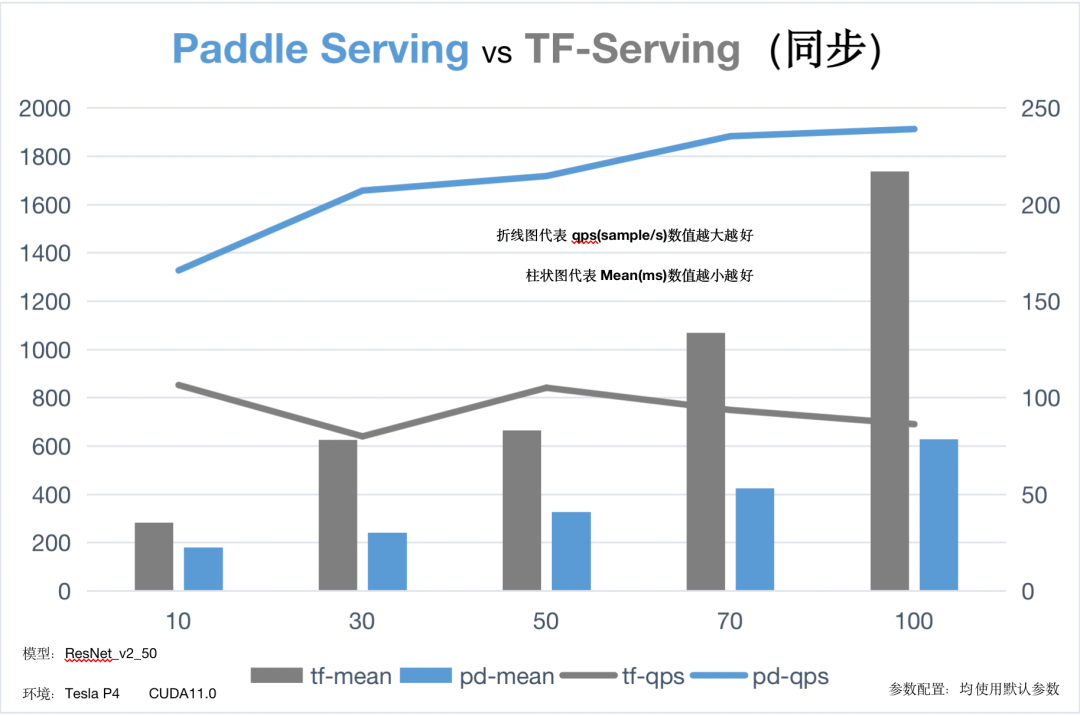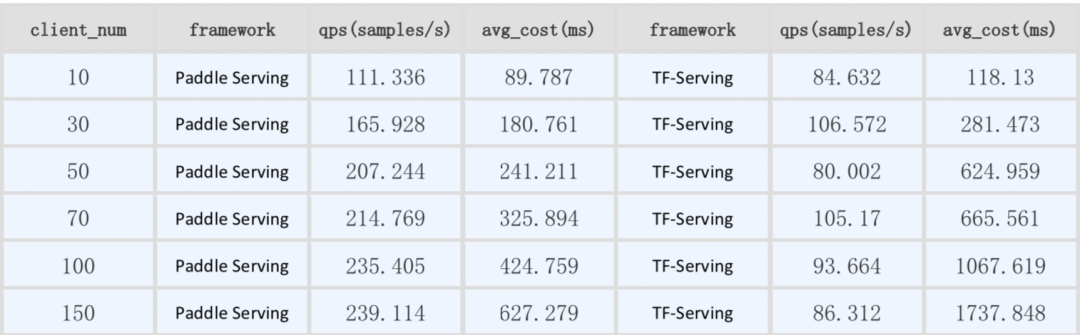
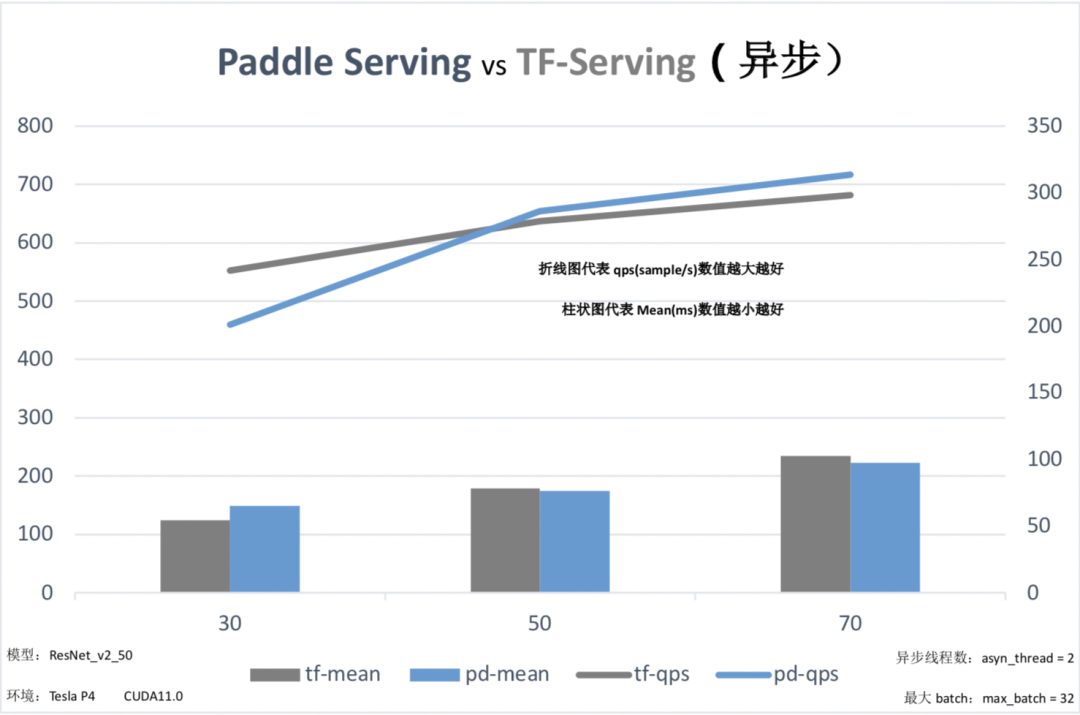
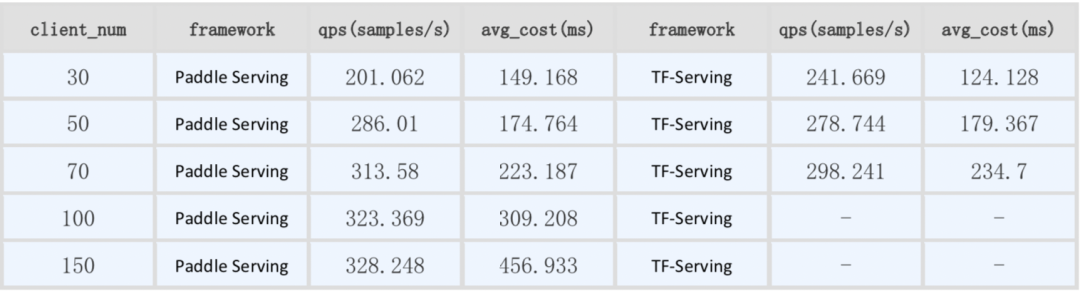
从上述性能测试对比数据中我们可以看出,与竞品相比,v0.7.0版本的C++ Serving在同步模式下全面领先竞品,异步模式在高并发时性能也优于竞品,那么是如何做到的呢?
使用内存池
提升资源获取/释放速度
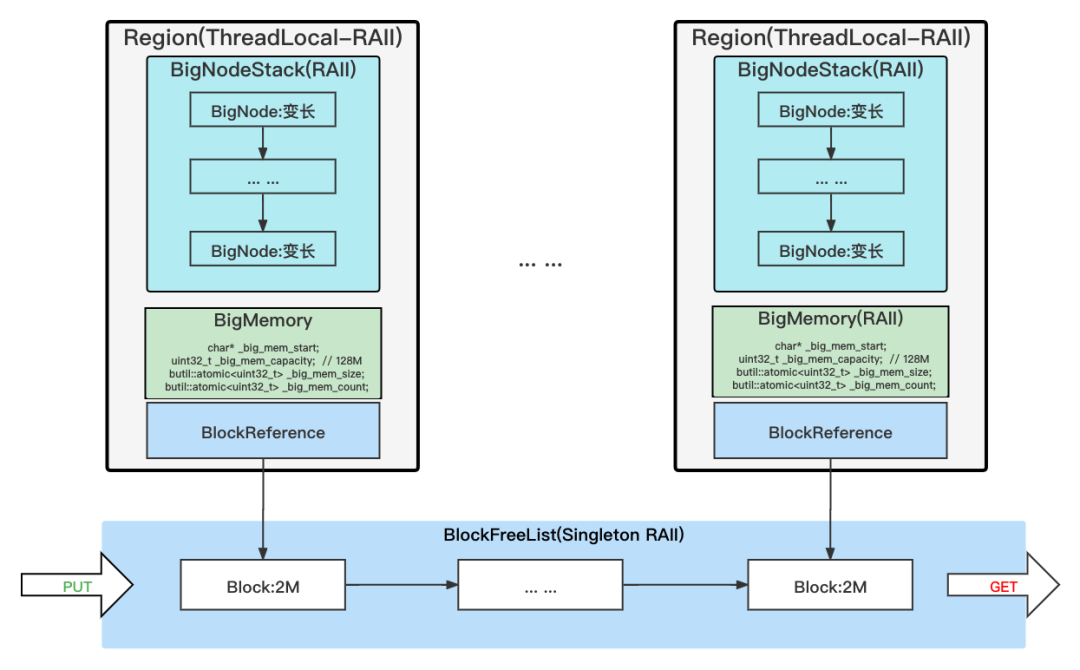
尽可能的无锁以节省性能开销
C++语言常使用多线程来处理服务中并发的问题,这就必然引入了线程安全的问题,常见的做法是加锁。加锁确实能保证线程安全,但加锁也必然带来了一定的性能开销。我们采取以下三种策略在保证线程安全的同时,尽可能地节省性能开销,提升框架的处理速度:
THREAD_KEY_CREATE(&_bspec_key, NULL)//创建线程局部变量key
THREAD_SETSPECIFIC(_bspec_key, mempool_region)//设置线程局部变量
MempoolRegion* mempool_region =(MempoolRegion*)THREAD_GETSPECIFIC(_bspec_key);//获取线程局部变量对于线程间资源的共享,尽可能的使用原子量这种无锁的设计来实现,避免频繁加锁导致的性能开销。
_big_mem_count.fetch_add(1, butil::memory_order_relaxed);//使用原子量代替锁
对于不得不加锁的地方,我们使用了双检锁来避免加锁粒度过大导致的性能开销。
if (!fetch_init) {//第一次检查fetch_init,当为false时,才会进入内部;否则表示已经完成了初始化。
AutoMutex lock(task_mut);//只有第一次检查fetch_init为false时,才可能加锁,减小锁的粒度。
if (!fetch_init) {//加锁后第二次检查fetch_init,当为false时,进入内部初始化;否则,离开作用域锁自动释放。
... ...
