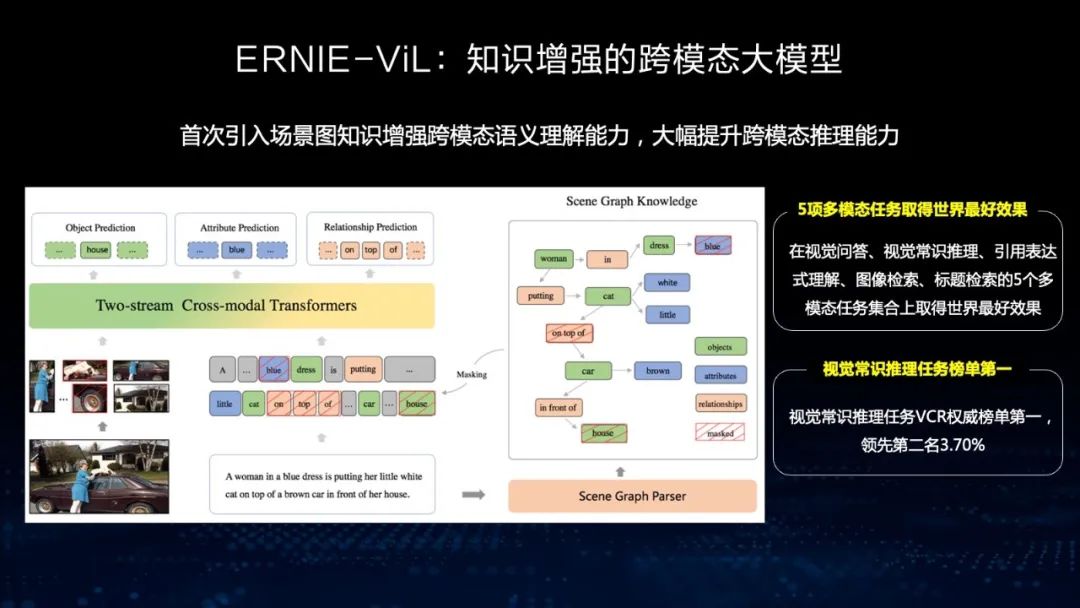
来看一个例子,左边图中一共有几位运动员?我们看到的一共有六个人,到底有几个运动员呢?我们选择了C,这是正确答案。在这个过程中模型要给出解释, 为什么在6个人之中只有5个是运动员?模型要判断其中一个是裁判。这个其实就是通过视觉推理来获得的。这就是在场景图里加入知识,通过它的文字信息去构建场景图,使得模型能够理解图中细粒度的语义。

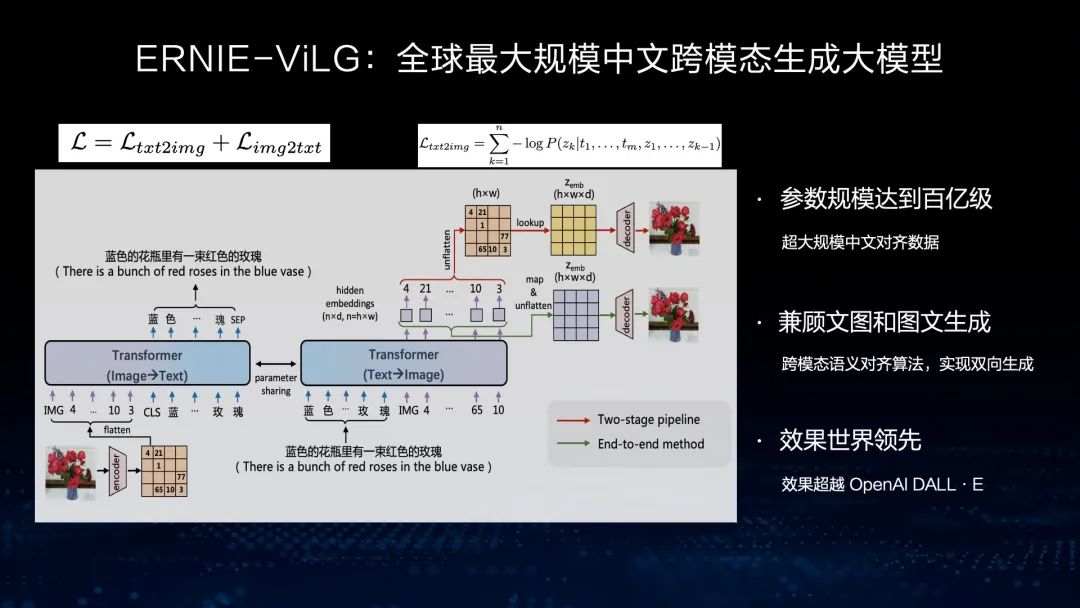
跨模态大模型 文心ERNIE-ViLG

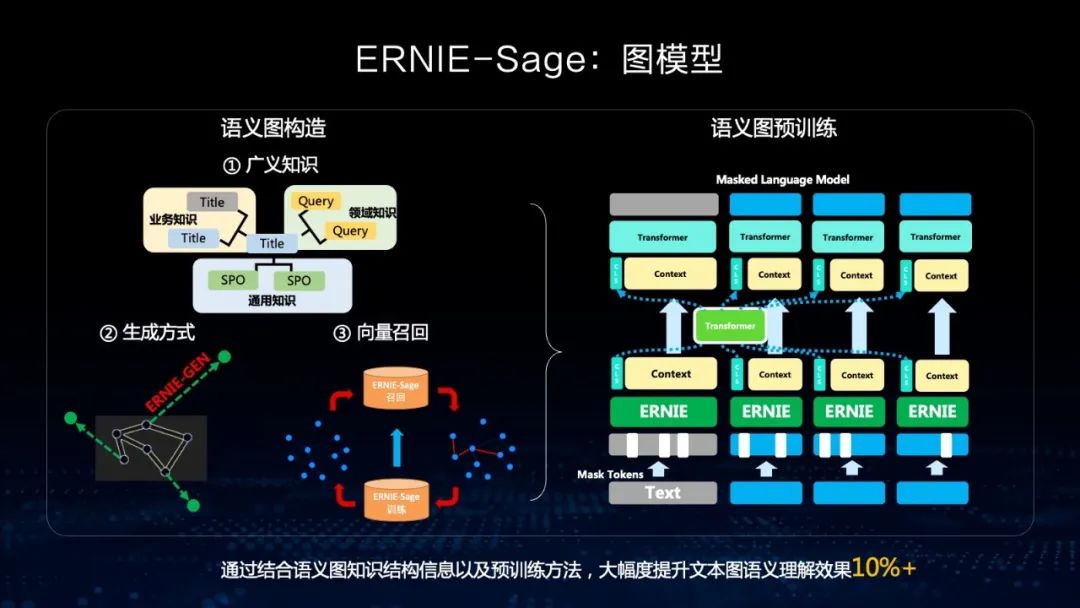
图模型 文心ERNIE-Sage

对话生成模型
文心PLATO
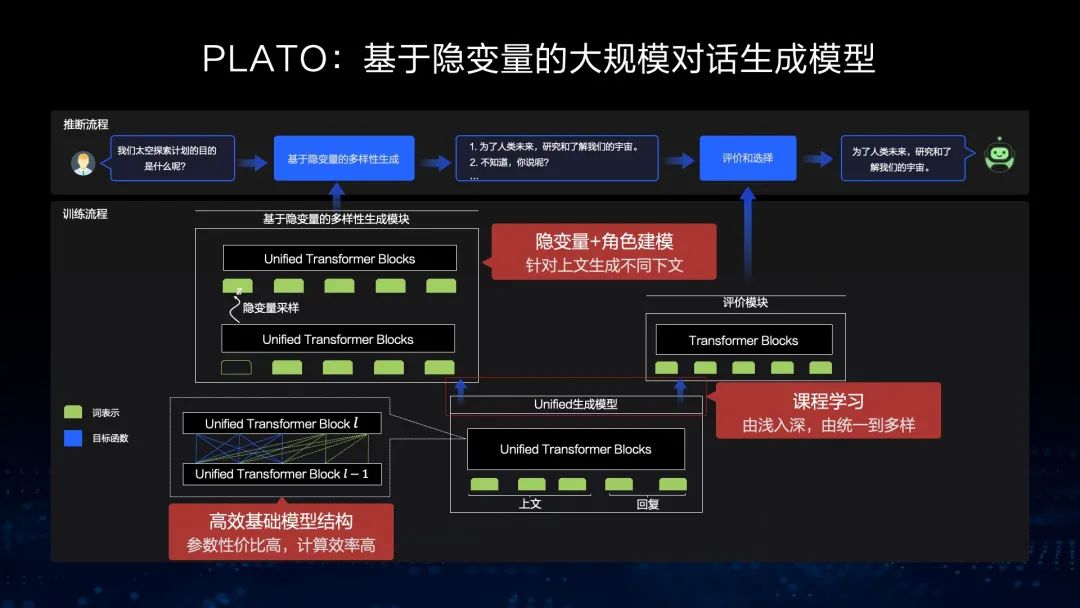
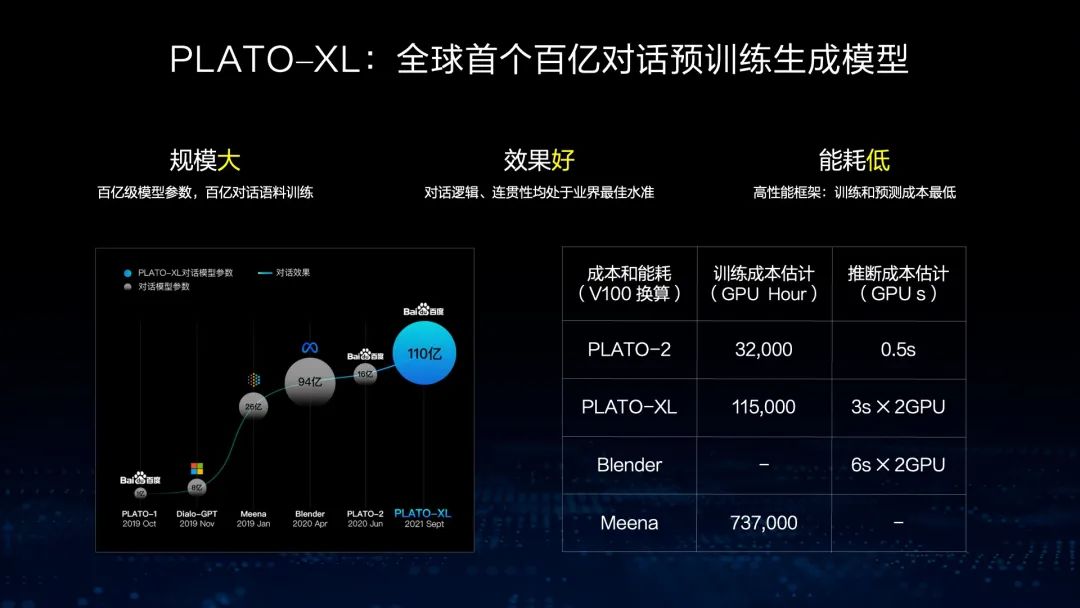
基于这样的框架,去年我们发布了全球首个百亿参数的预训练对话生成模型文心PLATO-XL,它的特点是规模大、效果好、能耗低。从下图左侧可以看出,在参数规模还不是很大的情况下,跟参数规模非常大的效果相比,文心PLATO-XL也能取得相对好的结果,而在能耗方面成本更低。
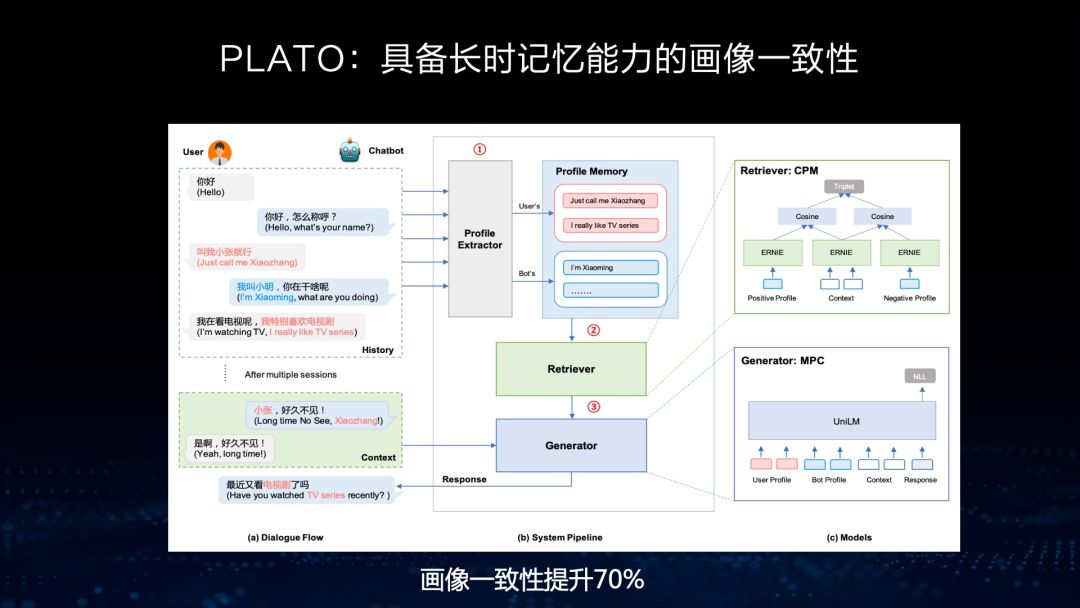
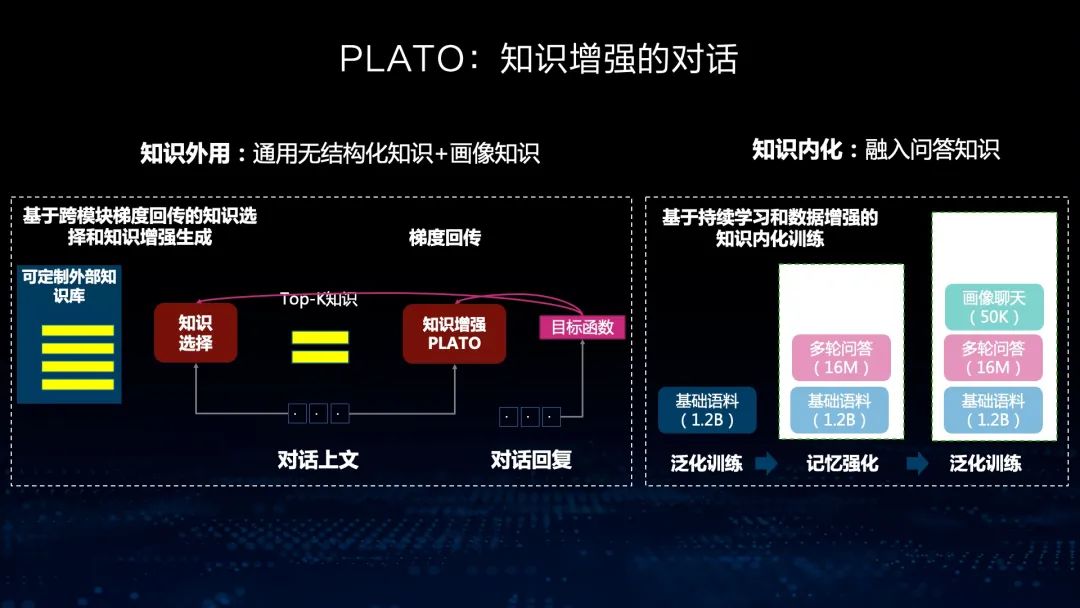
