部署"桨"坛栏目聚焦AI硬件部署,分享多款厂商硬件部署方案及教程,帮助开发者们实现模型训练与推理的一体化开发和多硬件设备间的无缝切换。
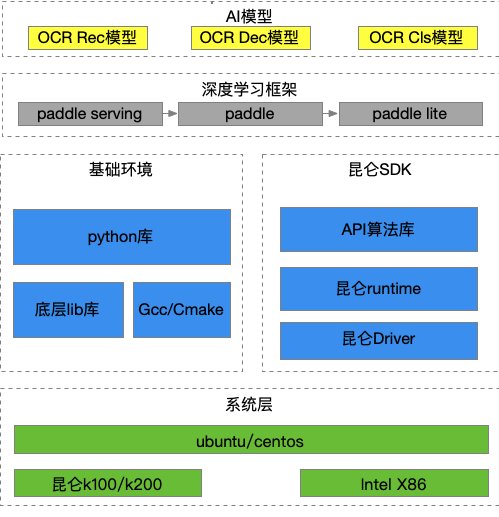
本期让我们将目光聚焦到飞桨与AI芯片公司——昆仑芯的适配合作。昆仑芯在实际业务场景中深耕AI加速领域已十余年,是一家在体系结构、芯片实现、软件系统和场景应用均有深厚积累的AI芯片企业。
3.目前支持的开源模型
飞桨自2.0版本起支持在昆仑XPU上运行,经验证的训练和预测的模型支持情况包括:图像分类、目标检测、图像分割、NLP、推荐、强化学习、OCR等领域的模型。详细的模型支持情况可以参考官网“飞桨对昆仑XPU芯片的支持”一文。地址:
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/09_hardware_support/xpu_docs/paddle_2.0_xpu_cn.html
1. # 检查pci插卡正常
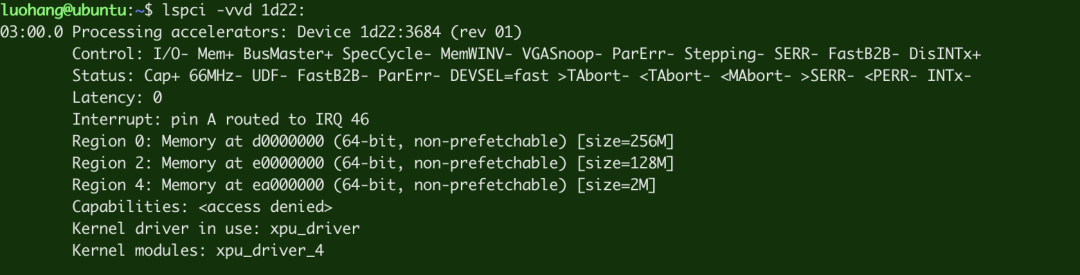
2. lspci -vvd 1d22:
如果插卡正常,输出类似下图所示:
如果没有输出,说明没有找到卡,可能pcie链路有问题。建议换插槽、重启机器,反复尝试,直到lspci有输出。
1. # 查看内核版本信息
2. uname -a

接着输入以下命令,检查芯片信息和以及状态是否正常:
1. # 检查芯片信息和状态正常
2. wget https://baidu-kunlun-public.su.bcebos.com/runtime_release_x86/xpu_smi
3. sudo chmod +x xpu_smi
4. ./xpu_smi
如果驱动安装正常,输出类似下图所示:
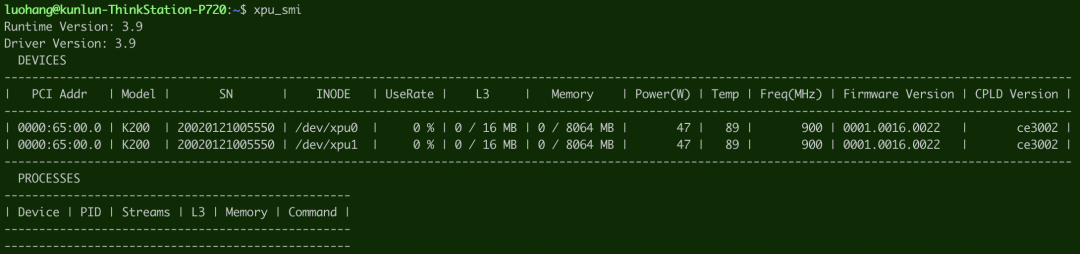
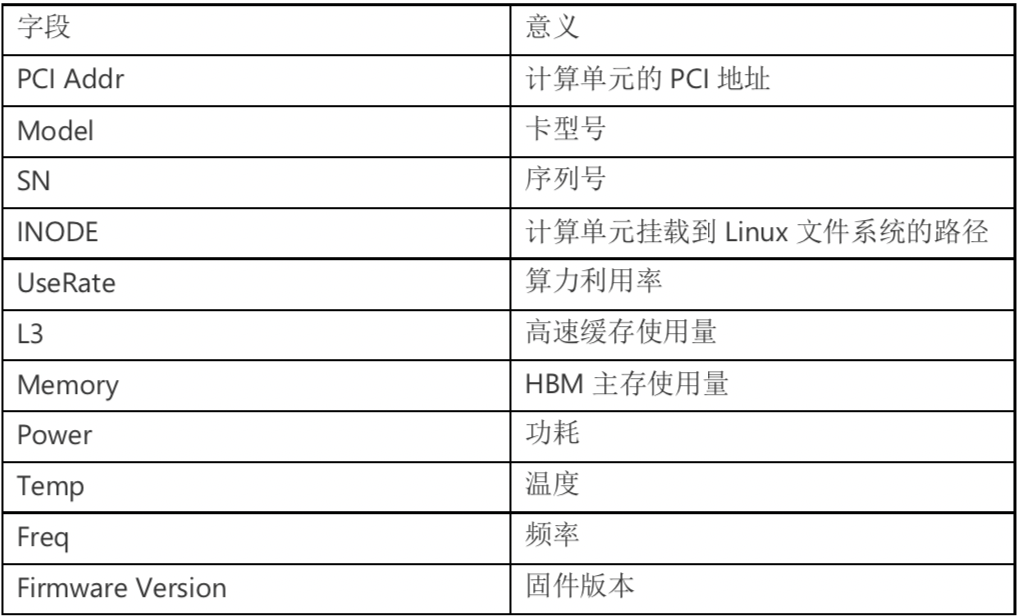
上图显示,这台机器上有两个计算单元(pd),分别是/dev/xpu0和/dev/xpu1(K200有两个计算单元,K100有一个计算单元)。部分字段意义:
1. # 切换root
2. sudo su
3. mkdir workspace
4. cd workspace
(2)下载PP-OCR推理部署包:
a.下载包含飞桨轻量化推理引擎Paddle Lite 与 PP-OCR 模型的本地部署包:
注:该版本只支持使用一个计算单元。
1. wget https://baidu-kunlun-public.su.bcebos.com/haiguangx86/ocr_infer_paddle2.1_lite_xpu.tar
2. tar -xvf ocr_infer_paddle2.1_lite_xpu.tar
1. wget https://baidu-kunlun-public.su.bcebos.com/haiguangx86/ocr_infer_paddle2.2_lite_multi_xpu_serving.tar
2. tar -xvf ocr_infer_paddle2.2_lite_multi_xpu_serving.tar