fetch_init = true;
}
}
更快的通信框架
C++ Serving框架使用BRPC作为通信框架。关于BRPC与GRPC的性能对比网上比比皆是,虽然得到的测试数值不尽相同,但基本上有一个确定的结论是BRPC无论在大数据量还是小数据量情况下的性能均优于GRPC。原因主要在于以下两个方面:
通信协议层面而言,BRPC是基于TCP协议的封装,而GRPC是基于HTTP2协议的封装,其中HTTP2协议又是基于TCP协议的封装。可以看出就协议层面来讲,BRPC协议比GRPC协议更轻量。
BRPC框架的Server端具有更轻量级的线程调度模型、更高效的内存管理等优点。
基于以上原因,BRPC可以为C++ Serving带来更高效的通信速度。
更好用
新增异步模式
v0.7.0版本的C++ Serving框架支持同步和异步两种模式。同步模式比较简单直接,适用于模型推理时间短,单个Request请求的Batch已经比较大的情况。
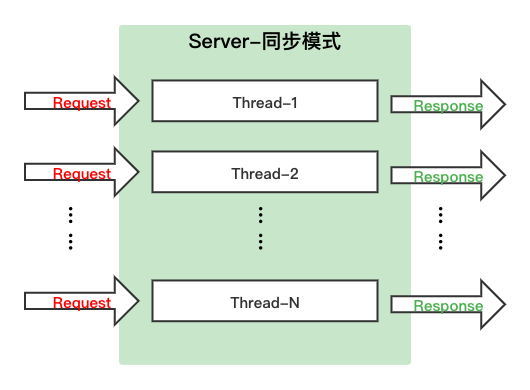

异步模式的主要特点是框架会对多个Request中的数据自动合并Batch,主要适用于模型支持多Batch(最大Batch数M可通过配置选项指定),单个Request请求的Batch较小(Batch << M),单次推理时间较长的情况。
异步模式下,Server端N个线程只负责接收Request请求,实际调用推理引擎是在异步框架的线程中,其中异步框架的线程数可以由配置选项来指定。