知识外用指的是我们把知识作为一个库,外挂在生成模型之外,通过检索的方法,检索知识加入生成模型中,能够很好地增强回复生成的信息量。知识内化是指我们把各种异构的数据、知识加入到这个聊天语料中一起训练,然后把知识信息学到模型参数中。通过这样的方法,我们能够把知识的准确率提升到90%以上。
举个例子,在医疗领域的对话中,我们用医疗图谱来指导生成。我们采用了两步生成方式,第一步通过上下文的方式生成一个流畅的句子,但是里面的知识可能是不准确的,这个时候利用知识图谱,也就是利用医疗知识图谱修正里面的知识错误,使生成回复中知识的准确率相对提高60%,达到80%以上。这样一个知识增强模型生成的回复,能够保持知识的准确率处于一个相对比较高的水平。
刚才提到,我们在有些任务中需要有对话推荐,如推荐一首音乐、推荐一本书,推荐一个地方去旅游等,这些都需要在对话中满足,也采用了两种方法:一种是层次化的内容规划,另外一种是通过数据增强的方式实现。我们也建立了多种跨类型的对话数据集,并且这些数据集已经发布。通过这样的方法,使多轮对话的合适度和推荐的成功率在90%以上。
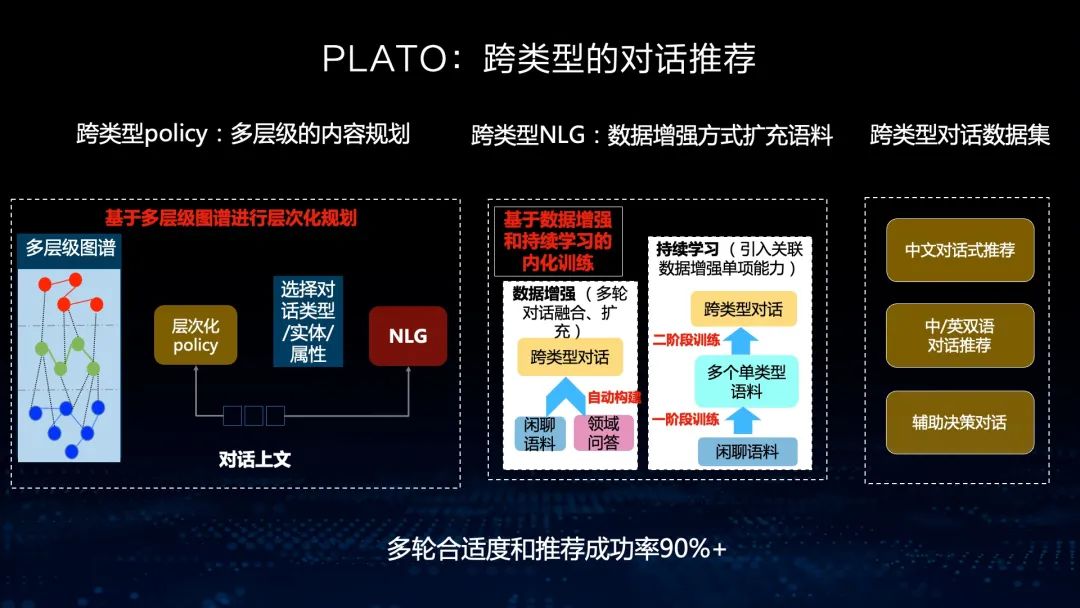
文心PLATO已经全方位开放,希望跟大家一起共建基础生态。我们有开源的KNOVER对话框架,其最新的代码都是开源、开放的。我们还开放了多种对话任务的数据集,供开发者提升和验证自己的对话技术。目前,开放数据下载次数有三万多,开发者也有三万多,尤其是在最近几年,我们也在举行对话相关的比赛,今年在语言与智能技术竞赛中也有一个知识对话的比赛,欢迎大家来参加。

