随着人工智能技术的逐渐成熟,计算机视觉、语音、自然语言处理等技术在金融行业的应用从广度和深度上都在加速,这不仅降低了金融机构的运营和风险成本,而且有助于提升客户的满意度,比如:利用OCR技术快速处理海量表格做信息结构化抽取和存储,大幅提升从业人员工作效率;利用NLP技术实现智能问答解决方案,帮助用户即使没有复杂的金融背景知识也能快速找到自己需要的信息。
本次飞桨产业实践范例库开源表单自动识别、保险智能问答两个金融行业典型场景应用,提供了从数据准备、模型训练及优化的全流程可复用方案,降低产业落地门槛。
⭐项目链接⭐
https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph/applications
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications
所有源码及教程均已开源,欢迎大家star鼓励~
表单识别旨在识别各种具有表格性质的证件(如房产证、营业执照、个人信息表、发票等)上的关键键值对(如姓名-张三),其广泛应用于银行、证券、公司财务等领域,具有很高的商业价值。本次范例项目开源了表单识别全流程方案,能够在多个场景快速实现能力迁移。
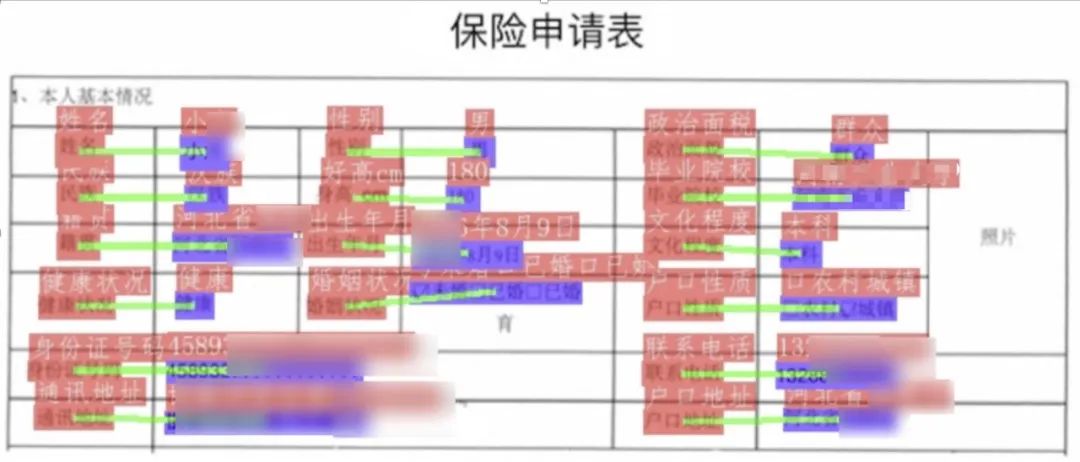
图1 保险申请单展示
图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
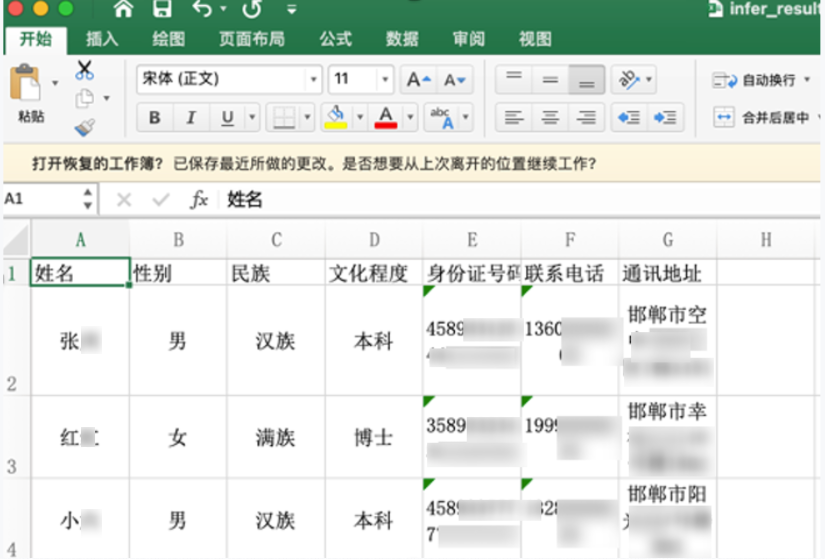
我们将上述OCR识别结果和关键键值对的匹配关系输出到Excel中,结果如图2所示,实现智能化录入,便于进一步整理。
图2 结果导出到Excel效果
场景难点
金融表单版样式多:常见表单类型众多,而且同一类型的表单版式也比较多,对方案的兼容能力要较高;
传统技术方案泛化效果不满足:传统单模态技术方案(只利用图像数据的OCR提取)模型泛化性差、依赖大量训练数据。
方案设计
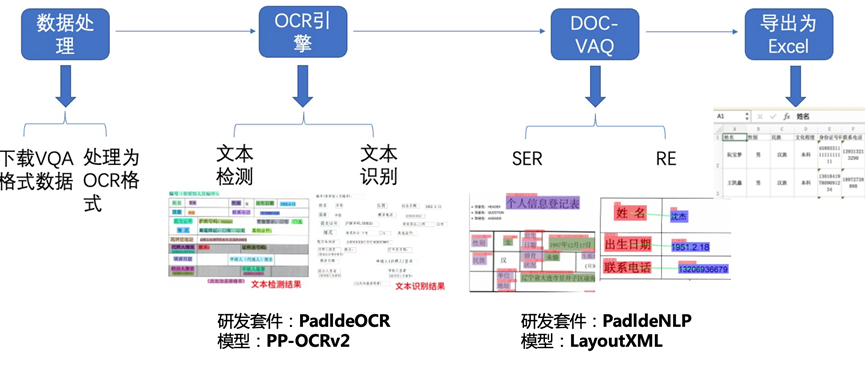
OCR阶段选取了PaddleOCR的PP-OCRv2模型,主要由文本检测和文本识别两个模块组成。DOC-VQA文档视觉问答阶段基于PaddleNLP自然语言处理算法库实现的LayoutXLM模型,支持基于多模态方法的语义实体识别(Semantic Entity Recognition, SER)以及关系抽取(Relation Extraction, RE)任务。该应用从实际的痛点出发,涉及数据处理、预训练模型使用、模型优化(超参数调节、fine-tune、添加真实场景数据等)、模型评估、模型导出、模型预测。
