案例简介
铁路货车车号是铁路货车车身上的一串号码,相当于车辆的“有效身份证”。它是铁路信息化管理的关键,是快速准确判断车辆位置和使用情况的重要依据。一旦出错,将直接影响行车调度指挥、列车运行、货车实时追踪管理、货车占用费清算等环节,不仅会降低铁路货车整体运转效率,严重情况下还会导致行车事故发生,后果不堪设想。人工喷涂与核对车号需要耗费大量精力,极其容易漏喷、错喷。厂、段修车数量庞大,核对人员很容易漏核。
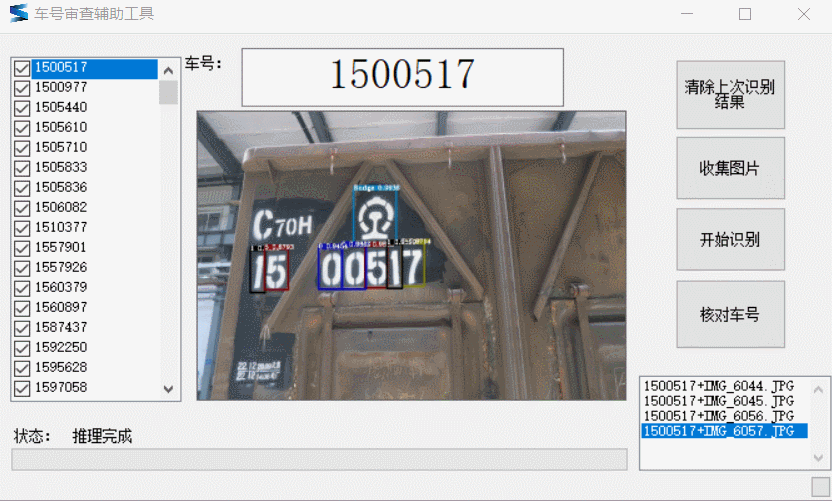
武汉铁路局襄阳车辆段为提升车号核验效率,基于百度飞桨深度学习技术PaddleDetection,研发了一套自动化车号识别工具,以机器代替人工,减少人为错误,提升了整体车辆车号识别效率。
相关飞桨产品
PaddleDetection
相关硬件产品
Intel i3-7100双核 4G RAM
场景分析
难点一:图像分类
货车检修的传统人工作业中,作业者要先在现场一次对落成车的14个部位进行拍照,作业完毕后,回到车间电脑上将照片存档。并按当日计划中车号,新建以车号命名的文件夹,放入14张照片,并核对四张车号照片。若按每天30辆段修能力计算,一天就需要将420张照片分类,核对120张车号照片,这个过程耗时长、重复且枯燥。
难点二:精准识别
对车辆车号识别过程中,会对拍摄图片由于存在受曝光、拍摄角度等因素干扰较大,不适合现场作业。正确率受曝光影响过大,对于OCR识别来说精确度也不高,经常识别不出或出错,因此对字符识别准确性产生较大影响。
业务抽象
通过深度学习框架飞桨PaddlePaddle,对车辆车号位置、字符进行识别。对任务进行抽象,可判定为典型的计算机视觉任务,可采用目标检测进行任务求解。
技术方案
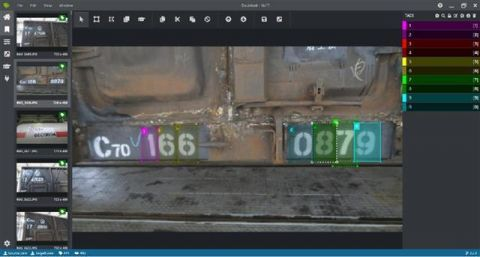
检修车间制动钳工兼软件开发者李桑郁通过深度学习目标检测算法对铁路车辆车号进行识别,通过目标检测算法(PP-YOLO)对车号区域进行检测定位,直接对车号字符逐个匹配。把字符定位和匹配结合起来计算出车号。
第一阶段:数据采集、标注和增强
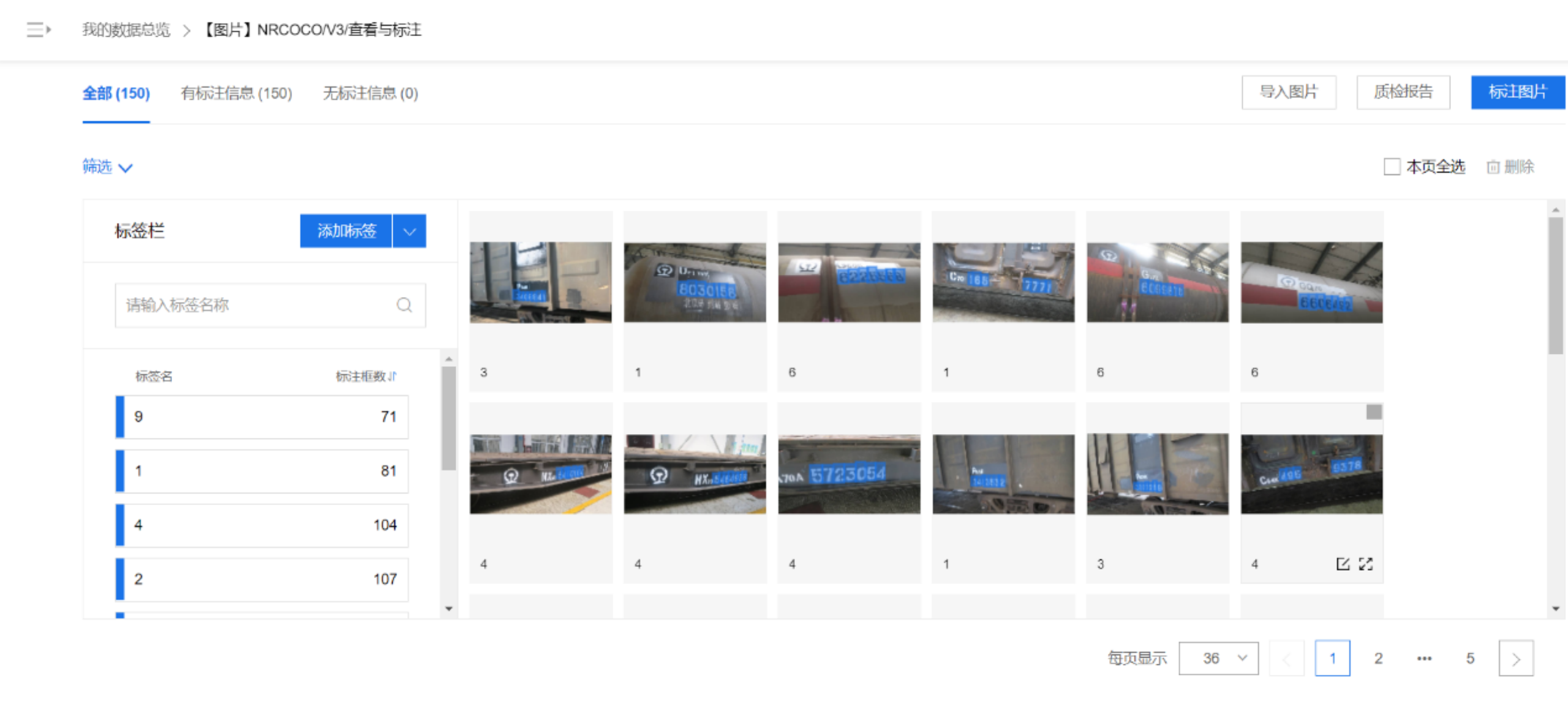