百度语言与知识技术开放平台
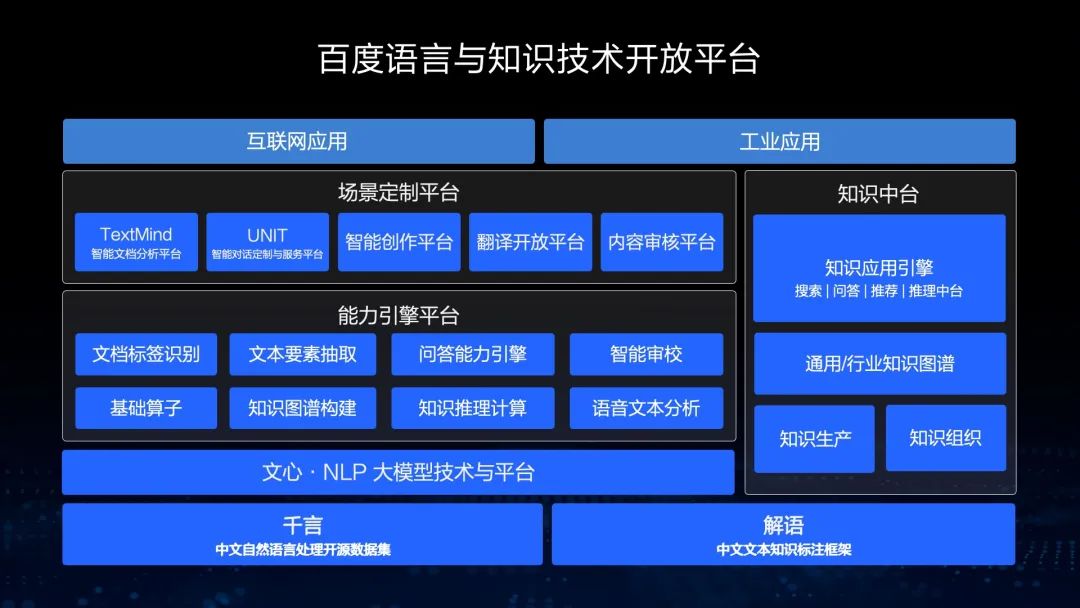
在这个能力引擎平台和知识中台上,我们能够支持各种场景定制,比如,智能文档分析、对话理解、定制与服务平台、智能创作、机器翻译开放平台、内容审核平台等,所有这些平台都可以支持各种互联网应用和工业应用。
今天我的解读就到这里,谢谢大家。
扫描下方二维码关注 【AI大模型】公众号
后台回复【知识增强】获取本次分享PPT
更多文心大模型技术开放日内容,将每周与大家分享,欢迎持续关注我们。
更多阅读

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
文心大模型首场技术开放日已经圆满结束。在本次活动中,文心大模型背后的“技术天团”首次集中亮相,分享大模型技术发展趋势洞察、文心大模型最新技术突破及产业应用实践,为技术爱好者带来一场干货满满的AI技术盛宴。
本篇文章整理自百度技术委员会主席吴华《文心大模型:知识增强的NLP模型详解》直播分享。
预训练大模型能够充分地挖掘大规模无标注数据的潜力,从海量数据中学习知识与规律,就像我们人类的通识教育。从出生开始,我们接受的都是通识教育,到上大学以后,才接受专业教育。在应用大模型以后,通过大模型加任务数据微调的方式,能获得非常好的效果,这已经成为了新的研发范式。
