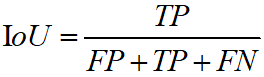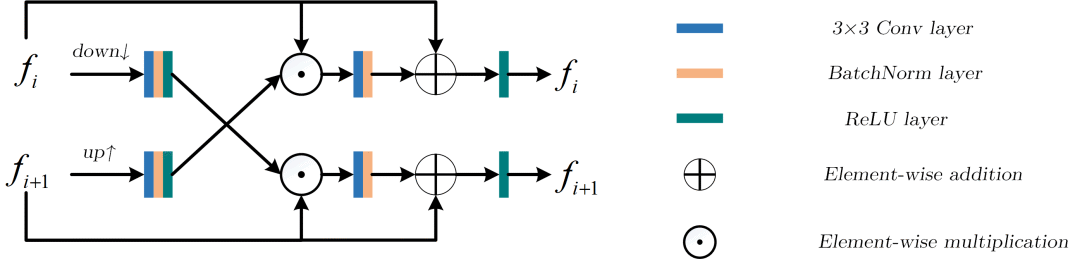赛题背景
监督学习模型的优异性能要以大量标注数据作为支撑,可现实中获得数量可观的标注数据十分耗费人力物力。于是,半监督学习逐渐成为深度学习领域的热门研究方向,只需要少量标注数据就可以完成模型训练过程,更适用于现实场景中的各种任务。
比赛任务
本次比赛采用IoU曲线作为评价指标,要求选手基于少量有标注数据训练模型,使分类网络具有目标定位能力,实现半监督目标定位任务。更多详细信息,详见比赛页:
https://aistudio.baidu.com/aistudio/competition/detail/78
竞赛算法介绍
本次比赛属于语义分割的范畴,确切来说是二分类语义分割,即将背景像素点归类为0(黑色),物体像素点归类为255(白色)。目前语义分割领域最为常用的就是以端到端为目标的编码器-解码器架构,以实现像素级别的输出,从而提高分割的精度。
实现这一目标的方法为全卷积神经网络(Fully Convolutional Network, FCN),见图2,全卷积神经网络中的编码器起到提取不同尺度特征信息的作用,通常由分类网络如ResNet、VGG提取输入图片的特征及语义信息, 这样的分类网络又被称为FCN中的骨干网络。
提取的不同尺度特征具有不同的语义信息,浅层特征具有较大的分辨率以及明显的物体轮廓信息,但也包含了复杂的背景噪音,深层特征具有较小的分辨率以及探测物体的位置信息,但小分辨率往往带来了粗糙的物体边界,而语义分割则需要精细的物体边界。因此,解码器就实现了深层浅层特征的融合,以定位具有清晰边界的目标物体。
因此,本次参赛采用的是以全卷积神经网络为基础的目标定位算法。
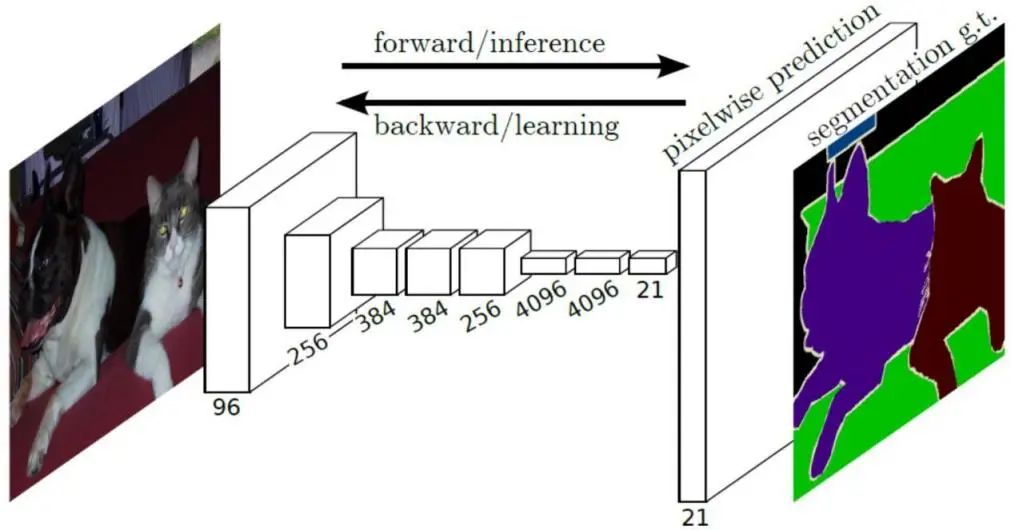 图2. 全卷积神经网络
图2. 全卷积神经网络
冠军团队方案详解
团队成员
张晋(上海应用技术大学研究生)、佟兴宇(中国移动-人工智能工程师)、张九鑫(东北大学研究生)、李吉平(迈瑞生物-监护算法工程师)、李想(上海应用技术大学研究生)。其中,张晋和佟兴宇负责模型的搭建和调试,张九鑫、李吉平和李想三位成员负责分析数据以及提出模型改进方法。