a.检查docker环境是否正常安装:执行命令
1. docker images
如果正常则会输出类似如下图信息:

1. docker ps -a
会输出类似如下图信息:

1. docker start ppocr
2. docker exec -it ppocr bash
(4)飞桨推理环境配置:根据所选择的部署方式对应的安装包,分别进入workspace目录下对应的解压目录如ocr_infer_paddle2.1_lite_xpu或ocr_infer_paddle2.2_lite_multi_xpu_serving。
1. cd PaddleOCR
1. # 执行推理。命令较长,复制粘贴请注意无效空格
2. python3.7 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False --rec_batch_num=1
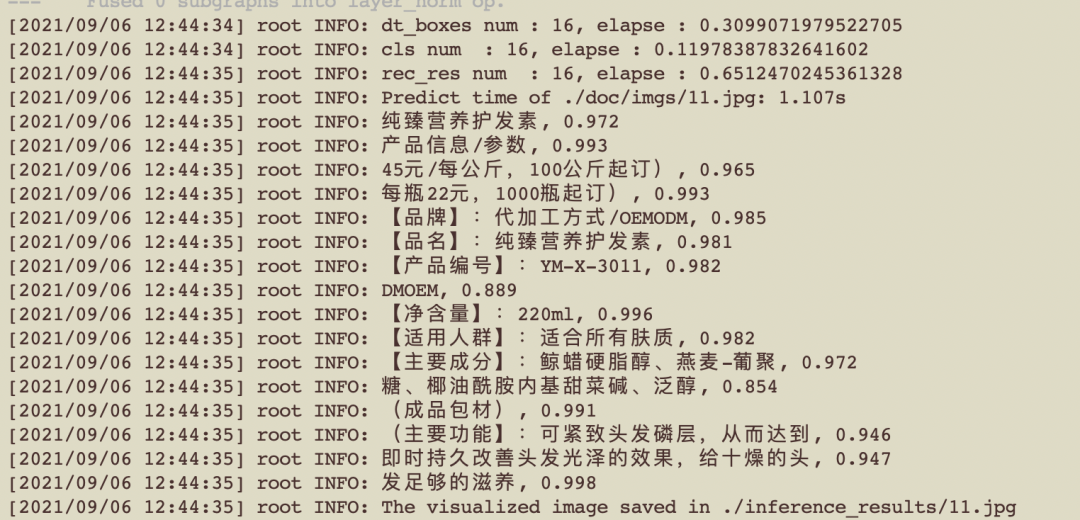
1. cd deploy/pdserving/
2. bash start.sh
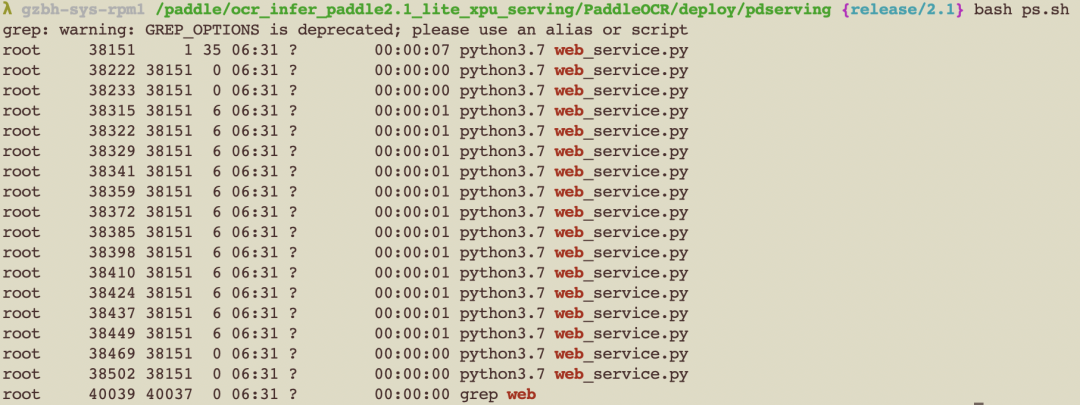
1. bash ps.sh
1. bash send.sh
import numpy as np
import requests
import json
import base64
import os
def cv2_to_base64(image):
return base64.b64encode(image).decode('utf8')
url = "http://127.0.0.1:9998/ocr/prediction"
test_img_dir = "../../doc/test_detect_3/"
for idx, img_file in enumerate(os.listdir(test_img_dir)):
with open(os.path.join(test_img_dir, img_file), 'rb') as file:
image_data1 = file.read()
image = cv2_to_base64(image_data1)
for i in range(1):
data = {"key": ["image"], "value": [image]}
r = requests.post(url=url, data=json.dumps(data))
print(r.json())
#test_img_dir = "../../doc/imgs/"
print("==> total number of test imgs: ", len(os.listdir(test_img_dir)))
try:
from paddle_serving_server_gpu.pipeline import PipelineClient
except ImportError:
from paddle_serving_server.pipeline import PipelineClient
import numpy as np
import requests
import json
import cv2
