导读:12月12日,在上海举行的WAVE SUMMIT 2021深度学习开发者峰会上,飞桨深度学习开源框架2.2版本正式发布。飞桨是中国首个开源的深度学习框架,一直致力于让深度学习技术的创新与应用更简单。
API 体系支持更广泛的模型开发。
端到端自适应大规模分布式训练架构。
多层次、低成本的硬件适配统一方案。
加速文本任务全流程。
飞桨框架v2.2新增100+ API,主要包括:
17个线性代数API paddle.linalg.* :全面覆盖了矩阵计算、矩阵分解、矩阵属性计算、线性方程组求解等4大场景。
新增 paddle.einsum,支持以更加简洁的方式来表达多维张量(Tensor)的计算。
增加更多的张量(Tensor)高级索引操作,即可用省略号、布尔值、Python List、Paddle Tensor等作为索引去操作张量(Tensor),能够更加方便和灵活地去读写张量(Tensor)中的某些元素。
加强对AI科学计算功能的支持,包括支持高阶微分的 elementwise_add、elementwise_mul、matmul、sigmoid 和 tanh 等算子,支持函数式自动微分接口的Jacobian、Hessian、jvp、vjp、vhp 等函数式自动微分 API,从而可以便捷实现基于深度学习的微分方程的求解,解决例如计算流体力学中的 LDC(Lid Driven Cavity Flow)等问题。
v2.2 的函数式自动微分API和高阶微分
在计算流体力学场景上的探索
另一方面由于存在串行运算,这些方法难以使用GPU硬件进行加速。而深度学习的神经网络具备“万能逼近”能力,即只要网络有足够的神经元,就可以充分地逼近任意一个连续函数,基于神经网络去求解偏微分方程组为解决科学计算领域问题提供了新范式。
飞桨一方面通过改进框架自动微分机制和底层算子实现,支持了典型运算的高阶自动微分;另一方面,通过新增Jacobian、Hessian、jvp、vjp等API接口,增强了对偏微分方程组的表达能力。在以上两部分工作的基础上,飞桨实现了基于神经网络的偏微分方程组的求解,并在计算流体力学场景做了探索性的工作。
