本项目介绍了TNT图像分类模型,讲述了如何使用飞桨一步步构建TNT模型网络结构,并尝试在新冠肺炎CT数据集上进行分类。由于作者水平有限,若有不当之处欢迎批评指正。
TNT模型全称是Transformer-In-Transformer,取名有些致敬NIN (Network in Network) 的意思, 提出了一种新颖的视觉识别神经网络结构,取得较好的性能,在当时表现SOTA。
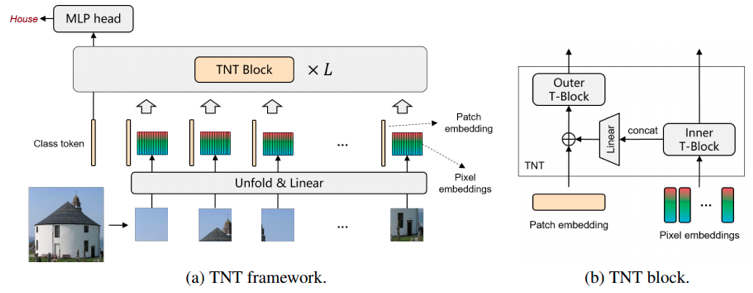
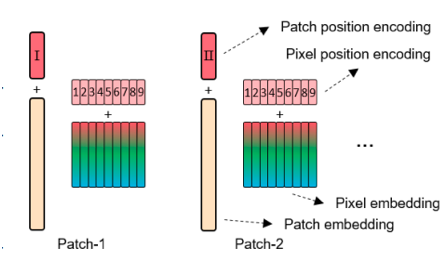
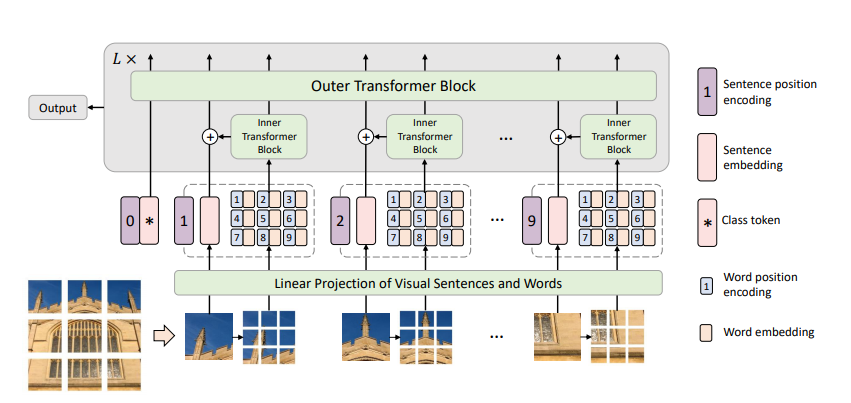
TNT不再使用传统的RNN和CNN方法,而是使用基于注意力的sequence数据的处理,将图像均匀地分成一系列patches,这样的Patches序列构成视觉语句(visual sentence),每个Patch进一步切分成多个sub-patches, 形成视觉词汇(visual word), 同时结合视觉词汇下的像素级特征进行建模。核心要点有以下几方面:
TNT 通过融合 Patches 和 Sub-Patches 两个层级的特征,相比只使用 Patches 层级特征的 ViT 及 DeiT 模型,在参数量和 FLOPs 相近的情况下精度更高。对比 CNN 模型,在相同的参数量和 FLOPs 下,精度表现优于 ResNet 和 RegNet,接近 EfficientNet 的精度表现。
GitHub代码:
https://github.com/huawei-noah/noah-research/tree/master/TNT
https://arxiv.org/pdf/2103.00112.pdf
TNT网络结构复现过程
本段将对TNT网络结构中比较关键的几个组件做一下介绍,包括关键的代码展示和一些代码注释说明。整体网络框架如下图:
PatchEmbed将图像
在visual words级进行编码嵌入
class PatchEmbed(nn.Layer):
""" Image to Visual Word Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, in_dim=48, stride=4):
super().__init__()
num_patches = (img_size // patch_size) * (img_size // patch_size) #行列维度上的patch数量
self.img_size = img_size
self.num_patches = num_patches
self.in_dim = in_dim
new_patch_size = math.ceil(patch_size / stride) #visual words数量
self.new_patch_size = new_patch_size
self.proj = nn.Conv2D(in_chans, self.in_dim, kernel_size=7, padding=3, stride=stride)
def forward(self, x, pixel_pos):
B, C, H, W = x.shape
assert H == self.img_size and W == self.img_size, \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size}*{self.img_size})."
