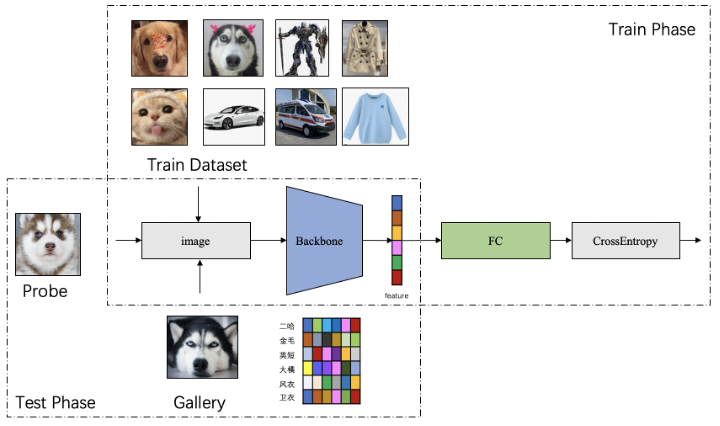
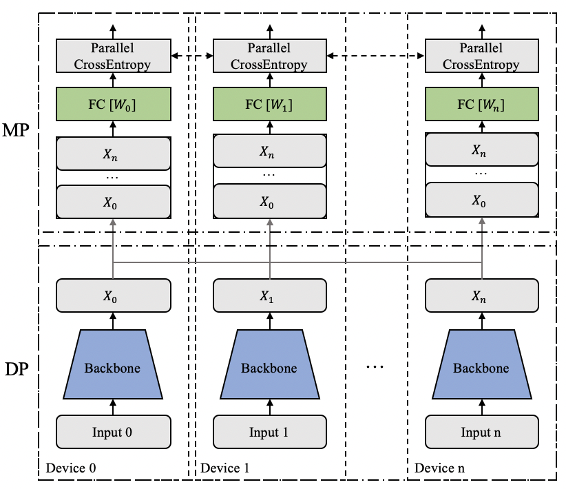
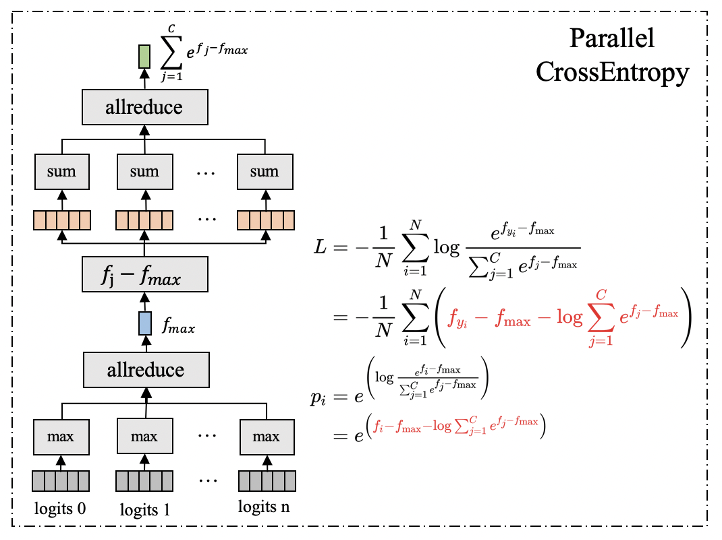
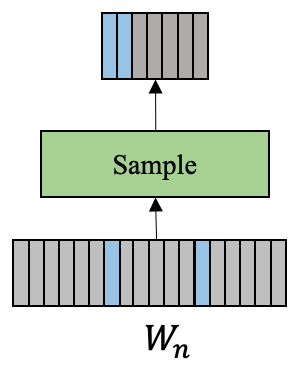
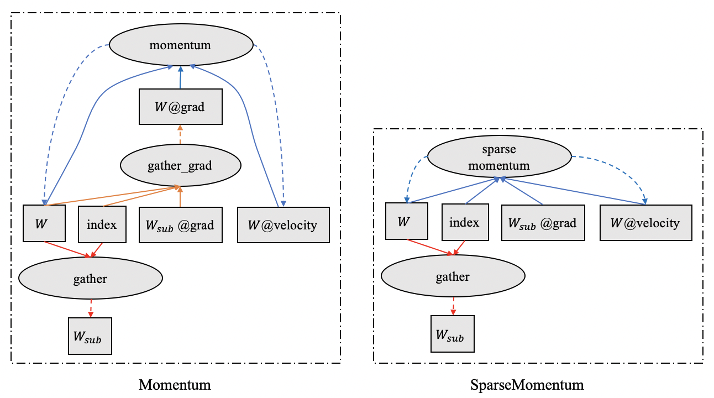
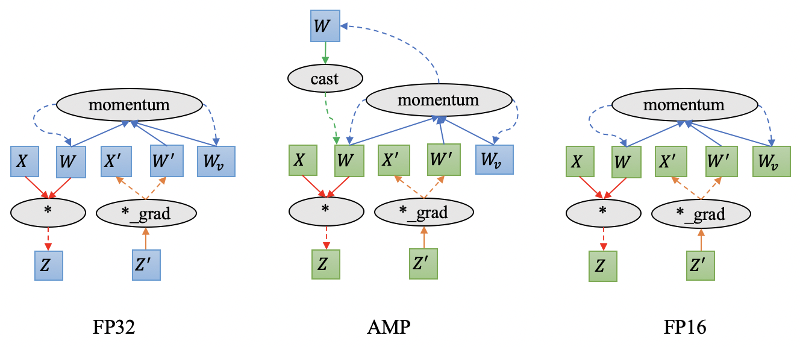
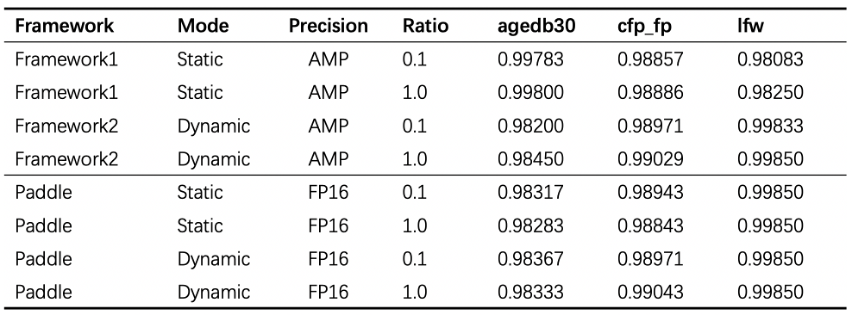
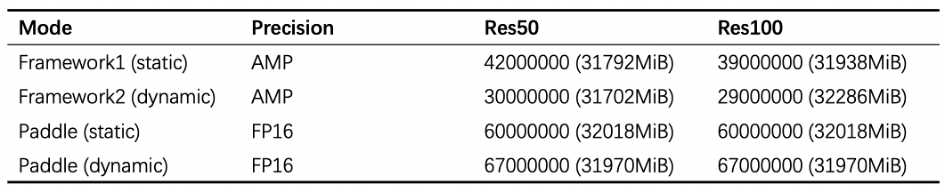
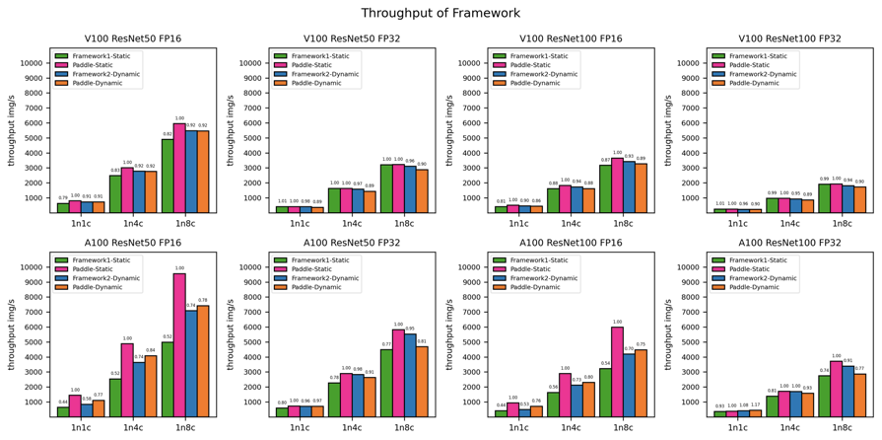
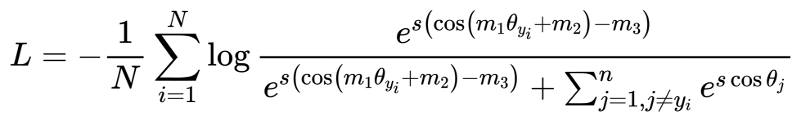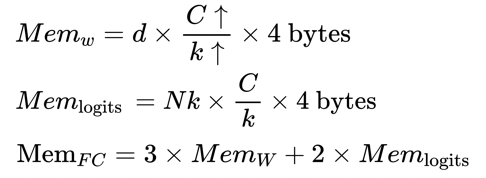其次是速度问题。普通分类模型也面临同样的问题。随着训练数据、模型规模和分类类别数的增加,模型训练的复杂度显著增长,导致模型训练所需要的时间不断增长。速度是人类永无止境的追求,如何在更短的时间内训练大规模分类模型也是工程实践中迫切需要解决的问题。 为了解决以上两方面难题,学术界和工业界不断围绕着训练的显存消耗和速度进行优化;飞桨团队也持续不断地打磨升级大规模分类库PLSC(Paddle Large Scale Classification),提供数据并行&模型并行混合训练、类别中心采样、稀疏梯度参数更新和FP16训练等解决方案。
项目地址:GitHub:https://github.com/PaddlePaddle/PLSCGitHub: https://github.com/deepinsight/insightface参考引用:[1]https://github.com/deepinsight/insightface.git[2]Deng, J., Guo, J., Xue, N. and Zafeiriou, S., 2019. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4690-4699).