发布10个视频领域产业级应用案例,涵盖体育、互联网、医疗、媒体和安全等行业。
首次开源5个冠军/顶会/产业级算法,包含视频-文本学习、视频分割、深度估计、视频-文本检索、动作识别/视频分类等技术方向。
配套丰富的文档和教程,更有直播课程和用户交流群,可以与百度资深研发工程师一起讨论交流。
十大视频场景化应用
工具详解
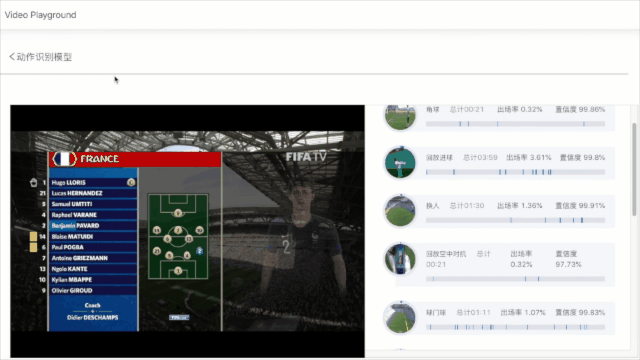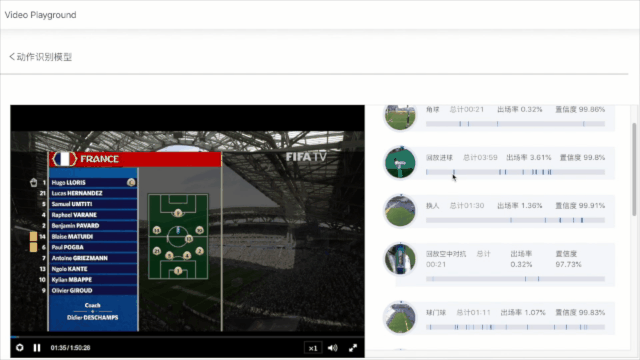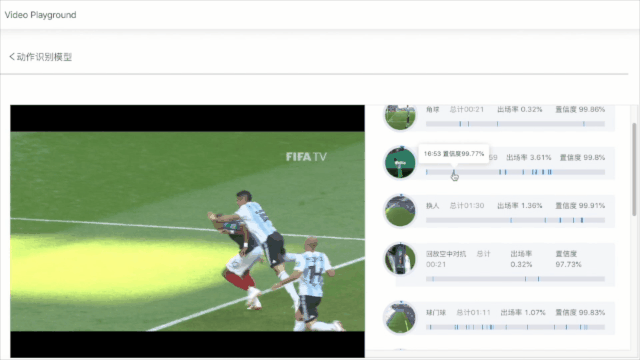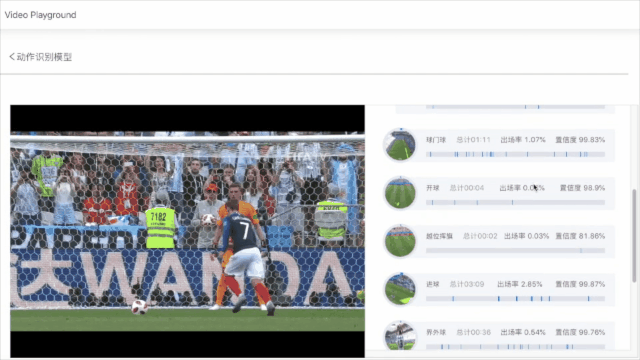
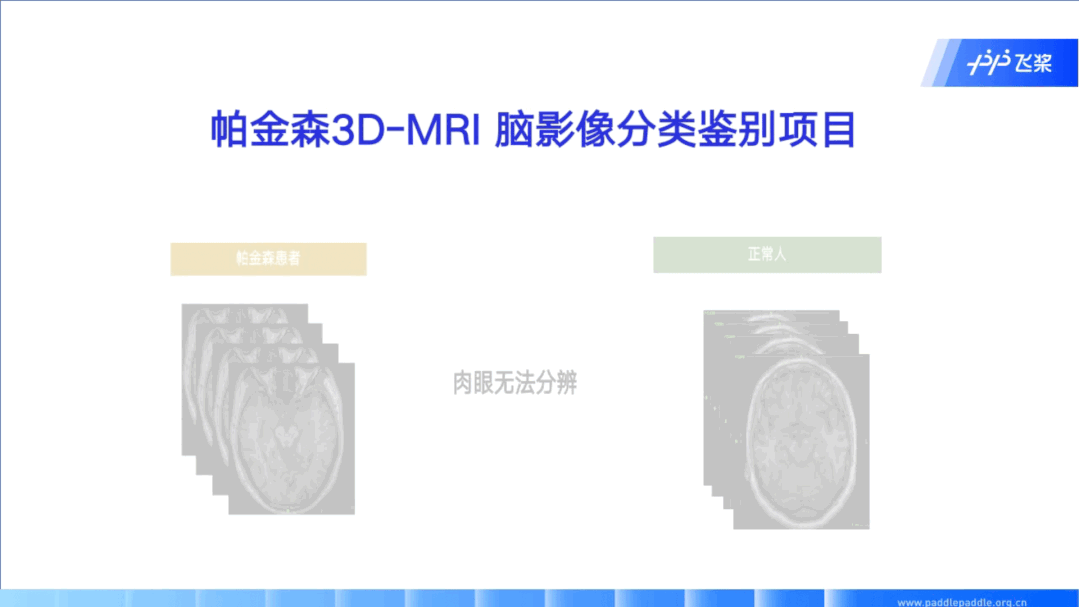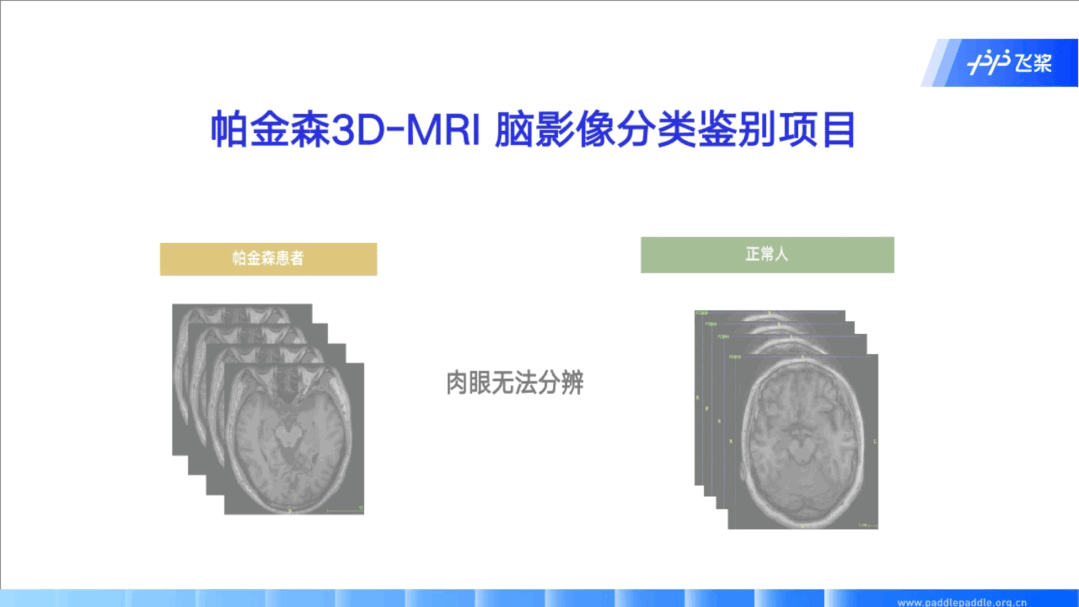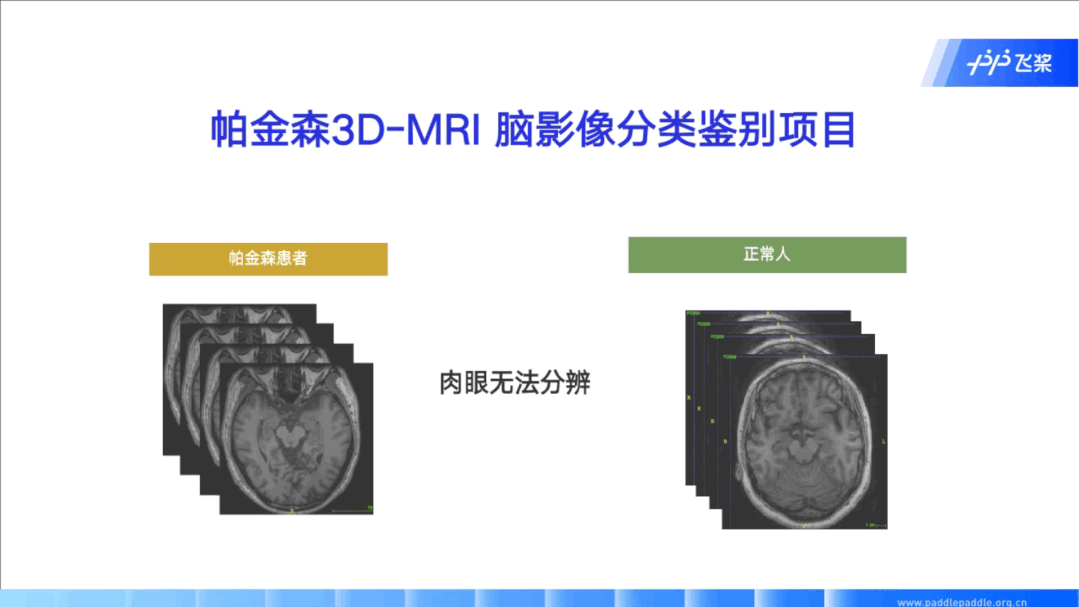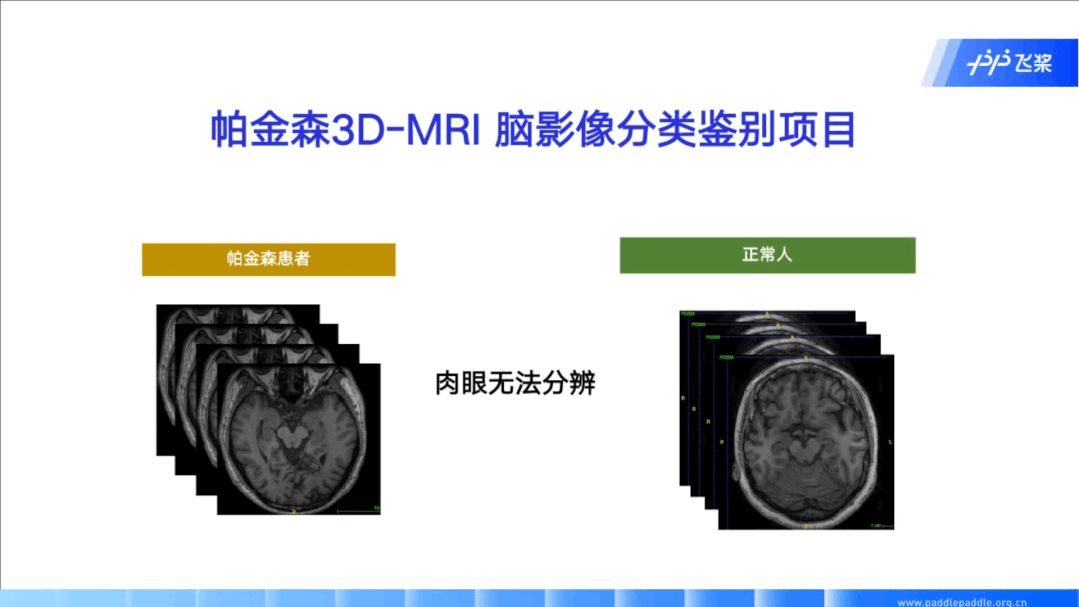
飞桨PaddleVideo基于体育行业中足球/篮球/乒乓球/花样滑冰等场景,开源出一套通用的体育类动作识别框架;针对互联网和媒体场景开源了基于知识增强的大规模多模态分类打标签、智能剪辑和视频拆条等解决方案;针对安全、教育、医疗等场景开源了多种检测识别案例。百度智能云结合飞桨深度学习技术也形成了一系列深度打磨的产业级多场景动作识别、视频智能分析和生产以及医疗分析等解决方案。
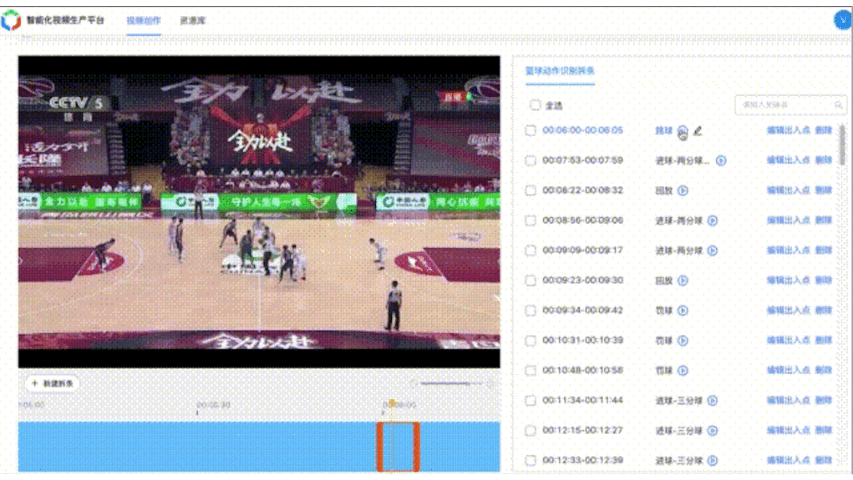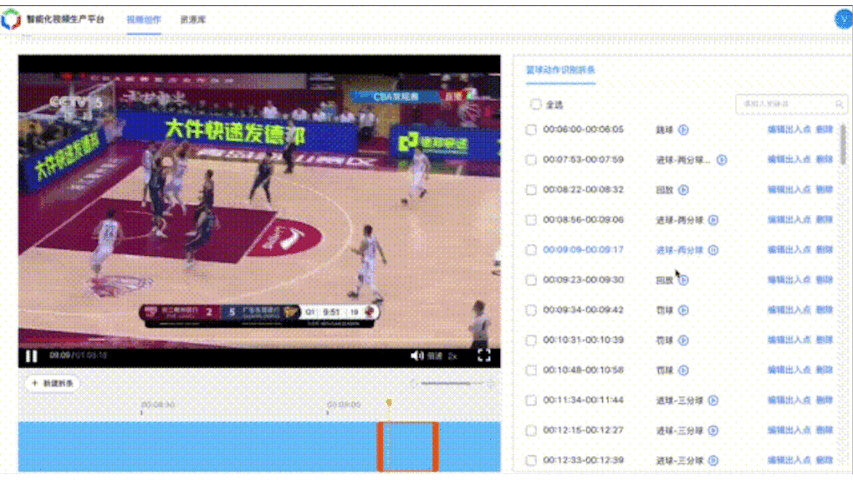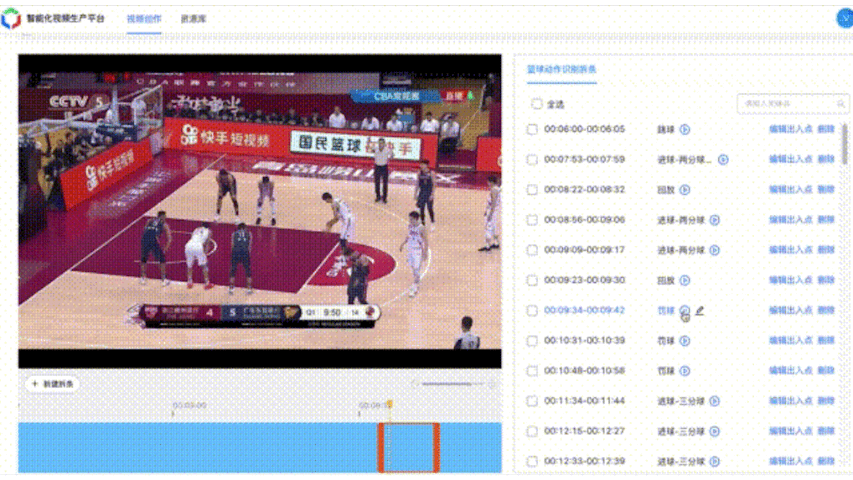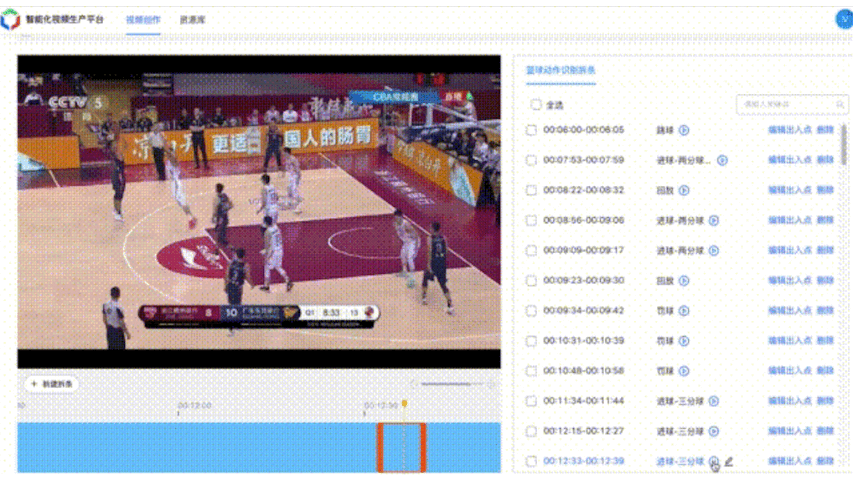
