传统人工处理的局限性
传统机器学习建模的局限性
业务理解
技术抽象
文本分类任务:基于故障描述文本,判断故障的类别或定位对应的检修专业部门。
文本生成任务:基于故障描述文本,生成维护建议。
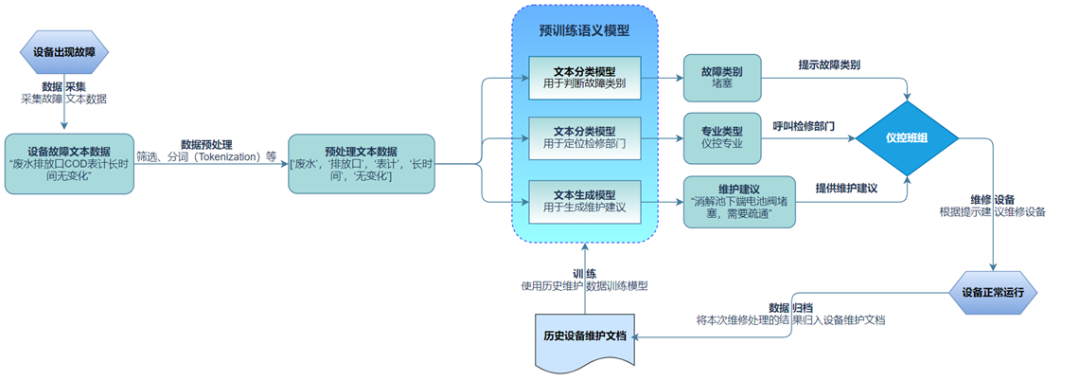
技术选型
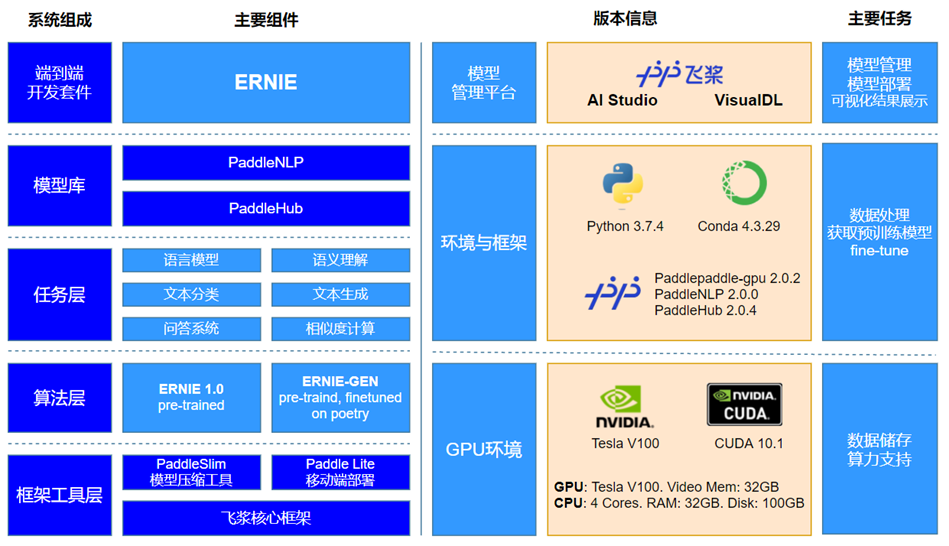
import paddlehub as hub
import paddle
model = hub.Module(name='ernie', task='seq-cls', num_classes=len(MyDataset.label_list))
数据处理
基本预处理
├──mydata: 数据目录
├── train.txt: 训练集数据
├── dev.txt: 验证集数据
└── test.txt: 测试集数据
label text_a
锅炉专业 捞渣机液压张紧油站处地沟堵塞
脱硫专业 脱硫冷却水至机喷淋装置进口电动阀54%处卡涩,无法关闭。
电气专业 网源协调分析装置屏柜内部分端口未禁用
from paddlehub.datasets.base_nlp_dataset import TextClassificationDataset
class MyDataset(TextClassificationDataset):
# 数据集存放目录
base_path = '/home/aistudio/data/' + dataID
# 数据集的标签列表
f = open(base_path + '/label_list.txt', 'r')
label_list = f.read().strip().split('\t')
f.close()
def __init__(self, tokenizer, max_seq_len: int = 128, mode: str = 'train'):
if mode == 'train':
data_file = 'train.txt'
elif mode == 'test':
data_file = 'test.txt'
else:
data_file = 'dev.txt'
super().__init__(
base_path=self.base_path,
tokenizer=tokenizer,
max_seq_len=max_seq_len,
mode=mode,
data_file=data_file,
label_list=self.label_list,
is_file_with_header=True)