x = self.proj(x) #利用卷积特征映射
x = F.unfold(x, self.new_patch_size, self.new_patch_size) #类似im2col, 窗口滑动时形成一系列的列向量
x = x.transpose((0, 2, 1)).reshape((B * self.num_patches, self.in_dim, self.new_patch_size, self.new_patch_size))
x = x + pixel_pos # 加上相应的位置编码
x = x.reshape((B * self.num_patches, self.in_dim, -1)).transpose((0, 2, 1))
return x多头注意力模块
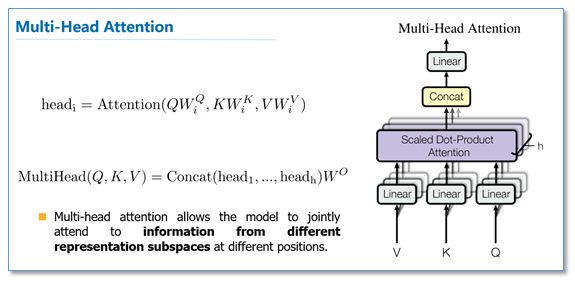
多头注意力是集成多个独立的Attention使用。相同的Q,K,V权重,通过线性转换,每个注意力模块负责最终输出序列中一个子空间。通过对输入数据进行注意力编码,然后将注意力结果叠加到原输入数据上。Attention的输入和输出维度一样,仅仅是数值上产生了变化。
多头自注意力计算的主要步骤:
class Attention(nn.Layer):
""" 多头自注意力
"""
def __init__(self, dim, hidden_dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
head_dim = hidden_dim // num_heads
self.head_dim = head_dim
self.scale = head_dim ** -0.5
self.qk = nn.Linear(dim, hidden_dim * 2, bias_attr=qkv_bias)
self.v = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qk = self.qk(x).reshape((B, N, 2, self.num_heads, self.head_dim)).transpose((2, 0, 3, 1, 4))
q, k = qk[0], qk[1] #分离query和key
v = self.v(x).reshape((B, N, self.num_heads, -1)).transpose((0, 2, 1, 3)) #计算v
attn = (q @ k.transpose((0, 1, 3, 2))) * self.scale #缩放点积注意力
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose((0, 2, 1, 3)).reshape((B, N, -1))
x = self.proj(x)
x = self.proj_drop(x)
return x
MLP多层感知机
class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return xDropPath丢弃策略
跟传统的DropOut有什么区别?与普通的DropOut相比,DropPath使得丢弃的数据更多。所谓Path,就是沿着输入单元的第一个轴的通道,并将在这轴上的通道按概率选取丢弃;传统的DropOut,在神经网络中以一定概率随机的暂时丢弃一些单元以及与它们相连的节点,而DropPath则是实现从整个轴上以概率方式随机进行丢弃,丢弃轴上的参数全部置为0, 主要用在多分支结构上。
def drop_path(x, drop_prob=0., training=False):
if drop_prob == 0. or not training:
return x
keep_prob = paddle.to_tensor(1 - drop_prob) #计算保留率
shape = (x.shape[0],) + (1,) * (x.ndim - 1) #计算形状
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype) #生成随机tensor
random_tensor = paddle.floor(random_tensor) # 二值化, 非0即1
output = x.divide(keep_prob) * random_tensor # 权值放缩, drop之后增强保留权值的权重
return output
class DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
TNT Block
该模块是网络结构中的核心部分,由内部和外部transformer组成,分别对visual words embedding间和 visual sentences embedding间进行建模并提取特征。
主要实现步骤:
构建内层Transformer,组网包括Attention, MLP, Linear三个模块。
输出内层tokens。
构建外层Transformer, 利用Linear将内层tokens映射到外层tokens,经过自注意力和多层感知机,输出外层tokens。
class Block(nn.Layer):
""" TNT Block
"""
def __init__(self, dim, in_dim, num_pixel, num_heads=12, in_num_head=4, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
# Inner transformer
self.norm_in = norm_layer(in_dim)
self.attn_in = Attention(
in_dim, in_dim, num_heads=in_num_head, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop)
self.norm_mlp_in = norm_layer(in_dim)
self.mlp_in = Mlp(in_features=in_dim, hidden_features=int(in_dim * 4),