篮球案例BasketballAction整体框架与FootballAction类似,共包含7个动作类别,分别为:背景、进球-三分球、进球-两分球、进球-扣篮、罚球、跳球。准确率超过90%。
在百度Create 2021(百度AI开发者大会)上,PaddleVideo联合北京大学一同发布的乒乓球动作进行识别模型,基于超过500G的比赛视频构建了标准的训练数据集,标签涵盖发球、拉、摆短等8个大类动作。其中起止回合准确率达到了97%以上,动作识别也达到了80%以上。
使用姿态估计算法提取关节点数据,最后将关节点数据输入时空图卷积网络ST-GCN模型中进行动作分类,可以实现30种动作的分类。飞桨联合CCF(中国计算机学会)举办了花样滑冰动作识别大赛,吸引了300家高校与200家企业超过3800人参赛,冠军方案比基线方案精度提升了12个点,比赛top3方案已经开源。
 |
 |
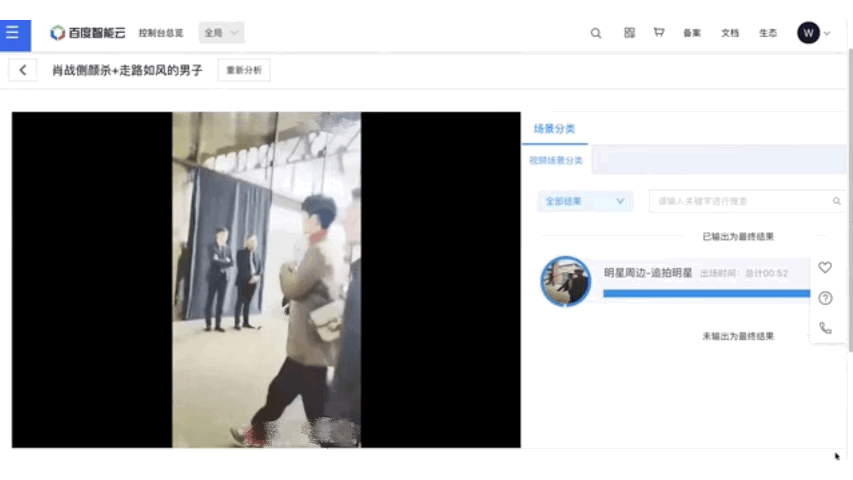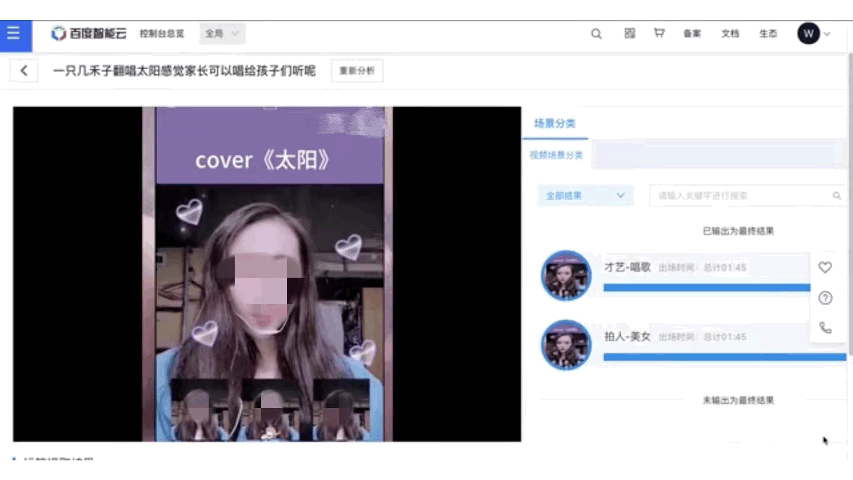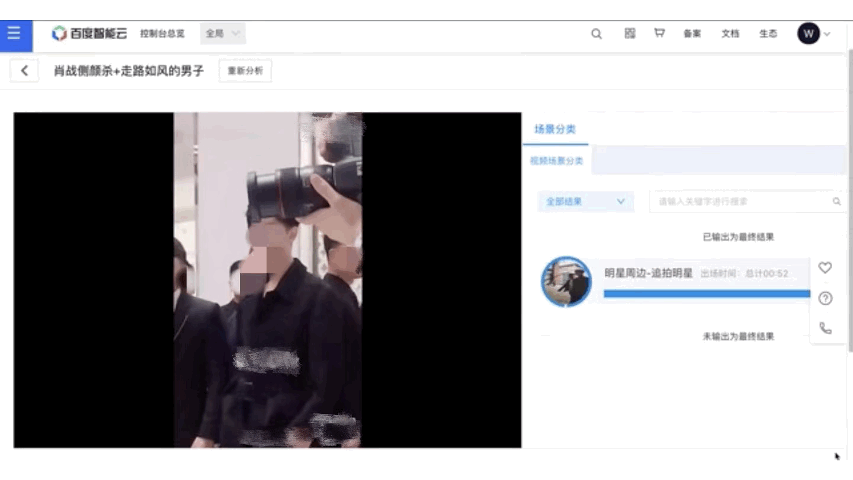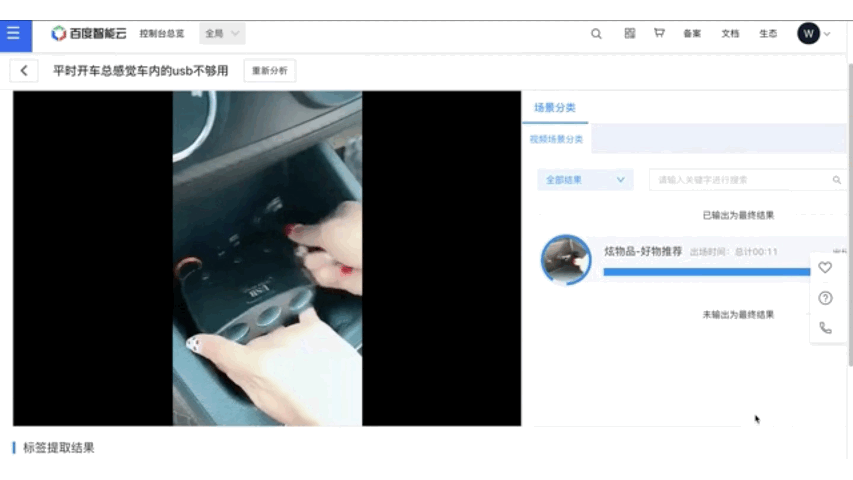
在视频内容分析方向,飞桨开源了基础的VideoTag和多模态的MultimodalVideoTag。VideoTag支持3000个源于产业实践的实用标签,具有良好的泛化能力,非常适用于国内大规模短视频分类场景的应用,标签准确率达到89%。
 |
