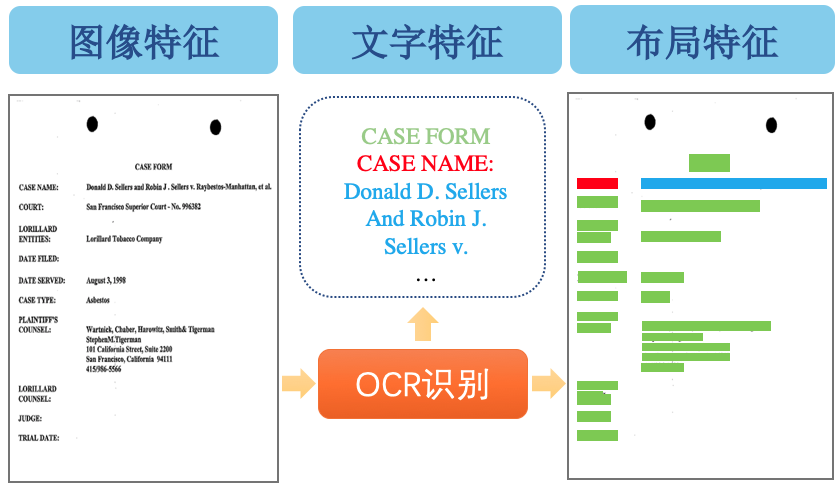
光学字符识别(OCR)是目前应用最为广泛的视觉AI技术之一。随着OCR技术在产业应用的快速发展,现实场景对OCR提出新的需求:从感知走向认知——OCR不但需要认识文字,也要进一步理解文字。因此,结构化逐渐成为OCR产业应用的核心技术之一,旨在快速且准确地分析卡证、票据、档案图像等富视觉数据中的结构化文字信息,并对关键数据进行提取。OCR结构化技术通常要解决两个高频应用任务类型:
实体分类:提取OCR结果中与预定义实体标签(例如“姓名”,“日期”等)对应的文本内容;
实体连接:分析文本实体间的关系,例如是否组成键(key)-值(value)对、是否属于表格里的同行或同列。
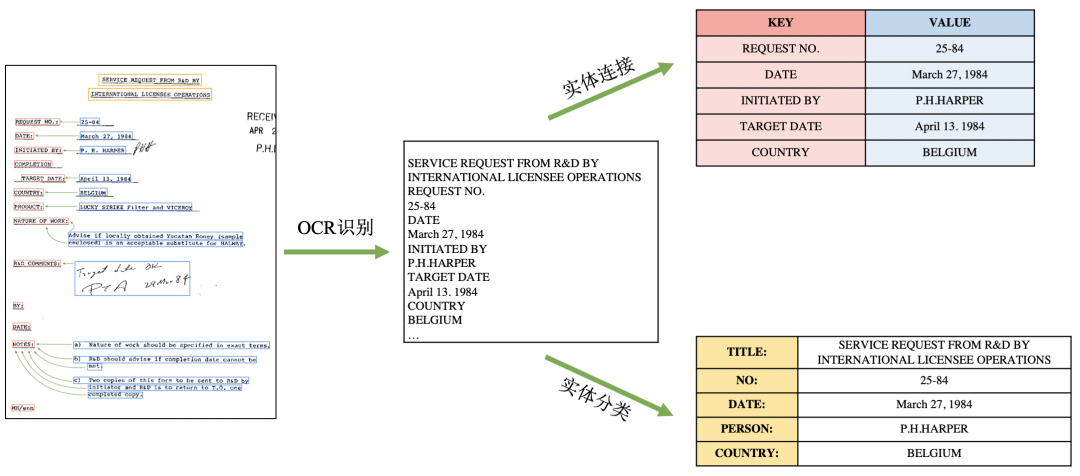
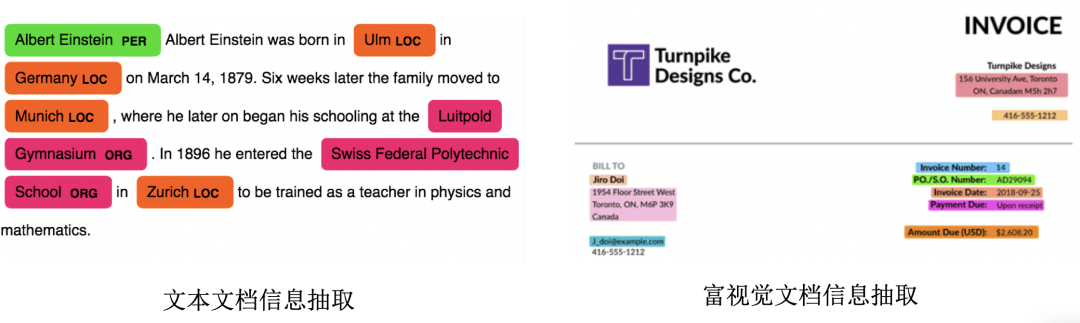
图像信息提取方法:基于检测分割等计算机视觉任务,定位文本实体的图像区域;
1.首创字段级多模态特征增强:提出字段级文档结构建模,结合文本序列,提出遮罩式视觉语言模型、字段长度预测、字段方位预测,更有效理解富视觉文档。