赛题数据分析
训练数据集包括50,000幅像素级有标注的图像,共包含500个类,每个类100幅图像;
总共为50,000张图片,经过分析后可以看出,赛题要求为定位目标的位置,而赛题数据给出的是500个类别,所以并不能把赛题归为500类分类问题。而应归类为50000张图片前景与背景的2分类问题。
赛题要求将图片中的目标定位出来,与显著目标检测任务相同的是,该赛题的某些图片中存在多个目标,但并不是所有目标都是检测目标,从图3可以看到,多条鱼的图像中,只有三条在标签图中存在。因此,网络的搭建中如果加入注意力模块则会更好地辅助网络寻找检测目标。
 图3. 训练集图片
图3. 训练集图片
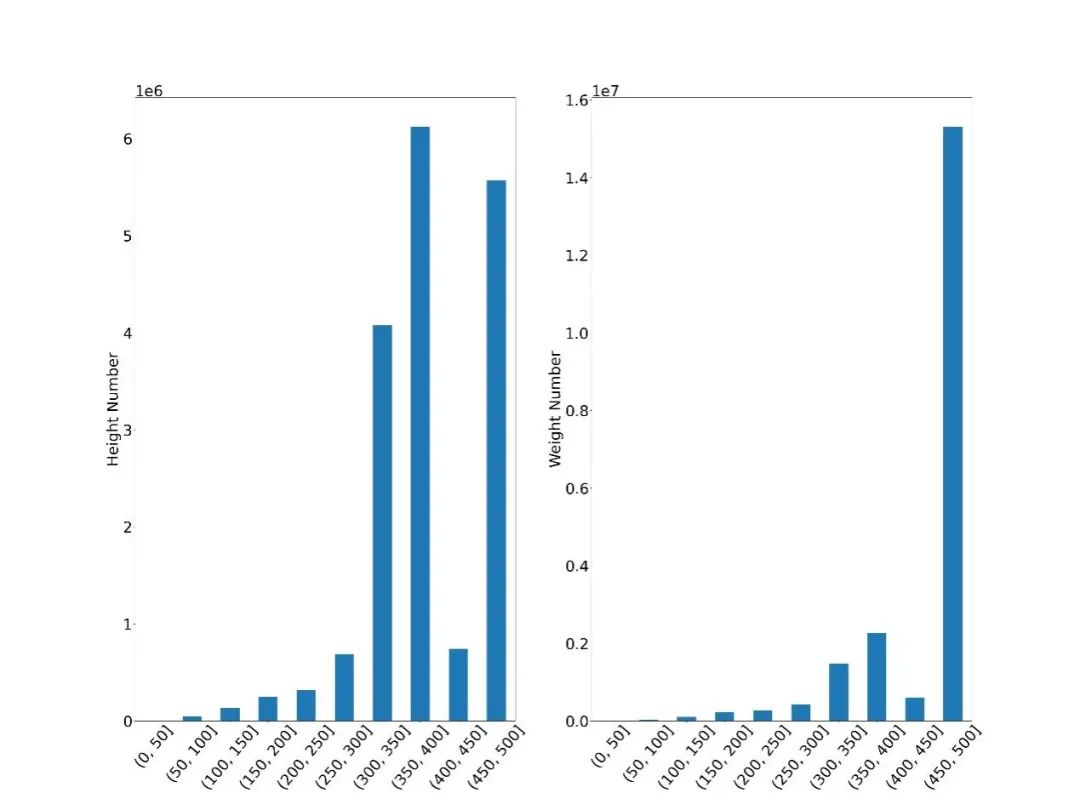
另外,我们对图片的尺寸做了大致的统计分析,如图4,横坐标为尺寸区间,纵坐标为在该尺寸区间的图片数量,可以看出图片高度在300-500居多,宽度在450-500居多。并计算了平均尺寸,大约为(384, 448),在数据处理过程中图片可以转换尺寸到均值尺寸以获得更全面的图片信息。
评价指标分析
本次比赛使用IoU曲线作为评价指标,即利用预测目标的定位概率图,计算不同阈值下预测结果与真实目标之间的IoU分数,最后取一个最高点作为最终分数。IoU的计算公式为:
对于本次比赛,图像处理的输出应该为经过sigmoid激活函数处理后归一化到[0,1]范围内的float32小数。存为图像则需要再乘255,并转化为int类型的灰度图。提交测试分数时,会根据[0, 255] 选择255个阈值来进行计算,大于阈值的设为正例,小于阈值的设为负例,从而计算IoU分数,选择最高的IoU分数作为成绩。
若在处理过程中自定阈值将图像处理为只存在0和255的像素点,即黑白图,则会导致在各个判断阈值之下的IoU得分相同,从而无法选择出最高的IoU分数。这是影响比赛得分的一个关键点。
整体思路分析
数据分析:举办方提供了50,000幅像素级有标注的图像作为训练集,并没有提供额外的验证集,因此我们在训练集的基础上划分4%的数据即2000张图片作为验证集。采用了固定随机种子的方法保证每次启动训练都会划分到相同的验证集与训练集。
