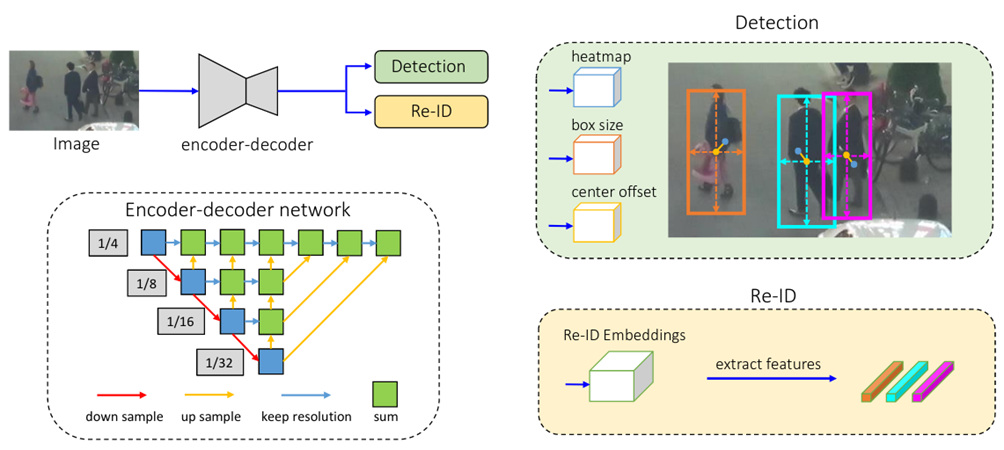
图1 MOT 行人检测[1]
本文采用的FairMOT模型在MOT-17数据集上测试结果达到了MOTA65.3。这篇文章将专注于展示如何将FairMOT转换为通用格式的ONNX模型,并且部署到CPU上,使用OpenVINO来做预测。
为什么选择Intel OpenVINO
是否有一种工具可以在最后部署环节拥有统一的接口,可重用代码呢?
答案是肯定的。IntelOpenVINO(以下简称OV)就是这样的一款工具。OV是Intel发布的一个综合性工具包, 其是用于快速开发解决各种任务的应用程序和解决方案。 它包括视觉、自动语音识别、自然语言处理、推荐系统等。该工具包基于最新一代人工神经网络,包括卷积神经网络(CNN)、Recurrent Network和基于注意力的网络,可跨英特尔® 硬件扩展计算机视觉和非视觉工作负载,从而最大限度地提高性能。有了它的帮助,AI工程师可以在模型构建和训练阶段,选择自己熟悉的AI框架来搭建起符合要求的个性化神经网络,而在后期使用OpenVINO快速构建起专属的解决方案,提供统一的接口,并在Intel®的硬件上优化性能以及运行。
面向的读者和需要的软件
第二步: 安装GPU或者CPU版本的飞桨框架:
对于选择GPU还是CPU版本的飞桨框架,主要是根据您的硬件配置。如果您有NVIDIA最近几年的显卡例如:RTX 3080,RTX 2070, RTX 1060等,那么请选择安装GPU版本。查看CUDA对GPU支持的详细信息,请阅读NVIDIA官网的GPU Compute Capability。
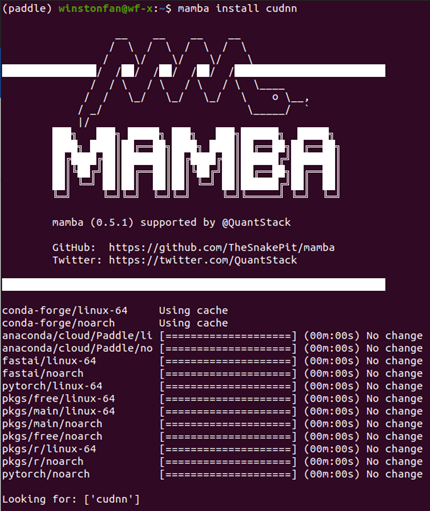
1)安装NVIDIA的cudnn
conda install cudnn
安装的时候也可以把conda 换成Mamba,从而得到更快的下载速度。
