

电动车以其环保节能、小巧便捷、经济实用等特性,市场需求逐年递增,但同时它带来的充电起火、电池爆炸等安全问题也时有发生。大部分小区物业都禁止电瓶车进电梯等违规停放行为,然而实际执行中往往难以监管。人工智能是否能帮助居民减少电瓶车违规停放带来的安全隐患呢?我们尝试用人工智能进行电瓶车检测,来减少人工检测的成本和压力。
本项目以“电梯电动车检测”为首要任务进行开发,使用飞桨全流程开发工具PaddleX和边缘计算硬件EdgeBoard,实现对违规停放的电动车的检测,后续还可以将场景延展到楼道门口、居民楼门口、公寓走道等众多关键场地。
PaddleX介绍
PaddleX 是飞桨全流程开发工具,集成飞桨智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,并提供统一任务API接口及图形化开发界面Demo。开发者无需分别安装不同套件,以低代码的形式即可快速完成飞桨全流程开发。
EdgeBoard方案介绍
EdgeBoard是百度面向嵌入式与边缘部署场景打造的AI视觉硬件方案,可无缝兼容百度大脑丰富的工具平台与开放能力,具有高性能、低成本、使用简单等三大优点,可广泛适用于智能设备打造、科研教学、安防监控、餐饮卫生监控、工业质检、交通巡检、医疗诊断、智能零售等领域。
数据集的获取
那么我们是怎样获取电瓶车数据呢?一开始我们是用Labelme标注了一部分数据,但是数据量太少了。但如果大量标注又太耗费时间了,通过观察,电瓶车与摩托车外形相当相似,因此在本项目中,我们加入了摩托车的数据集。
本项目使用的数据集来自Pascal-VOC和COCO2017,一共提取出了4718张含有摩托车的图片。数据集统一制作成VOC格式,包括两个文件夹,其中JPEGImages存储原图,Annotations存储标注文件;再以8:2的比例划分训练集和验证集。

模型训练
本项目使用的是调用API的方式,与配置化驱动的区别是只需要一行命令安装PaddleX库即可调用,无需下载和打包整个PaddleX项目。但配置基本相同,主要分为数据变换(数据增强)、数据集处理、模型准备、优化器、训练5个部分。
!pip -q install paddlex
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from paddlex import transforms
import paddlex as pdx
数据增强
采用的策略是随机翻转、随机像素内容变换、图像融合、随机扩张图像等。
# 定义训练和验证时的transforms
train_transforms = transforms.Compose([
transforms.MixupImage(mixup_epoch=-1),
transforms.RandomDistort(),
transforms.RandomExpand(),
transforms.RandomCrop(),
transforms.Resize(target_size=608, interp='RANDOM'),
transforms.RandomHorizontalFlip(),
transforms.Normalize(),
])
eval_transforms = transforms.Compose([
transforms.Resize(target_size=608, interp='CUBIC'),
transforms.Normalize()])
数据集处理
将数据增强策略应用到数据集上。
# 定义训练和验证所用的数据集
train_dataset = pdx.datasets.VOCDetection(
data_dir='./',
file_list='motorbike/train.txt',
label_list='motorbike/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='./',