为了方便理解,我们假设每个Request请求的Batch均为1,此时异步框架会尽可能多的从请求池中取n(n≤M)个Request并将其拼装为1个Request(Batch=n),调用1次推理引擎,得到1个Response(Batch = n),再将其对应拆分为n个Response作为返回结果。这样合并Batch后仅调用一次推理引擎的做法,由于避免了n个Request重复n次调用推理引擎的耗时,可以使整体效率大幅度提升,资源利用率更高。详细的参数设置及使用方法见Github主页:https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/C++_Serving/Performance_Tuning_CN.md
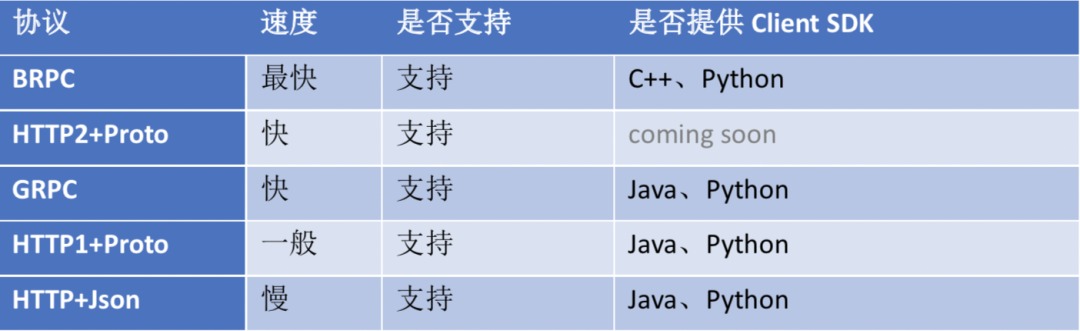
多语言多协议Client
v0.7.0版本C++ Serving框架Server端能够支持Client端多种协议的请求访问,具体情况如下表所示。各种Client端通信协议的相关使用方法和示例请参见:https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/C++_Serving/Introduction_CN.md
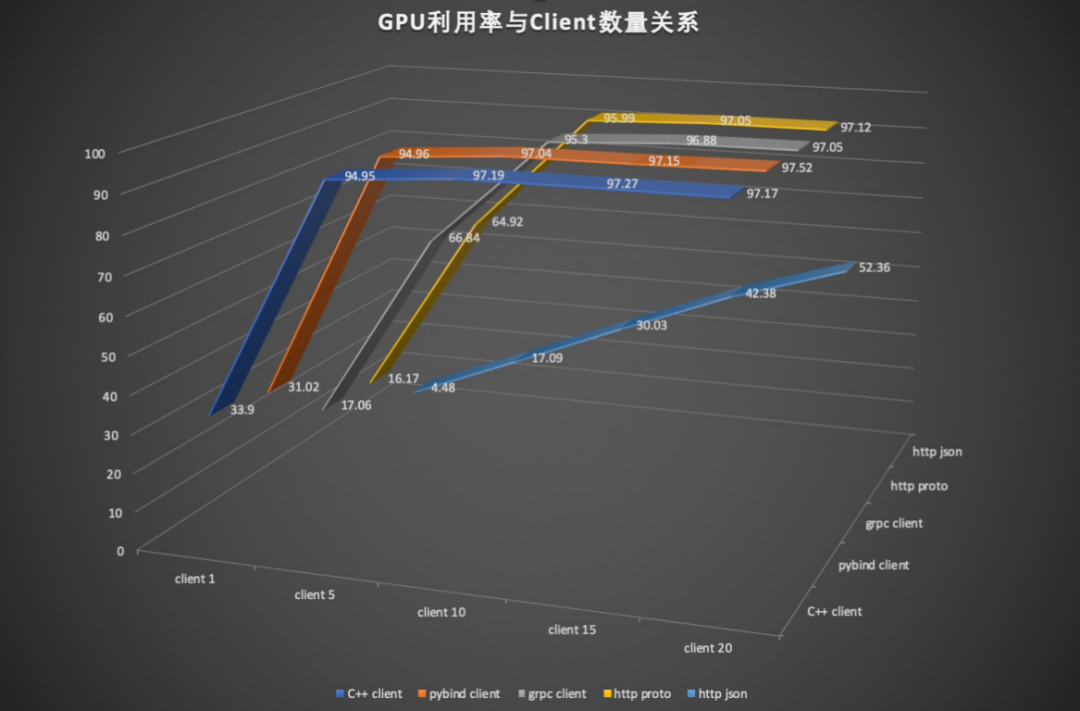
其中,针对C++BRPC、Pybind-BRPC、GRPC、HTTP1+Proto、HTTP+Json五种方式,我们做了一组测试来检验GPU利用率与Client端的通信协议的关系,测试结果如下图所示,其中GPU利用率越快打满,表示对应的通信协议的传输效率越高,测试结果与上表中各种通信协议的特性基本相符,用户可根据对语言、协议、速度等的要求自由选择。
