PPMA(Paddle Model Analysis)是一个基于飞桨实现的一个模型分析小工具,它以极简主义为特色,高度封装了飞桨代码以便让大家用最少的代码来完成模型的分析,目前所支持的功能有ImageNet精度验证、可视化图片Top5预测类别、测试模型Params、Throughput、类激活图可视化(CAM)、测试时数据增强(TTA)等,在这里你可以用最少三行代码来实现想要的功能。
其中ImageNet精度验证在计算Top5准确率上用了飞桨的API(paddle.metric.Accuracy),减少了代码的编写。类激活图可视化CAM迁移了pytorch-grad-cam项目,同时参考了飞桨InterpretDL库的几行代码(这里推荐一下IntepretDL,它是基于飞桨的可解释性算法库,不仅包含可视化算法,还能从数据集和训练过程的角度去解释模型),测试时数据增强TTA迁移了ttach项目,用飞桨代码进行高阶封装。
设计思路
【为什么设计】
图像分类作为CV的基础任务,在ImageNet上训练的权重能更好迁移到下游任务,比如目标检测、语义分割等。所以分析基于ImageNet上训练的模型有助于我们能更好了解掌握模型的优劣,正是基于此,本项目简洁封装了飞桨基础代码,以便用户能用至少三行代码来完成对模型的分析。
【怎么设计】
目前有很多优秀的库拥有着简洁易用的体验,比如fastai、keras、scikit-learn,以及飞桨自家的PaddleHapi,这些都是对复杂的代码进行封装,大大降低了用户上手难度以及用户学习成本,同时高度的封装带来的是灵活性、自定义性的下降,如何去权衡这两个矛盾是一个需要思考的问题。
在尝试体验上述工具后,总结了对于一个工具是否简洁易用需要看以下两点:
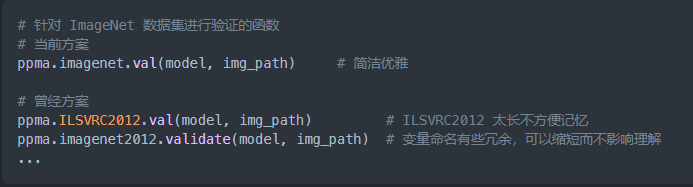
对函数的命名是一个需要推敲磨打的技术活,一方面函数命名尽量简单直观,做到用户自然记忆不需要查函数名,这就要求尽量命名短,单词意思尽量贴合使用场景。一方面又要避免与用户变量命名习惯冲突,比如"img"这个命名很常见,大多数用来表示一张图片,故命名函数时尽可能避开它,这能降低因为命名问题造成的error。
API的设计
高度封装以及灵活性是一对矛盾。比如具有高度封装的Keras,其灵活性和自定义性没有Pytorch那么好。在本项目(模型分析)上,因为我们只是针对具体任务进行分析,其自定义性需求并不是那么高,我们可以适当提高封装性,同时支持更多的默认参数,用户可以通过修改默认参数来完成特定需求,比如CAM增加自定义标签(默认是网络输出的标签)查看相应激活图。
如何使用
AI Studio在线运行本项目:
https://aistudio.baidu.com/aistudio/projectdetail/2143665
pip install ppma
训练集:1,281,167张图片+标签
验证集:50,000张图片+标签
测试集:100,000张图片,
它是图像分类任务的试金石,基于此数据训练一个很不错的分类网络,可以良好迁移到下游任务比如检测、分割,可以说这个数据集极大推动了计算机视觉的发展。
"ImageNet改变了AI领域人们对数据集的认识,人们真正开始意识到它在研究中的地位,就像算法一样重要",李飞飞教授说。
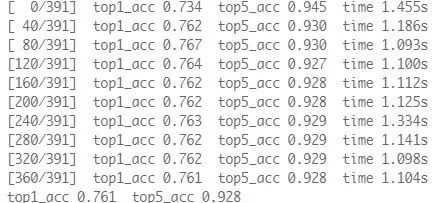
所以,当我们用ILSVRC2012训练好模型后,或者通过Pytorch、Tensorflow进行模型转换以及权重转换后,我们需要对该模型进行精度验证从而了解这个分类网络的性能。
先准备数据集结构如下,数据集已上传AI Studio:
https://aistudio.baidu.com/aistudio/datasetdetail/96753
data/ILSVRC2012
├─ ILSVRC2012_val_00000001.JPEG
├─ ILSVRC2012_val_00000002.JPEG
├─ ILSVRC2012_val_00000003.JPEG
├─ ...