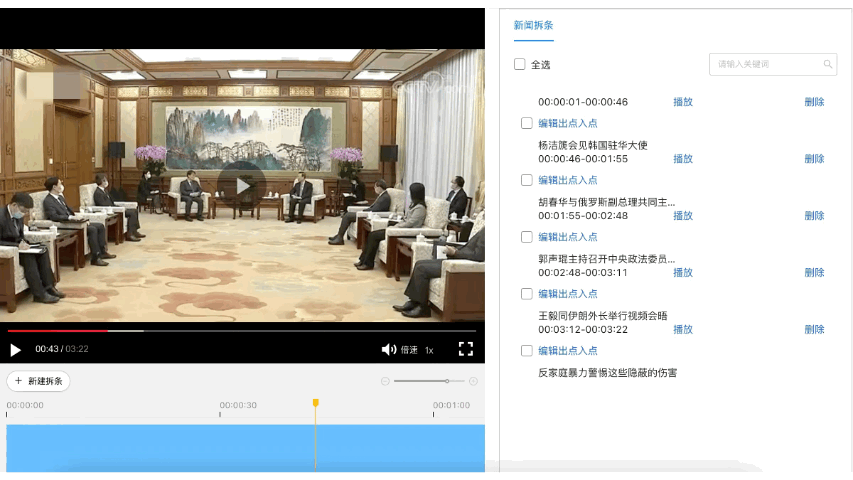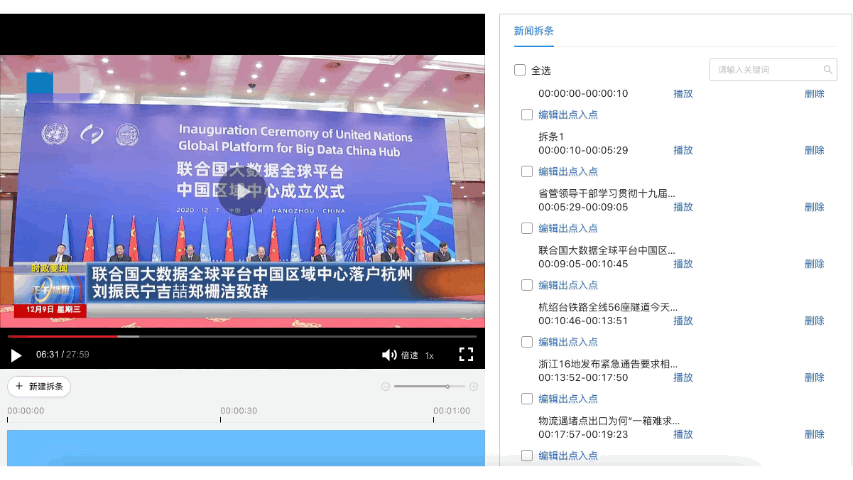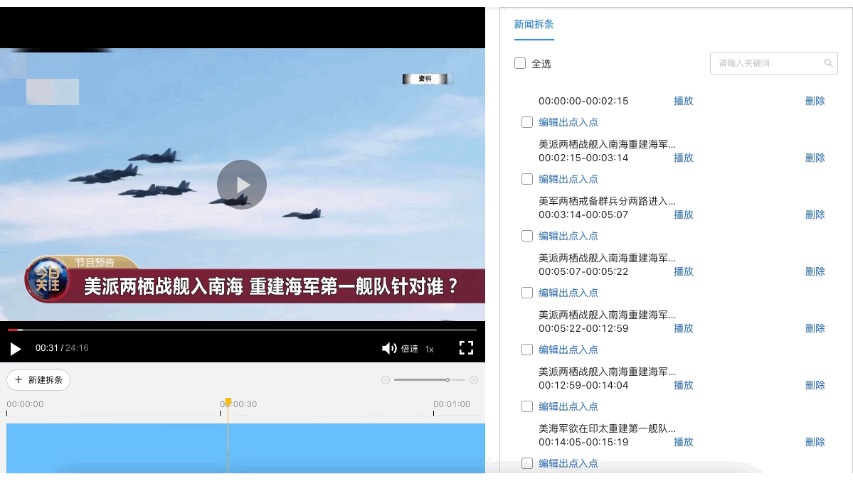
在视频智能生产方向,主要目标是辅助内容创作者对视频进行二次编辑。飞桨开源了基于PP-TSM的视频质量分析模型,可以实现新闻视频拆条和视频智能封面两大生产应用解决方案,其中新闻拆条是广电媒体行业的编辑们的重要素材来源;智能封面在直播、互娱等泛互联网行业的点击率和推荐效果方面发挥重要作用。
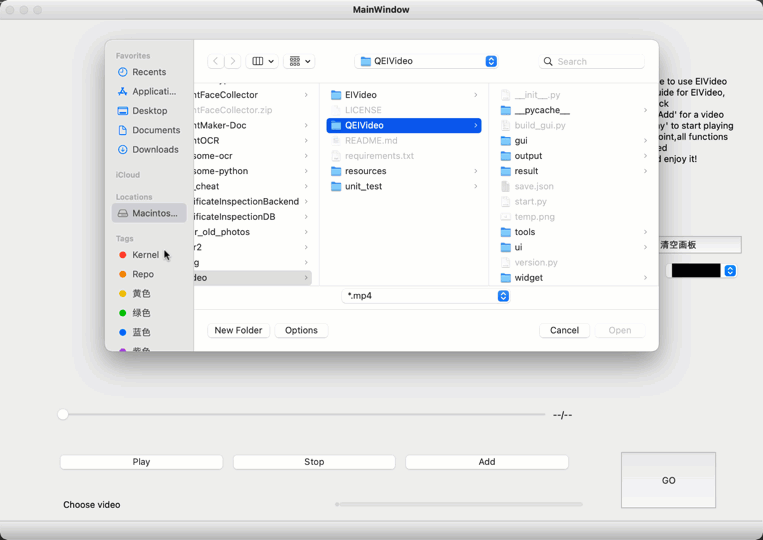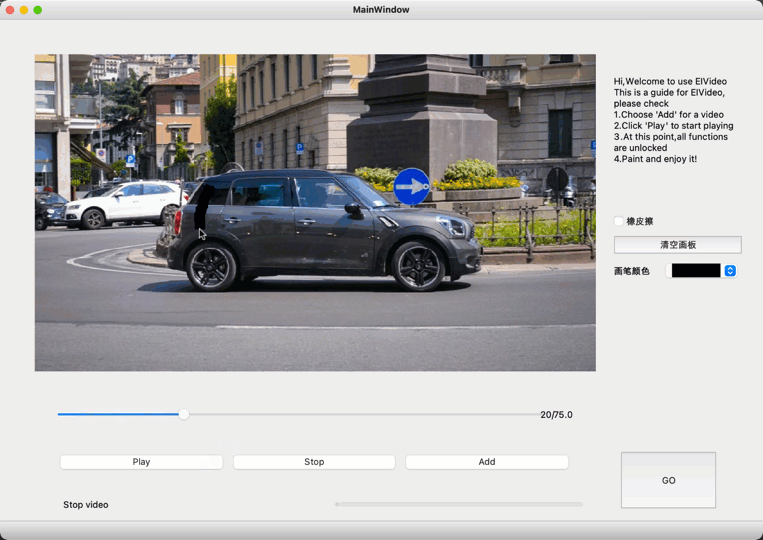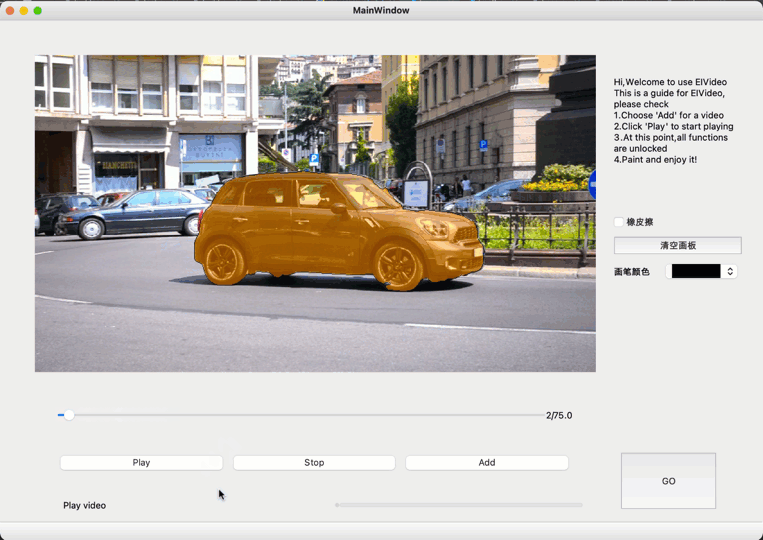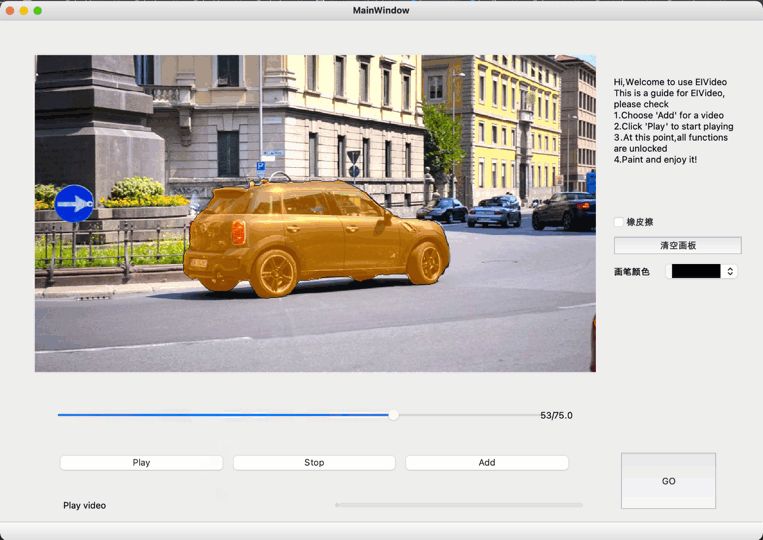
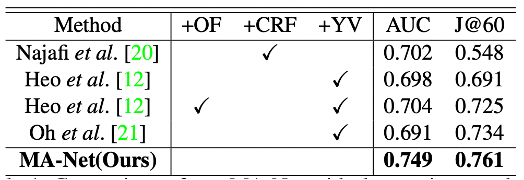
飞桨开源了基于MA-Net的交互式视频分割(interactive VOS)工具,提供少量的人工监督信号来实现较好的分割结果,可以仅靠标注简单几帧完成全视频标注,之后可通过多次和视频交互而不断提升视频分割质量,直至对分割质量满意。
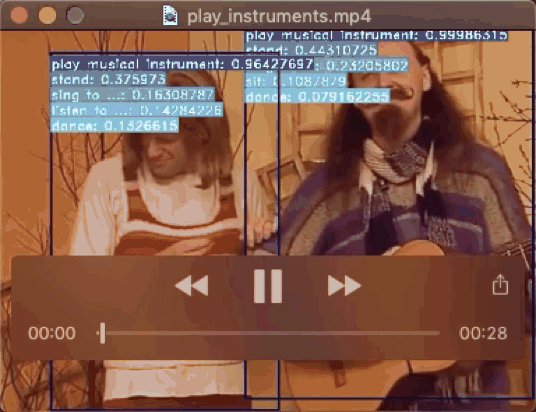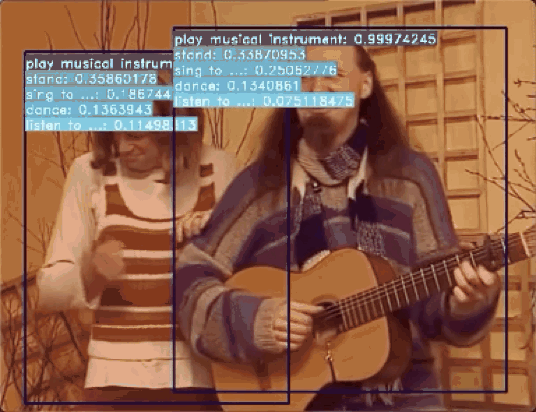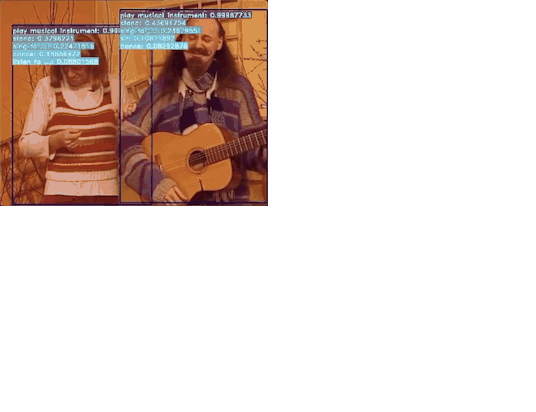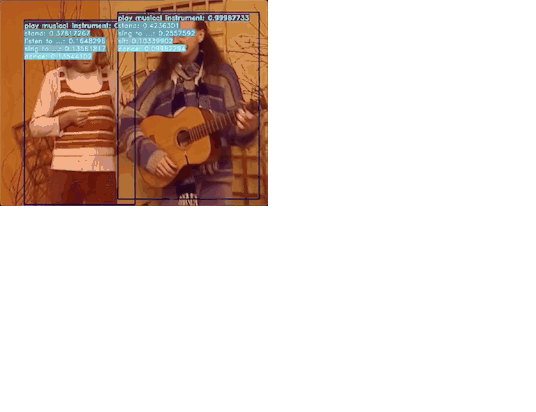
