刚刚过去的冬奥会开幕式,可以说是一场美轮美奂的视觉盛宴。其中,科技与艺术的融合铸造了各种梦幻的视觉效果,让我们看到AI在艺术领域大有可为。而今天分享的项目也是AI+艺术的一个小方向,灵感来源于我的小女儿。
技术介绍
本文介绍的涂鸦应用采用的模型出自文章《Semantic Image Synthesis with Spatially-Adaptive Normalization》。这个模型有个好听的名字GauGAN [1] ,Gau就是梵高的Gau,在风格迁移网络Pix2PixHD的生成器上进行了改进,使用 SPADE(Spatially-Adaptive Normalization)模块代替了原来的BN层,以解决图片特征图在经过BN层时信息被“洗掉”的问题。Pix2PixHD实际上是一个CGAN(Conditional GAN)条件生成对抗网络,它能够通过输入的控制标签,也就是语义分割掩码来控制生成图片各个部分的内容。下面就详细介绍一下GauGAN各个部件的实现细节。
1.多尺度判别器
# Multi-scale discriminators 判别器代码
class MultiscaleDiscriminator(nn.Layer):
def __init__(self, opt):
super(MultiscaleDiscriminator, self).__init__()
for i in range(opt.num_D):
sequence = []
feat_size = opt.crop_size
for j in range(i):
sequence += [nn.AvgPool2D(3, 2, 1)]
feat_size = np.floor((feat_size + 1 * 2 - (3 - 2)) / 2).astype('int64') # 计算各个判别器输入的缩放比例
opt_downsampled = copy.deepcopy(opt)
opt_downsampled.crop_size = feat_size
sequence += [NLayersDiscriminator(opt_downsampled)]
sequence = nn.Sequential(*sequence)
self.add_sublayer('nld_'+str(i), sequence)
def forward(self, input):
output = []
for layer in self._sub_layers.values():
output.append(layer(input))
return output
2.逐渐精细化的生成器
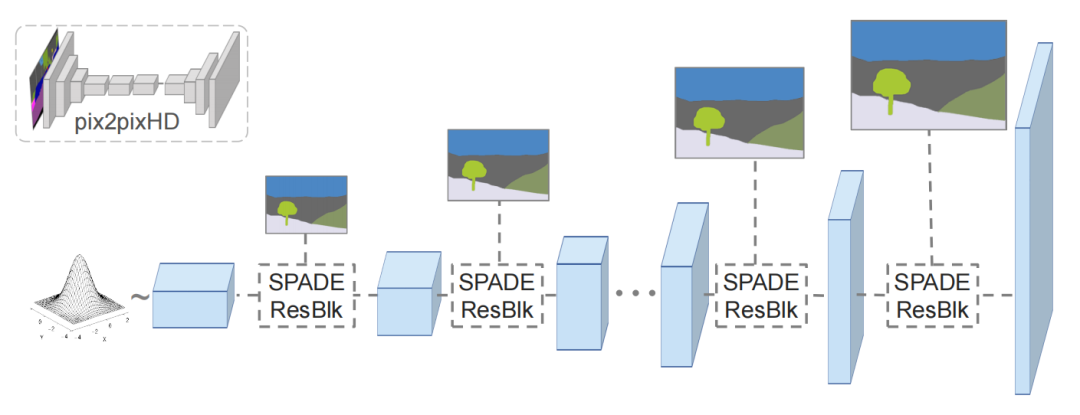
# Coarse-to-fine generator 生成器代码
class SPADEGenerator(nn.Layer):
def __init__(self, opt):
super(SPADEGenerator, self).__init__()
self.opt = opt
nf = opt.ngf
self.sw, self.sh = self.compute_latent_vector_size(opt)
if self.opt.use_vae:
self.fc = nn.Linear(opt.z_dim, 16 * opt.nef * self.sw * self.sh)
self.head_0 = SPADEResnetBlock(16 * opt.nef, 16 * nf, opt)
else:
self.fc = nn.Conv2D(self.opt.semantic_nc, 16 * nf, 3, 1, 1)
self.head_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.G_middle_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.G_middle_1 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.up_0 = SPADEResnetBlock(16 * nf, 8 * nf, opt)
self.up_1 = SPADEResnetBlock(8 * nf, 4 * nf, opt)
self.up_2 = SPADEResnetBlock(4 * nf, 2 * nf, opt)
self.up_3 = SPADEResnetBlock(2 * nf, 1 * nf, opt)
final_nc = nf
if opt.num_upsampling_layers == 'most':
self.up_4 = SPADEResnetBlock(1 * nf, nf // 2, opt)
final_nc = nf // 2
self.conv_img = nn.Conv2D(final_nc, 3, 3, 1, 1)
self.up = nn.Upsample(scale_factor=2)
def forward(self, input, z=None):
seg = input
if self.opt.use_vae:
x = self.fc(z)
x = paddle.reshape(x, [-1, 16 * self.opt.nef, self.sh, self.sw])