├─ ILSVRC2012_val_00050000.JPEG
└─ val.txt # target
准备好数据集后,运行以下代码
import ppma
import paddle
model = paddle.vision.models.resnet50(pretrained=True) # 可以替换自己的模型
data_path = "data/ILSVRC2012" # 数据路径
ppma.imagenet.val(model, data_path) # 进行验证
可以看见,我们只需要三行代码,即可完成对ImageNet数据集的验证
测试图片 Top5 类别
基于ImageNet数据集,我们可以对一张图片进行分类,利用PPMA可以快速得到图像分类前5个最可能的分类结果以及相应的精度
import ppma
import paddle
img_path = 'test.jpg' # 图片路径
model = paddle.vision.models.resnet50(pretrained=True) # 可以替换自己的模型
ppma.imagenet.test_img(model, img_path)
在这个示例中我们只需要准备图像路径和模型,一键放入函数里面,无过多的冗余,简单直观,输入效果如下
测试图片:
模型预测:
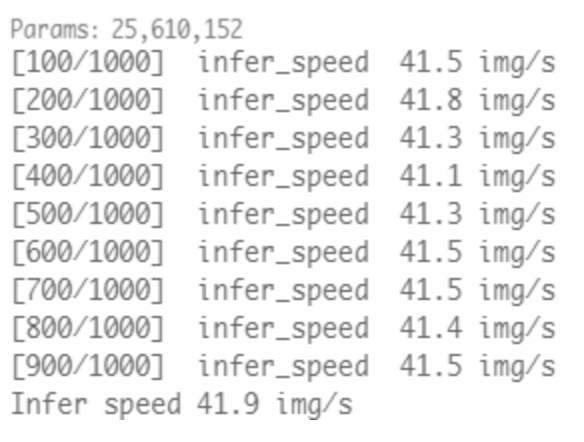
一个模型除了精度指标之外,还有参数量(Params)、吞吐量(Throughput)等,以下是如何对于模型进行检测参数量和吞吐量(测试Throughput时候,前几轮因为不稳定要进行warmup,这里设置10iter)
import ppma
import paddle
model = paddle.vision.models.resnet50() # 可以替换自己的模型
# Params -- depend model
param = ppma.tools.param(model)
print('Params:{:,}'.format(param))
# Thoughtout -- depend model and resolution
ppma.tools.throughput(model, image_size=224)