out_features=in_dim, act_layer=act_layer, drop=drop) self.norm1_proj = norm_layer(in_dim)
self.proj = nn.Linear(in_dim * num_pixel, dim, bias_attr=True)
# Outer transformer
self.norm_out = norm_layer(dim)
self.attn_out = Attention(
dim, dim, num_heads=num_heads, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm_mlp = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio),
out_features=dim, act_layer=act_layer, drop=drop)
def forward(self, inner_tokens, outer_tokens):
# inner
inner_tokens = inner_tokens + self.drop_path(self.attn_in(self.norm_in(inner_tokens)))
inner_tokens = inner_tokens + self.drop_path(self.mlp_in(self.norm_mlp_in(inner_tokens)))
# outer
B, N, C = outer_tokens.shape
outer_tokens[:, 1:] = outer_tokens[:, 1:] + self.proj(self.norm1_proj(inner_tokens).reshape((B, N - 1, -1)))
outer_tokens = outer_tokens + self.drop_path(self.attn_out(self.norm_out(outer_tokens)))
outer_tokens = outer_tokens + self.drop_path(self.mlp(self.norm_mlp(outer_tokens)))
return inner_tokens, outer_tokens
TNT模型组网
将上面的网络模块按照模型框架组织构造起来,流程大致如下:
class TNT(nn.Layer):
"""TNT"""
def __init__(
self,
img_size=224,
patch_size=16,
in_chans=3,
num_classes=1000,
embed_dim=384,
in_dim=24,
depth=12,
num_heads=6,
in_num_head=4,
mlp_ratio=4.,
qkv_bias=False,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
norm_layer=nn.LayerNorm,
first_stride=4):
super(TNT, self).__init__()
assert embed_dim % num_heads == 0
assert img_size % patch_size == 0
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(img_size, patch_size, in_chans, in_dim, first_stride)
num_patches = self.patch_embed.num_patches
self.num_patches = num_patches
new_patch_size = self.patch_embed.new_patch_size
num_pixel = new_patch_size ** 2
self.norm1_proj = norm_layer(num_pixel * in_dim)
self.proj = nn.Linear(num_pixel * in_dim, embed_dim)
self.norm2_proj = norm_layer(embed_dim)
self.cls_token = self.create_parameter(shape=(1, 1, embed_dim), default_initializer=zeros_)
self.patch_pos = self.create_parameter(shape=(1, self.num_patches + 1, embed_dim), default_initializer=zeros_)
self.pixel_pos = self.create_parameter(shape=(1, in_dim, new_patch_size, new_patch_size), default_initializer=zeros_)
self.pos_drop = nn.Dropout(1. - drop_rate)
dpr = list(np.linspace(0, drop_rate, depth))
blocks = []
for i in range(depth):
blocks.append(Block(
dim=embed_dim, in_dim=in_dim, num_pixel=num_pixel, num_heads=num_heads, in_num_head=in_num_head,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[i], norm_layer=norm_layer))
self.blocks = nn.LayerList(blocks)
self.norm = norm_layer(embed_dim)
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else Identity()
trunc_normal_(self.cls_token)
trunc_normal_(self.patch_pos)