else:
x = F.interpolate(seg, (self.sh, self.sw))
x = self.fc(x)
x = self.head_0(x, seg)
x = self.up(x)
x = self.G_middle_0(x, seg)
if self.opt.num_upsampling_layers == 'more' or \
self.opt.num_upsampling_layers == 'most':
x = self.up(x)
x = self.G_middle_1(x, seg)
x = self.up(x)
x = self.up_0(x, seg)
x = self.up(x)
x = self.up_1(x, seg)
x = self.up(x)
x = self.up_2(x, seg)
x = self.up(x)
x = self.up_3(x, seg)
if self.opt.num_upsampling_layers == 'most':
x = self.up(x)
x = self.up_4(x, seg)
x = self.conv_img(F.gelu(x))
x = F.tanh(x)
return x

3.空间自适应归一化 SPADE
(Spatially-Adaptive Normalization)
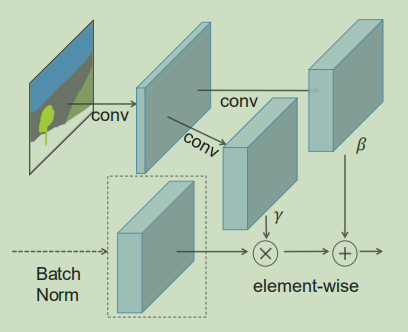

# SPADE空间自适应归一化模块代码
class SPADE(nn.Layer):
def __init__(self, config_text, norm_nc, label_nc):
super(SPADE, self).__init__()
parsed = re.search(r'spade(\D+)(\d)x\d', config_text)
param_free_norm_type = str(parsed.group(1))
ks = int(parsed.group(2))
self.param_free_norm = build_norm_layer(param_free_norm_type)(norm_nc) # 此处理须关闭归一化层的自适应参数
# The dimension of the intermediate embedding space. Yes, hardcoded.
nhidden = 128
pw = ks // 2
self.mlp_shared = nn.Sequential(*[
nn.Conv2D(label_nc, nhidden, ks, 1, pw),
nn.GELU(),
])
self.mlp_gamma = nn.Conv2D(nhidden, norm_nc, ks, 1, pw)
self.mlp_beta = nn.Conv2D(nhidden, norm_nc, ks, 1, pw)
def forward(self, x, segmap):
# Part 1. generate parameter-free normalized activations
normalized = self.param_free_norm(x)
# Part 2. produce scaling and bias conditioned on semantic map
segmap = F.interpolate(segmap, x.shape[2:])
actv = self.mlp_shared(segmap)
gamma = self.mlp_gamma(actv)
beta = self.mlp_beta(actv)
# apply scale and bias
out = normalized * (1 + gamma) + beta
return out
4.GauGAN的Loss 计算
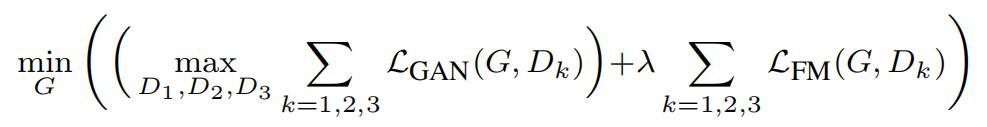
# 判别器对抗损失
df_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][:batch_size]
new_loss = -paddle.minimum(-pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss
df_ganloss += new_loss
df_ganloss /= len(pred)
dr_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][batch_size:]
new_loss = -paddle.minimum(pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss
dr_ganloss += new_loss
dr_ganloss /= len(pred)
# 生成器对抗损失
g_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][:batch_size]
new_loss = -pred_i.mean() # hinge loss
g_ganloss += new_loss
g_ganloss /= len(pred)
g_featloss = 0.