安装飞桨的时候, 可以在飞桨的官网获取最新的指南,我以Ubuntu 20.04的系统为例(如果您用其他的系统,那么请选择相应的选项)。
图3:安装飞桨框架
具体命令如下:
conda install paddlepaddle-gpu==2.2.1 cudatoolkit=11.2 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
3)安装PaddleDetection
安装完底层框架之后,就可以开始安装PaddleDetection啦。同理, 您的好朋友是它的Github仓库。安装代码如下:
pip install paddledet
模型转换
本篇文章使用到的是 fairmot_hrnetv2_w18_dlafpn_30e_576x320, 更多不同尺寸和准确度的FairMOT模型可以在这里(FairMOT: Onthe Fairness of Detection and Re-Identification in Multiple Object Tracking)找到
第一阶段结束。如果对怎样导出飞桨模型的过程感兴趣,请查看本系列之前的文章中的4.1章节。
转模型到ONNX:飞桨模型→ONNX
pip install paddle2onnx
将飞桨模型转化成ONNX格式:(请确保指向模型的路径是正确的)
这里要特别指出两点:
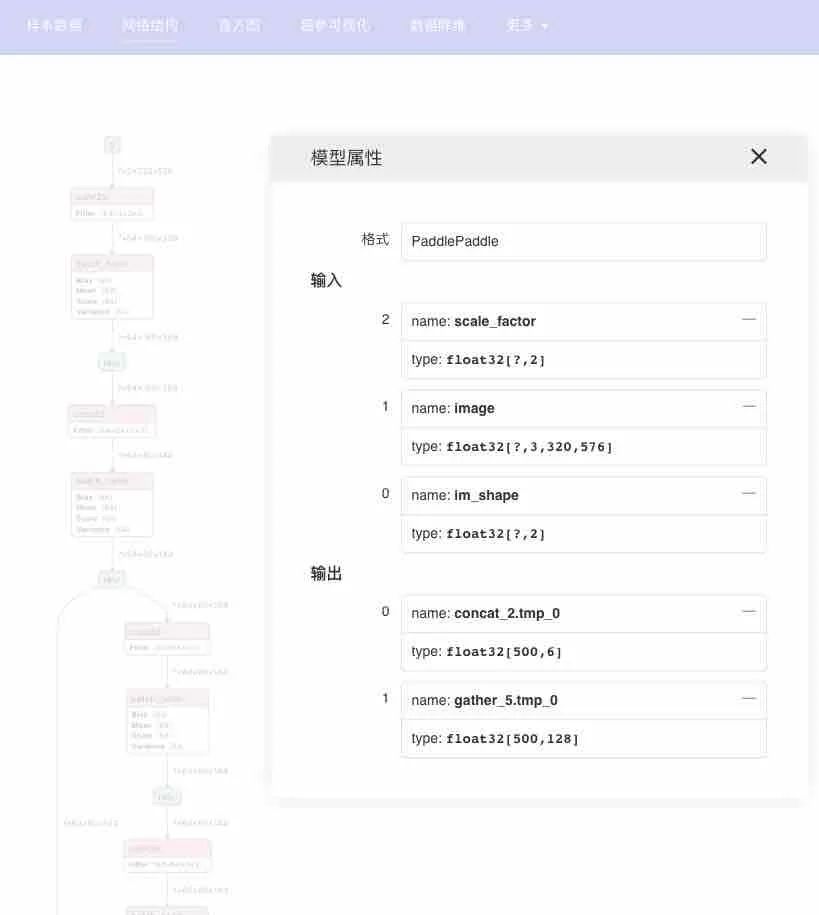
1.PaddleDetection下的FaiMOT模型并没有固定下来模型的 input(见图6),但是OpenVINO不接受非固定input。所以解决的方法也很明确,就是要把飞桨模型中未固定的参数固定下来。
在Paddle2ONNX的命令行参数中,有一个参数叫做input_shape_dict,我们可以通过这个参数做文章把需要固定下来的参数都指定好。
那么自然,我们就要知道到底有哪些参数要固定下来呢?
