面由心生,由脸观心:基于AI的面部微表情分析技术解读
发布日期:2022-03-03T11:58:00.000+0000 浏览量:3249次

本文为大家带来的演讲主题是“
面由心生,由脸观心
”,将主要分享如何快速实时且精准检测并识别面部情绪。
俗话说“面由心生”,意思是如果你心理有情绪,我们一般能够从你的脸上观察到,这种技术可以说是“由脸观心”,是一种基于面部的AI情绪识别技术。

WAVE SUMMIT+2021深度学习开发者峰会
它是指我们肌肉下面有一处或者多处运动变化,表达人类情绪的一种面部运动状态。
面部表情是我们信息交流跟情感传递的一种重要手段。
传统意义上说的面部表情,实际上指的是宏表情,基本上分六类,有、悲伤、、厌恶、恐惧等等。因为它受意识的控制,所以它可以掩盖内心的真实情绪,是可以通过伪装而表达出来的。

心理学家艾克曼教授团队对这种面部表情进行了编码,即人脸运动编码系统。
这套系统把人脸面部表情运动的描述方式抽象成一些基本的人脸形变单元,比如把“高兴”面部表情拆解,会对应“圈眼轮匝肌外收紧;
脸颊抬升......”等描述。
对于不同的情绪,人脸的各个面部表情最终被对应到相应AU组合中。
我们以“高兴”为例,它实际上是AU6跟AU12的结合。
表情是人类情绪的外在反映,它一定能够做到心神合一吗?不一定。
1969年,艾克曼教授和他的团队,在心理医生和抑郁症患者的交谈录像中发现,患者Mary在整个视频中情绪表现得非常积极,因为她试图通过积极的情绪欺骗医生,让医生允许她出院。
但当我们去慢看视频时,会发现视频中有几帧暴露了Mary的真实情绪,她想自杀。