飞桨基于时空动作检测模型实现了识别多种人类行为的方案,利用视频多帧时序信息解决传统检测单帧效果差的问题,从数据处理、模型训练、模型测试到模型推理,可以实现AVA数据集中80个动作和自研的7个异常行为(挥棍、打架、踢东西、追逐、争吵、快速奔跑、摔倒)的识别。模型的效果远超目标检测方案。
 |
 |
禁飞领域无人机检测有如下挑战:
 |
 |
五大冠军、顶会算法开源
百度研究院首次开源自研冠军、顶会算法
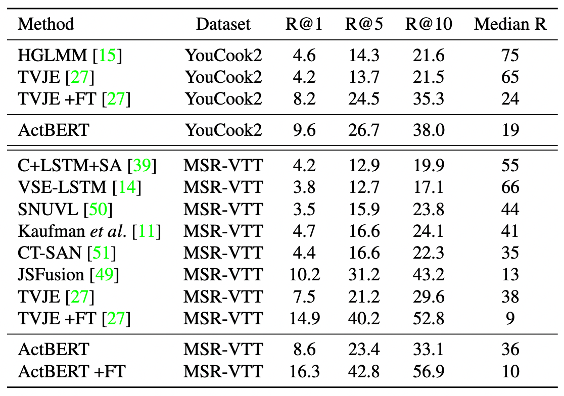
ActBERT是融合了视频、图像和文本的多模态预训练模型,它使用一种全新的纠缠编码模块从三个来源进行多模态特征学习,以增强两个视觉输入和语言之间的互动功能。该纠缠编码模块,在全局动作信息的指导下,对语言模型注入了视觉信息,并将语言信息整合到视觉模型中。纠缠编码器动态选择合适的上下文以促进目标预测。简单来说,纠缠编码器利用动作信息催化局部区域与文字的相互关联。在文本视频检索、视频描述、视频问答等5个下游任务上,ActBERT均明显优于其他方法。下表展示了ActBERT模型在文本视频检索数据集MSR-VTT上的性能表现。
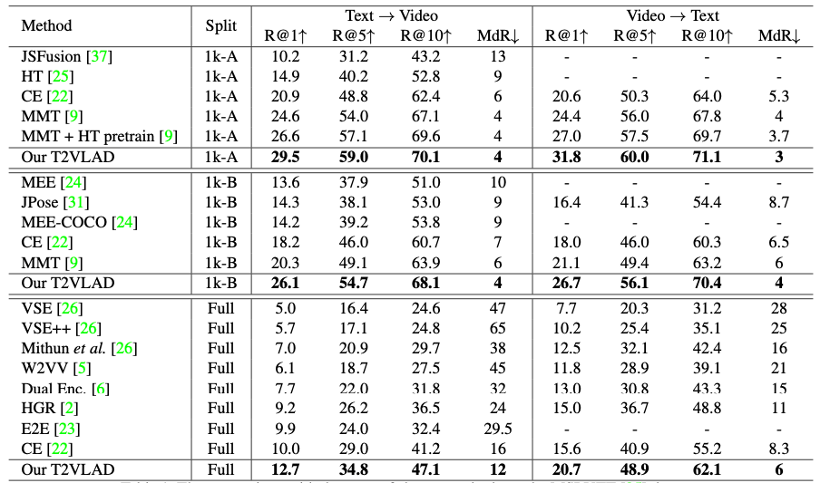
随着各种互联网视频尤其是短视频的火热,文本视频检索在近段时间获得了学术界和工业界的广泛关注。特别是在引入多模态视频信息后,如何精细化地配准局部视频特征和自然语言特征成为一大难点。T2VLAD采用一种高效的全局-局部的对齐方法,自动学习文本和视频信息共享的语义中心,并对聚类后的局部特征做对应匹配,避免了复杂的计算,同时赋予了模型精细化理解语言和视频局部信息的能力。
视频目标分割(VOS)是计算机视觉领域的一个基础任务,有很多重要的应用场景,如视频编辑、场景理解及自动驾驶等。交互式视频目标分割由用户在视频的某一帧中给目标物体简单的标注(比如在目标物体上画几条简单的线),就能够通过算法获得整个视频中该目标物体的分割结果,用户可以通过多次和视频交互而不断提升视频分割质量,直到用户对分割质量满意。