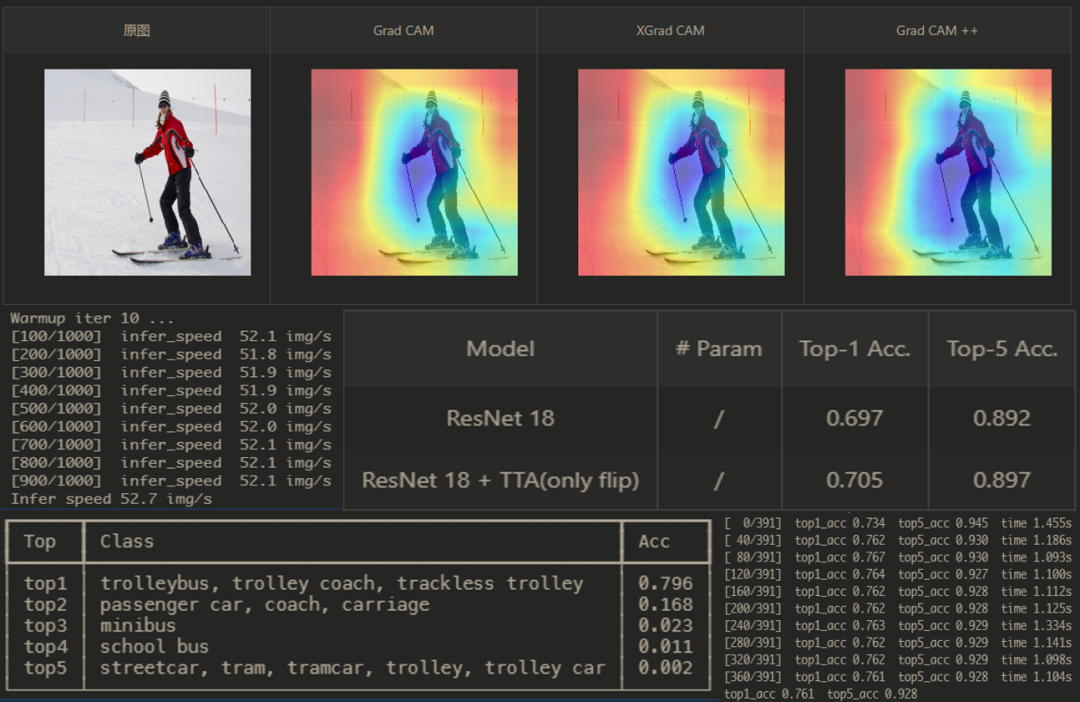
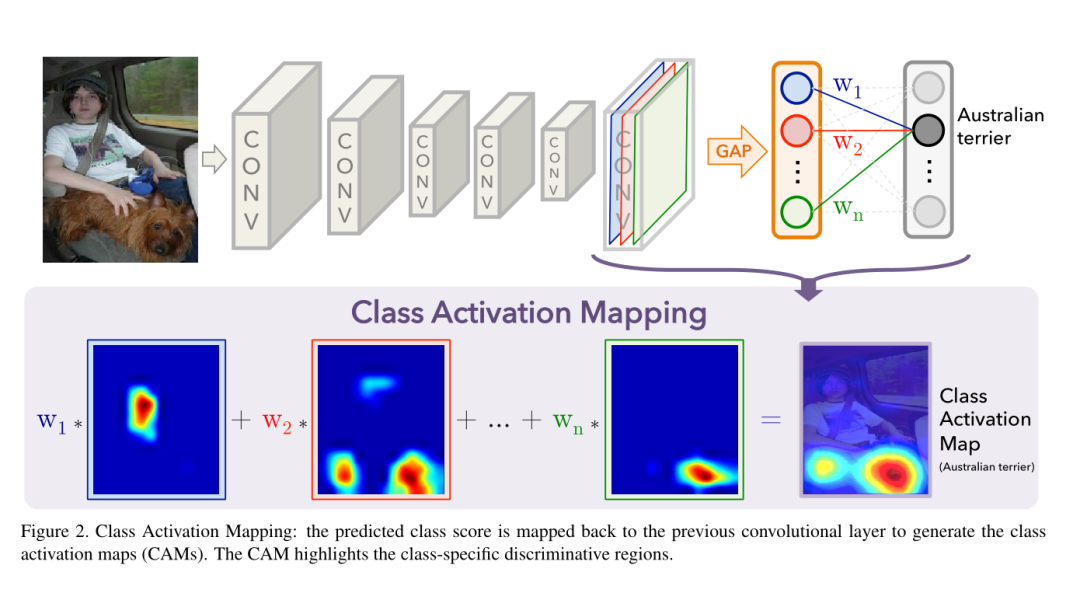
深度学习的可解释一直是讨论的热点,尤其是在分类和检测等视觉性任务,我们要了解网络学到了什么知识以及哪些没有学习,这就用到了CAM。它可用于定位图像中与类别相关的区域,可视化以此来观察分类的高响应是否落在目标的核心部位上,CAM的具体原理如下。
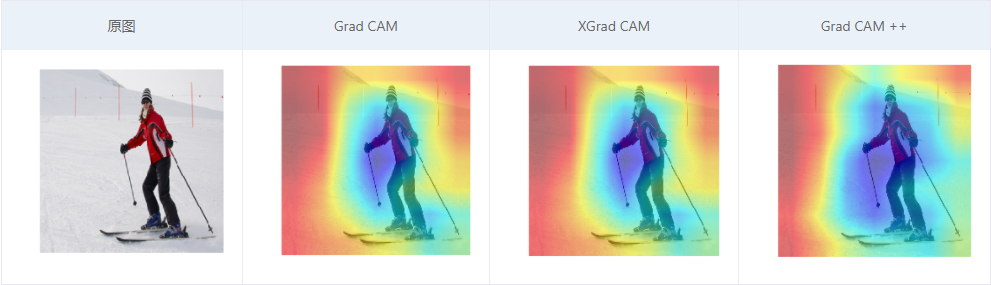
PPMA基于热门的开源项目进行复现,对代码进行了更高的封装,并提供了基于CAM的GradCAM、GradCAM++、XGradCAM三种可视化方法,使用方法如下所示。
import paddle
import matplotlib.pyplot as plt
from ppma import cam
img_path = 'img1.jpg' # 图片路径
model = paddle.vision.models.resnet18(pretrained=True) # 模型定义
target_layer = model.layer4[-1] # 提取模型某层的激活图
cam_extractor = cam.GradCAMPlusPlus(model, target_layer) # 支持 GradCAM、XGradCAM、GradCAM++
# 提取激活图
# label设置为None,默认标签用该网络的ImageNet top1类别
activation_map = cam_extractor(img_path, label=None)
plt.imshow(activation_map)
plt.axis('off')
plt.show()
# 与原图融合
cam_image = cam.overlay(img_path, activation_map)
plt.imshow(cam_image)
plt.axis('off')
plt.show()