使用VOTT标注部分数据集后导出,接着使用EasyData自动标注功能进行自动标注。因目标变化不大,所以不需要太大的数据集,即可达到理想的识别效果。
第二阶段:模型选择及调优
考虑到铁路内部计算机性能普遍羸弱,检测器选择一阶段检测器PP-YOLO。PP-YOLO 单阶段检测器与达到同样精度的传统目标检测方法相比,推断速度能达到接近两倍,精度差距不大。在保证速度与精度均达到较高水平的情况下,能更好应用到现场生产中。
第三阶段:模型训练及评估
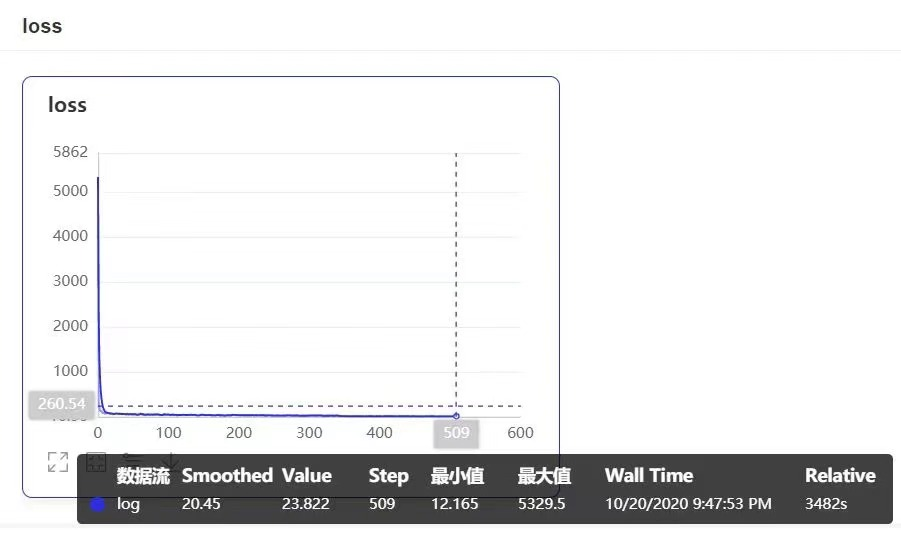
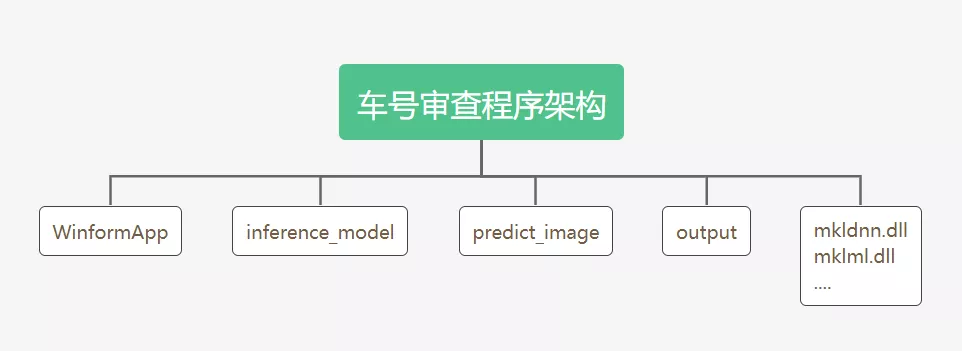
根据个人需要编写代码,将主干网络(backbone)更换为ResNet(代码略)。接着训练数据,并使用VisualDL查看loss、IoU等各项参数变化。训练完成后导出模型,着手部署工作。考虑到大多数办公电脑为Windows电脑,且性能不佳,不具有高性能GPU,所以将推理(Inference)程序编译时配置使用Intel MKL(数学核心库),并生成dll与Winform客户端对接。
通过测试、验证,该系统具有较高的识别准确率,高达97%,在测试中(216辆车,3024张照片),仅有23张照片出现个别数字识别错误的情况(大部分是照片模糊、角度过偏引起的)。此应用能够基本解决传统人工识别易出错、耗精力等问题,能够极大的提高审核效率。
第四阶段:部署及上线
训练完成后导出模型,着手部署工作。考虑到大多数办公电脑为Windows电脑,且性能不佳,不具有高性能GPU,所以将推理(Inference)程序编译时配置使用Intel MKL(数学核心库),并生成dll与Winform客户端对接。
上线效果
通过测试、验证,该车号识别工具有较高的识别准确率,高达97%。在216辆车、3024张照片的测试中,仅有23张照片出现个别数字识别错误的情况,且均为是照片模糊、拍摄角度过偏引起的。可见,此辅助工具可以基本解决传统人工识别易出错、耗精力等问题,能够极大的提高审核效率。
案例企业简介
中国铁路武汉局集团有限公司襄阳车辆段于2017年06月07日成立。法定代表人黄东林,公司经营范围包括:国铁货车车辆检查及维修,企业自备车检查及维修服务,铁路货车车辆检查技术服务;铁路器材、设备、配件的采购、销售、安装及维修;铁路货车维修用材料及配件采购、供销、仓储(不含危险品);装卸服务;房屋场地租赁;废旧物资处置(不含废弃电器电子产品及危险废弃物);报废货车解体、搬运、处置;铁路货车维修技术教育培训;铁路车辆安全工程施工及管理等。