[3]Wang, H., Wang, Y., Zhou, Z., Ji, X., Gong, D., Zhou, J., Li, Z. and Liu, W., 2018. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5265-5274).[4]Liu, W., Wen, Y., Yu, Z., Li, M., Raj, B. and Song, L., 2017. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 212-220).[5]An, X., Zhu, X., Gao, Y., Xiao, Y., Zhao, Y., Feng, Z., Wu, L., Qin, B., Zhang, M., Zhang, D. and Fu, Y., 2021. Partial fc: Training 10 million identities on a single machine. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 1445-1449).[6]Micikevicius, P., Narang, S., Alben, J., Diamos, G., Elsen, E., Garcia, D., Ginsburg, B., Houston, M., Kuchaiev, O., Venkatesh, G. and Wu, H., 2017. Mixed precision training. arXiv preprint arXiv:1710.03740. 关注公众号,获取更多技术内容~
其次是速度问题。普通分类模型也面临同样的问题。随着训练数据、模型规模和分类类别数的增加,模型训练的复杂度显著增长,导致模型训练所需要的时间不断增长。速度是人类永无止境的追求,如何在更短的时间内训练大规模分类模型也是工程实践中迫切需要解决的问题。 为了解决以上两方面难题,学术界和工业界不断围绕着训练的显存消耗和速度进行优化;飞桨团队也持续不断地打磨升级大规模分类库PLSC(Paddle Large Scale Classification),提供数据并行&模型并行混合训练、类别中心采样、稀疏梯度参数更新和FP16训练等解决方案。
项目地址:GitHub:https://github.com/PaddlePaddle/PLSCGitHub: https://github.com/deepinsight/insightface参考引用:[1]https://github.com/deepinsight/insightface.git[2]Deng, J., Guo, J., Xue, N. and Zafeiriou, S., 2019. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4690-4699).[3]Wang, H., Wang, Y., Zhou, Z., Ji, X., Gong, D., Zhou, J., Li, Z. and Liu, W., 2018. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5265-5274).[4]Liu, W., Wen, Y., Yu, Z., Li, M., Raj, B. and Song, L., 2017. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 212-220).[5]An, X., Zhu, X., Gao, Y., Xiao, Y., Zhao, Y., Feng, Z., Wu, L., Qin, B., Zhang, M., Zhang, D. and Fu, Y., 2021. Partial fc: Training 10 million identities on a single machine. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 1445-1449).[6]Micikevicius, P., Narang, S., Alben, J., Diamos, G., Elsen, E., Garcia, D., Ginsburg, B., Houston, M., Kuchaiev, O., Venkatesh, G. and Wu, H., 2017. Mixed precision training. arXiv preprint arXiv:1710.03740. 关注公众号,获取更多技术内容~