支持低精度推理
在精度要求不高的场景中,使用半精度和单精度可以有效降低内存(显存)占用,在硬件上可大幅提升计算吞吐量。本次Paddle Serving v0.7.0新增了对低精度推理的支持,包括半精度(FP16)和量化(INT8)推理。Paddle Serving用户可通过设置服务启动参数开启低精度推理;与此同时,低精度与Intel MKLDNN或Nvidia TensorRT同时开启,可获得更大的计算收益。开启低精度的使用方法见链接:https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/Serving_Configure_CN.md
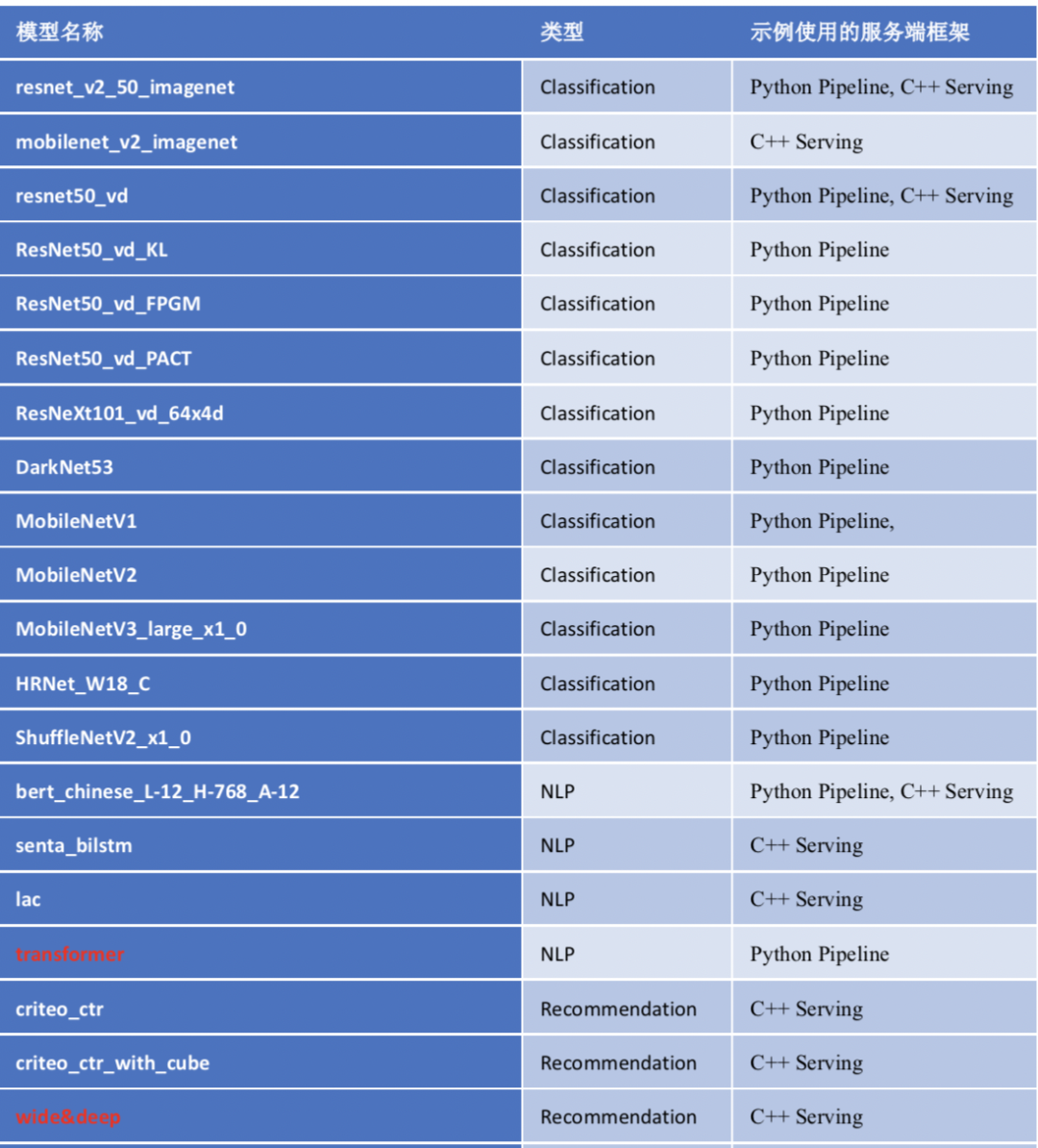
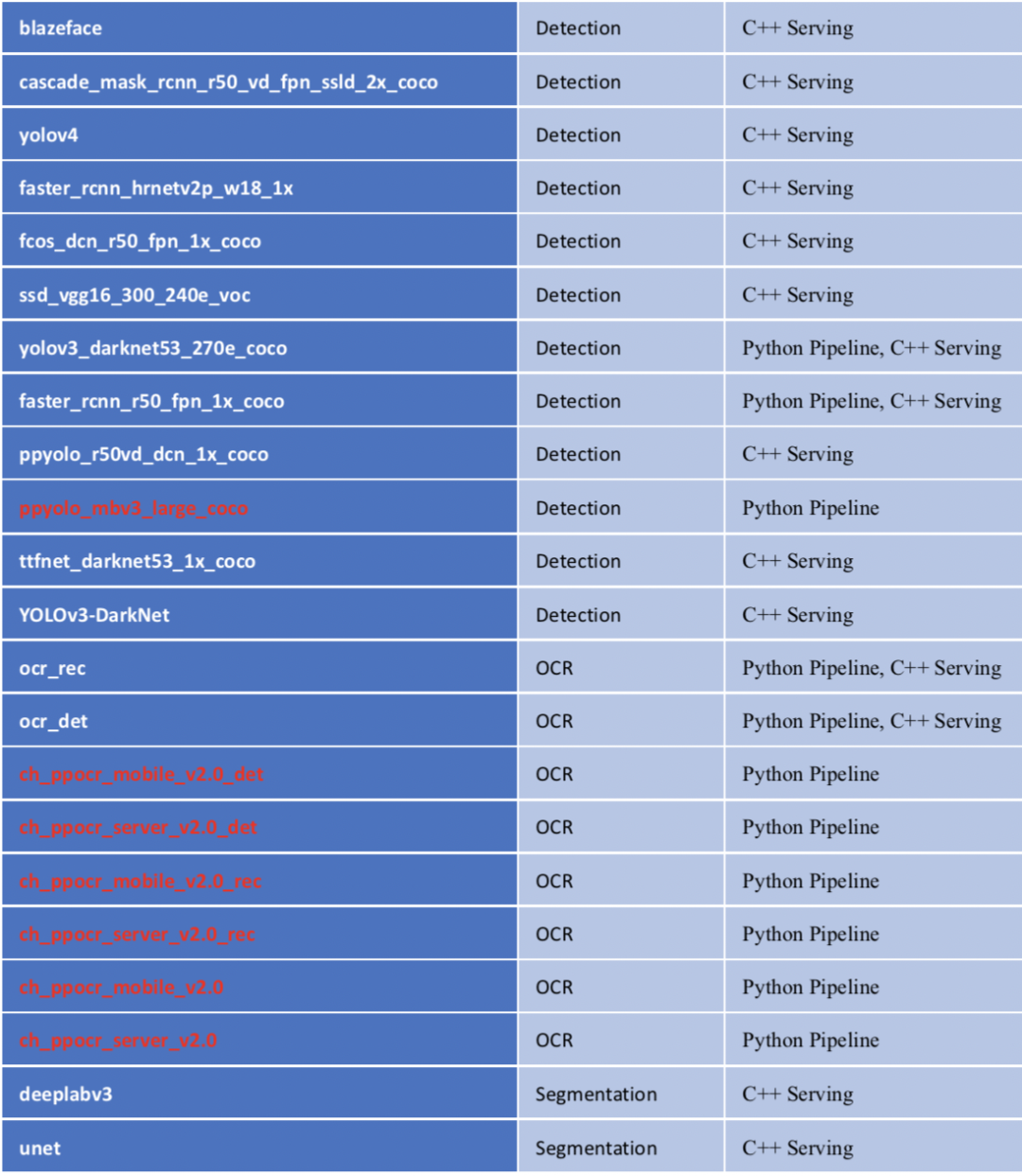
更多模型
更便捷
docker run --rm -dit --name pipeline_serving_demo paddle_serving:cuda10.2-py36 bash
cd Serving/python/example/pipeline/ocr
# get models
python -m paddle_serving_app.package --get_model ocr_rec
tar -xzvf ocr_rec.tar.gz
python -m paddle_serving_app.package --get_model ocr_det
tar -xzvf ocr_det.tar.gz
cd ..