2.中英文场景上效果全面领先:覆盖4w+中英文常见字词,实现业界最大规模5千万OCR中英文场景数据预训练,深度挖掘不同模态间的语义关联。
3.完备的OCR字段解析能力:基于双粒度输出框架,灵活的建模粒度选择,可支持字符信息抽取、字段信息抽取和字段连接预测三种结构化信息提取任务。
4.单模型支持多个下游任务:支持中英混合场景的OCR场景,单模型可并行处理多个下游任务。
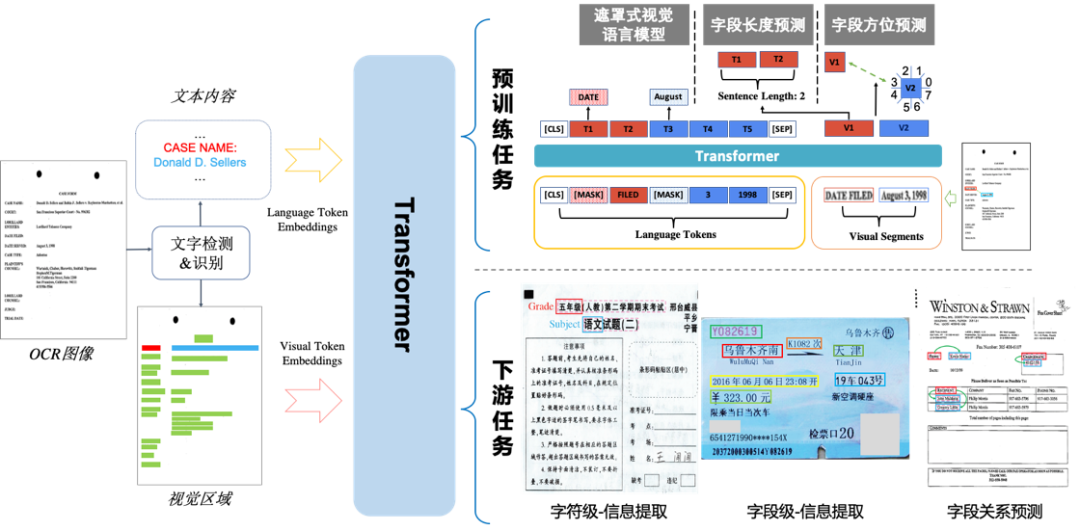
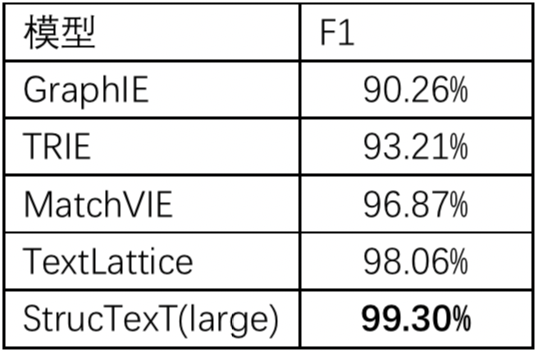
1.字符信息抽取任务:StrucTexT基于预训练模型使用字符粒度的分类方式,在中文试卷数据集EPHOIE上取得了99.30%的卓越效果。
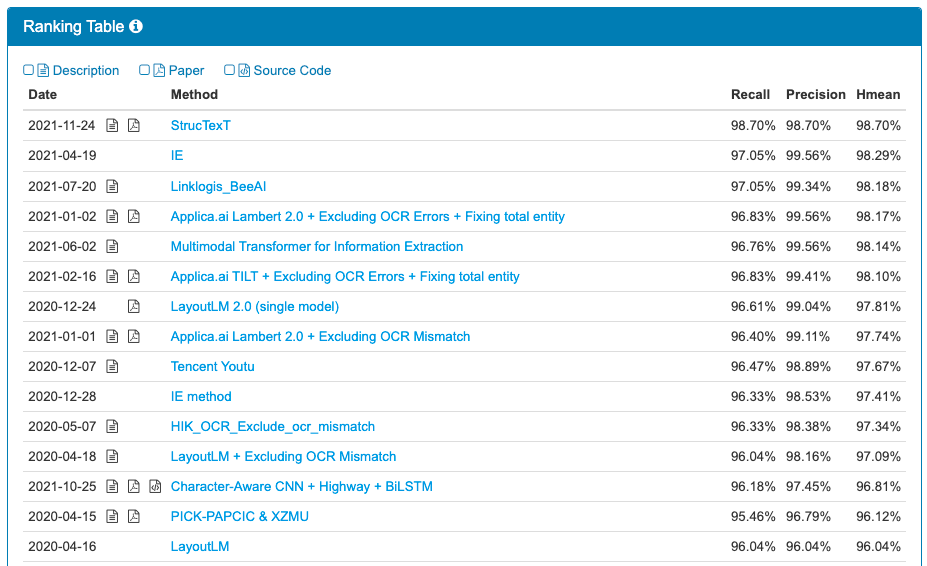
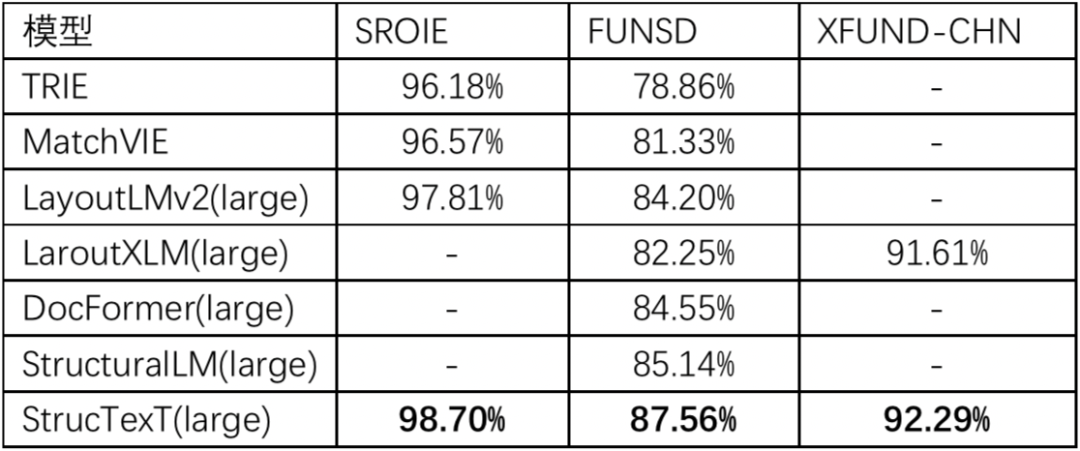
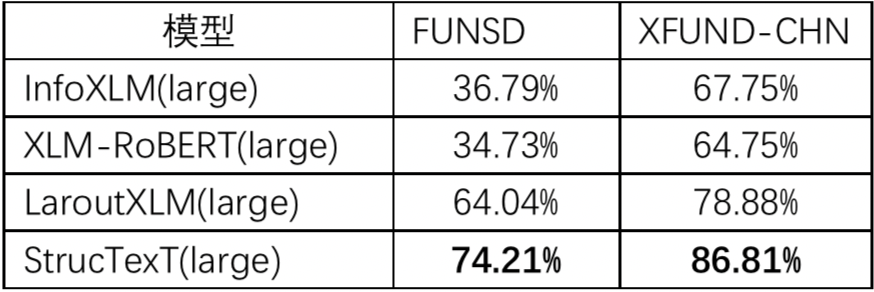
StrucTexT强力支持,
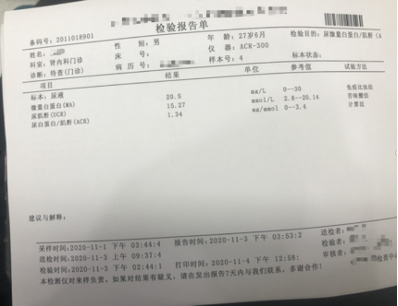
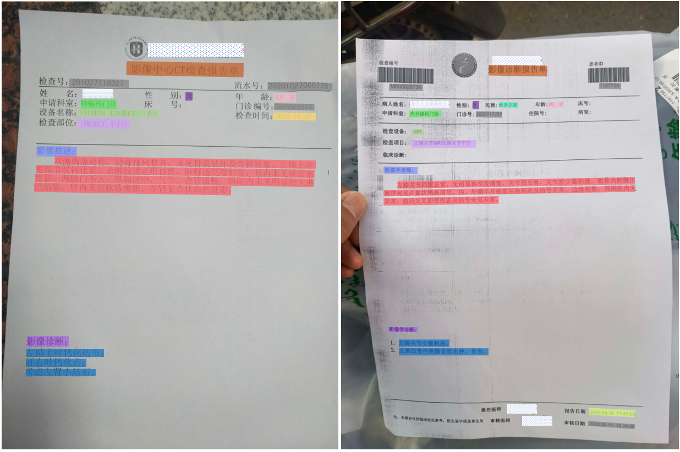