图3 表单识别解决方案流程图
模型优化策略和效果
文本检测
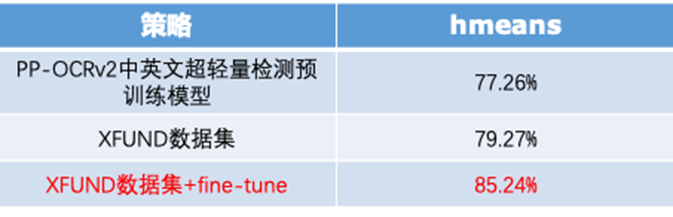
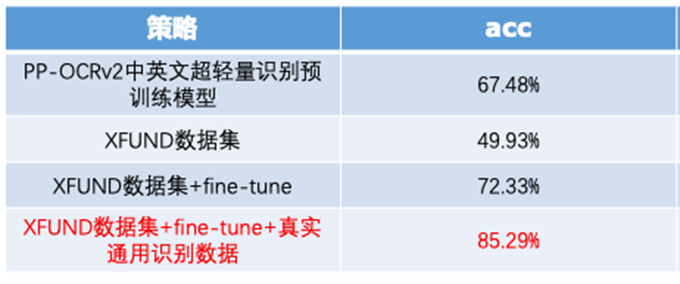
首先利用PP-OCRv2中英文超轻量检测预训练模型在XFUND数据集(微软提出的一个多语言数据集,包含多种类型的表单数据)上评估,然后在XFUND数据集上微调进一步提升模型效果。
文本识别
同上,我们首先也采用PP-OCRv2中英文超轻量识别预训练模型、XFUND数据集+fine-tune、XFUND数据集+fine-tune+真实通用识别数据3种方案。
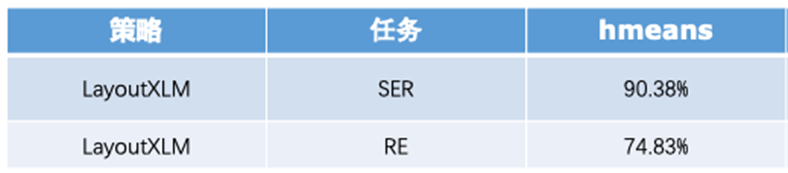
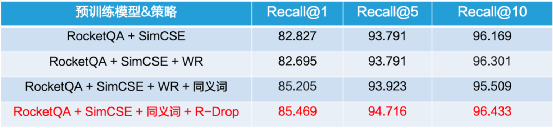
本方案的DOC- VQA文档视觉问答阶段基于LayoutXLM模型,包含SER和RE,使用在XFUND的中文数据集上的预训练模型,模型性能如下。
范例使用工具介绍
保险智能问答方案
在保险领域,用户常见的问题占了60%~70%,这部分重复性工作费时费力,需要更有效率的处理方式。智能问答能够准确理解用户的意图,并直接给出精确的答案,极大节省了用户及工作人员的时间。本次飞桨产业实践范例,基于PaddleNLP实现智能问答方案,在没有标注数据的情况下,也可以得到一个效果不错的智能问答模型。
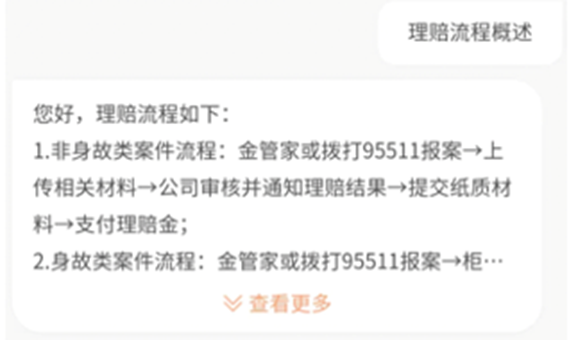
图4 保险智能问答展示
场景难点
专业性强:基于保险关键字的问答匹配的方法优化起来繁琐,不能很好的对句子级别的语义信息进行建模,无法跨越句子级别的语义鸿沟;
无标注数据:在系统搭建初期或者数据体量比较小的场景,并没有很多标注好的问句对,并且标注的成本很高。
方案设计
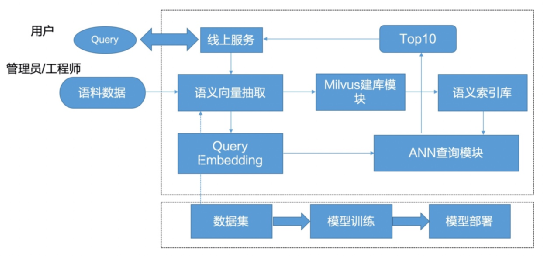
作为技术方案,并且使用飞桨服务化部署框架Paddle Serving 进行服务化部署。该方案从实际的痛点出发,然后涉及网络选择和调整、策略增强、超参数调节、预训练模型使用5个方面,对各个模块的模型进行优化,使用少量的领域数据集做微调,最终在小成本代价下能够得到效果不错的模型。
图5 项目方案说明
模型优化策略和效果
部署方案
范例使用工具介绍
精彩课程预告