CAM里面有两个很重要的参数,分别是target_layer、label,target_layer是提取网络某个层梯度作为激活,不同的网络结构提取的层不同,对于CNN网络,大部分是在网络最后的avgpool层之前,而label是待测试的标签,默认为None,即用网络的预测标签,也可以自己设置图片的标签以此来看模型是否学习到该学习的地方。
特别说明:预计下一版本的飞桨会改进获取模型内部梯度的方式,计算梯度的效率会大幅提高,到时候对更大型的CNN网络以及ViT、MLP等前沿模型会提供更好的支持,敬请关注!于此同时,这里推荐一个基于飞桨的可解释性算法库InterpretDL,目前已集成十余种不同的可解释性算法。除了可视化算法,InterpretDL还能从数据集和训练过程的角度去解释模型,推荐大家去使用。
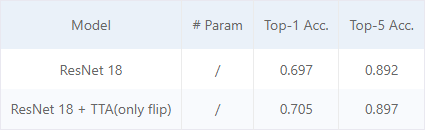
TTA (Test Time Augmentation)
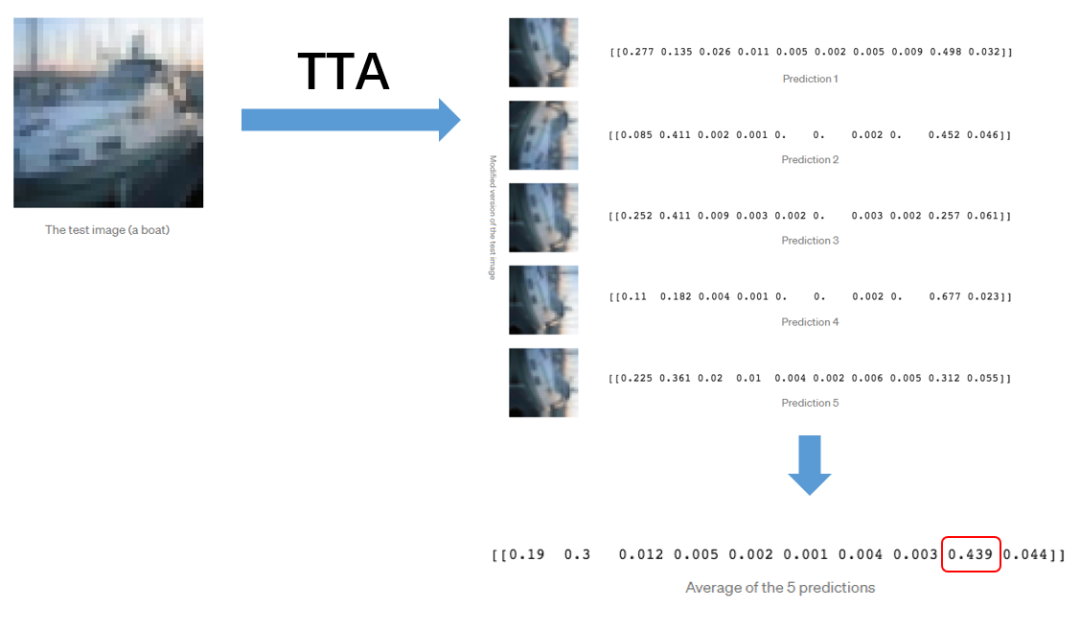
TTA,测试时间数据增强,是在模型测试时对数据进行增强以达到提升模型性能的一种Trick。
与数据增强对训练集的方式类似,测试时间数据增强的目的是对测试图像进行不同方式的修改。因此,我们将向训练好的模型展示几次增强后的图像,而不是只展示一次常规的、"干净的 "图像。然后,我们将对每张相应图像的预测进行平均,并将其作为模型的最终预测结果。
本项目基于热门开源项目做了简化,提升了易用性,使用如下:
import paddle
import ppma
import ppma.tta as tta
model = paddle.vision.resnet18(pretrained=True)
model_tta = tta.ClassTTA(model, tta.aliases.hflip_transform()) # 生成 TTA 模型
ppma.imagenet.val(model_tta, "data/ILSVRC2012")
参考资料
InterpretDL:基于飞桨的模型可解释性算法开源库,目前集成了十余种主流的可解释性算法。InterpretDL遵循『Plug-and-Play』的设计理念,用户无需修改模型;所有算法使用统一API接口,方便用户快速上手;并对每种算法提供单独的教程与解析,帮助用户理解、选择合适的算法。