案例简介
铁路货车车号是铁路货车车身上的一串号码,相当于车辆的“有效身份证”。它是铁路信息化管理的关键,是快速准确判断车辆位置和使用情况的重要依据。一旦出错,将直接影响行车调度指挥、列车运行、货车实时追踪管理、货车占用费清算等环节,不仅会降低铁路货车整体运转效率,严重情况下还会导致行车事故发生,后果不堪设想。人工喷涂与核对车号需要耗费大量精力,极其容易漏喷、错喷。厂、段修车数量庞大,核对人员很容易漏核。
武汉铁路局襄阳车辆段为提升车号核验效率,基于百度飞桨深度学习技术PaddleDetection,研发了一套自动化车号识别工具,以机器代替人工,减少人为错误,提升了整体车辆车号识别效率。
相关飞桨产品
PaddleDetection
相关硬件产品
Intel i3-7100双核 4G RAM
场景分析
难点一:图像分类
货车检修的传统人工作业中,作业者要先在现场一次对落成车的14个部位进行拍照,作业完毕后,回到车间电脑上将照片存档。并按当日计划中车号,新建以车号命名的文件夹,放入14张照片,并核对四张车号照片。若按每天30辆段修能力计算,一天就需要将420张照片分类,核对120张车号照片,这个过程耗时长、重复且枯燥。
难点二:精准识别
对车辆车号识别过程中,会对拍摄图片由于存在受曝光、拍摄角度等因素干扰较大,不适合现场作业。正确率受曝光影响过大,对于OCR识别来说精确度也不高,经常识别不出或出错,因此对字符识别准确性产生较大影响。
业务抽象
通过深度学习框架飞桨PaddlePaddle,对车辆车号位置、字符进行识别。对任务进行抽象,可判定为典型的计算机视觉任务,可采用目标检测进行任务求解。
技术方案
检修车间制动钳工兼软件开发者李桑郁通过深度学习目标检测算法对铁路车辆车号进行识别,通过目标检测算法(PP-YOLO)对车号区域进行检测定位,直接对车号字符逐个匹配。把字符定位和匹配结合起来计算出车号。
第一阶段:数据采集、标注和增强
使用VOTT标注部分数据集后导出,接着使用EasyData自动标注功能进行自动标注。因目标变化不大,所以不需要太大的数据集,即可达到理想的识别效果。