docker cp ocr pipeline_serving_demo:/home/
docker commit pipeline_serving_demo ocr_serving:latest
kubectl apply -f k8s_serving.yaml
更多详细细节和使用示例见:
https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/Run_On_Kubernetes_CN.md
更安全
此外,安全网关还可以同模型加密结合使用,安全网关在访问层面对流量加密和控制,确保原始模型不被窃取的同时仅为有权限的合法请求提供服务。更多详细介绍和使用示例见:
https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/Serving_Auth_Docker_CN.md
助力企业案例
58同城某业务部门真实案例
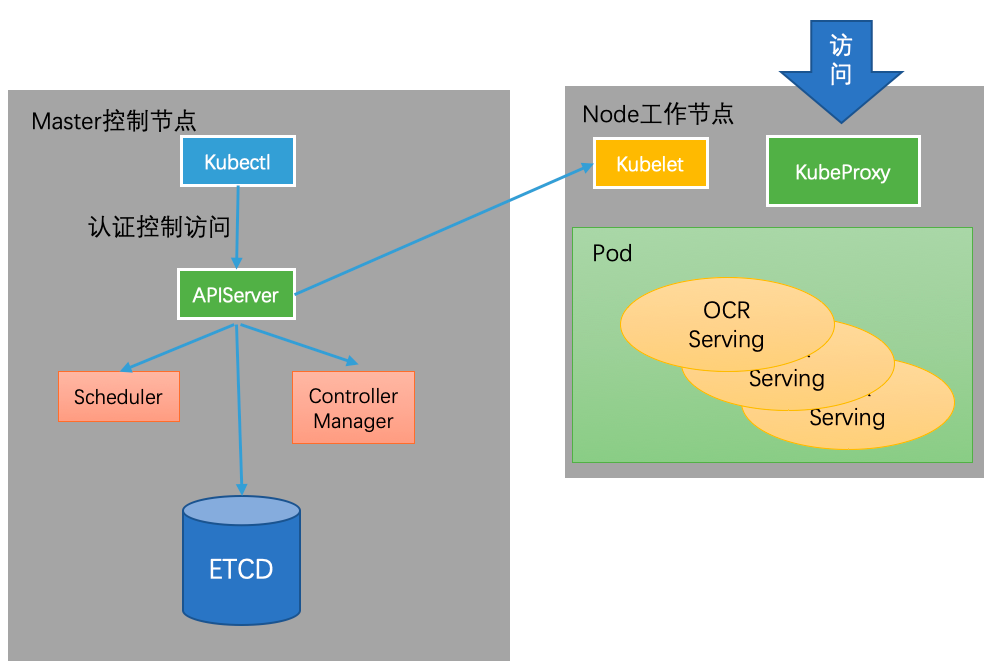
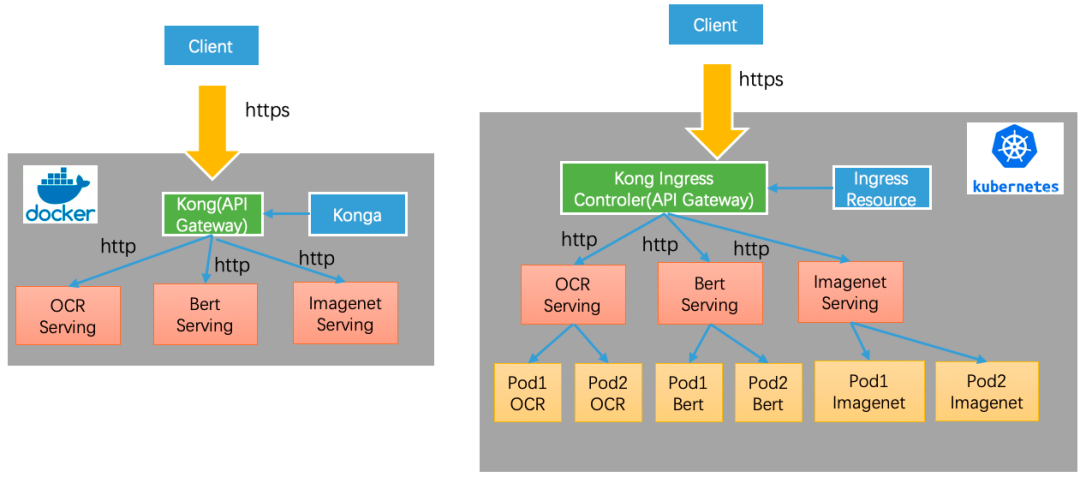
58同城某业务部门线上部署OCR模型对外提供服务。使用Paddle Serving v0.6.0版本部署,服务的访问形式如下图左侧所示,此时来自Java Client的请求需要经过三次转发才能真正到达Server端执行推理预测。
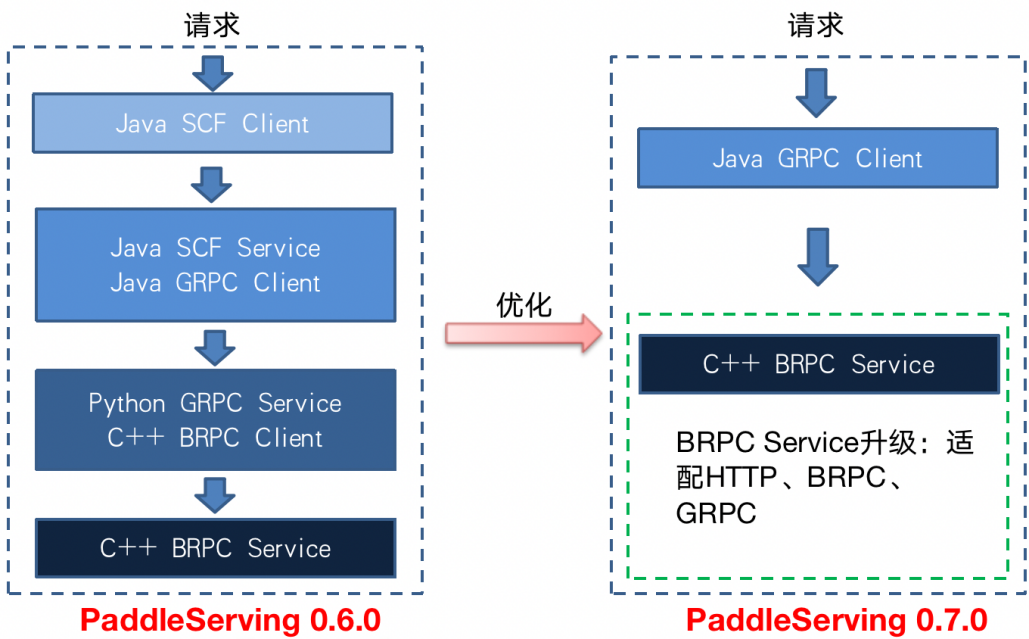
使用Paddle Serving v0.7.0版本只需部署一个Server端即可同时支持HTTP/GRPC/BRPC三种协议,且v0.7.0版本提供了Java/Python/C++三种语言的Client SDK,优化后的服务访问形式如下图右侧所示,此时来自Java Client的请求直接发送给Server端执行推理预测。
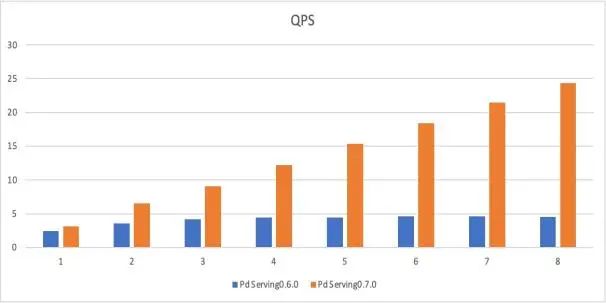
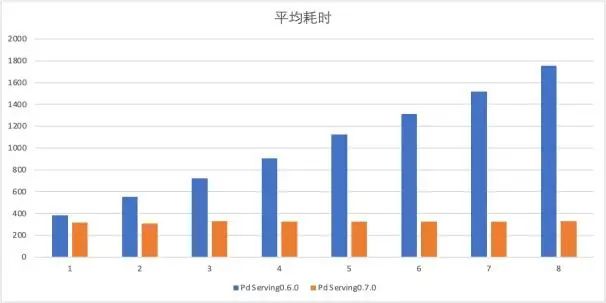
伴随着服务结构的优化,线上服务性能获得提升也是必然的。下图为服务升级前后的性能对比,升级后线上服务的QPS显著提升,平均耗时大幅度下降,取得了不错的效果。