trunc_normal_(self.pixel_pos)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else Identity()
def forward_features(self, x):
B = x.shape[0]
inner_tokens = self.patch_embed(x, self.pixel_pos) #visual words间的嵌入
#将inner_tokens线性映射到outer_tokens
outer_tokens = self.norm2_proj(self.proj(self.norm1_proj(inner_tokens.reshape((B, self.num_patches, -1)))))
#拼接分类token和patch_embed
outer_tokens = paddle.concat((self.cls_token.expand((B, -1, -1)), outer_tokens), axis=1)
outer_tokens = outer_tokens + self.patch_pos #加上patch的位置编码
outer_tokens = self.pos_drop(outer_tokens) #普通的nn.dropout丢弃策略
#迭代多个TNT Blocks
for blk in self.blocks:
inner_tokens, outer_tokensd = blk(inner_tokens, outer_tokens)
outer_tokens = self.norm(outer_tokens) #归一化
return outer_tokens[:, 0] #cls_token用于分类
def forward(self, x):
x = self.forward_features(x)
x = self.head(x) #全连接到类别数
return x
TNT复现结果
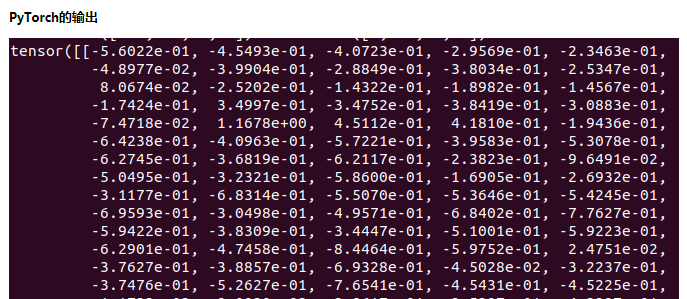
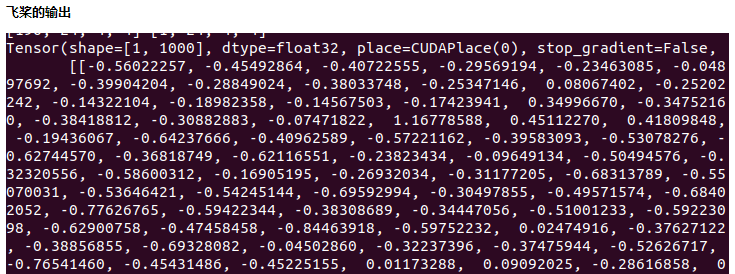
将PyTorch权重导出为飞桨权重文件,使用固定的网络输入,例如全是1, 对比二者的输出结果,基本保持一致:
使用ImageNet验证集数据,对复现的飞桨网络结构进行验证,最终达到作者提出的精度。
model = TNT(num_classes=1000)
model_state_dict = paddle.load("/home/aistudio/work/tnt.pdparams")
model.set_state_dict(model_state_dict)
run_model = paddle.Model(model)
optim = paddle.optimizer.SGD(learning_rate=0.0001, weight_decay=6e-5, parameters=run_model.parameters())
run_model.prepare(optimizer= optim,
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
#模型验证
run_model.evaluate(val_dataset, batch_size=32, verbose=1)
完整的复现代码:
https://aistudio.baidu.com/aistudio/projectdetail/1949371
https://github.com/thunder95/paddle_papers_reproduce
基于TNT模型
训练新冠肺炎CT
中重症新冠肺炎患者的肺部可能会出现磨玻璃影,铺路石症等症状,这在CT检查中容易判别。因此在这个项目中使用复现好的TNT模型对新冠肺炎、其他病毒性肺炎 和 正常人三个类别的CT检查结果进行了分类。
使用covid19-radiography-database 数据集,该数据集包含220张从多种渠道收集的新冠肺炎患者CT影像,1346张其他病毒性肺炎患者CT影像和1342张正常人CT影像。本项目将数据集按照8:2比例划分成训练集和验证集。
继承Paddle.io的Dataset,构造数据读取器。
class CatDataset(Dataset):
def __init__(self, mode='train', split_ratio=0.8):
super(CatDataset, self).__init__()
data_transforms = T.Compose([
T.Resize(480, interpolation='bicubic'),
T.ToTensor(),
T.Normalize()
])
train_data_folder = DatasetFolder(train_image_dir, transform=data_transforms)
eval_data_folder = DatasetFolder(eval_image_dir, transform=data_transforms)
self.mode = mode
if self.mode == 'train':
self.data = train_data_folder
elif self.mode == 'eval':
self.data = eval_data_folder
def __getitem__(self, index):
data = self.data[index][0].astype('float32')
if self.mode == 'test':
return data
else:
label = np.array([self.data[index][1]]).astype('int64')
return data, label
基于飞桨的高层API,只需短短的几十行代码就可以非常方便的进行训练和测试。
import paddle
from tnt import TNT
from dataset import CatDataset
train_dataset = CatDataset("train") #加载训练集