模型分析:在训练的过程中,我们发现不同模型融合的效果图可以有效捕捉到图像的不同细节信息,从而提高IoU分数。最终,我们采用3种不同骨干网络和2种不同解码网络构建的4个模型进行融合,并分配不同的权重,达到B榜的最终成绩。
代码实现:
在整个比赛过程中,我们团队使用飞桨以及相关套件PaddleClas和PaddleSeg进行模型的搭建、损失函数的设计、数据的封装处理以及评价指标的实现。PaddleClas提供了大量预训练的图像分类网络,并通过半监督知识蒸馏的方法提高了部分模型的准确率,这为我们后面获得高分提供了坚实的基础。
我们在PaddleClas中选择了三个骨干网络:Res2Net200_vd_26w_4s_ssld、ResNeXt101_32x16d_wsl
和SwinTransformer_large_patch4_window12_384,作为骨干网络。这三个骨干网络都是PaddleClas实现的具有高准确率的分类网络。
PaddleSeg可以快速实现语义分割任务。模型主要由飞桨提供的深度学习模块API“paddle.nn”实现,数据处理由飞桨提供的数据处理模块API”paddle.io.Dataset”实现,并将这些模块放到PaddleSeg中方便后续调参训练预测等操作。
另外,在阅读PaddleSeg的源码时,特别惊喜的发现PaddleSeg的预测代码额外提供了多尺度预测以及翻转预测等操作,我们使用了多尺度预测以及水平翻转这些方法进行预测,以加强最终预测结果的图像边缘点的置信度。
骨干网络的选择
如上所述,FCN由编码器(骨干网络)和解码器组成,图像分类网络经常被选为骨干网络,因为图像分类网络能提取更好的图片信息,以方便在后续的特征融合中生成高质量的效果图。
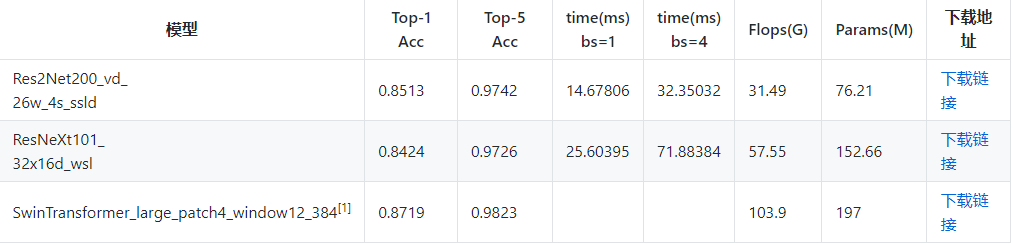
因此我们在PaddleClas中的ImageNet预训练模型库选择Top-1 Acc分别为0.851、0.8424和0.8719的Res2Net200_vd_26w_4s_ssld(以下简称为Res2Net200)、ResNeXt101_32x16d_wsl(以下简称为ResNeXt101)
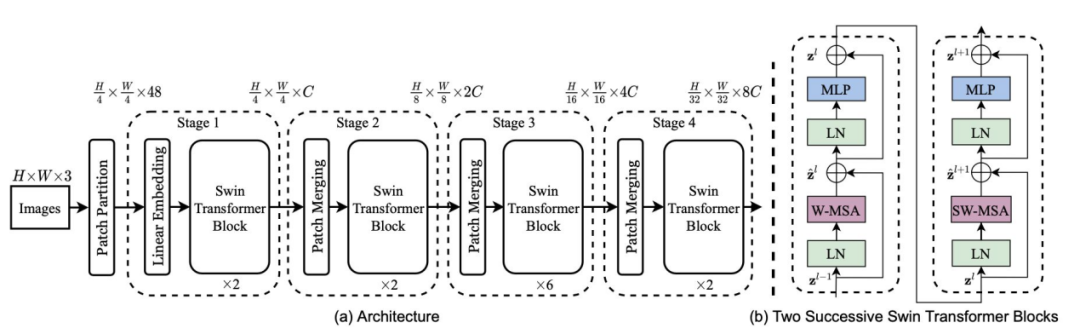