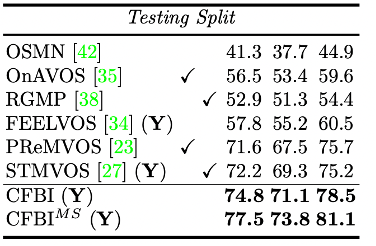
在视频目标分割领域中,半监督领域在今年来备受关注。给定视频中第一帧或多个参考帧中的目标标定,半监督方法需要精确跟踪并分割出目标物体在整个视频中的掩模。以往的视频目标分割方法都专注于提取给定的前景目标的鲁棒特征,但这在遮挡、尺度变化以及背景中存在相似物体的等等复杂场景下是十分困难的。基于此,我们重新思考了背景特征的重要性,并提出了前背景整合式的视频目标分割方法(CFBI)。
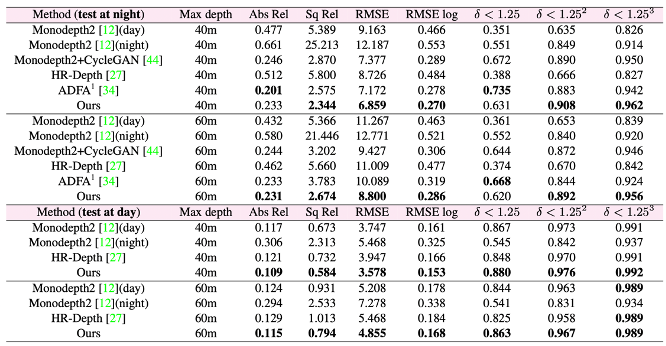
ADDS是基于白天和夜晚图像的自监督单目深度估计模型,其利用了白天和夜晚的图像数据互补性质,减缓了昼夜图像较大的域偏移以及照明变化对深度估计的精度带来的影响,在具有挑战性的牛津RobotCar数据集上实现了全天图像的最先进的深度估计结果。下表展示了ADDS模型在白天和夜间数据集上的测试性能表现。
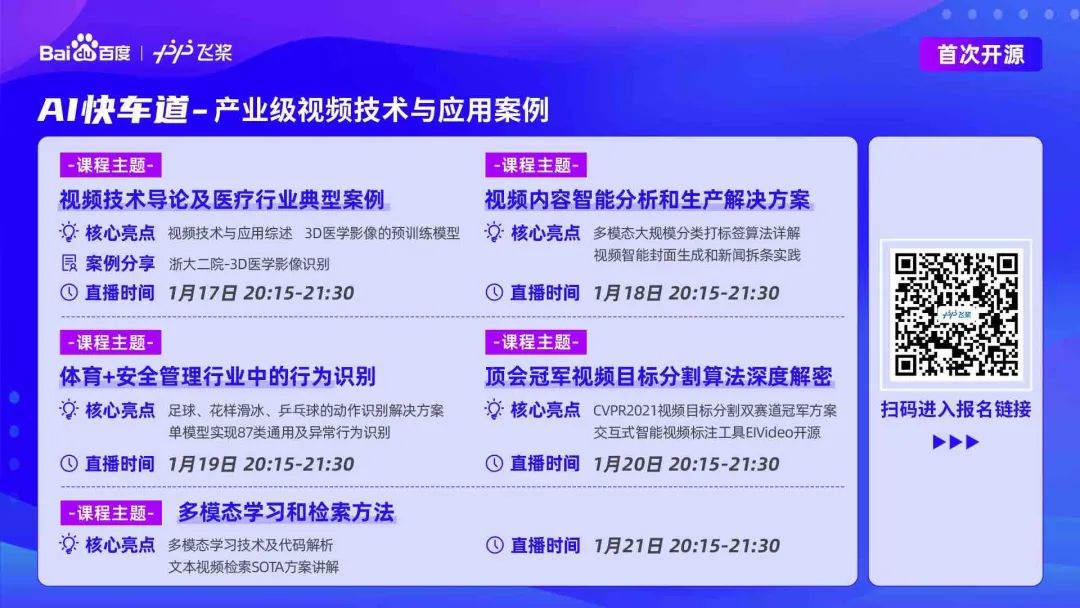
精彩课程预告
1.17~1.21日每晚20:15~21:30,飞桨联合百度智能云、百度研究院数十位高工为大家带来直播讲解,剖析行业痛点问题,深入解读体育、互联网、医疗、媒体等行业应用案例及产业级视频技术方案,并带来手把手项目实战。扫码或点击"阅读原文"进行报名,我们直播间不见不散~

发布10个视频领域产业级应用案例,涵盖体育、互联网、医疗、媒体和安全等行业。
首次开源5个冠军/顶会/产业级算法,包含视频-文本学习、视频分割、深度估计、视频-文本检索、动作识别/视频分类等技术方向。