val_dataset = CatDataset("eval") #加载测试集
callback = paddle.callbacks.EarlyStopping(patience=50, verbose=0, min_delta=0.0001) #回调函数
model = TNT( num_classes=3, img_size=480) #初始化模型, 修改输入大小
run_model = paddle.Model(model)
optim = paddle.optimizer.Adam(learning_rate=0.00005, weight_decay=6e-5, parameters=run_model.parameters())
run_model.prepare(optimizer= optim,
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy(topk=(1, 5)))
run_model.fit(train_dataset, val_dataset, epochs=100, batch_size=32, log_freq=200,
save_freq=10,
save_dir="./checkpoints", callbacks=callback, verbose=1)
run_model.predict(val_dataset) #模型预测
新冠肺炎CT数据集在传统网络如ResNet, MobileNet下表现得更加好,通常不经过仔细调参,精度就能达到97%以上。TNT网络结构相比更加复杂,训练过程中更容易过拟合,很难用更好的trick去调优,精度达到90%就很难再有所提升。本次训练过程基于飞桨开源框架v 2.0高层API完成,只是为了验证TNT网络在分类任务上的能力,没有经过仔细的调参优化,小伙伴可以自己多加尝试。
完整代码地址:
https://aistudio.baidu.com/aistudio/projectdetail/2317372
参考资料:
https://aistudio.baidu.com/aistudio/projectdetail/463184
https://aistudio.baidu.com/aistudio/projectdetail/1966894
https://github.com/PaddlePaddle/Paddle
https://www.paddlepaddle.org.cn/documentation/docs/zh/tutorial/quick_start/high_level_api/high_level_api.html#api
长按下方二维码立即
Star

更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
欢迎在飞桨论坛讨论交流~~
http://discuss.paddlepaddle.org.cn
本项目介绍了TNT图像分类模型,讲述了如何使用飞桨一步步构建TNT模型网络结构,并尝试在新冠肺炎CT数据集上进行分类。由于作者水平有限,若有不当之处欢迎批评指正。
TNT模型全称是Transformer-In-Transformer,取名有些致敬NIN (Network in Network) 的意思, 提出了一种新颖的视觉识别神经网络结构,取得较好的性能,在当时表现SOTA。
TNT不再使用传统的RNN和CNN方法,而是使用基于注意力的sequence数据的处理,将图像均匀地分成一系列patches,这样的Patches序列构成视觉语句(visual sentence),每个Patch进一步切分成多个sub-patches, 形成视觉词汇(visual word), 同时结合视觉词汇下的像素级特征进行建模。核心要点有以下几方面:
TNT 通过融合 Patches 和 Sub-Patches 两个层级的特征,相比只使用 Patches 层级特征的 ViT 及 DeiT 模型,在参数量和 FLOPs 相近的情况下精度更高。对比 CNN 模型,在相同的参数量和 FLOPs 下,精度表现优于 ResNet 和 RegNet,接近 EfficientNet 的精度表现。
GitHub代码:
https://github.com/huawei-noah/noah-research/tree/master/TNT
https://arxiv.org/pdf/2103.00112.pdf
TNT网络结构复现过程
本段将对TNT网络结构中比较关键的几个组件做一下介绍,包括关键的代码展示和一些代码注释说明。整体网络框架如下图:
PatchEmbed将图像
在visual words级进行编码嵌入
class PatchEmbed(nn.Layer):
""" Image to Visual Word Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, in_dim=48, stride=4):
super().__init__()
num_patches = (img_size // patch_size) * (img_size // patch_size) #行列维度上的patch数量
self.img_size = img_size
self.num_patches = num_patches
self.in_dim = in_dim
new_patch_size = math.ceil(patch_size / stride) #visual words数量
self.new_patch_size = new_patch_size
self.proj = nn.Conv2D(in_chans, self.in_dim, kernel_size=7, padding=3, stride=stride)
def forward(self, x, pixel_pos):
B, C, H, W = x.shape
assert H == self.img_size and W == self.img_size, \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size}*{self.img_size})."