类别均衡
对于分类任务,数据存在部分类别样本量过少,各类别数据不均衡的问题。针对此问题,采用下列三种方法尝试解决:
def random_deletion(words, p):
if len(words) == 1:
return words
new_words = []
for word in words:
r = random.uniform(0, 1)
if r > p:
new_words.append(word)
if len(new_words) == 0:
rand_int = random.randint(0, len(words)-1)
return [words[rand_int]]
return new_words
训练策略
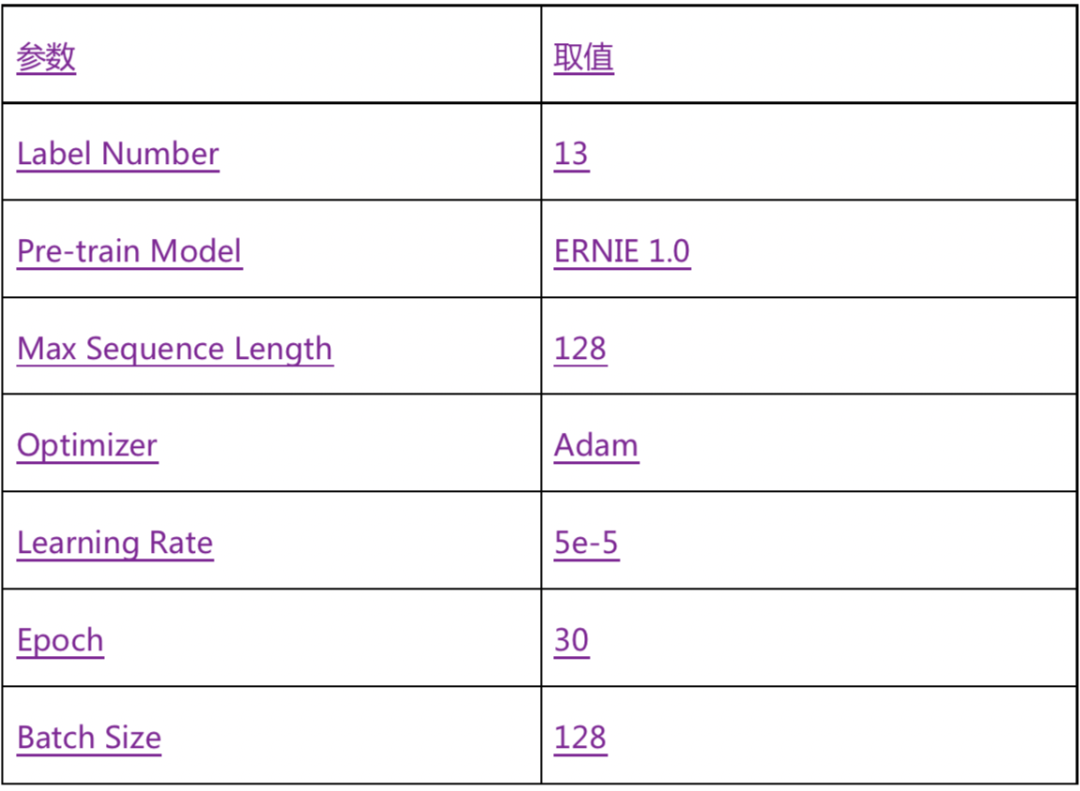
文本分类任务
optimizer = paddle.optimizer.Adam(learning_rate=5e-5, parameters=model.parameters()) # 优化器的选择和参数配置
trainer = hub.Trainer(model, optimizer, checkpoint_dir='./ckpt', use_gpu=True) # fine-tune任务的执行者
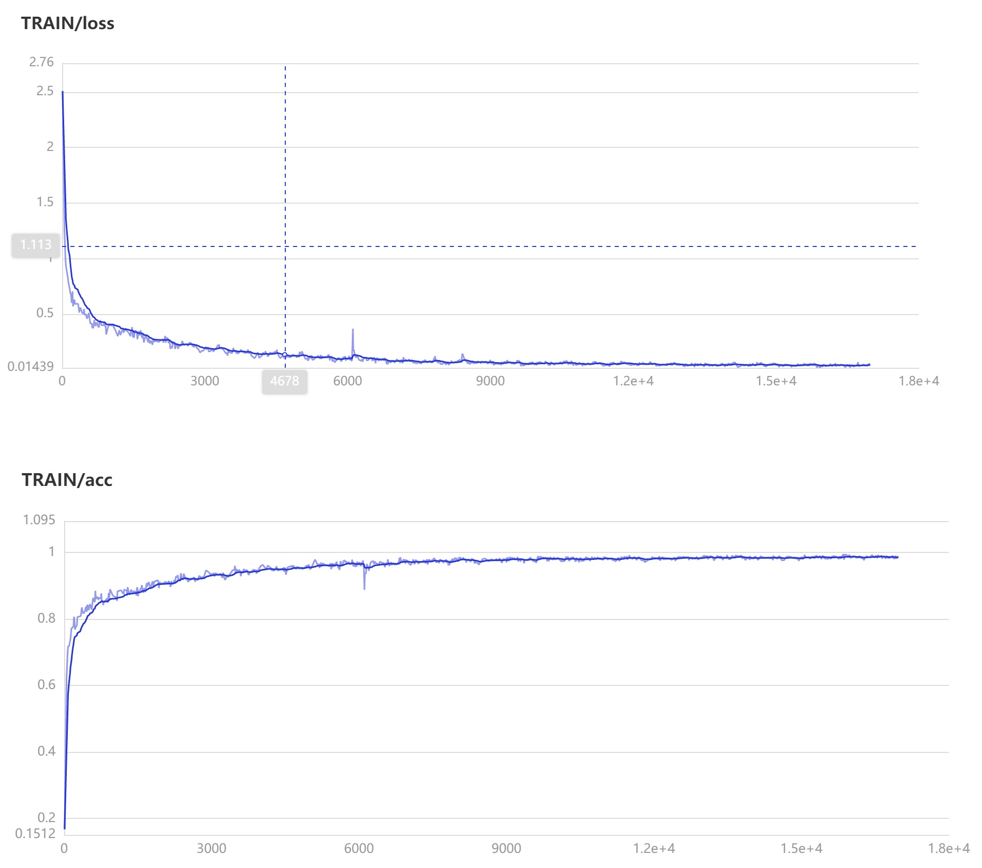
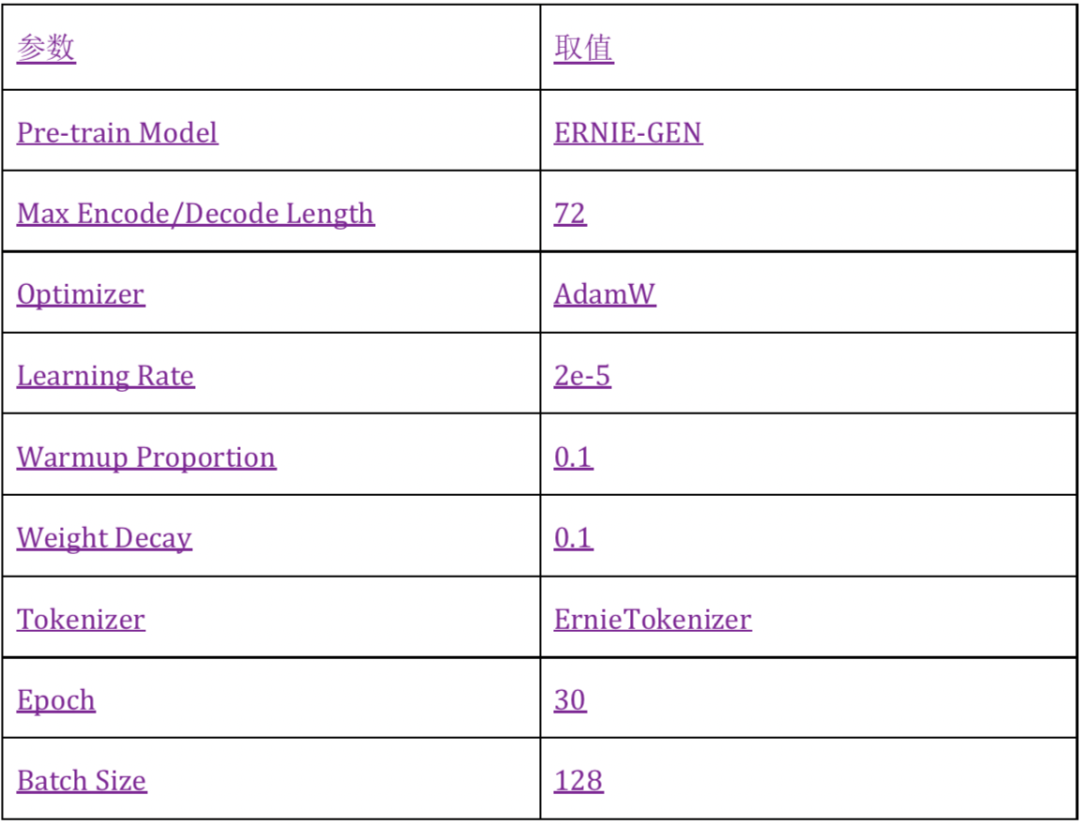
文本生成任务
使用预热学习(Warmup)与学习率衰减(Decay)结合的策略,即设置学习率先升后降的方法进行训练:


import paddle.nn as nn
num_epochs = 30
learning_rate = 2e-5
warmup_proportion = 0.1
weight_decay = 0.1
max_steps = (len(train_data_loader) * num_epochs)
lr_scheduler = paddle.optimizer.lr.LambdaDecay(
learning_rate,
lambda current_step, num_warmup_steps=max_steps*warmup_proportion, num_training_steps=max_steps: float(current_step) / float(max(1, num_warmup_steps))