配套丰富的文档和教程,更有直播课程和用户交流群,可以与百度资深研发工程师一起讨论交流。
十大视频场景化应用
工具详解
飞桨PaddleVideo基于体育行业中足球/篮球/乒乓球/花样滑冰等场景,开源出一套通用的体育类动作识别框架;针对互联网和媒体场景开源了基于知识增强的大规模多模态分类打标签、智能剪辑和视频拆条等解决方案;针对安全、教育、医疗等场景开源了多种检测识别案例。百度智能云结合飞桨深度学习技术也形成了一系列深度打磨的产业级多场景动作识别、视频智能分析和生产以及医疗分析等解决方案。
篮球案例BasketballAction整体框架与FootballAction类似,共包含7个动作类别,分别为:背景、进球-三分球、进球-两分球、进球-扣篮、罚球、跳球。准确率超过90%。
在百度Create 2021(百度AI开发者大会)上,PaddleVideo联合北京大学一同发布的乒乓球动作进行识别模型,基于超过500G的比赛视频构建了标准的训练数据集,标签涵盖发球、拉、摆短等8个大类动作。其中起止回合准确率达到了97%以上,动作识别也达到了80%以上。
使用姿态估计算法提取关节点数据,最后将关节点数据输入时空图卷积网络ST-GCN模型中进行动作分类,可以实现30种动作的分类。飞桨联合CCF(中国计算机学会)举办了花样滑冰动作识别大赛,吸引了300家高校与200家企业超过3800人参赛,冠军方案比基线方案精度提升了12个点,比赛top3方案已经开源。
|
|
在视频内容分析方向,飞桨开源了基础的VideoTag和多模态的MultimodalVideoTag。VideoTag支持3000个源于产业实践的实用标签,具有良好的泛化能力,非常适用于国内大规模短视频分类场景的应用,标签准确率达到89%。
|