如果您想详细了解更多InterpretDL的相关内容,大家可以直接前往Github地址获得完整开源项目代码,记得Star收藏支持一下哦:
https://github.com/PaddlePaddle/InterpretDL
长按下方二维码立即
Star

更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
欢迎在飞桨论坛讨论交流~~
http://discuss.paddlepaddle.org.cn
PPMA(Paddle Model Analysis)是一个基于飞桨实现的一个模型分析小工具,它以极简主义为特色,高度封装了飞桨代码以便让大家用最少的代码来完成模型的分析,目前所支持的功能有ImageNet精度验证、可视化图片Top5预测类别、测试模型Params、Throughput、类激活图可视化(CAM)、测试时数据增强(TTA)等,在这里你可以用最少三行代码来实现想要的功能。
其中ImageNet精度验证在计算Top5准确率上用了飞桨的API(paddle.metric.Accuracy),减少了代码的编写。类激活图可视化CAM迁移了pytorch-grad-cam项目,同时参考了飞桨InterpretDL库的几行代码(这里推荐一下IntepretDL,它是基于飞桨的可解释性算法库,不仅包含可视化算法,还能从数据集和训练过程的角度去解释模型),测试时数据增强TTA迁移了ttach项目,用飞桨代码进行高阶封装。
设计思路
【为什么设计】
图像分类作为CV的基础任务,在ImageNet上训练的权重能更好迁移到下游任务,比如目标检测、语义分割等。所以分析基于ImageNet上训练的模型有助于我们能更好了解掌握模型的优劣,正是基于此,本项目简洁封装了飞桨基础代码,以便用户能用至少三行代码来完成对模型的分析。
【怎么设计】
目前有很多优秀的库拥有着简洁易用的体验,比如fastai、keras、scikit-learn,以及飞桨自家的PaddleHapi,这些都是对复杂的代码进行封装,大大降低了用户上手难度以及用户学习成本,同时高度的封装带来的是灵活性、自定义性的下降,如何去权衡这两个矛盾是一个需要思考的问题。