for i in range(len(pred)):
for j in range(len(pred[i]) - 1): # 除去最后一层的中间层featuremap
unweighted_loss = (pred[i][j][:batch_size] - pred[i][j][batch_size:]).abs().mean() # L1 loss
g_featloss += unweighted_loss * opt.lambda_feat / len(pred)
g_vggloss = paddle.to_tensor(0.)
if not opt.no_vgg_loss:
rates = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0]
_, fake_features = vgg19(resize(fake_img, opt, 224))
_, real_features = vgg19(resize(image, opt, 224))
for i in range(len(fake_features)):
g_vggloss += rates[i] * l1loss(fake_features[i], real_features[i])
g_vggloss *= opt.lambda_vgg
d_loss = df_ganloss + dr_ganloss
if opt.use_vae:
g_loss = g_ganloss + g_featloss + g_vggloss + g_vaeloss
opt_e.clear_grad()
g_loss.backward(retain_graph=True)
opt_e.step()
else:
g_loss = g_ganloss + g_featloss + g_vggloss
opt_g.clear_grad()
g_loss.backward()
opt_g.step()
工程实践及更多探索
1.项目实现中遇到的一些问题
2.模型改进及正在进行的后续处理
①添加注意力
def simam(x, e_lambda=1e-4):
b, c, h, w = x.shape
n = w * h - 1
x_minus_mu_square = (x - x.mean(axis=[2, 3], keepdim=True)) ** 2
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(axis=[2, 3], keepdim=True) / n + e_lambda)) + 0.5
return x * nn.functional.sigmoid(y)

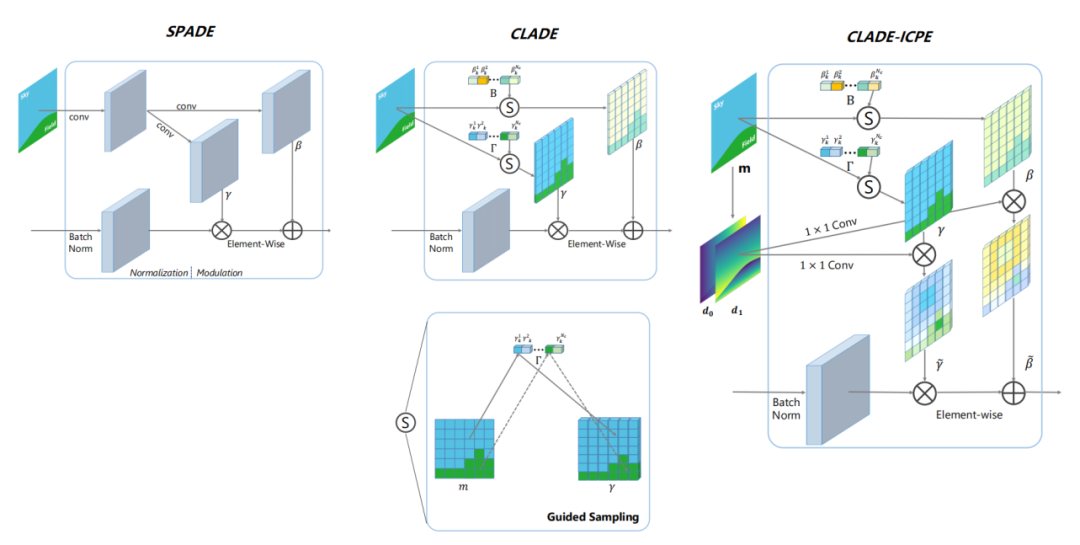
这个开始的思路是:真正使得模型提升效果的是SPADE模块中保留的类别信息,而非空间信息。所以,改进版本的CLADE(Class-Adaptive(De)Normalization)模块只将类别信息映射到了反归一化模块的缩放系数和偏置中,大大节省了参数量和计算量。但后来又发现,保留空间信息还是能使模型的效果提升一些的,就又使用语义标签手动计算了ICPE(intra-class positional encoding类内位置嵌入码)乘到了缩放系数和偏置上。最终版本的CLADE-ICPE 在生成质量与SPADE相当的情况下,大大降低了参数量和计算量。
结语


关注公众号,获取更多技术内容~
刚刚过去的冬奥会开幕式,可以说是一场美轮美奂的视觉盛宴。其中,科技与艺术的融合铸造了各种梦幻的视觉效果,让我们看到AI在艺术领域大有可为。而今天分享的项目也是AI+艺术的一个小方向,灵感来源于我的小女儿。
技术介绍
本文介绍的涂鸦应用采用的模型出自文章《Semantic Image Synthesis with Spatially-Adaptive Normalization》。这个模型有个好听的名字GauGAN [1] ,Gau就是梵高的Gau,在风格迁移网络Pix2PixHD的生成器上进行了改进,使用 SPADE(Spatially-Adaptive Normalization)模块代替了原来的BN层,以解决图片特征图在经过BN层时信息被“洗掉”的问题。Pix2PixHD实际上是一个CGAN(Conditional GAN)条件生成对抗网络,它能够通过输入的控制标签,也就是语义分割掩码来控制生成图片各个部分的内容。下面就详细介绍一下GauGAN各个部件的实现细节。
1.多尺度判别器
# Multi-scale discriminators 判别器代码
class MultiscaleDiscriminator(nn.Layer):
def __init__(self, opt):
super(MultiscaleDiscriminator, self).__init__()
for i in range(opt.num_D):
sequence = []
feat_size = opt.crop_size
for j in range(i):
sequence += [nn.AvgPool2D(3, 2, 1)]
feat_size = np.floor((feat_size + 1 * 2 - (3 - 2)) / 2).astype('int64') # 计算各个判别器输入的缩放比例
opt_downsampled = copy.deepcopy(opt)
opt_downsampled.crop_size = feat_size