if current_step < num_warmup_steps else max(0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps))))
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
grad_clip=nn.ClipGradByGlobalNorm(1.0),
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
import os
import time
from paddlenlp.utils.log import logger
global_step = 1
logging_steps = 100
save_steps = 1000
output_dir = "output_model"
tic_train = time.time()
for epoch in range(num_epochs):
for step, batch in enumerate(train_data_loader, start=1):
(src_ids, src_sids, src_pids, tgt_ids, tgt_sids, tgt_pids, attn_ids,
mask_src_2_src, mask_tgt_2_srctgt, mask_attn_2_srctgtattn,
tgt_labels, _) = batch
# import pdb; pdb.set_trace()
_, __, info = model(
src_ids,
sent_ids=src_sids,
pos_ids=src_pids,
attn_bias=mask_src_2_src,
encode_only=True)
cached_k, cached_v = info['caches']
_, __, info = model(
tgt_ids,
sent_ids=tgt_sids,
pos_ids=tgt_pids,
attn_bias=mask_tgt_2_srctgt,
past_cache=(cached_k, cached_v),
encode_only=True)
cached_k2, cached_v2 = info['caches']
past_cache_k = [
paddle.concat([k, k2], 1) for k, k2 in zip(cached_k, cached_k2)
]
past_cache_v = [
paddle.concat([v, v2], 1) for v, v2 in zip(cached_v, cached_v2)