file_list='motorbike/val.txt',
label_list='motorbike/labels.txt',
transforms=eval_transforms)
模型准备
在PaddleX中有多种模型,为了适应端侧部署,选用较为轻量级的模型YOLOv3-MobileNetV1。
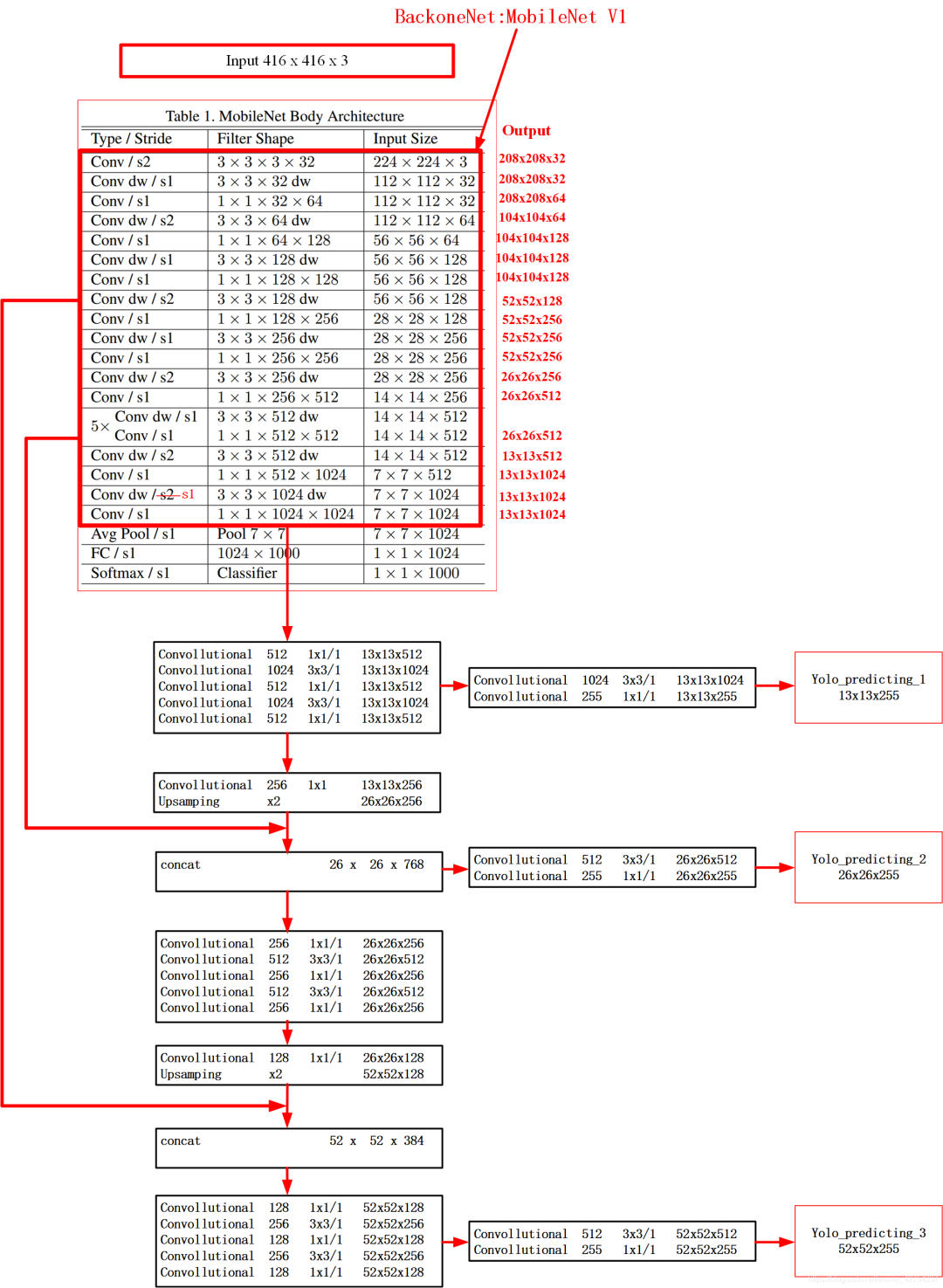
模型训练
通过PaddleX API我们只需要几行代码就可以完成模型训练。
# 初始化模型,并进行训练
num_classes = len(train_dataset.labels)
batch_size = 64
model = pdx.det.YOLOv3(num_classes=num_classes, backbone='MobileNetV1')
model.train(
num_epochs=200,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
train_batch_size=batch_size,
learning_rate=1e-4,
warmup_steps=len(train_dataset)//2,
save_interval_epochs=4,
save_dir='output/yolov3_mobilenetv1',
metric='VOC',
use_vdl=True,
early_stop=True)

模型导出
!paddlex --export_inference --model_dir=output/yolov3_mobilenetv1/best_model --save_dir=inference_model --fixed_input_shape=[608,608]
模型部署
上位机
下位机

关注公众号,获取更多技术内容~
电动车以其环保节能、小巧便捷、经济实用等特性,市场需求逐年递增,但同时它带来的充电起火、电池爆炸等安全问题也时有发生。大部分小区物业都禁止电瓶车进电梯等违规停放行为,然而实际执行中往往难以监管。人工智能是否能帮助居民减少电瓶车违规停放带来的安全隐患呢?我们尝试用人工智能进行电瓶车检测,来减少人工检测的成本和压力。
本项目以“电梯电动车检测”为首要任务进行开发,使用飞桨全流程开发工具PaddleX和边缘计算硬件EdgeBoard,实现对违规停放的电动车的检测,后续还可以将场景延展到楼道门口、居民楼门口、公寓走道等众多关键场地。
PaddleX介绍
PaddleX 是飞桨全流程开发工具,集成飞桨智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,并提供统一任务API接口及图形化开发界面Demo。开发者无需分别安装不同套件,以低代码的形式即可快速完成飞桨全流程开发。
EdgeBoard方案介绍
EdgeBoard是百度面向嵌入式与边缘部署场景打造的AI视觉硬件方案,可无缝兼容百度大脑丰富的工具平台与开放能力,具有高性能、低成本、使用简单等三大优点,可广泛适用于智能设备打造、科研教学、安防监控、餐饮卫生监控、工业质检、交通巡检、医疗诊断、智能零售等领域。
数据集的获取
那么我们是怎样获取电瓶车数据呢?一开始我们是用Labelme标注了一部分数据,但是数据量太少了。但如果大量标注又太耗费时间了,通过观察,电瓶车与摩托车外形相当相似,因此在本项目中,我们加入了摩托车的数据集。
本项目使用的数据集来自Pascal-VOC和COCO2017,一共提取出了4718张含有摩托车的图片。数据集统一制作成VOC格式,包括两个文件夹,其中JPEGImages存储原图,Annotations存储标注文件;再以8:2的比例划分训练集和验证集。
模型训练