为了让小伙伴们更便捷地实践和应用金融行业中表单自动识别和保险智能问答技术方案,百度高级工程师将于4月27日和4月28日19:00为大家深度解析从数据准备、方案设计到模型优化部署的开发全流程,手把手教大家进行代码实践。
扫码报名直播课,加入技术交流群
参考
[1] https://github.com/PaddlePaddle/RocketQA
相关阅读

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
随着人工智能技术的逐渐成熟,计算机视觉、语音、自然语言处理等技术在金融行业的应用从广度和深度上都在加速,这不仅降低了金融机构的运营和风险成本,而且有助于提升客户的满意度,比如:利用OCR技术快速处理海量表格做信息结构化抽取和存储,大幅提升从业人员工作效率;利用NLP技术实现智能问答解决方案,帮助用户即使没有复杂的金融背景知识也能快速找到自己需要的信息。
本次飞桨产业实践范例库开源表单自动识别、保险智能问答两个金融行业典型场景应用,提供了从数据准备、模型训练及优化的全流程可复用方案,降低产业落地门槛。
⭐项目链接⭐
https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph/applications
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications
所有源码及教程均已开源,欢迎大家star鼓励~
表单识别旨在识别各种具有表格性质的证件(如房产证、营业执照、个人信息表、发票等)上的关键键值对(如姓名-张三),其广泛应用于银行、证券、公司财务等领域,具有很高的商业价值。本次范例项目开源了表单识别全流程方案,能够在多个场景快速实现能力迁移。
图1 保险申请单展示
图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
我们将上述OCR识别结果和关键键值对的匹配关系输出到Excel中,结果如图2所示,实现智能化录入,便于进一步整理。
图2 结果导出到Excel效果
场景难点
金融表单版样式多:常见表单类型众多,而且同一类型的表单版式也比较多,对方案的兼容能力要较高;
传统技术方案泛化效果不满足:传统单模态技术方案(只利用图像数据的OCR提取)模型泛化性差、依赖大量训练数据。
方案设计
OCR阶段选取了PaddleOCR的PP-OCRv2模型,主要由文本检测和文本识别两个模块组成。DOC-VQA文档视觉问答阶段基于PaddleNLP自然语言处理算法库实现的LayoutXLM模型,支持基于多模态方法的语义实体识别(Semantic Entity Recognition, SER)以及关系抽取(Relation Extraction, RE)任务。该应用从实际的痛点出发,涉及数据处理、预训练模型使用、模型优化(超参数调节、fine-tune、添加真实场景数据等)、模型评估、模型导出、模型预测。