]
loss, _, __ = model(
attn_ids,
sent_ids=tgt_sids,
pos_ids=tgt_pids,
attn_bias=mask_attn_2_srctgtattn,
past_cache=(past_cache_k, past_cache_v),
tgt_labels=tgt_labels,
tgt_pos=paddle.nonzero(attn_ids == attn_id))
if global_step % logging_steps == 0:
logger.info(
"global step %d, epoch: %d, batch: %d, loss: %f, speed: %.2f step/s, lr: %.3e"
% (global_step, epoch, step, loss, logging_steps /
(time.time() - tic_train), lr_scheduler.get_lr()))
tic_train = time.time()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_gradients()
if global_step % save_steps == 0:
model_dir = os.path.join(output_dir,
"model_%d" % global_step)
if not os.path.exists(model_dir):
os.makedirs(model_dir)
model.save_pretrained(model_dir)
tokenizer.save_pretrained(model_dir)
global_step += 1项目成果
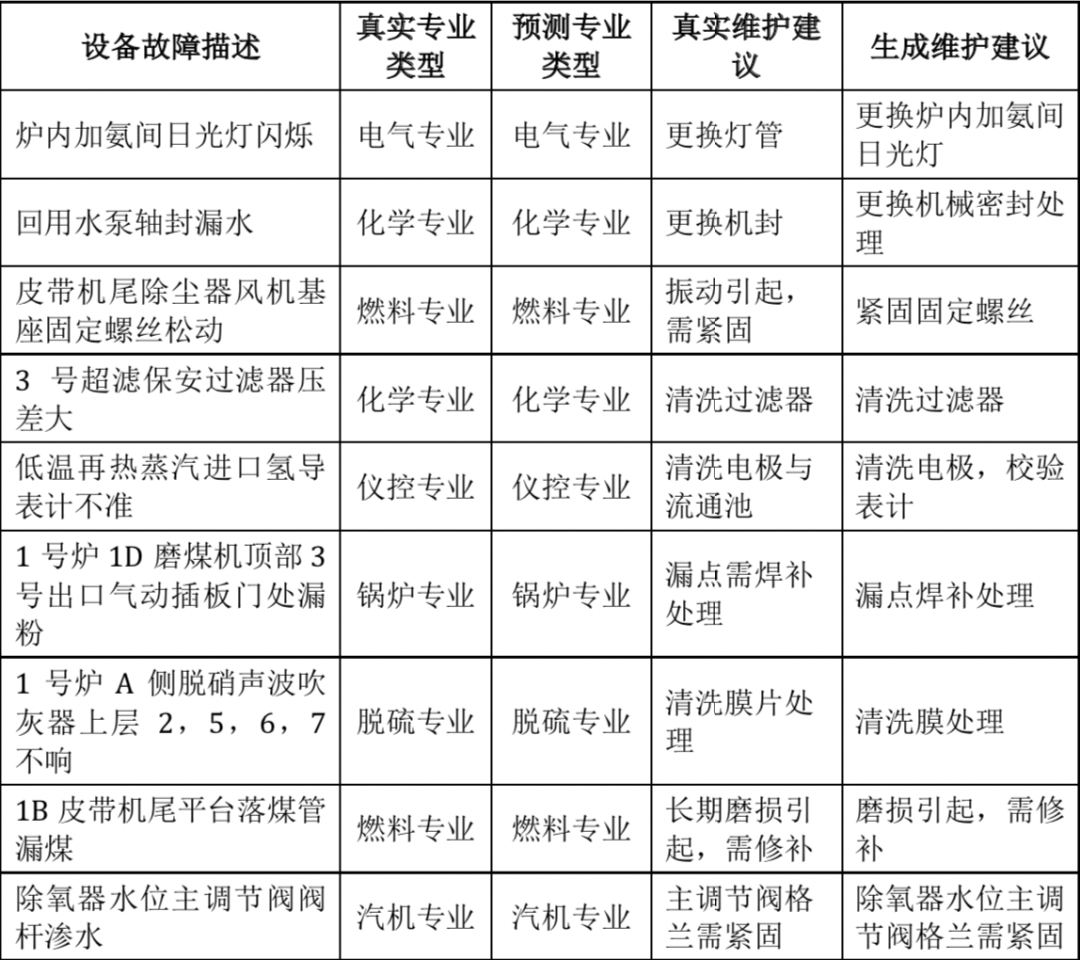
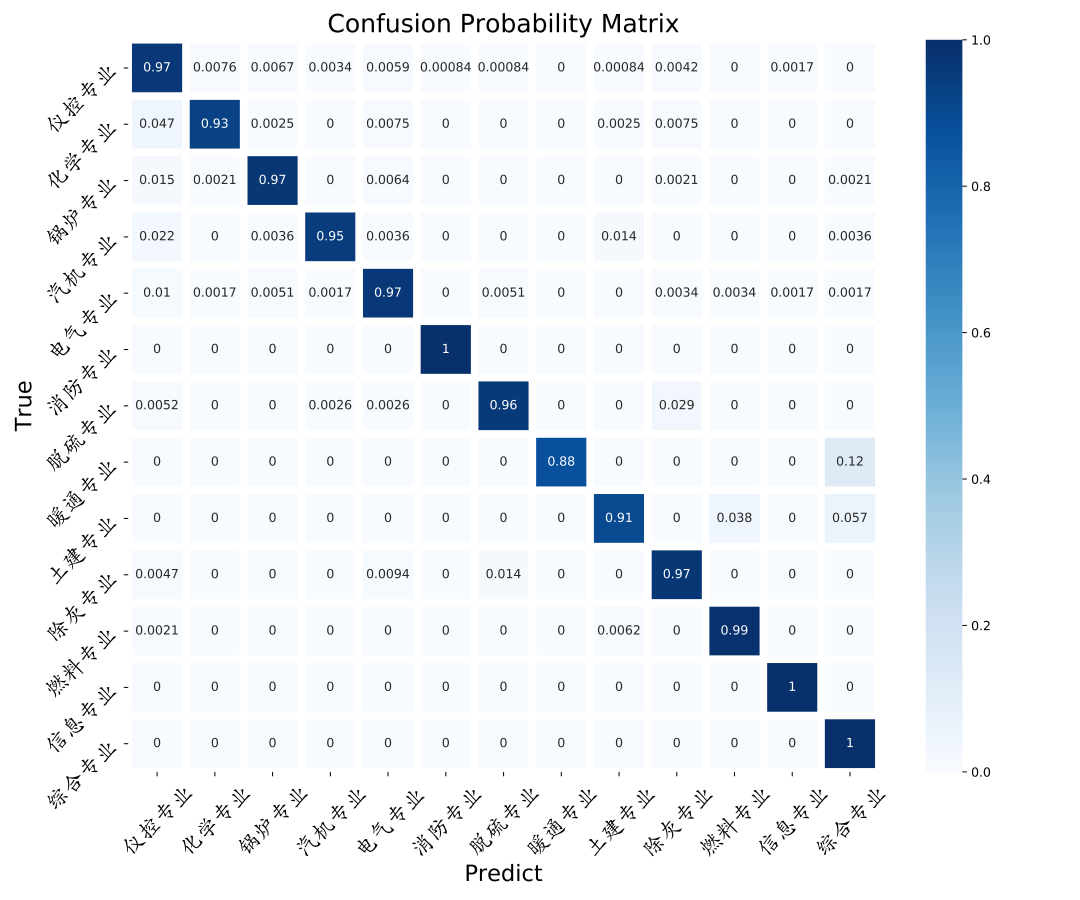
文本分类任务
在全新的测试数据上测试文本分类模型:
import numpy as np
import pandas as pd
# Data to be predicted
test_tokens = pd.read_table('/home/aistudio/data/' + dataID + '/test.txt')['tokens']
test_labels = pd.read_table('/home/aistudio/data/' + dataID + '/test.txt')['labels']