本项目使用的是调用API的方式,与配置化驱动的区别是只需要一行命令安装PaddleX库即可调用,无需下载和打包整个PaddleX项目。但配置基本相同,主要分为数据变换(数据增强)、数据集处理、模型准备、优化器、训练5个部分。
!pip -q install paddlex
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from paddlex import transforms
import paddlex as pdx
数据增强
采用的策略是随机翻转、随机像素内容变换、图像融合、随机扩张图像等。
# 定义训练和验证时的transforms
train_transforms = transforms.Compose([
transforms.MixupImage(mixup_epoch=-1),
transforms.RandomDistort(),
transforms.RandomExpand(),
transforms.RandomCrop(),
transforms.Resize(target_size=608, interp='RANDOM'),
transforms.RandomHorizontalFlip(),
transforms.Normalize(),
])
eval_transforms = transforms.Compose([
transforms.Resize(target_size=608, interp='CUBIC'),
transforms.Normalize()])
数据集处理
将数据增强策略应用到数据集上。
# 定义训练和验证所用的数据集
train_dataset = pdx.datasets.VOCDetection(
data_dir='./',
file_list='motorbike/train.txt',
label_list='motorbike/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='./',
file_list='motorbike/val.txt',
label_list='motorbike/labels.txt',
transforms=eval_transforms)
模型准备
在PaddleX中有多种模型,为了适应端侧部署,选用较为轻量级的模型YOLOv3-MobileNetV1。
模型训练
通过PaddleX API我们只需要几行代码就可以完成模型训练。
# 初始化模型,并进行训练
num_classes = len(train_dataset.labels)
batch_size = 64
model = pdx.det.YOLOv3(num_classes=num_classes, backbone='MobileNetV1')
model.train(
num_epochs=200,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
train_batch_size=batch_size,
learning_rate=1e-4,
warmup_steps=len(train_dataset)//2,
save_interval_epochs=4,
save_dir='output/yolov3_mobilenetv1',
metric='VOC',
use_vdl=True,
early_stop=True)
模型导出
!paddlex --export_inference --model_dir=output/yolov3_mobilenetv1/best_model --save_dir=inference_model --fixed_input_shape=[608,608]
模型部署
上位机
下位机
关注公众号,获取更多技术内容~