图3 表单识别解决方案流程图
模型优化策略和效果
文本检测
首先利用PP-OCRv2中英文超轻量检测预训练模型在XFUND数据集(微软提出的一个多语言数据集,包含多种类型的表单数据)上评估,然后在XFUND数据集上微调进一步提升模型效果。
文本识别
同上,我们首先也采用PP-OCRv2中英文超轻量识别预训练模型、XFUND数据集+fine-tune、XFUND数据集+fine-tune+真实通用识别数据3种方案。
本方案的DOC- VQA文档视觉问答阶段基于LayoutXLM模型,包含SER和RE,使用在XFUND的中文数据集上的预训练模型,模型性能如下。
范例使用工具介绍
保险智能问答方案
在保险领域,用户常见的问题占了60%~70%,这部分重复性工作费时费力,需要更有效率的处理方式。智能问答能够准确理解用户的意图,并直接给出精确的答案,极大节省了用户及工作人员的时间。本次飞桨产业实践范例,基于PaddleNLP实现智能问答方案,在没有标注数据的情况下,也可以得到一个效果不错的智能问答模型。
图4 保险智能问答展示
场景难点
专业性强:基于保险关键字的问答匹配的方法优化起来繁琐,不能很好的对句子级别的语义信息进行建模,无法跨越句子级别的语义鸿沟;
无标注数据:在系统搭建初期或者数据体量比较小的场景,并没有很多标注好的问句对,并且标注的成本很高。
方案设计
作为技术方案,并且使用飞桨服务化部署框架Paddle Serving 进行服务化部署。该方案从实际的痛点出发,然后涉及网络选择和调整、策略增强、超参数调节、预训练模型使用5个方面,对各个模块的模型进行优化,使用少量的领域数据集做微调,最终在小成本代价下能够得到效果不错的模型。
图5 项目方案说明
模型优化策略和效果
部署方案
范例使用工具介绍
精彩课程预告
为了让小伙伴们更便捷地实践和应用金融行业中表单自动识别和保险智能问答技术方案,百度高级工程师将于4月27日和4月28日19:00为大家深度解析从数据准备、方案设计到模型优化部署的开发全流程,手把手教大家进行代码实践。
扫码报名直播课,加入技术交流群
参考
[1] https://github.com/PaddlePaddle/RocketQA
相关阅读
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~