test_input = []
for token in test_tokens:
test_input.append([token])
f = open('/home/aistudio/data/' + dataID + '/label_list.txt', 'r')
label_list = f.read().strip().split('\t')
f.close()
label_map = {
idx: label_text for idx, label_text in enumerate(label_list)
}
model = hub.Module(
name='ernie',
task='seq-cls',
load_checkpoint='./model.pdparams',
label_map=label_map)
results = model.predict(test_input, max_seq_len=128, batch_size=1, use_gpu=True)
# 展示 10 条结果
for idx, text in enumerate(test_input[:10]):
print('Data: {} \t Lable: {} \t Prediction: {}'.format(text, test_labels[idx], results[idx]))
# 保存结果
output= pd.DataFrame({'token': test_tokens, 'label': test_labels, 'prediction': results})
output.to_csv('output.csv')
文本生成任务
from tqdm import tqdm
from paddlenlp.metrics import Rouge1
rouge1 = Rouge1()
vocab = tokenizer.vocab
eos_id = vocab[tokenizer.sep_token]
sos_id = vocab[tokenizer.cls_token]
pad_id = vocab[tokenizer.pad_token]
unk_id = vocab[tokenizer.unk_token]
vocab_size = len(vocab)
paddle.seed(2021) # set random seed
evaluated_sentences_ids = []
reference_sentences_ids = []
logger.info("Evaluating...")