import base64
import os
client = PipelineClient()
client.connect(['127.0.0.1:18091'])
def cv2_to_base64(image):
return base64.b64encode(image).decode('utf8')
test_img_dir = "imgs/"
for img_file in os.listdir(test_img_dir):
with open(os.path.join(test_img_dir, img_file), 'rb') as file:
image_data = file.read()
image = cv2_to_base64(image_data)
for i in range(1):
ret = client.predict(feed_dict={"image": image}, fetch=["res"])
print(ret)
(4)关闭serving server:
1. cd PaddleOCR/deploy/pdserving/
2. bash kill.sh
3. bash ps.sh

至此,飞桨PP-OCR模型已经可以在昆仑芯AI加速卡K200上运行。开发者也可以根据自己的应用需求,训练模型进行部署。
昆仑芯AI加速卡
K200介绍
采用昆仑芯1代芯片,256 TOPS@INT8 算力,HBM 16GB 高速显存,512GB/s 访存带宽可广泛支持自然语言处理、计算机视觉、语音以及传统机器学习等各类人工智能任务万片级别规模落地,并经过了互联网核心算法对稳定性、可用性、可靠性和鲁棒性的考验,业界领先。下图是K200参数介绍。
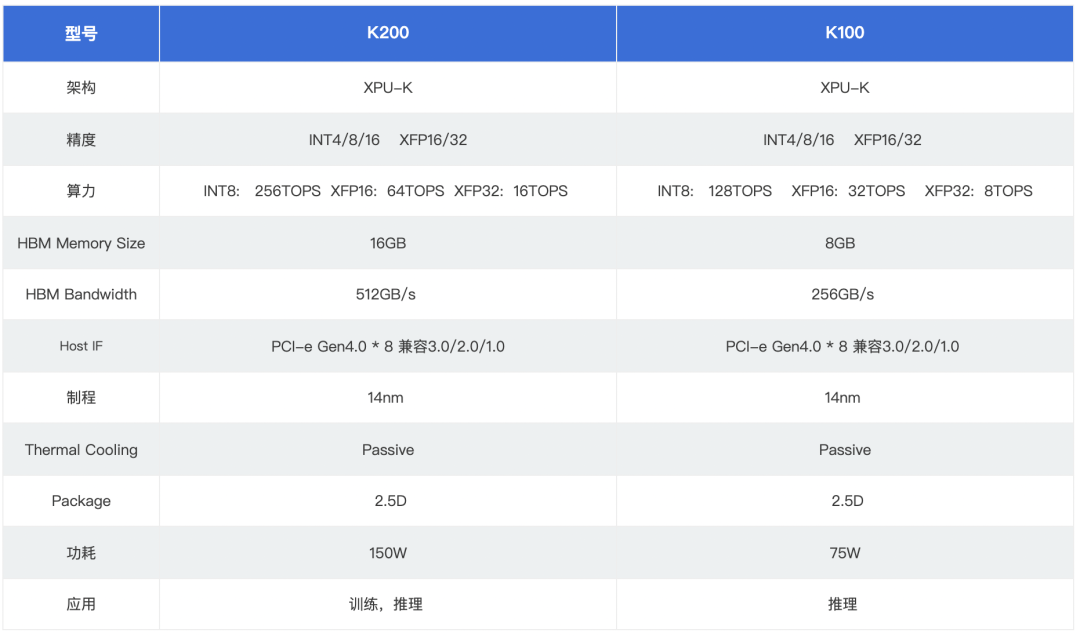
图:参数来源来自昆仑芯官网介绍:
http://www.kunlunxin.com.cn/k200-100

部署"桨"坛栏目聚焦AI硬件部署,分享多款厂商硬件部署方案及教程,帮助开发者们实现模型训练与推理的一体化开发和多硬件设备间的无缝切换。
本期让我们将目光聚焦到飞桨与AI芯片公司——昆仑芯的适配合作。昆仑芯在实际业务场景中深耕AI加速领域已十余年,是一家在体系结构、芯片实现、软件系统和场景应用均有深厚积累的AI芯片企业。
3.目前支持的开源模型
飞桨自2.0版本起支持在昆仑XPU上运行,经验证的训练和预测的模型支持情况包括:图像分类、目标检测、图像分割、NLP、推荐、强化学习、OCR等领域的模型。详细的模型支持情况可以参考官网“飞桨对昆仑XPU芯片的支持”一文。地址:
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/09_hardware_support/xpu_docs/paddle_2.0_xpu_cn.html
1. # 检查pci插卡正常
2. lspci -vvd 1d22:
如果插卡正常,输出类似下图所示:
如果没有输出,说明没有找到卡,可能pcie链路有问题。建议换插槽、重启机器,反复尝试,直到lspci有输出。
1. # 查看内核版本信息
2. uname -a
接着输入以下命令,检查芯片信息和以及状态是否正常:
1. # 检查芯片信息和状态正常
2. wget https://baidu-kunlun-public.su.bcebos.com/runtime_release_x86/xpu_smi
3. sudo chmod +x xpu_smi
4. ./xpu_smi
如果驱动安装正常,输出类似下图所示:
上图显示,这台机器上有两个计算单元(pd),分别是/dev/xpu0和/dev/xpu1(K200有两个计算单元,K100有一个计算单元)。部分字段意义:
1. # 切换root
2. sudo su
3. mkdir workspace
4. cd workspace
(2)下载PP-OCR推理部署包:
a.下载包含飞桨轻量化推理引擎Paddle Lite 与 PP-OCR 模型的本地部署包:
注:该版本只支持使用一个计算单元。
1. wget https://baidu-kunlun-public.su.bcebos.com/haiguangx86/ocr_infer_paddle2.1_lite_xpu.tar
2. tar -xvf ocr_infer_paddle2.1_lite_xpu.tar
1. wget https://baidu-kunlun-public.su.bcebos.com/haiguangx86/ocr_infer_paddle2.2_lite_multi_xpu_serving.tar
2. tar -xvf ocr_infer_paddle2.2_lite_multi_xpu_serving.tar
a.检查docker环境是否正常安装:执行命令
1. docker images
如果正常则会输出类似如下图信息:
1. docker ps -a
会输出类似如下图信息:
1. docker start ppocr
2. docker exec -it ppocr bash
(4)飞桨推理环境配置:根据所选择的部署方式对应的安装包,分别进入workspace目录下对应的解压目录如ocr_infer_paddle2.1_lite_xpu或ocr_infer_paddle2.2_lite_multi_xpu_serving。
1. cd PaddleOCR
1. # 执行推理。命令较长,复制粘贴请注意无效空格
2. python3.7 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False --rec_batch_num=1
1. cd deploy/pdserving/
2. bash start.sh
1. bash ps.sh
1. bash send.sh
import numpy as np
import requests
import json
import base64
import os
def cv2_to_base64(image):
return base64.b64encode(image).decode('utf8')
url = "http://127.0.0.1:9998/ocr/prediction"
test_img_dir = "../../doc/test_detect_3/"