sequence += [NLayersDiscriminator(opt_downsampled)]
sequence = nn.Sequential(*sequence)
self.add_sublayer('nld_'+str(i), sequence)
def forward(self, input):
output = []
for layer in self._sub_layers.values():
output.append(layer(input))
return output
2.逐渐精细化的生成器
# Coarse-to-fine generator 生成器代码
class SPADEGenerator(nn.Layer):
def __init__(self, opt):
super(SPADEGenerator, self).__init__()
self.opt = opt
nf = opt.ngf
self.sw, self.sh = self.compute_latent_vector_size(opt)
if self.opt.use_vae:
self.fc = nn.Linear(opt.z_dim, 16 * opt.nef * self.sw * self.sh)
self.head_0 = SPADEResnetBlock(16 * opt.nef, 16 * nf, opt)
else:
self.fc = nn.Conv2D(self.opt.semantic_nc, 16 * nf, 3, 1, 1)
self.head_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.G_middle_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.G_middle_1 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.up_0 = SPADEResnetBlock(16 * nf, 8 * nf, opt)
self.up_1 = SPADEResnetBlock(8 * nf, 4 * nf, opt)
self.up_2 = SPADEResnetBlock(4 * nf, 2 * nf, opt)
self.up_3 = SPADEResnetBlock(2 * nf, 1 * nf, opt)
final_nc = nf
if opt.num_upsampling_layers == 'most':
self.up_4 = SPADEResnetBlock(1 * nf, nf // 2, opt)
final_nc = nf // 2
self.conv_img = nn.Conv2D(final_nc, 3, 3, 1, 1)
self.up = nn.Upsample(scale_factor=2)
def forward(self, input, z=None):
seg = input
if self.opt.use_vae:
x = self.fc(z)
x = paddle.reshape(x, [-1, 16 * self.opt.nef, self.sh, self.sw])
else:
x = F.interpolate(seg, (self.sh, self.sw))
x = self.fc(x)
x = self.head_0(x, seg)
x = self.up(x)
x = self.G_middle_0(x, seg)
if self.opt.num_upsampling_layers == 'more' or \
self.opt.num_upsampling_layers == 'most':
x = self.up(x)
x = self.G_middle_1(x, seg)
x = self.up(x)
x = self.up_0(x, seg)
x = self.up(x)
x = self.up_1(x, seg)
x = self.up(x)
x = self.up_2(x, seg)
x = self.up(x)
x = self.up_3(x, seg)
if self.opt.num_upsampling_layers == 'most':
x = self.up(x)
x = self.up_4(x, seg)
x = self.conv_img(F.gelu(x))
x = F.tanh(x)
return x
3.空间自适应归一化 SPADE
(Spatially-Adaptive Normalization)
# SPADE空间自适应归一化模块代码
class SPADE(nn.Layer):
def __init__(self, config_text, norm_nc, label_nc):
super(SPADE, self).__init__()
parsed = re.search(r'spade(\D+)(\d)x\d', config_text)
param_free_norm_type = str(parsed.group(1))
ks = int(parsed.group(2))
self.param_free_norm = build_norm_layer(param_free_norm_type)(norm_nc) # 此处理须关闭归一化层的自适应参数