model.eval()
for data in tqdm(test_data_loader):
(src_ids, src_sids, src_pids, _, _, _, _, _, _, _, _,
raw_tgt_labels) = data # never use target when infer
output_ids = greedy_search_infilling(
model,
src_ids,
src_sids,
eos_id=eos_id,
sos_id=sos_id,
attn_id=attn_id,
pad_id=pad_id,
unk_id=unk_id,
vocab_size=vocab_size,
max_decode_len=max_decode_len,
max_encode_len=max_encode_len,
tgt_type_id=tgt_type_id)
for ids in output_ids.tolist():
if eos_id in ids:
ids = ids[:ids.index(eos_id)]
evaluated_sentences_ids.append(ids)
for ids in raw_tgt_labels.numpy().tolist():
ids = ids[1:ids.index(eos_id)]
reference_sentences_ids.append(ids)
evaluated_sentences = []
reference_sentences = []
for ids in reference_sentences_ids[:]:
reference_sentences.append(''.join(vocab.to_tokens(ids)))
for ids in evaluated_sentences_ids[:]:
evaluated_sentences.append(''.join(vocab.to_tokens(ids)))
长线规划
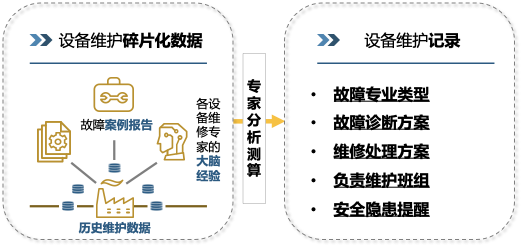
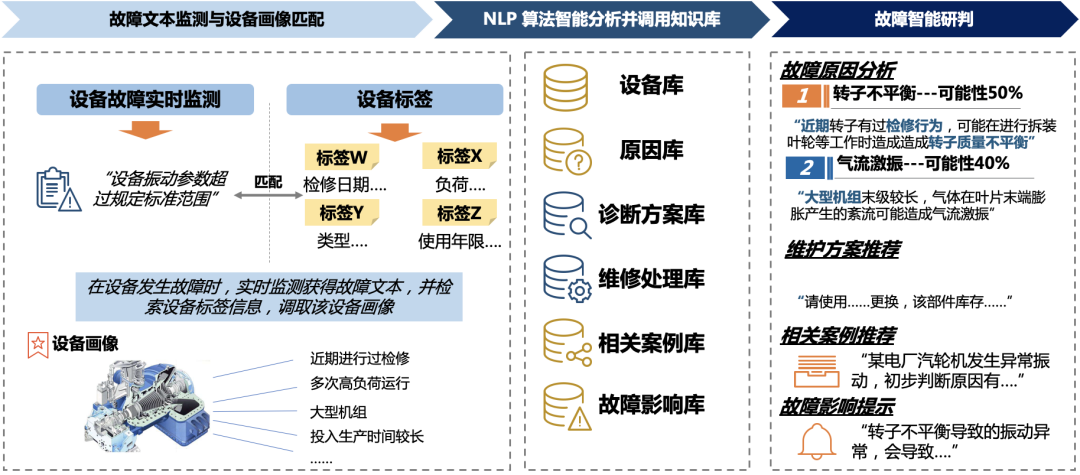
基于本项目的成果,后续可以发展出更加完善、全面的设备故障智能维护系统。以汽轮机的异常振动为例,当实时监测系统监测到设备故障时,会生成故障文本:“设备振动参数超过规定标准范围”,故障文本与设备的检修日期、使用年限等标签信息和设备画像信息相匹配,一起输入到模型中。根据算法结果调用知识库,输出故障的原因分析:有 50% 的可能性是转子不平衡引起的,有 40% 的可能性是气流激振引起的,等等。并推送相应的维护方案、相关案例、故障影响等。这些故障研判信息能够对实际消缺工作起到辅助作用,有效提高设备故障抢修效率,减少人力消耗,缩短维修时间,整体上提高电厂设备运行效率,降低因设备故障造成的经济损失。
传统人工处理的局限性
传统机器学习建模的局限性
业务理解
技术抽象
文本分类任务:基于故障描述文本,判断故障的类别或定位对应的检修专业部门。
文本生成任务:基于故障描述文本,生成维护建议。
技术选型
import paddlehub as hub
import paddle
model = hub.Module(name='ernie', task='seq-cls', num_classes=len(MyDataset.label_list))
数据处理
基本预处理
├──mydata: 数据目录
├── train.txt: 训练集数据
├── dev.txt: 验证集数据
└── test.txt: 测试集数据
label text_a
锅炉专业 捞渣机液压张紧油站处地沟堵塞
脱硫专业 脱硫冷却水至机喷淋装置进口电动阀54%处卡涩,无法关闭。
电气专业 网源协调分析装置屏柜内部分端口未禁用
from paddlehub.datasets.base_nlp_dataset import TextClassificationDataset
class MyDataset(TextClassificationDataset):
# 数据集存放目录
base_path = '/home/aistudio/data/' + dataID
# 数据集的标签列表
f = open(base_path + '/label_list.txt', 'r')
label_list = f.read().strip().split('\t')
f.close()
def __init__(self, tokenizer, max_seq_len: int = 128, mode: str = 'train'):
if mode == 'train':
data_file = 'train.txt'
elif mode == 'test':
data_file = 'test.txt'
else:
data_file = 'dev.txt'
super().__init__(
base_path=self.base_path,
tokenizer=tokenizer,
max_seq_len=max_seq_len,
mode=mode,
data_file=data_file,
label_list=self.label_list,
is_file_with_header=True)
类别均衡
对于分类任务,数据存在部分类别样本量过少,各类别数据不均衡的问题。针对此问题,采用下列三种方法尝试解决:
def random_deletion(words, p):
if len(words) == 1:
return words
new_words = []
for word in words:
r = random.uniform(0, 1)
if r > p:
new_words.append(word)
if len(new_words) == 0:
rand_int = random.randint(0, len(words)-1)