2.FairMOT在input里需要3个参数,分别是input_shape, scale_factor 和im_shape。
而这3个参数是如何发现的呢? 一个小技巧就是用模型可视化工具(VisualDL)先来看一下这个模型:
图6: FairMOT的概述图[1]
由上图可以看出在INPUTS里面有3个部分,分别是之前提到过的:scale_factor,image以及im_shape。这样我们就知道该如何构建input_shape_dict的参数值。
{'image': [1, 3, 320, 576],'scale_factor': [1, 2], 'im_shape': [1, 2]}
接下来记住将 model_dir,model_filename,以及params_filename和save_file替换成自己的文件路径,之后类似的路径也请替换成自己电脑上的相应路径,不再赘述。
--model_dir是转换后的模型要保存的目录
--enable_onnx_checker 启动它可以让转换程序帮我们检查模型
您可能遇到的问题:
Opset_version的默认值是9, 如果您的框架比较新,需要把这个opset_version调高到12。
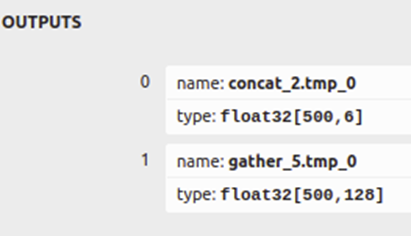
在ONNX模型转换好后,我们可以快速看一下FairMOT模型有哪些输出。
7: FairMOT的输出结构[1]
这2个通道的结果,正是FairMOT检测出来的 detections和embeddings,之后我们便会用到。
验证转换后的ONNX模型
接下来是最重要的过程。整体思路是:
1. 首先我们需要得到一个ExecutableNetwork;
2. 然后还要得知输入输出频道的名字;
3. 准备好输入数据(即对输入图像调整大小resize, 标准化normalize)。在标准化的时候,mean和std很重要。如果在自己预处理输入图像的时候,用的标准化参数mean,std的值和模型训练时候用的数值有所不同,那么会严重影响预测精准度。这个mean和std的数值可以在PaddleDetection项目中相应的模型配置文件fairmot_hrnetv2_w18_dlafpn_30e_576x320.yml中找到。
4. 把已处理好的图像传递到ExecutableNetwork里的infer()中即可得到预测结果。
5. 最后我们需要将得到的预测结果:pred_dets, pred_embs 做postprocess,便可得到最后的结果。
完整代码可以在这里查看:Intel-OpenVINO-Paddle(https://github.com/franva/Intel-OpenVINO-Paddle/tree/main/PaddleDetection/FairMot)
我们来看一下成果。
图8: FairMOT检测结果
可以看出识别率还是非常之高,如果想更加谨慎一些,可以通过增加postprocess()中的threshold来确保降低误判率。
模型性能和吞吐量
测试好模型之后,我们还可以检查一下模型的性能和吞吐量。幸运的是,Intel DevCloud已经提供了现有的工具来帮助我们快速完成这项工作。这里是它的Jupyter Notebooks平台,在使用前需要先注册账户。
Jupyter Notebooks平台:
https://devcloud.intel.com/zh/edge/advanced/connect_and_create/
随机挑选几套硬件搭配,来看一下刚转换好的ONNX模型性能:
表格1:Benchmark ofPP-Tracking FairMOT 576*320 模型
关于如何使用 Intel®DevCloud,更详细的步骤请参考:《使用 OpenVINO™ 工具套件优化和部署 DenseNet 模型并在 DevCloud 上完成性能测试》。
至此,整个流程结束。恭喜大家成功的转换了模型并且部署到了设备上。期待看到你们更多的精彩应用!