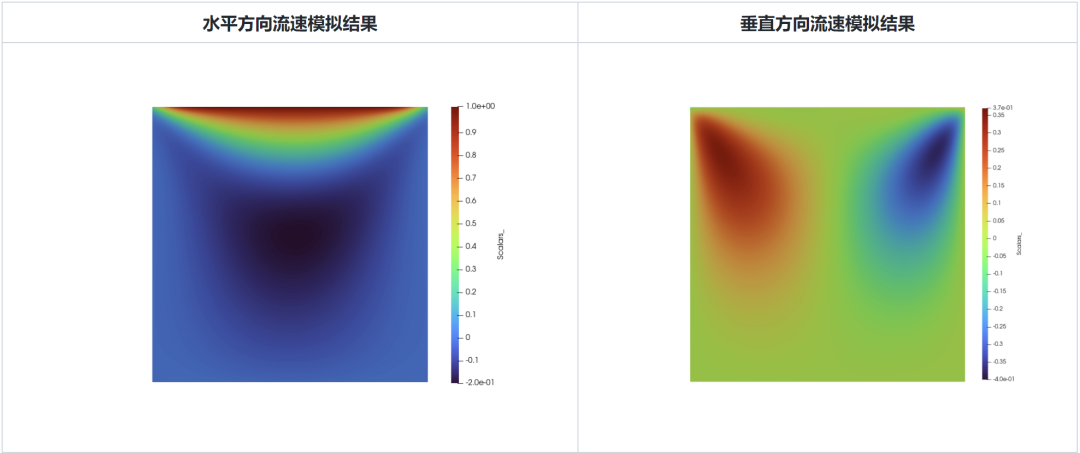
LDC是计算流体力学的一个经典问题,我们使用隐藏层节点数为50的10层全连接网络作为神经网络模型,在[-0.05, -0.05] 到[0.05, 0.05]的矩形区域上以100 * 100的为粒度划分网格,根据偏微分方程组和边界条件设计Loss,进行训练以实现对偏微分方程组的求解,从而正确模拟出了腔体内水平方向和垂直方向上的液体流速分布,与基于OpenFOAM软件实现的传统方法结果均方误差在1e-4数量级。
各网格粒度下推理结果与传统方法的均方误差均在1e-4数量级,这说明了AI方法拥有在粗网格上训练,在更细网格上推理的泛化能力。
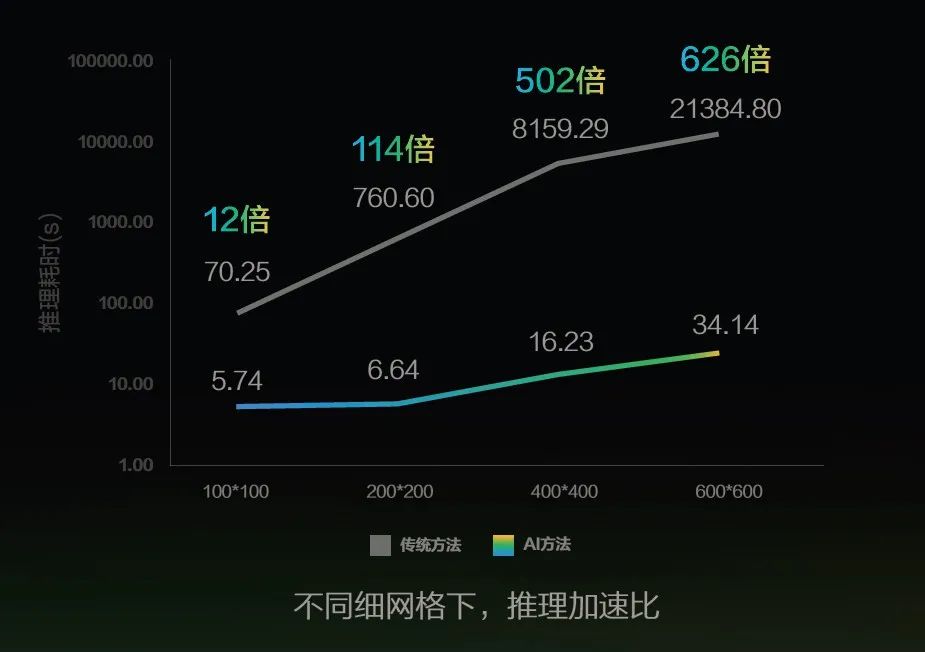
使用AI方法推理,计算量和网格点数成线性关系,复杂度优于传统算法,并且得益于算法容易并行的特性和GPU硬件算力,推理性能比传统方法可以提升12到626倍。
分布式训练能力的
最新升级
飞桨围绕统一的分布式计算图表示和集群资源表示,针对不同应用模型与硬件平台,打造全流程通用异构自适应分布式软件栈,实现不同应用场景和硬件架构高效协同训练,支持超大规模分布式训练。
端到端自适应大规模分布式训练架构
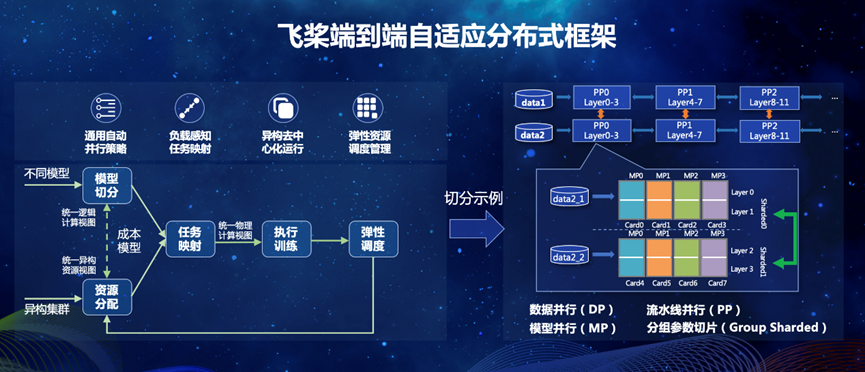
混合并行能力升级
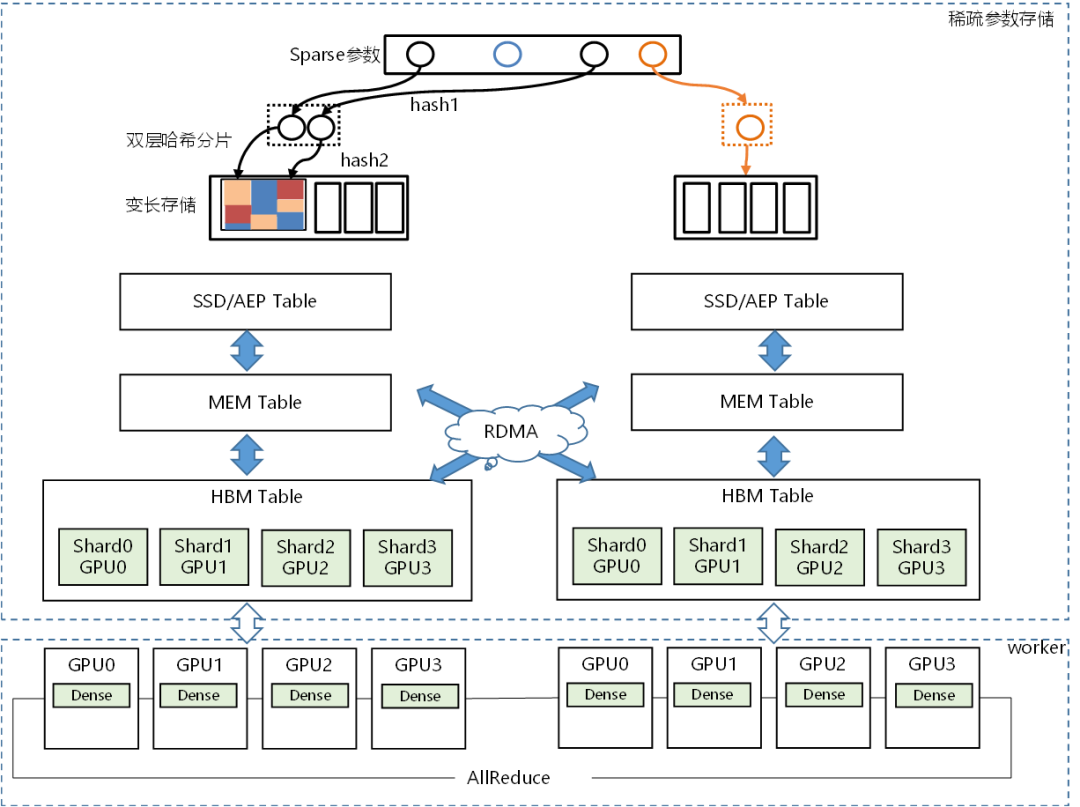
多层次、低成本的
硬件适配统一方案
随着智能芯片种类越来越复杂,深度学习框架的硬件接入成本已经成为一个显著问题,也会进而影响到新硬件的应用推广。
为此,飞桨框架v2.2推出了硬件适配的统一方案,来降低适配成本。如下图所示,该方案不仅包括基于算子Kernel接入的 Kernel Primitive API方案,还有基于子图/整图接入的 NNAdapter 方案,硬件厂商可以根据硬件特性灵活选择。

Kernel Primitive API
实现算子计算与硬件解耦