艾克曼和团队给这种真实情绪起了一个名字,叫微表情。微表情是一种持续时间短,运动幅度小的表情。它试图掩饰自己真实情绪,却不自觉暴露在人脸肌肉上。
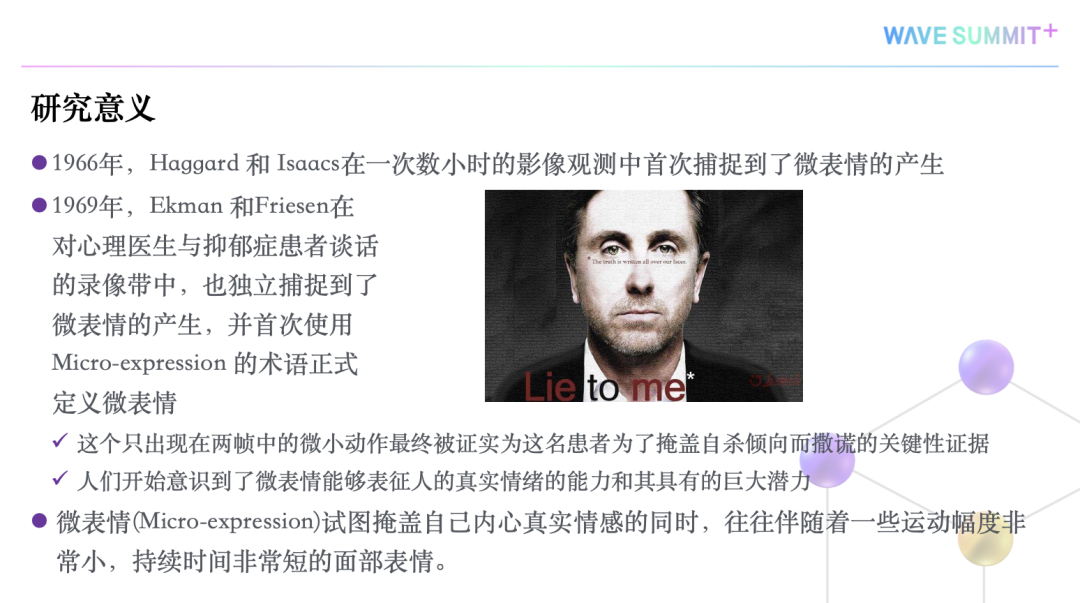
由此可知微表情跟表情是有关系的,微表情不但不受思维意识控制,而且持续的时间非常短,人的意识还没有来得及去控制它,就已经被暴露出来,所以它一定是真实情绪的反应。正是由于微表情的这个特点,它在刑侦、安全、司法、谈判等领域都有非常重要的应用。
第一是微表情的识别,它最开始是通过人工训练的,大概训练一个半小时,可以提高到30%-40%的准确性,但心理学家论证了人工识别最高不会超过47%。后来随着心理学实验逐渐演进到计算机应用上面,微表情有了AU组合,如果是高兴,宏表情的高兴是AU6+AU12,微表情是AU6或者是AU12,或者是AU6+AU12。
第二是微表情运动,它是局部的肌肉块运动,而不是两个肌肉块同时运动,比如高兴,运动的是AU6或者是AU12。但如果强度比较大,可能会出现AU6和AU12同时发生的情况。另外宏表情和微表情有一些联系,就是微表情的AU可能是宏表情AU的子集。
微表情不容易被觉察,而宏表情非常容易被觉察;
微表情的持续时间非常短,介于0.065秒到0.5秒之间,但是宏表情的时间相对长一些,介于0.5到4秒之间;
微表情的幅度变化非常小的,但宏表情变化非常大;
微表情不受人的意识控制,但宏表情是可以控制的;
微表情涉及到人脸面部的运动单元更少一些,但是宏表情可能涉及到更多的区域。