return [words[rand_int]]
return new_words
训练策略
文本分类任务
optimizer = paddle.optimizer.Adam(learning_rate=5e-5, parameters=model.parameters()) # 优化器的选择和参数配置
trainer = hub.Trainer(model, optimizer, checkpoint_dir='./ckpt', use_gpu=True) # fine-tune任务的执行者
文本生成任务
使用预热学习(Warmup)与学习率衰减(Decay)结合的策略,即设置学习率先升后降的方法进行训练:
import paddle.nn as nn
num_epochs = 30
learning_rate = 2e-5
warmup_proportion = 0.1
weight_decay = 0.1
max_steps = (len(train_data_loader) * num_epochs)
lr_scheduler = paddle.optimizer.lr.LambdaDecay(
learning_rate,
lambda current_step, num_warmup_steps=max_steps*warmup_proportion, num_training_steps=max_steps: float(current_step) / float(max(1, num_warmup_steps))
if current_step < num_warmup_steps else max(0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps))))
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
grad_clip=nn.ClipGradByGlobalNorm(1.0),
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
import os
import time
from paddlenlp.utils.log import logger
global_step = 1
logging_steps = 100
save_steps = 1000
output_dir = "output_model"
tic_train = time.time()
for epoch in range(num_epochs):
for step, batch in enumerate(train_data_loader, start=1):
(src_ids, src_sids, src_pids, tgt_ids, tgt_sids, tgt_pids, attn_ids,
mask_src_2_src, mask_tgt_2_srctgt, mask_attn_2_srctgtattn,
tgt_labels, _) = batch
# import pdb; pdb.set_trace()
_, __, info = model(
src_ids,
sent_ids=src_sids,
pos_ids=src_pids,
attn_bias=mask_src_2_src,
encode_only=True)
cached_k, cached_v = info['caches']
_, __, info = model(
tgt_ids,
sent_ids=tgt_sids,
pos_ids=tgt_pids,
attn_bias=mask_tgt_2_srctgt,
past_cache=(cached_k, cached_v),
encode_only=True)
cached_k2, cached_v2 = info['caches']
past_cache_k = [
paddle.concat([k, k2], 1) for k, k2 in zip(cached_k, cached_k2)
]
past_cache_v = [
paddle.concat([v, v2], 1) for v, v2 in zip(cached_v, cached_v2)
]
loss, _, __ = model(
attn_ids,
sent_ids=tgt_sids,
pos_ids=tgt_pids,
attn_bias=mask_attn_2_srctgtattn,
past_cache=(past_cache_k, past_cache_v),
tgt_labels=tgt_labels,
tgt_pos=paddle.nonzero(attn_ids == attn_id))
if global_step % logging_steps == 0:
logger.info(
"global step %d, epoch: %d, batch: %d, loss: %f, speed: %.2f step/s, lr: %.3e"
% (global_step, epoch, step, loss, logging_steps /
(time.time() - tic_train), lr_scheduler.get_lr()))
tic_train = time.time()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_gradients()
if global_step % save_steps == 0:
model_dir = os.path.join(output_dir,
"model_%d" % global_step)
if not os.path.exists(model_dir):
os.makedirs(model_dir)
model.save_pretrained(model_dir)
tokenizer.save_pretrained(model_dir)