以昆仑芯第2代芯片(XPU-2)接入为例,实践证明Reduce、Elementwise、Activation这三类算子,适配代码量可减少93.4%。另外,使用 Kernel Primitive API 还实现了一处优化,多处收益的效果,仅对IO运算进行向量化访存优化,飞桨的70个算子性能就可以平均提升12.8%。您可以在这里了解关于 Kernel Primitive API 的详情。
NNAdapter 飞桨推理
AI 硬件统一适配框架
https://paddle-lite.readthedocs.io/zh/develop/develop_guides/nnadapter.html
加速文本任务全流程
飞桨框架 v2.2 通过四大特性加速了文本任务开发全流程,给开发者提供了更快更易用的开发体验。
文本预处理加速
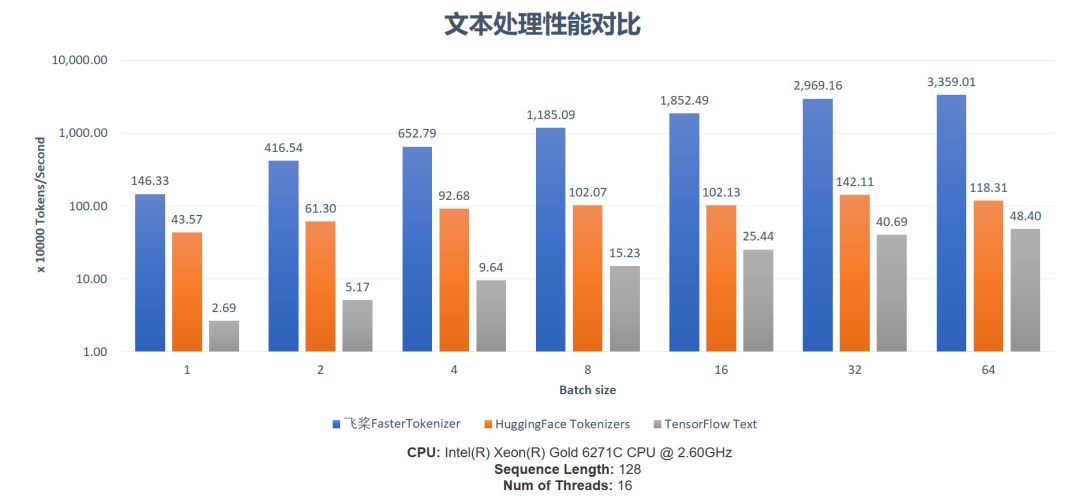
预训练任务加速
生成解码加速
训推一体部署体验
结语
关于本版本的更详细的信息,请参看v2.2.0 Release Note。飞桨提供了多种安装方式,欢迎大家登录飞桨官网(https://www.paddlepaddle.org.cn/)下载体验飞桨框架v2.2 。您也可以关注飞桨的官方网站来跟进最新进展。
https://github.com/PaddlePaddle/Paddle/releases/tag/v2.2.0
导读:12月12日,在上海举行的WAVE SUMMIT 2021深度学习开发者峰会上,飞桨深度学习开源框架2.2版本正式发布。飞桨是中国首个开源的深度学习框架,一直致力于让深度学习技术的创新与应用更简单。
API 体系支持更广泛的模型开发。
端到端自适应大规模分布式训练架构。
多层次、低成本的硬件适配统一方案。
加速文本任务全流程。
飞桨框架v2.2新增100+ API,主要包括:
17个线性代数API paddle.linalg.* :全面覆盖了矩阵计算、矩阵分解、矩阵属性计算、线性方程组求解等4大场景。
新增 paddle.einsum,支持以更加简洁的方式来表达多维张量(Tensor)的计算。