for idx, img_file in enumerate(os.listdir(test_img_dir)):
with open(os.path.join(test_img_dir, img_file), 'rb') as file:
image_data1 = file.read()
image = cv2_to_base64(image_data1)
for i in range(1):
data = {"key": ["image"], "value": [image]}
r = requests.post(url=url, data=json.dumps(data))
print(r.json())
#test_img_dir = "../../doc/imgs/"
print("==> total number of test imgs: ", len(os.listdir(test_img_dir)))
try:
from paddle_serving_server_gpu.pipeline import PipelineClient
except ImportError:
from paddle_serving_server.pipeline import PipelineClient
import numpy as np
import requests
import json
import cv2
import base64
import os
client = PipelineClient()
client.connect(['127.0.0.1:18091'])
def cv2_to_base64(image):
return base64.b64encode(image).decode('utf8')
test_img_dir = "imgs/"
for img_file in os.listdir(test_img_dir):
with open(os.path.join(test_img_dir, img_file), 'rb') as file:
image_data = file.read()
image = cv2_to_base64(image_data)
for i in range(1):
ret = client.predict(feed_dict={"image": image}, fetch=["res"])
print(ret)(4)关闭serving server:
1. cd PaddleOCR/deploy/pdserving/
2. bash kill.sh
3. bash ps.sh
至此,飞桨PP-OCR模型已经可以在昆仑芯AI加速卡K200上运行。开发者也可以根据自己的应用需求,训练模型进行部署。
昆仑芯AI加速卡
K200介绍
采用昆仑芯1代芯片,256 TOPS@INT8 算力,HBM 16GB 高速显存,512GB/s 访存带宽可广泛支持自然语言处理、计算机视觉、语音以及传统机器学习等各类人工智能任务万片级别规模落地,并经过了互联网核心算法对稳定性、可用性、可靠性和鲁棒性的考验,业界领先。下图是K200参数介绍。
图:参数来源来自昆仑芯官网介绍:
http://www.kunlunxin.com.cn/k200-100