Github链接:
https://github.com/franva/Intel-OpenVINO-Paddle/tree/main/PaddleDetection/FairMot
总结
本文开头介绍了多目标追踪MOT的广泛的适用性,阐述了用IntelOpenVINO部署模型的重要性。快速介绍了Intel的OpenVINO。然后以一个训练好的百度飞桨模型为例开始,逐步地带着大家把模型转换到了通用型ONNX格式,这和之前的教程不同,同时详细介绍了OV和FairMOT的工作流程以及代码。相信大家对于不同的模型,只需要做适量的改动,便可以快速独立的开发属于自己的AI应用程序。
参考文献:
[1]:MOT行人检测,https://arxiv.org/pdf/2004.01888.pdf
[2]:百度,PaddleDetection- FairMOT
相关阅读

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
图1 MOT 行人检测[1]
本文采用的FairMOT模型在MOT-17数据集上测试结果达到了MOTA65.3。这篇文章将专注于展示如何将FairMOT转换为通用格式的ONNX模型,并且部署到CPU上,使用OpenVINO来做预测。
为什么选择Intel OpenVINO
是否有一种工具可以在最后部署环节拥有统一的接口,可重用代码呢?
答案是肯定的。IntelOpenVINO(以下简称OV)就是这样的一款工具。OV是Intel发布的一个综合性工具包, 其是用于快速开发解决各种任务的应用程序和解决方案。 它包括视觉、自动语音识别、自然语言处理、推荐系统等。该工具包基于最新一代人工神经网络,包括卷积神经网络(CNN)、Recurrent Network和基于注意力的网络,可跨英特尔® 硬件扩展计算机视觉和非视觉工作负载,从而最大限度地提高性能。有了它的帮助,AI工程师可以在模型构建和训练阶段,选择自己熟悉的AI框架来搭建起符合要求的个性化神经网络,而在后期使用OpenVINO快速构建起专属的解决方案,提供统一的接口,并在Intel®的硬件上优化性能以及运行。
面向的读者和需要的软件
第二步: 安装GPU或者CPU版本的飞桨框架:
对于选择GPU还是CPU版本的飞桨框架,主要是根据您的硬件配置。如果您有NVIDIA最近几年的显卡例如:RTX 3080,RTX 2070, RTX 1060等,那么请选择安装GPU版本。查看CUDA对GPU支持的详细信息,请阅读NVIDIA官网的GPU Compute Capability。
1)安装NVIDIA的cudnn
conda install cudnn
安装的时候也可以把conda 换成Mamba,从而得到更快的下载速度。
安装飞桨的时候, 可以在飞桨的官网获取最新的指南,我以Ubuntu 20.04的系统为例(如果您用其他的系统,那么请选择相应的选项)。
图3:安装飞桨框架
具体命令如下:
conda install paddlepaddle-gpu==2.2.1 cudatoolkit=11.2 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
3)安装PaddleDetection
安装完底层框架之后,就可以开始安装PaddleDetection啦。同理, 您的好朋友是它的Github仓库。安装代码如下:
pip install paddledet
模型转换
本篇文章使用到的是 fairmot_hrnetv2_w18_dlafpn_30e_576x320, 更多不同尺寸和准确度的FairMOT模型可以在这里(FairMOT: Onthe Fairness of Detection and Re-Identification in Multiple Object Tracking)找到
第一阶段结束。如果对怎样导出飞桨模型的过程感兴趣,请查看本系列之前的文章中的4.1章节。
转模型到ONNX:飞桨模型→ONNX
pip install paddle2onnx
将飞桨模型转化成ONNX格式:(请确保指向模型的路径是正确的)
这里要特别指出两点:
1.PaddleDetection下的FaiMOT模型并没有固定下来模型的 input(见图6),但是OpenVINO不接受非固定input。所以解决的方法也很明确,就是要把飞桨模型中未固定的参数固定下来。
在Paddle2ONNX的命令行参数中,有一个参数叫做input_shape_dict,我们可以通过这个参数做文章把需要固定下来的参数都指定好。
那么自然,我们就要知道到底有哪些参数要固定下来呢?