增加更多的张量(Tensor)高级索引操作,即可用省略号、布尔值、Python List、Paddle Tensor等作为索引去操作张量(Tensor),能够更加方便和灵活地去读写张量(Tensor)中的某些元素。
加强对AI科学计算功能的支持,包括支持高阶微分的 elementwise_add、elementwise_mul、matmul、sigmoid 和 tanh 等算子,支持函数式自动微分接口的Jacobian、Hessian、jvp、vjp、vhp 等函数式自动微分 API,从而可以便捷实现基于深度学习的微分方程的求解,解决例如计算流体力学中的 LDC(Lid Driven Cavity Flow)等问题。
v2.2 的函数式自动微分API和高阶微分
在计算流体力学场景上的探索
另一方面由于存在串行运算,这些方法难以使用GPU硬件进行加速。而深度学习的神经网络具备“万能逼近”能力,即只要网络有足够的神经元,就可以充分地逼近任意一个连续函数,基于神经网络去求解偏微分方程组为解决科学计算领域问题提供了新范式。
飞桨一方面通过改进框架自动微分机制和底层算子实现,支持了典型运算的高阶自动微分;另一方面,通过新增Jacobian、Hessian、jvp、vjp等API接口,增强了对偏微分方程组的表达能力。在以上两部分工作的基础上,飞桨实现了基于神经网络的偏微分方程组的求解,并在计算流体力学场景做了探索性的工作。
LDC是计算流体力学的一个经典问题,我们使用隐藏层节点数为50的10层全连接网络作为神经网络模型,在[-0.05, -0.05] 到[0.05, 0.05]的矩形区域上以100 * 100的为粒度划分网格,根据偏微分方程组和边界条件设计Loss,进行训练以实现对偏微分方程组的求解,从而正确模拟出了腔体内水平方向和垂直方向上的液体流速分布,与基于OpenFOAM软件实现的传统方法结果均方误差在1e-4数量级。
各网格粒度下推理结果与传统方法的均方误差均在1e-4数量级,这说明了AI方法拥有在粗网格上训练,在更细网格上推理的泛化能力。
使用AI方法推理,计算量和网格点数成线性关系,复杂度优于传统算法,并且得益于算法容易并行的特性和GPU硬件算力,推理性能比传统方法可以提升12到626倍。
分布式训练能力的
最新升级