# The dimension of the intermediate embedding space. Yes, hardcoded.
nhidden = 128
pw = ks // 2
self.mlp_shared = nn.Sequential(*[
nn.Conv2D(label_nc, nhidden, ks, 1, pw),
nn.GELU(),
])
self.mlp_gamma = nn.Conv2D(nhidden, norm_nc, ks, 1, pw)
self.mlp_beta = nn.Conv2D(nhidden, norm_nc, ks, 1, pw)
def forward(self, x, segmap):
# Part 1. generate parameter-free normalized activations
normalized = self.param_free_norm(x)
# Part 2. produce scaling and bias conditioned on semantic map
segmap = F.interpolate(segmap, x.shape[2:])
actv = self.mlp_shared(segmap)
gamma = self.mlp_gamma(actv)
beta = self.mlp_beta(actv)
# apply scale and bias
out = normalized * (1 + gamma) + beta
return out
4.GauGAN的Loss 计算
# 判别器对抗损失
df_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][:batch_size]
new_loss = -paddle.minimum(-pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss
df_ganloss += new_loss
df_ganloss /= len(pred)
dr_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][batch_size:]
new_loss = -paddle.minimum(pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss
dr_ganloss += new_loss
dr_ganloss /= len(pred)
# 生成器对抗损失
g_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][:batch_size]
new_loss = -pred_i.mean() # hinge loss
g_ganloss += new_loss
g_ganloss /= len(pred)
g_featloss = 0.
for i in range(len(pred)):
for j in range(len(pred[i]) - 1): # 除去最后一层的中间层featuremap
unweighted_loss = (pred[i][j][:batch_size] - pred[i][j][batch_size:]).abs().mean() # L1 loss
g_featloss += unweighted_loss * opt.lambda_feat / len(pred)
g_vggloss = paddle.to_tensor(0.)
if not opt.no_vgg_loss:
rates = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0]
_, fake_features = vgg19(resize(fake_img, opt, 224))
_, real_features = vgg19(resize(image, opt, 224))
for i in range(len(fake_features)):
g_vggloss += rates[i] * l1loss(fake_features[i], real_features[i])
g_vggloss *= opt.lambda_vgg
d_loss = df_ganloss + dr_ganloss
if opt.use_vae:
g_loss = g_ganloss + g_featloss + g_vggloss + g_vaeloss
opt_e.clear_grad()
g_loss.backward(retain_graph=True)
opt_e.step()
else:
g_loss = g_ganloss + g_featloss + g_vggloss
opt_g.clear_grad()
g_loss.backward()
opt_g.step()
工程实践及更多探索
1.项目实现中遇到的一些问题
2.模型改进及正在进行的后续处理
①添加注意力
def simam(x, e_lambda=1e-4):
b, c, h, w = x.shape
n = w * h - 1
x_minus_mu_square = (x - x.mean(axis=[2, 3], keepdim=True)) ** 2
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(axis=[2, 3], keepdim=True) / n + e_lambda)) + 0.5
return x * nn.functional.sigmoid(y)
这个开始的思路是:真正使得模型提升效果的是SPADE模块中保留的类别信息,而非空间信息。所以,改进版本的CLADE(Class-Adaptive(De)Normalization)模块只将类别信息映射到了反归一化模块的缩放系数和偏置中,大大节省了参数量和计算量。但后来又发现,保留空间信息还是能使模型的效果提升一些的,就又使用语义标签手动计算了ICPE(intra-class positional encoding类内位置嵌入码)乘到了缩放系数和偏置上。最终版本的CLADE-ICPE 在生成质量与SPADE相当的情况下,大大降低了参数量和计算量。
结语
关注公众号,获取更多技术内容~