拥有了预训练大模型后,我们可以从之前的手工调参依赖AI专家的阶段进入大规模可复制的大工业落地阶段。
这是我们文心大模型的全景图,包括NLP大模型、CV大模型和跨模态大模型,在此基础上,我们开发了大模型的开发工具、轻量化工具和大规模部署工具,而且我们支持零门槛的AI开发平台以及全功能AI开发平台。
知识增强大模型
文心ERNIE
接下来,首先让我们解读知识增强大模型文心ERNIE。
文心ERNIE:持续学习框架
能够从大规模知识图谱和海量无结构数据中学习,突破异构数据统一表达的瓶颈问题。
能够融合自编码和自回归结构,既可以做语言理解,也可以做语言生成。
基于飞桨4D混合并行技术,能够更高效地支持超大规模模型的预训练。
首先,我们来看第一个特色,从大规模知识图谱和海量无结构数据中学习。从这个例子可以看出,我们同时输入大规模图谱和相应无标注、无结构化的文本,通过文本的Mask,能够推理这个知识图谱里的关系,从而使这个模型具有知识推理能力。在右图的知识问答过程图可以看到,ERNIE具有增强的知识推理能力。
第二个特色是我们融合了自编码和自回归的结构,使模型既可以做语言理解,也可以做语言生成。在做语言理解时,我们可以让模型拥有上下文相关的信息,从而做语言理解。在生成的时候,由于模型只看到了上文,所以只能基于自回归的方式学习。因此,在一个框架中同时能够拥有语言理解和语言生成两种能力非常重要。