飞桨围绕统一的分布式计算图表示和集群资源表示,针对不同应用模型与硬件平台,打造全流程通用异构自适应分布式软件栈,实现不同应用场景和硬件架构高效协同训练,支持超大规模分布式训练。
端到端自适应大规模分布式训练架构
混合并行能力升级
多层次、低成本的
硬件适配统一方案
随着智能芯片种类越来越复杂,深度学习框架的硬件接入成本已经成为一个显著问题,也会进而影响到新硬件的应用推广。
为此,飞桨框架v2.2推出了硬件适配的统一方案,来降低适配成本。如下图所示,该方案不仅包括基于算子Kernel接入的 Kernel Primitive API方案,还有基于子图/整图接入的 NNAdapter 方案,硬件厂商可以根据硬件特性灵活选择。
Kernel Primitive API
实现算子计算与硬件解耦
以昆仑芯第2代芯片(XPU-2)接入为例,实践证明Reduce、Elementwise、Activation这三类算子,适配代码量可减少93.4%。另外,使用 Kernel Primitive API 还实现了一处优化,多处收益的效果,仅对IO运算进行向量化访存优化,飞桨的70个算子性能就可以平均提升12.8%。您可以在这里了解关于 Kernel Primitive API 的详情。
NNAdapter 飞桨推理
AI 硬件统一适配框架
https://paddle-lite.readthedocs.io/zh/develop/develop_guides/nnadapter.html
加速文本任务全流程
飞桨框架 v2.2 通过四大特性加速了文本任务开发全流程,给开发者提供了更快更易用的开发体验。
文本预处理加速
预训练任务加速
生成解码加速
训推一体部署体验
结语
关于本版本的更详细的信息,请参看v2.2.0 Release Note。飞桨提供了多种安装方式,欢迎大家登录飞桨官网(https://www.paddlepaddle.org.cn/)下载体验飞桨框架v2.2 。您也可以关注飞桨的官方网站来跟进最新进展。
https://github.com/PaddlePaddle/Paddle/releases/tag/v2.2.0