在视频智能生产方向,主要目标是辅助内容创作者对视频进行二次编辑。飞桨开源了基于PP-TSM的视频质量分析模型,可以实现新闻视频拆条和视频智能封面两大生产应用解决方案,其中新闻拆条是广电媒体行业的编辑们的重要素材来源;智能封面在直播、互娱等泛互联网行业的点击率和推荐效果方面发挥重要作用。
飞桨开源了基于MA-Net的交互式视频分割(interactive VOS)工具,提供少量的人工监督信号来实现较好的分割结果,可以仅靠标注简单几帧完成全视频标注,之后可通过多次和视频交互而不断提升视频分割质量,直至对分割质量满意。
飞桨基于时空动作检测模型实现了识别多种人类行为的方案,利用视频多帧时序信息解决传统检测单帧效果差的问题,从数据处理、模型训练、模型测试到模型推理,可以实现AVA数据集中80个动作和自研的7个异常行为(挥棍、打架、踢东西、追逐、争吵、快速奔跑、摔倒)的识别。模型的效果远超目标检测方案。
|
|
禁飞领域无人机检测有如下挑战:
|
|
五大冠军、顶会算法开源
百度研究院首次开源自研冠军、顶会算法
ActBERT是融合了视频、图像和文本的多模态预训练模型,它使用一种全新的纠缠编码模块从三个来源进行多模态特征学习,以增强两个视觉输入和语言之间的互动功能。该纠缠编码模块,在全局动作信息的指导下,对语言模型注入了视觉信息,并将语言信息整合到视觉模型中。纠缠编码器动态选择合适的上下文以促进目标预测。简单来说,纠缠编码器利用动作信息催化局部区域与文字的相互关联。在文本视频检索、视频描述、视频问答等5个下游任务上,ActBERT均明显优于其他方法。下表展示了ActBERT模型在文本视频检索数据集MSR-VTT上的性能表现。