第三个特色是基于飞桨的4D混合并行。4D混合并行是指训练的时候同时有4种不同并行方式:数据并行、模型并行、流水线并行和分组参数切片。这四种技术支持了文心大规模的模型训练,因此我们能够节省50%的时间,同时在千亿模型上完成3750亿Token的训练,使我们拥有大规模的文心ERNIE模型。
在Fine-tuning任务上,文心ERNIE可以用在不同任务中,用任务数据做微调。文心ERNIE在21类54个Fine-tuning任务中取得领先。这些任务分布很广泛,有语言理解、语言生成、知识推理等。同时,文心ERNIE在零样本和小样本学习的能力也非常好,尤其是在文本分类、阅读理解、知识推理、指代消解等任务中取得全面领先。
众所周知,大模型的训练成本及使用成本非常高,在实际业务落地应用中面临着相当大的挑战。首先,对千亿模型进行知识蒸馏需要耗费非常高的计算资源,而且,如果从千亿的规模蒸馏到几亿或几千万的数据量,差距过大,影响蒸馏的效果。针对这个问题,我们提出了在线蒸馏的框架,能够降低计算资源的消耗。同时,我们采取辅助蒸馏的方式,首先从千亿规模蒸馏到几十亿,然后到几亿。通过这个过程,我们能使模型蒸馏的效率和效果都得到很好的提升。
从这个实际应用案例中能看到,我们实现了搜索15亿的大模型无损蒸馏,并把这个模型应用在搜索排序的场景中。实际上,在这个过程中,我们将多个教师模型进行蒸馏,使效果得到了非常大的提升。