x = self.proj(x) #利用卷积特征映射
x = F.unfold(x, self.new_patch_size, self.new_patch_size) #类似im2col, 窗口滑动时形成一系列的列向量
x = x.transpose((0, 2, 1)).reshape((B * self.num_patches, self.in_dim, self.new_patch_size, self.new_patch_size))
x = x + pixel_pos # 加上相应的位置编码
x = x.reshape((B * self.num_patches, self.in_dim, -1)).transpose((0, 2, 1))
return x多头注意力模块
多头注意力是集成多个独立的Attention使用。相同的Q,K,V权重,通过线性转换,每个注意力模块负责最终输出序列中一个子空间。通过对输入数据进行注意力编码,然后将注意力结果叠加到原输入数据上。Attention的输入和输出维度一样,仅仅是数值上产生了变化。
多头自注意力计算的主要步骤:
class Attention(nn.Layer):
""" 多头自注意力
"""
def __init__(self, dim, hidden_dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
head_dim = hidden_dim // num_heads
self.head_dim = head_dim
self.scale = head_dim ** -0.5
self.qk = nn.Linear(dim, hidden_dim * 2, bias_attr=qkv_bias)
self.v = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qk = self.qk(x).reshape((B, N, 2, self.num_heads, self.head_dim)).transpose((2, 0, 3, 1, 4))
q, k = qk[0], qk[1] #分离query和key
v = self.v(x).reshape((B, N, self.num_heads, -1)).transpose((0, 2, 1, 3)) #计算v
attn = (q @ k.transpose((0, 1, 3, 2))) * self.scale #缩放点积注意力
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose((0, 2, 1, 3)).reshape((B, N, -1))
x = self.proj(x)
x = self.proj_drop(x)
return x
MLP多层感知机
class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return xDropPath丢弃策略
跟传统的DropOut有什么区别?与普通的DropOut相比,DropPath使得丢弃的数据更多。所谓Path,就是沿着输入单元的第一个轴的通道,并将在这轴上的通道按概率选取丢弃;传统的DropOut,在神经网络中以一定概率随机的暂时丢弃一些单元以及与它们相连的节点,而DropPath则是实现从整个轴上以概率方式随机进行丢弃,丢弃轴上的参数全部置为0, 主要用在多分支结构上。
def drop_path(x, drop_prob=0., training=False):
if drop_prob == 0. or not training:
return x
keep_prob = paddle.to_tensor(1 - drop_prob) #计算保留率
shape = (x.shape[0],) + (1,) * (x.ndim - 1) #计算形状
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype) #生成随机tensor
random_tensor = paddle.floor(random_tensor) # 二值化, 非0即1
output = x.divide(keep_prob) * random_tensor # 权值放缩, drop之后增强保留权值的权重
return output
class DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
TNT Block
该模块是网络结构中的核心部分,由内部和外部transformer组成,分别对visual words embedding间和 visual sentences embedding间进行建模并提取特征。
主要实现步骤:
构建内层Transformer,组网包括Attention, MLP, Linear三个模块。
输出内层tokens。
构建外层Transformer, 利用Linear将内层tokens映射到外层tokens,经过自注意力和多层感知机,输出外层tokens。
class Block(nn.Layer):
""" TNT Block
"""
def __init__(self, dim, in_dim, num_pixel, num_heads=12, in_num_head=4, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
# Inner transformer
self.norm_in = norm_layer(in_dim)
self.attn_in = Attention(
in_dim, in_dim, num_heads=in_num_head, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop)
self.norm_mlp_in = norm_layer(in_dim)
self.mlp_in = Mlp(in_features=in_dim, hidden_features=int(in_dim * 4),
out_features=in_dim, act_layer=act_layer, drop=drop) self.norm1_proj = norm_layer(in_dim)
self.proj = nn.Linear(in_dim * num_pixel, dim, bias_attr=True)
# Outer transformer
self.norm_out = norm_layer(dim)
self.attn_out = Attention(
dim, dim, num_heads=num_heads, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm_mlp = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio),
out_features=dim, act_layer=act_layer, drop=drop)