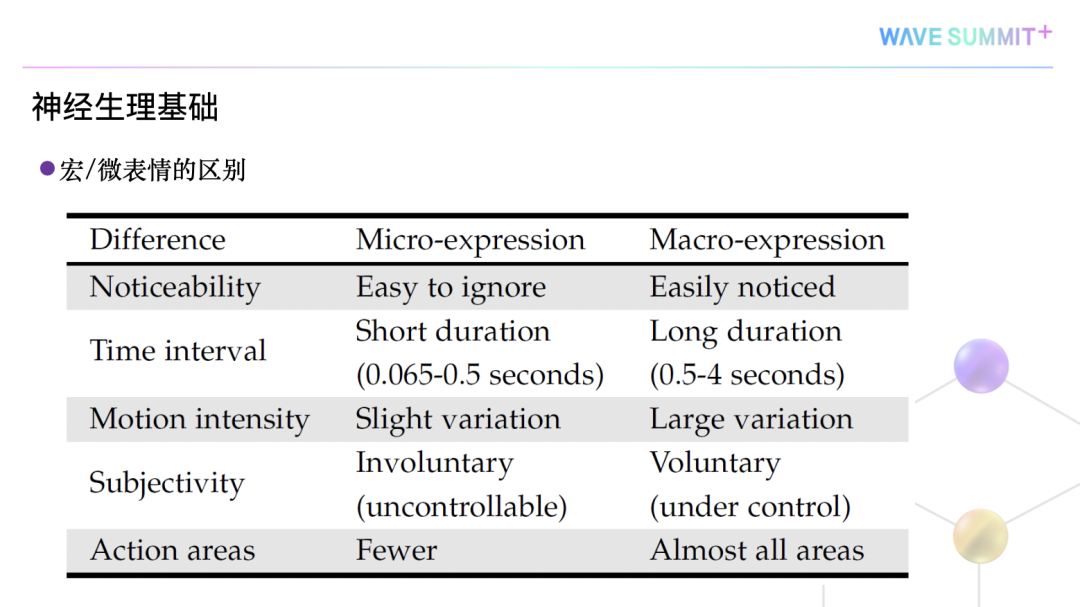
微表情的特点是持续的时间非常短、运动幅度的变化较小、难以掩饰和抑制,因此它经常容易被人所忽略掉。
既然人容易忽略微表情,那么我们可以借助计算机辅助手段来解决这些问题,比如用一个高速摄像机对着待测者的脸,让计算机把图像一帧一帧存储起来。

在我们团队建立MMEW数据库之前,针对微表情的研究,缺乏一些特别大的公开数据库,最大的数据库也仅有247个样本,且它的图像分辨率不高。
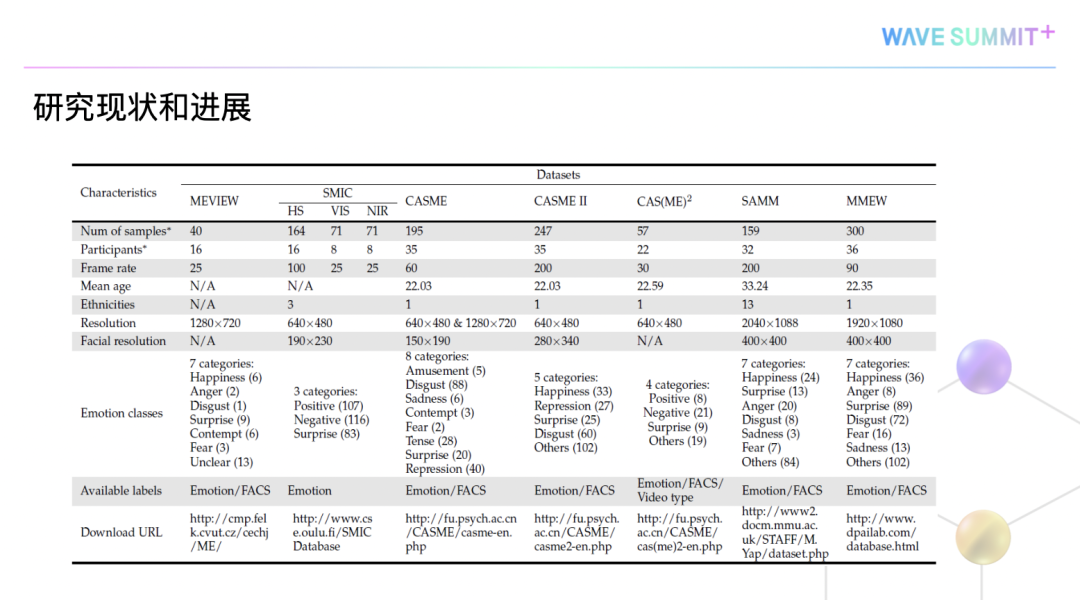
对此我们进行了优化,一方面从人员的数量上进行了优化升级,人脸分辨率和图像的分辨率尽量做大。另一方面对于人表情情绪的分类,做到了更精确,同时样本的均衡性要比其他的库好。最后,我们发布的一个数据集MMEW,它包含同一个人的宏表情和微表情的样本,这是现有的数据库做不到的。
四、现有的数据库、微表情的特征、检测算法、识别算法、应用、已有方法比较、未来可能的研究方向展望。
在收集数据前,我们要诱发微表情的产生,因此要给待测者看一些心理学家论证好的刺激源,这些小的刺激源持续时间非常短,要保证待测者的注意力十分集中。
在他们产生表情之前,我们要让待测者保持一种平静的情绪,相当于面部没有肌肉变化,一旦受到刺激以后,面部就会有一些刺激,我们让待测者描述受到刺激时他是什么样的情绪,然后我们对这个图片会一帧一帧观察,最后形成MMEW数据集。
收集好数据,接下来要对数据集进行标注。因为要给情绪标签,所以我要知道到底哪些AU发生了变化,从而给变化的AU打一个标注。且微表情是一个时间的持续概念,所以我还要标注出它发生的开始时刻、结束时刻以及高潮时刻。