随着各种互联网视频尤其是短视频的火热,文本视频检索在近段时间获得了学术界和工业界的广泛关注。特别是在引入多模态视频信息后,如何精细化地配准局部视频特征和自然语言特征成为一大难点。T2VLAD采用一种高效的全局-局部的对齐方法,自动学习文本和视频信息共享的语义中心,并对聚类后的局部特征做对应匹配,避免了复杂的计算,同时赋予了模型精细化理解语言和视频局部信息的能力。
视频目标分割(VOS)是计算机视觉领域的一个基础任务,有很多重要的应用场景,如视频编辑、场景理解及自动驾驶等。交互式视频目标分割由用户在视频的某一帧中给目标物体简单的标注(比如在目标物体上画几条简单的线),就能够通过算法获得整个视频中该目标物体的分割结果,用户可以通过多次和视频交互而不断提升视频分割质量,直到用户对分割质量满意。
在视频目标分割领域中,半监督领域在今年来备受关注。给定视频中第一帧或多个参考帧中的目标标定,半监督方法需要精确跟踪并分割出目标物体在整个视频中的掩模。以往的视频目标分割方法都专注于提取给定的前景目标的鲁棒特征,但这在遮挡、尺度变化以及背景中存在相似物体的等等复杂场景下是十分困难的。基于此,我们重新思考了背景特征的重要性,并提出了前背景整合式的视频目标分割方法(CFBI)。
ADDS是基于白天和夜晚图像的自监督单目深度估计模型,其利用了白天和夜晚的图像数据互补性质,减缓了昼夜图像较大的域偏移以及照明变化对深度估计的精度带来的影响,在具有挑战性的牛津RobotCar数据集上实现了全天图像的最先进的深度估计结果。下表展示了ADDS模型在白天和夜间数据集上的测试性能表现。
精彩课程预告
1.17~1.21日每晚20:15~21:30,飞桨联合百度智能云、百度研究院数十位高工为大家带来直播讲解,剖析行业痛点问题,深入解读体育、互联网、医疗、媒体等行业应用案例及产业级视频技术方案,并带来手把手项目实战。扫码或点击"阅读原文"进行报名,我们直播间不见不散~