def forward(self, inner_tokens, outer_tokens):
# inner
inner_tokens = inner_tokens + self.drop_path(self.attn_in(self.norm_in(inner_tokens)))
inner_tokens = inner_tokens + self.drop_path(self.mlp_in(self.norm_mlp_in(inner_tokens)))
# outer
B, N, C = outer_tokens.shape
outer_tokens[:, 1:] = outer_tokens[:, 1:] + self.proj(self.norm1_proj(inner_tokens).reshape((B, N - 1, -1)))
outer_tokens = outer_tokens + self.drop_path(self.attn_out(self.norm_out(outer_tokens)))
outer_tokens = outer_tokens + self.drop_path(self.mlp(self.norm_mlp(outer_tokens)))
return inner_tokens, outer_tokens
TNT模型组网
将上面的网络模块按照模型框架组织构造起来,流程大致如下:
class TNT(nn.Layer):
"""TNT"""
def __init__(
self,
img_size=224,
patch_size=16,
in_chans=3,
num_classes=1000,
embed_dim=384,
in_dim=24,
depth=12,
num_heads=6,
in_num_head=4,
mlp_ratio=4.,
qkv_bias=False,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
norm_layer=nn.LayerNorm,
first_stride=4):
super(TNT, self).__init__()
assert embed_dim % num_heads == 0
assert img_size % patch_size == 0
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(img_size, patch_size, in_chans, in_dim, first_stride)
num_patches = self.patch_embed.num_patches
self.num_patches = num_patches
new_patch_size = self.patch_embed.new_patch_size
num_pixel = new_patch_size ** 2
self.norm1_proj = norm_layer(num_pixel * in_dim)
self.proj = nn.Linear(num_pixel * in_dim, embed_dim)
self.norm2_proj = norm_layer(embed_dim)
self.cls_token = self.create_parameter(shape=(1, 1, embed_dim), default_initializer=zeros_)
self.patch_pos = self.create_parameter(shape=(1, self.num_patches + 1, embed_dim), default_initializer=zeros_)
self.pixel_pos = self.create_parameter(shape=(1, in_dim, new_patch_size, new_patch_size), default_initializer=zeros_)
self.pos_drop = nn.Dropout(1. - drop_rate)
dpr = list(np.linspace(0, drop_rate, depth))
blocks = []
for i in range(depth):
blocks.append(Block(
dim=embed_dim, in_dim=in_dim, num_pixel=num_pixel, num_heads=num_heads, in_num_head=in_num_head,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[i], norm_layer=norm_layer))
self.blocks = nn.LayerList(blocks)
self.norm = norm_layer(embed_dim)
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else Identity()
trunc_normal_(self.cls_token)
trunc_normal_(self.patch_pos)
trunc_normal_(self.pixel_pos)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else Identity()
def forward_features(self, x):
B = x.shape[0]
inner_tokens = self.patch_embed(x, self.pixel_pos) #visual words间的嵌入
#将inner_tokens线性映射到outer_tokens
outer_tokens = self.norm2_proj(self.proj(self.norm1_proj(inner_tokens.reshape((B, self.num_patches, -1)))))
#拼接分类token和patch_embed
outer_tokens = paddle.concat((self.cls_token.expand((B, -1, -1)), outer_tokens), axis=1)
outer_tokens = outer_tokens + self.patch_pos #加上patch的位置编码
outer_tokens = self.pos_drop(outer_tokens) #普通的nn.dropout丢弃策略
#迭代多个TNT Blocks
for blk in self.blocks:
inner_tokens, outer_tokensd = blk(inner_tokens, outer_tokens)
outer_tokens = self.norm(outer_tokens) #归一化
return outer_tokens[:, 0] #cls_token用于分类
def forward(self, x):