微表情的特征,是由原始视频特征,提取一些描述,最终送到检测器或分类器。
现在较好的微表情特征分成这样几类,有时空域特征、频域特征、光流特征,深度学习特征。

深度学习特征,它是一种黑盒模型,我们需要研究它的可解释性的问题。对于这种光流特征,目前比较主流的方法是主方向的光流的平均特征,叫MDMO。获取它不同的稀疏特征系数,最后送到SVM分类器里面。深度学习这个方法也有对空间和时间上进行处理,得到时间性的连接模型还有时空模型,这是一个循环卷积网络进行微表情识别的工作。还有动态的成像系统来做微表情识别的深度学习方法。
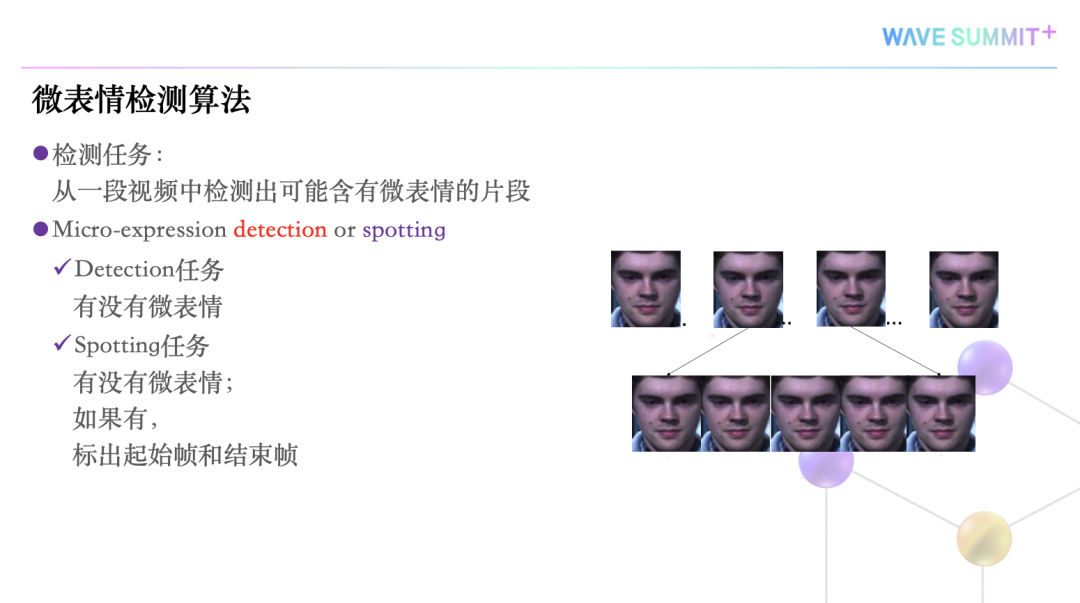
我们说微表情检测有两种方法,一个是detection,它是检测有没有微表情发生;
一个是spotting,它是除了检测微表情有没有发生,如果有发生,还要标注出来微表情发生的起始时刻、终止时刻、高潮时刻。
这两种方法容易受到一些阈值的干扰,这些阈值要进行手工调,非常耗时。识别的方法有传统的分类器SVM、极端学习机、K近邻,还有深度学习模型、迁移学习模型。
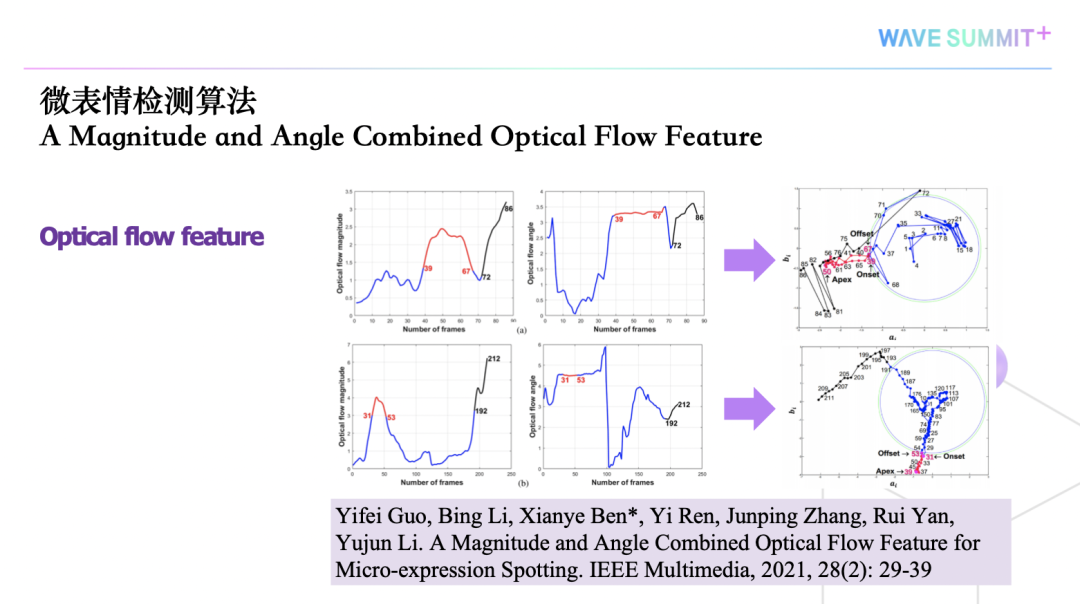
因此我们提出了一种新的微表情检测方法,首先要找到一些特征点,然后在实验中我们发现标注出来的区域是最感兴趣的区域,最后计算感兴趣区域里面的光流。