2.FairMOT在input里需要3个参数,分别是input_shape, scale_factor 和im_shape。
而这3个参数是如何发现的呢? 一个小技巧就是用模型可视化工具(VisualDL)先来看一下这个模型:
图6: FairMOT的概述图[1]
由上图可以看出在INPUTS里面有3个部分,分别是之前提到过的:scale_factor,image以及im_shape。这样我们就知道该如何构建input_shape_dict的参数值。
{'image': [1, 3, 320, 576],'scale_factor': [1, 2], 'im_shape': [1, 2]}
接下来记住将 model_dir,model_filename,以及params_filename和save_file替换成自己的文件路径,之后类似的路径也请替换成自己电脑上的相应路径,不再赘述。
--model_dir是转换后的模型要保存的目录
--enable_onnx_checker 启动它可以让转换程序帮我们检查模型
您可能遇到的问题:
Opset_version的默认值是9, 如果您的框架比较新,需要把这个opset_version调高到12。
在ONNX模型转换好后,我们可以快速看一下FairMOT模型有哪些输出。
7: FairMOT的输出结构[1]
这2个通道的结果,正是FairMOT检测出来的 detections和embeddings,之后我们便会用到。
验证转换后的ONNX模型
接下来是最重要的过程。整体思路是:
1. 首先我们需要得到一个ExecutableNetwork;
2. 然后还要得知输入输出频道的名字;
3. 准备好输入数据(即对输入图像调整大小resize, 标准化normalize)。在标准化的时候,mean和std很重要。如果在自己预处理输入图像的时候,用的标准化参数mean,std的值和模型训练时候用的数值有所不同,那么会严重影响预测精准度。这个mean和std的数值可以在PaddleDetection项目中相应的模型配置文件fairmot_hrnetv2_w18_dlafpn_30e_576x320.yml中找到。
4. 把已处理好的图像传递到ExecutableNetwork里的infer()中即可得到预测结果。
5. 最后我们需要将得到的预测结果:pred_dets, pred_embs 做postprocess,便可得到最后的结果。
完整代码可以在这里查看:Intel-OpenVINO-Paddle(https://github.com/franva/Intel-OpenVINO-Paddle/tree/main/PaddleDetection/FairMot)
我们来看一下成果。
图8: FairMOT检测结果
可以看出识别率还是非常之高,如果想更加谨慎一些,可以通过增加postprocess()中的threshold来确保降低误判率。
模型性能和吞吐量
测试好模型之后,我们还可以检查一下模型的性能和吞吐量。幸运的是,Intel DevCloud已经提供了现有的工具来帮助我们快速完成这项工作。这里是它的Jupyter Notebooks平台,在使用前需要先注册账户。
Jupyter Notebooks平台:
https://devcloud.intel.com/zh/edge/advanced/connect_and_create/
随机挑选几套硬件搭配,来看一下刚转换好的ONNX模型性能:
表格1:Benchmark ofPP-Tracking FairMOT 576*320 模型
关于如何使用 Intel®DevCloud,更详细的步骤请参考:《使用 OpenVINO™ 工具套件优化和部署 DenseNet 模型并在 DevCloud 上完成性能测试》。
至此,整个流程结束。恭喜大家成功的转换了模型并且部署到了设备上。期待看到你们更多的精彩应用!
Github链接:
https://github.com/franva/Intel-OpenVINO-Paddle/tree/main/PaddleDetection/FairMot
总结
本文开头介绍了多目标追踪MOT的广泛的适用性,阐述了用IntelOpenVINO部署模型的重要性。快速介绍了Intel的OpenVINO。然后以一个训练好的百度飞桨模型为例开始,逐步地带着大家把模型转换到了通用型ONNX格式,这和之前的教程不同,同时详细介绍了OV和FairMOT的工作流程以及代码。相信大家对于不同的模型,只需要做适量的改动,便可以快速独立的开发属于自己的AI应用程序。
参考文献:
[1]:MOT行人检测,https://arxiv.org/pdf/2004.01888.pdf
[2]:百度,PaddleDetection- FairMOT
相关阅读
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~