x = self.forward_features(x)
x = self.head(x) #全连接到类别数
return x
TNT复现结果
将PyTorch权重导出为飞桨权重文件,使用固定的网络输入,例如全是1, 对比二者的输出结果,基本保持一致:
使用ImageNet验证集数据,对复现的飞桨网络结构进行验证,最终达到作者提出的精度。
model = TNT(num_classes=1000)
model_state_dict = paddle.load("/home/aistudio/work/tnt.pdparams")
model.set_state_dict(model_state_dict)
run_model = paddle.Model(model)
optim = paddle.optimizer.SGD(learning_rate=0.0001, weight_decay=6e-5, parameters=run_model.parameters())
run_model.prepare(optimizer= optim,
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
#模型验证
run_model.evaluate(val_dataset, batch_size=32, verbose=1)
完整的复现代码:
https://aistudio.baidu.com/aistudio/projectdetail/1949371
https://github.com/thunder95/paddle_papers_reproduce
基于TNT模型
训练新冠肺炎CT
中重症新冠肺炎患者的肺部可能会出现磨玻璃影,铺路石症等症状,这在CT检查中容易判别。因此在这个项目中使用复现好的TNT模型对新冠肺炎、其他病毒性肺炎 和 正常人三个类别的CT检查结果进行了分类。
使用covid19-radiography-database 数据集,该数据集包含220张从多种渠道收集的新冠肺炎患者CT影像,1346张其他病毒性肺炎患者CT影像和1342张正常人CT影像。本项目将数据集按照8:2比例划分成训练集和验证集。
继承Paddle.io的Dataset,构造数据读取器。
class CatDataset(Dataset):
def __init__(self, mode='train', split_ratio=0.8):
super(CatDataset, self).__init__()
data_transforms = T.Compose([
T.Resize(480, interpolation='bicubic'),
T.ToTensor(),
T.Normalize()
])
train_data_folder = DatasetFolder(train_image_dir, transform=data_transforms)
eval_data_folder = DatasetFolder(eval_image_dir, transform=data_transforms)
self.mode = mode
if self.mode == 'train':
self.data = train_data_folder
elif self.mode == 'eval':
self.data = eval_data_folder
def __getitem__(self, index):
data = self.data[index][0].astype('float32')
if self.mode == 'test':
return data
else:
label = np.array([self.data[index][1]]).astype('int64')
return data, label
基于飞桨的高层API,只需短短的几十行代码就可以非常方便的进行训练和测试。
import paddle
from tnt import TNT
from dataset import CatDataset
train_dataset = CatDataset("train") #加载训练集
val_dataset = CatDataset("eval") #加载测试集
callback = paddle.callbacks.EarlyStopping(patience=50, verbose=0, min_delta=0.0001) #回调函数
model = TNT( num_classes=3, img_size=480) #初始化模型, 修改输入大小
run_model = paddle.Model(model)
optim = paddle.optimizer.Adam(learning_rate=0.00005, weight_decay=6e-5, parameters=run_model.parameters())
run_model.prepare(optimizer= optim,
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy(topk=(1, 5)))
run_model.fit(train_dataset, val_dataset, epochs=100, batch_size=32, log_freq=200,
save_freq=10,
save_dir="./checkpoints", callbacks=callback, verbose=1)
run_model.predict(val_dataset) #模型预测
新冠肺炎CT数据集在传统网络如ResNet, MobileNet下表现得更加好,通常不经过仔细调参,精度就能达到97%以上。TNT网络结构相比更加复杂,训练过程中更容易过拟合,很难用更好的trick去调优,精度达到90%就很难再有所提升。本次训练过程基于飞桨开源框架v 2.0高层API完成,只是为了验证TNT网络在分类任务上的能力,没有经过仔细的调参优化,小伙伴可以自己多加尝试。
完整代码地址:
https://aistudio.baidu.com/aistudio/projectdetail/2317372
参考资料:
https://aistudio.baidu.com/aistudio/projectdetail/463184
https://aistudio.baidu.com/aistudio/projectdetail/1966894
https://github.com/PaddlePaddle/Paddle
https://www.paddlepaddle.org.cn/documentation/docs/zh/tutorial/quick_start/high_level_api/high_level_api.html#api
长按下方二维码立即
Star
更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
欢迎在飞桨论坛讨论交流~~
http://discuss.paddlepaddle.org.cn