第二阶段:模型选择及调优
考虑到铁路内部计算机性能普遍羸弱,检测器选择一阶段检测器PP-YOLO。PP-YOLO 单阶段检测器与达到同样精度的传统目标检测方法相比,推断速度能达到接近两倍,精度差距不大。在保证速度与精度均达到较高水平的情况下,能更好应用到现场生产中。
第三阶段:模型训练及评估
根据个人需要编写代码,将主干网络(backbone)更换为ResNet(代码略)。接着训练数据,并使用VisualDL查看loss、IoU等各项参数变化。训练完成后导出模型,着手部署工作。考虑到大多数办公电脑为Windows电脑,且性能不佳,不具有高性能GPU,所以将推理(Inference)程序编译时配置使用Intel MKL(数学核心库),并生成dll与Winform客户端对接。
通过测试、验证,该系统具有较高的识别准确率,高达97%,在测试中(216辆车,3024张照片),仅有23张照片出现个别数字识别错误的情况(大部分是照片模糊、角度过偏引起的)。此应用能够基本解决传统人工识别易出错、耗精力等问题,能够极大的提高审核效率。
第四阶段:部署及上线
训练完成后导出模型,着手部署工作。考虑到大多数办公电脑为Windows电脑,且性能不佳,不具有高性能GPU,所以将推理(Inference)程序编译时配置使用Intel MKL(数学核心库),并生成dll与Winform客户端对接。
上线效果
通过测试、验证,该车号识别工具有较高的识别准确率,高达97%。在216辆车、3024张照片的测试中,仅有23张照片出现个别数字识别错误的情况,且均为是照片模糊、拍摄角度过偏引起的。可见,此辅助工具可以基本解决传统人工识别易出错、耗精力等问题,能够极大的提高审核效率。
案例企业简介
中国铁路武汉局集团有限公司襄阳车辆段于2017年06月07日成立。法定代表人黄东林,公司经营范围包括:国铁货车车辆检查及维修,企业自备车检查及维修服务,铁路货车车辆检查技术服务;铁路器材、设备、配件的采购、销售、安装及维修;铁路货车维修用材料及配件采购、供销、仓储(不含危险品);装卸服务;房屋场地租赁;废旧物资处置(不含废弃电器电子产品及危险废弃物);报废货车解体、搬运、处置;铁路货车维修技术教育培训;铁路车辆安全工程施工及管理等。