如果是微表情,它的幅度有一定的高度,角度是恒定的。我们把它转成极坐标系,可以发现这部分点对应微表情的特征,如果这部分点在单位圆以内,代表它的变化幅度非常小,可以理解为没有表情;如果这部分点在圆以外,我们看它的角度实际上是变化的,那么这个黑色的点对应的就是宏表情。
用这个方法就可以区分微表情、没有表情、宏表情,也可以用这种方式来做微表情的检测。我们还提出了不同的决策准则,比如有积极的准则,有保守的准则,最后在公开的数据库上,该方法得到了非常好的性能。
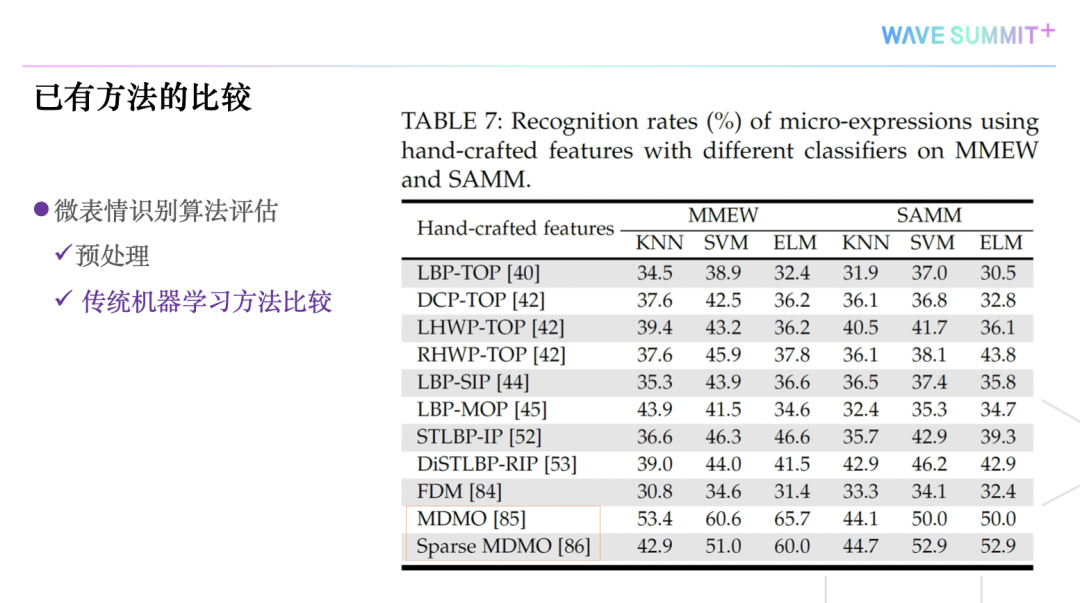
和已有方法的比较,微表情识别算法评估的优势有那些?
我们对现有的一些图像预处理的方法,进行了评估,发现跟传统的机器学习方法对比,光流的方法能最好的识别性能。
我们还对比了传统的机器学习方法和深度学习机器方法,发现后者更有优势的,但是它需要去考虑可解释的深度学习。
首先仿照人脸识别,我们认为未来微表情识别,也是需要保护隐私的。
其次我们可以去迁移一些相关领域的知识,比如说宏表情和微表情比较相近,那么能不能把宏表情的特征迁移学习到微表情识别呢?这将是一个值得学习的方向。对于数据集,现在我们团队有一个800多个样本的库,可即使把所有可获取的微表情样本全部加到一块,还是非常小。
最后,因为微表情在采集的时候是通过高速摄像机,所以从网上搜索的一些数据满足不了这个帧频,只能够通过采集的方式获取。我们可以采用众筹的方式,把的数据集做的更标准化一些。还可以采用生成技术,进行一些微表情的生成,帮助我们更好的去识别微表情。
因为现在深度学习比较热,所以我们需要做可解释的微表情识别。

关注飞桨公众号,获取更多技术内容~