1.票据种类繁多:单单常见的清单、发票、检验报告单就有上百余种。
2.票据版式不一:各个省市医院输出版面各有不同,形式纷繁复杂。医疗机构为了方便,往往不按照规范打印,内容排版极为随意,存在遮挡、偏移、叠字等较强干扰。
3.图像采集不规范:健康险属于C端服务,用户拍照行为不规范,单据存在折损、弯曲、形变等问题,上传的图像质量不高。
4.票据排版复杂:医疗单据属于多类型文字混排,包含中英文、数字和特殊符号,文字识别难度大。
结束语

光学字符识别(OCR)是目前应用最为广泛的视觉AI技术之一。随着OCR技术在产业应用的快速发展,现实场景对OCR提出新的需求:从感知走向认知——OCR不但需要认识文字,也要进一步理解文字。因此,结构化逐渐成为OCR产业应用的核心技术之一,旨在快速且准确地分析卡证、票据、档案图像等富视觉数据中的结构化文字信息,并对关键数据进行提取。OCR结构化技术通常要解决两个高频应用任务类型:
实体分类:提取OCR结果中与预定义实体标签(例如“姓名”,“日期”等)对应的文本内容;
实体连接:分析文本实体间的关系,例如是否组成键(key)-值(value)对、是否属于表格里的同行或同列。
图像信息提取方法:基于检测分割等计算机视觉任务,定位文本实体的图像区域;