在尝试体验上述工具后,总结了对于一个工具是否简洁易用需要看以下两点:
对函数的命名是一个需要推敲磨打的技术活,一方面函数命名尽量简单直观,做到用户自然记忆不需要查函数名,这就要求尽量命名短,单词意思尽量贴合使用场景。一方面又要避免与用户变量命名习惯冲突,比如"img"这个命名很常见,大多数用来表示一张图片,故命名函数时尽可能避开它,这能降低因为命名问题造成的error。
API的设计
高度封装以及灵活性是一对矛盾。比如具有高度封装的Keras,其灵活性和自定义性没有Pytorch那么好。在本项目(模型分析)上,因为我们只是针对具体任务进行分析,其自定义性需求并不是那么高,我们可以适当提高封装性,同时支持更多的默认参数,用户可以通过修改默认参数来完成特定需求,比如CAM增加自定义标签(默认是网络输出的标签)查看相应激活图。
如何使用
AI Studio在线运行本项目:
https://aistudio.baidu.com/aistudio/projectdetail/2143665
pip install ppma
训练集:1,281,167张图片+标签
验证集:50,000张图片+标签
测试集:100,000张图片,
它是图像分类任务的试金石,基于此数据训练一个很不错的分类网络,可以良好迁移到下游任务比如检测、分割,可以说这个数据集极大推动了计算机视觉的发展。
"ImageNet改变了AI领域人们对数据集的认识,人们真正开始意识到它在研究中的地位,就像算法一样重要",李飞飞教授说。
所以,当我们用ILSVRC2012训练好模型后,或者通过Pytorch、Tensorflow进行模型转换以及权重转换后,我们需要对该模型进行精度验证从而了解这个分类网络的性能。
先准备数据集结构如下,数据集已上传AI Studio:
https://aistudio.baidu.com/aistudio/datasetdetail/96753
data/ILSVRC2012
├─ ILSVRC2012_val_00000001.JPEG
├─ ILSVRC2012_val_00000002.JPEG
├─ ILSVRC2012_val_00000003.JPEG
├─ ...