global_step += 1项目成果
文本分类任务
在全新的测试数据上测试文本分类模型:
import numpy as np
import pandas as pd
# Data to be predicted
test_tokens = pd.read_table('/home/aistudio/data/' + dataID + '/test.txt')['tokens']
test_labels = pd.read_table('/home/aistudio/data/' + dataID + '/test.txt')['labels']
test_input = []
for token in test_tokens:
test_input.append([token])
f = open('/home/aistudio/data/' + dataID + '/label_list.txt', 'r')
label_list = f.read().strip().split('\t')
f.close()
label_map = {
idx: label_text for idx, label_text in enumerate(label_list)
}
model = hub.Module(
name='ernie',
task='seq-cls',
load_checkpoint='./model.pdparams',
label_map=label_map)
results = model.predict(test_input, max_seq_len=128, batch_size=1, use_gpu=True)
# 展示 10 条结果
for idx, text in enumerate(test_input[:10]):
print('Data: {} \t Lable: {} \t Prediction: {}'.format(text, test_labels[idx], results[idx]))
# 保存结果
output= pd.DataFrame({'token': test_tokens, 'label': test_labels, 'prediction': results})
output.to_csv('output.csv')
文本生成任务
from tqdm import tqdm
from paddlenlp.metrics import Rouge1
rouge1 = Rouge1()
vocab = tokenizer.vocab
eos_id = vocab[tokenizer.sep_token]
sos_id = vocab[tokenizer.cls_token]
pad_id = vocab[tokenizer.pad_token]
unk_id = vocab[tokenizer.unk_token]
vocab_size = len(vocab)
paddle.seed(2021) # set random seed
evaluated_sentences_ids = []
reference_sentences_ids = []
logger.info("Evaluating...")
model.eval()
for data in tqdm(test_data_loader):
(src_ids, src_sids, src_pids, _, _, _, _, _, _, _, _,
raw_tgt_labels) = data # never use target when infer
output_ids = greedy_search_infilling(
model,
src_ids,
src_sids,
eos_id=eos_id,
sos_id=sos_id,
attn_id=attn_id,
pad_id=pad_id,
unk_id=unk_id,
vocab_size=vocab_size,
max_decode_len=max_decode_len,
max_encode_len=max_encode_len,
tgt_type_id=tgt_type_id)
for ids in output_ids.tolist():
if eos_id in ids:
ids = ids[:ids.index(eos_id)]
evaluated_sentences_ids.append(ids)
for ids in raw_tgt_labels.numpy().tolist():
ids = ids[1:ids.index(eos_id)]
reference_sentences_ids.append(ids)
evaluated_sentences = []
reference_sentences = []
for ids in reference_sentences_ids[:]:
reference_sentences.append(''.join(vocab.to_tokens(ids)))
for ids in evaluated_sentences_ids[:]:
evaluated_sentences.append(''.join(vocab.to_tokens(ids)))
长线规划
基于本项目的成果,后续可以发展出更加完善、全面的设备故障智能维护系统。以汽轮机的异常振动为例,当实时监测系统监测到设备故障时,会生成故障文本:“设备振动参数超过规定标准范围”,故障文本与设备的检修日期、使用年限等标签信息和设备画像信息相匹配,一起输入到模型中。根据算法结果调用知识库,输出故障的原因分析:有 50% 的可能性是转子不平衡引起的,有 40% 的可能性是气流激振引起的,等等。并推送相应的维护方案、相关案例、故障影响等。这些故障研判信息能够对实际消缺工作起到辅助作用,有效提高设备故障抢修效率,减少人力消耗,缩短维修时间,整体上提高电厂设备运行效率,降低因设备故障造成的经济损失。