天覆科技使用Paddle Serving
安全网关的真实案例
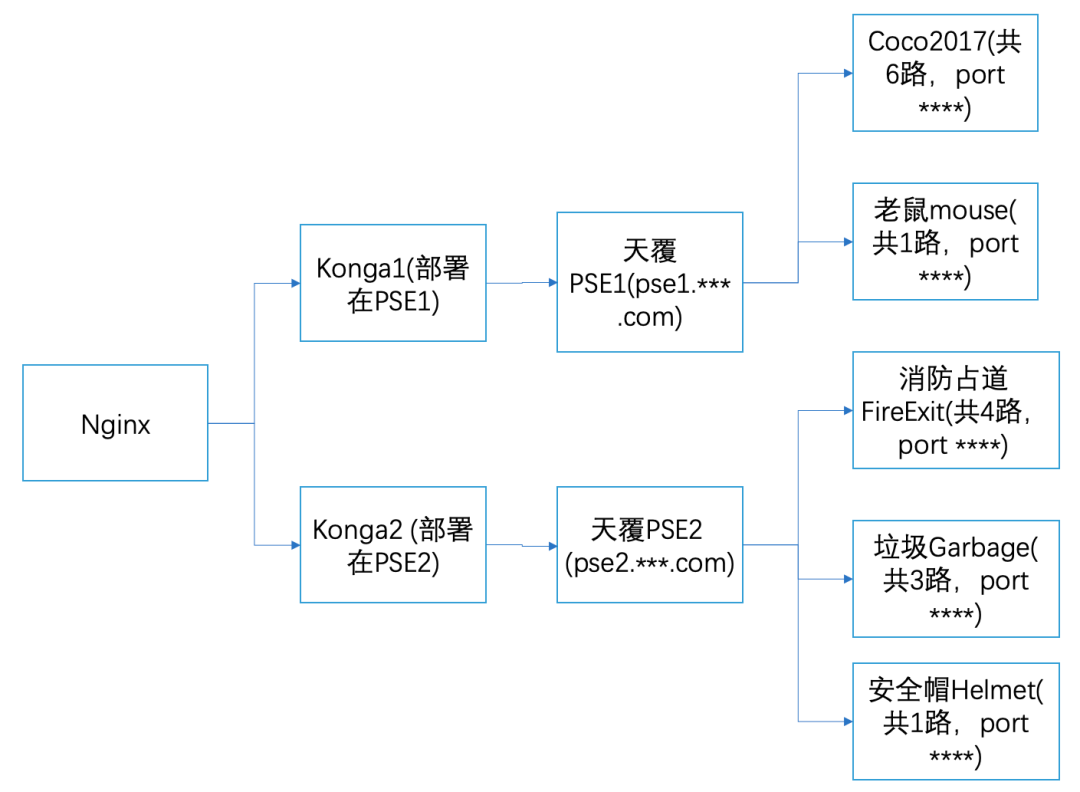
天覆科技在安防领域的主要业务是部署各个图像处理领域的深度学习模型,下图是节选的数据流图,在真实的业务场景中,边缘端(包含X86和ARM的平台)部署了多种不同的深度学习图像处理领域的模型来提供线上服务。
总结
从上述性能测试对比数据中我们可以看出,与竞品相比,v0.7.0版本的C++ Serving在同步模式下全面领先竞品,异步模式在高并发时性能也优于竞品,那么是如何做到的呢?
使用内存池
提升资源获取/释放速度
尽可能的无锁以节省性能开销
C++语言常使用多线程来处理服务中并发的问题,这就必然引入了线程安全的问题,常见的做法是加锁。加锁确实能保证线程安全,但加锁也必然带来了一定的性能开销。我们采取以下三种策略在保证线程安全的同时,尽可能地节省性能开销,提升框架的处理速度:
THREAD_KEY_CREATE(&_bspec_key, NULL)//创建线程局部变量key
THREAD_SETSPECIFIC(_bspec_key, mempool_region)//设置线程局部变量
MempoolRegion* mempool_region =(MempoolRegion*)THREAD_GETSPECIFIC(_bspec_key);//获取线程局部变量对于线程间资源的共享,尽可能的使用原子量这种无锁的设计来实现,避免频繁加锁导致的性能开销。
_big_mem_count.fetch_add(1, butil::memory_order_relaxed);//使用原子量代替锁
对于不得不加锁的地方,我们使用了双检锁来避免加锁粒度过大导致的性能开销。
if (!fetch_init) {//第一次检查fetch_init,当为false时,才会进入内部;否则表示已经完成了初始化。
AutoMutex lock(task_mut);//只有第一次检查fetch_init为false时,才可能加锁,减小锁的粒度。
if (!fetch_init) {//加锁后第二次检查fetch_init,当为false时,进入内部初始化;否则,离开作用域锁自动释放。
... ...