├─ ILSVRC2012_val_00050000.JPEG
└─ val.txt # target
准备好数据集后,运行以下代码
import ppma
import paddle
model = paddle.vision.models.resnet50(pretrained=True) # 可以替换自己的模型
data_path = "data/ILSVRC2012" # 数据路径
ppma.imagenet.val(model, data_path) # 进行验证
可以看见,我们只需要三行代码,即可完成对ImageNet数据集的验证
测试图片 Top5 类别
基于ImageNet数据集,我们可以对一张图片进行分类,利用PPMA可以快速得到图像分类前5个最可能的分类结果以及相应的精度
import ppma
import paddle
img_path = 'test.jpg' # 图片路径
model = paddle.vision.models.resnet50(pretrained=True) # 可以替换自己的模型
ppma.imagenet.test_img(model, img_path)
在这个示例中我们只需要准备图像路径和模型,一键放入函数里面,无过多的冗余,简单直观,输入效果如下
测试图片:
模型预测:
一个模型除了精度指标之外,还有参数量(Params)、吞吐量(Throughput)等,以下是如何对于模型进行检测参数量和吞吐量(测试Throughput时候,前几轮因为不稳定要进行warmup,这里设置10iter)
import ppma
import paddle
model = paddle.vision.models.resnet50() # 可以替换自己的模型
# Params -- depend model
param = ppma.tools.param(model)
print('Params:{:,}'.format(param))
# Thoughtout -- depend model and resolution
ppma.tools.throughput(model, image_size=224)
深度学习的可解释一直是讨论的热点,尤其是在分类和检测等视觉性任务,我们要了解网络学到了什么知识以及哪些没有学习,这就用到了CAM。它可用于定位图像中与类别相关的区域,可视化以此来观察分类的高响应是否落在目标的核心部位上,CAM的具体原理如下。
PPMA基于热门的开源项目进行复现,对代码进行了更高的封装,并提供了基于CAM的GradCAM、GradCAM++、XGradCAM三种可视化方法,使用方法如下所示。
import paddle
import matplotlib.pyplot as plt
from ppma import cam
img_path = 'img1.jpg' # 图片路径
model = paddle.vision.models.resnet18(pretrained=True) # 模型定义
target_layer = model.layer4[-1] # 提取模型某层的激活图
cam_extractor = cam.GradCAMPlusPlus(model, target_layer) # 支持 GradCAM、XGradCAM、GradCAM++
# 提取激活图
# label设置为None,默认标签用该网络的ImageNet top1类别
activation_map = cam_extractor(img_path, label=None)
plt.imshow(activation_map)
plt.axis('off')
plt.show()
# 与原图融合
cam_image = cam.overlay(img_path, activation_map)
plt.imshow(cam_image)
plt.axis('off')
plt.show()
CAM里面有两个很重要的参数,分别是target_layer、label,target_layer是提取网络某个层梯度作为激活,不同的网络结构提取的层不同,对于CNN网络,大部分是在网络最后的avgpool层之前,而label是待测试的标签,默认为None,即用网络的预测标签,也可以自己设置图片的标签以此来看模型是否学习到该学习的地方。
特别说明:预计下一版本的飞桨会改进获取模型内部梯度的方式,计算梯度的效率会大幅提高,到时候对更大型的CNN网络以及ViT、MLP等前沿模型会提供更好的支持,敬请关注!于此同时,这里推荐一个基于飞桨的可解释性算法库InterpretDL,目前已集成十余种不同的可解释性算法。除了可视化算法,InterpretDL还能从数据集和训练过程的角度去解释模型,推荐大家去使用。
TTA (Test Time Augmentation)
TTA,测试时间数据增强,是在模型测试时对数据进行增强以达到提升模型性能的一种Trick。
与数据增强对训练集的方式类似,测试时间数据增强的目的是对测试图像进行不同方式的修改。因此,我们将向训练好的模型展示几次增强后的图像,而不是只展示一次常规的、"干净的 "图像。然后,我们将对每张相应图像的预测进行平均,并将其作为模型的最终预测结果。
本项目基于热门开源项目做了简化,提升了易用性,使用如下:
import paddle
import ppma
import ppma.tta as tta
model = paddle.vision.resnet18(pretrained=True)
model_tta = tta.ClassTTA(model, tta.aliases.hflip_transform()) # 生成 TTA 模型
ppma.imagenet.val(model_tta, "data/ILSVRC2012")
参考资料
InterpretDL:基于飞桨的模型可解释性算法开源库,目前集成了十余种主流的可解释性算法。InterpretDL遵循『Plug-and-Play』的设计理念,用户无需修改模型;所有算法使用统一API接口,方便用户快速上手;并对每种算法提供单独的教程与解析,帮助用户理解、选择合适的算法。
如果您想详细了解更多InterpretDL的相关内容,大家可以直接前往Github地址获得完整开源项目代码,记得Star收藏支持一下哦:
https://github.com/PaddlePaddle/InterpretDL
长按下方二维码立即
Star
更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
欢迎在飞桨论坛讨论交流~~
http://discuss.paddlepaddle.org.cn