1.首创字段级多模态特征增强:提出字段级文档结构建模,结合文本序列,提出遮罩式视觉语言模型、字段长度预测、字段方位预测,更有效理解富视觉文档。
2.中英文场景上效果全面领先:覆盖4w+中英文常见字词,实现业界最大规模5千万OCR中英文场景数据预训练,深度挖掘不同模态间的语义关联。
3.完备的OCR字段解析能力:基于双粒度输出框架,灵活的建模粒度选择,可支持字符信息抽取、字段信息抽取和字段连接预测三种结构化信息提取任务。
4.单模型支持多个下游任务:支持中英混合场景的OCR场景,单模型可并行处理多个下游任务。
1.字符信息抽取任务:StrucTexT基于预训练模型使用字符粒度的分类方式,在中文试卷数据集EPHOIE上取得了99.30%的卓越效果。
StrucTexT强力支持,
1.票据种类繁多:单单常见的清单、发票、检验报告单就有上百余种。
2.票据版式不一:各个省市医院输出版面各有不同,形式纷繁复杂。医疗机构为了方便,往往不按照规范打印,内容排版极为随意,存在遮挡、偏移、叠字等较强干扰。
3.图像采集不规范:健康险属于C端服务,用户拍照行为不规范,单据存在折损、弯曲、形变等问题,上传的图像质量不高。
4.票据排版复杂:医疗单据属于多类型文字混排,包含中英文、数字和特殊符号,文字识别难度大。
结束语