刚才介绍了文心ERNIE的学习框架以及学习效果。接下来,我将针对知识增强大模型里其他的跨语言大模型、跨模态大模型以及图模型进行解读。
跨语言大模型 文心ERNIE-M
在跨语言的学习过程中,中文和英文这类语种的语料资源较为丰富,然而对于很多小语种来说,比如泰语,我们的资源是不够丰富的。那么,如何利用资源丰富的语种来帮助资源缺乏的语种实现性能提升呢?我们采用了用少量平行语料和大量非平行语料通过回译的机制进行学习的方式来实现。
在这个过程中,我们使用统一模型建模了96种语言,并在5类语言任务上刷新世界最好结果。例如在自然语言推断、语义相似度、阅读理解、命名实体识别、跨语言检索等任务中,我们都获得了极大提升,同时在权威跨语言理解榜单XTREME上获得了第一。
看一个例子,我们通过用非平行语料来学习各个语种中语义的关联,同时将标注丰富语种中的知识(比如中文中一些命名实体的标注)通过跨语言模型迁移到其他语种中,从而实现语言知识的迁移,并提高其他语种下游任务的效果。
跨模态大模型 文心ERNIE-ViL
在文心ERNIE-ViL中,我们在跨模态模型中首次引入了场景知识。引入场景知识的目的是为了理解图像中细粒度的语义,比如说房子、车子和人之间的关系,以及车的颜色等。通过构建场景图的方式,模型能够对图像进行细粒度的语义理解,从而在跨模态任务上取得最好的效果,比如视觉问答、视觉常识推理、图像检索等。我们在权威视觉常识推理任务VCR榜单上也排名第一。