fetch_init = true;
}
}
更快的通信框架
C++ Serving框架使用BRPC作为通信框架。关于BRPC与GRPC的性能对比网上比比皆是,虽然得到的测试数值不尽相同,但基本上有一个确定的结论是BRPC无论在大数据量还是小数据量情况下的性能均优于GRPC。原因主要在于以下两个方面:
通信协议层面而言,BRPC是基于TCP协议的封装,而GRPC是基于HTTP2协议的封装,其中HTTP2协议又是基于TCP协议的封装。可以看出就协议层面来讲,BRPC协议比GRPC协议更轻量。
BRPC框架的Server端具有更轻量级的线程调度模型、更高效的内存管理等优点。
基于以上原因,BRPC可以为C++ Serving带来更高效的通信速度。
更好用
新增异步模式
v0.7.0版本的C++ Serving框架支持同步和异步两种模式。同步模式比较简单直接,适用于模型推理时间短,单个Request请求的Batch已经比较大的情况。
异步模式的主要特点是框架会对多个Request中的数据自动合并Batch,主要适用于模型支持多Batch(最大Batch数M可通过配置选项指定),单个Request请求的Batch较小(Batch << M),单次推理时间较长的情况。
异步模式下,Server端N个线程只负责接收Request请求,实际调用推理引擎是在异步框架的线程中,其中异步框架的线程数可以由配置选项来指定。为了方便理解,我们假设每个Request请求的Batch均为1,此时异步框架会尽可能多的从请求池中取n(n≤M)个Request并将其拼装为1个Request(Batch=n),调用1次推理引擎,得到1个Response(Batch = n),再将其对应拆分为n个Response作为返回结果。这样合并Batch后仅调用一次推理引擎的做法,由于避免了n个Request重复n次调用推理引擎的耗时,可以使整体效率大幅度提升,资源利用率更高。详细的参数设置及使用方法见Github主页:https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/C++_Serving/Performance_Tuning_CN.md
多语言多协议Client
v0.7.0版本C++ Serving框架Server端能够支持Client端多种协议的请求访问,具体情况如下表所示。各种Client端通信协议的相关使用方法和示例请参见:https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/C++_Serving/Introduction_CN.md
其中,针对C++BRPC、Pybind-BRPC、GRPC、HTTP1+Proto、HTTP+Json五种方式,我们做了一组测试来检验GPU利用率与Client端的通信协议的关系,测试结果如下图所示,其中GPU利用率越快打满,表示对应的通信协议的传输效率越高,测试结果与上表中各种通信协议的特性基本相符,用户可根据对语言、协议、速度等的要求自由选择。
支持低精度推理
在精度要求不高的场景中,使用半精度和单精度可以有效降低内存(显存)占用,在硬件上可大幅提升计算吞吐量。本次Paddle Serving v0.7.0新增了对低精度推理的支持,包括半精度(FP16)和量化(INT8)推理。Paddle Serving用户可通过设置服务启动参数开启低精度推理;与此同时,低精度与Intel MKLDNN或Nvidia TensorRT同时开启,可获得更大的计算收益。开启低精度的使用方法见链接:https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/Serving_Configure_CN.md
更多模型
更便捷
docker run --rm -dit --name pipeline_serving_demo paddle_serving:cuda10.2-py36 bash
cd Serving/python/example/pipeline/ocr
# get models
python -m paddle_serving_app.package --get_model ocr_rec
tar -xzvf ocr_rec.tar.gz
python -m paddle_serving_app.package --get_model ocr_det
tar -xzvf ocr_det.tar.gz
cd ..
docker cp ocr pipeline_serving_demo:/home/
docker commit pipeline_serving_demo ocr_serving:latest
kubectl apply -f k8s_serving.yaml
更多详细细节和使用示例见:
https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/Run_On_Kubernetes_CN.md
更安全
此外,安全网关还可以同模型加密结合使用,安全网关在访问层面对流量加密和控制,确保原始模型不被窃取的同时仅为有权限的合法请求提供服务。更多详细介绍和使用示例见:
https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/Serving_Auth_Docker_CN.md
助力企业案例
58同城某业务部门真实案例
58同城某业务部门线上部署OCR模型对外提供服务。使用Paddle Serving v0.6.0版本部署,服务的访问形式如下图左侧所示,此时来自Java Client的请求需要经过三次转发才能真正到达Server端执行推理预测。
使用Paddle Serving v0.7.0版本只需部署一个Server端即可同时支持HTTP/GRPC/BRPC三种协议,且v0.7.0版本提供了Java/Python/C++三种语言的Client SDK,优化后的服务访问形式如下图右侧所示,此时来自Java Client的请求直接发送给Server端执行推理预测。
伴随着服务结构的优化,线上服务性能获得提升也是必然的。下图为服务升级前后的性能对比,升级后线上服务的QPS显著提升,平均耗时大幅度下降,取得了不错的效果。
天覆科技使用Paddle Serving
安全网关的真实案例
天覆科技在安防领域的主要业务是部署各个图像处理领域的深度学习模型,下图是节选的数据流图,在真实的业务场景中,边缘端(包含X86和ARM的平台)部署了多种不同的深度学习图像处理领域的模型来提供线上服务。
总结