来看一个例子,左边图中一共有几位运动员?我们看到的一共有六个人,到底有几个运动员呢?我们选择了C,这是正确答案。在这个过程中模型要给出解释, 为什么在6个人之中只有5个是运动员?模型要判断其中一个是裁判。这个其实就是通过视觉推理来获得的。这就是在场景图里加入知识,通过它的文字信息去构建场景图,使得模型能够理解图中细粒度的语义。
跨模态大模型 文心ERNIE-ViLG
图模型 文心ERNIE-Sage
对话生成模型
文心PLATO
基于这样的框架,去年我们发布了全球首个百亿参数的预训练对话生成模型文心PLATO-XL,它的特点是规模大、效果好、能耗低。从下图左侧可以看出,在参数规模还不是很大的情况下,跟参数规模非常大的效果相比,文心PLATO-XL也能取得相对好的结果,而在能耗方面成本更低。
知识外用指的是我们把知识作为一个库,外挂在生成模型之外,通过检索的方法,检索知识加入生成模型中,能够很好地增强回复生成的信息量。知识内化是指我们把各种异构的数据、知识加入到这个聊天语料中一起训练,然后把知识信息学到模型参数中。通过这样的方法,我们能够把知识的准确率提升到90%以上。
举个例子,在医疗领域的对话中,我们用医疗图谱来指导生成。我们采用了两步生成方式,第一步通过上下文的方式生成一个流畅的句子,但是里面的知识可能是不准确的,这个时候利用知识图谱,也就是利用医疗知识图谱修正里面的知识错误,使生成回复中知识的准确率相对提高60%,达到80%以上。这样一个知识增强模型生成的回复,能够保持知识的准确率处于一个相对比较高的水平。
刚才提到,我们在有些任务中需要有对话推荐,如推荐一首音乐、推荐一本书,推荐一个地方去旅游等,这些都需要在对话中满足,也采用了两种方法:一种是层次化的内容规划,另外一种是通过数据增强的方式实现。我们也建立了多种跨类型的对话数据集,并且这些数据集已经发布。通过这样的方法,使多轮对话的合适度和推荐的成功率在90%以上。
文心PLATO已经全方位开放,希望跟大家一起共建基础生态。我们有开源的KNOVER对话框架,其最新的代码都是开源、开放的。我们还开放了多种对话任务的数据集,供开发者提升和验证自己的对话技术。目前,开放数据下载次数有三万多,开发者也有三万多,尤其是在最近几年,我们也在举行对话相关的比赛,今年在语言与智能技术竞赛中也有一个知识对话的比赛,欢迎大家来参加。
百度语言与知识技术开放平台
在这个能力引擎平台和知识中台上,我们能够支持各种场景定制,比如,智能文档分析、对话理解、定制与服务平台、智能创作、机器翻译开放平台、内容审核平台等,所有这些平台都可以支持各种互联网应用和工业应用。
今天我的解读就到这里,谢谢大家。
扫描下方二维码关注 【AI大模型】公众号
后台回复【知识增强】获取本次分享PPT
更多文心大模型技术开放日内容,将每周与大家分享,欢迎持续关注我们。
更多阅读
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~