和SwinTransformer_large_patch4_window12_384 (以下简称为SwinT384) 三种骨干网络作测试。
其中Res2Net和ResNeXt均为ResNet的变体形式,Swin Transformer是一种新的视觉Transformer网络,可以用作计算机视觉领域的通用骨干网络。
可以说,骨干网络的选取是决定成败最为关键的一步,骨干网络提取的特征直接影响到后续特征处理以及特征融合的效果,间接影响到结果图的质量。
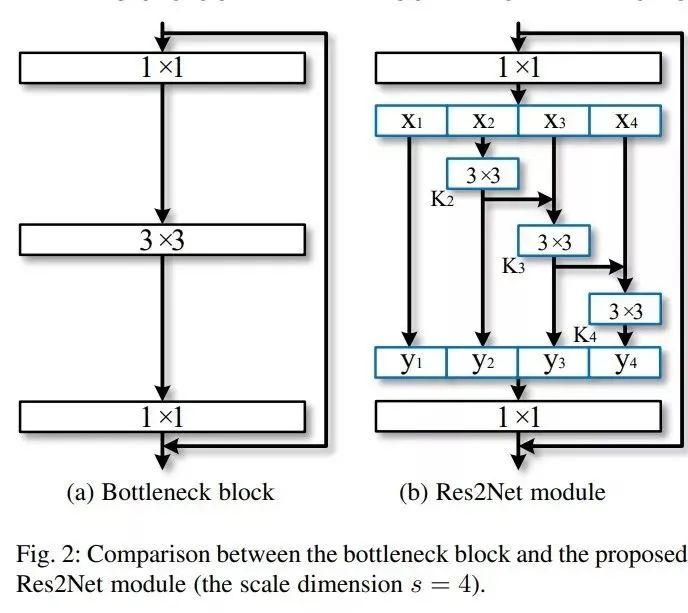
Res2Net
相较于ResNet,Res2Net将输入分成几部分,一组卷积核从对应的一组输入特征图中提取信息。前面得到的信息送到另一组卷积核中作为输入。重复此操作,直到处理完所有输入特征图。最后,每组输出的特征图通过拼接操作送入1x1的卷积中用于进行特征融合。Res2Net着重于分割类型的任务,其中改进的物体识别能力发挥了作用。
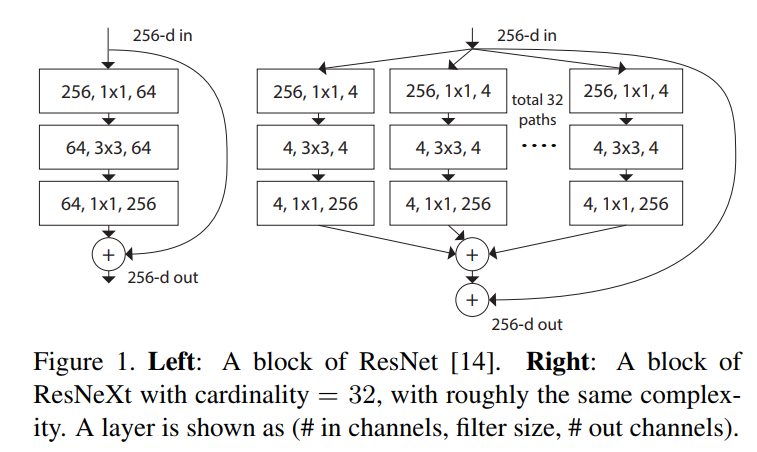
ResNeXt
ResNeXt是facebook于2016年提出的一种对ResNet的改进版网络。ResNeXt是ResNet和Inception的结合体, ResNext的每一个分支都采用相同的拓扑结构。ResNeXt的本质是分组卷积(Group Convolution),通过变量基数(Cardinality)来控制组的数量。
分组卷积是普通卷积和深度可分离卷积的一个折中方案,即每个分支产生的Feature Map的通道数为n(n>1)。在2019年,facebook通过弱监督学习研究了该系列网络在ImageNet上的精度上限,为了区别之前的ResNeXt网络,该系列网络的后缀为wsl,其中wsl是弱监督学习(weakly-supervised-learning)的简称。
为了能有更强的特征提取能力,研究者将其网络宽度进一步放大,其中最大的ResNeXt101_32x48d_wsl拥有8亿个参数,将其在9.4亿的弱标签图片下训练并在ImageNet-1k上做finetune,最终在ImageNet-1k的top-1达到了85.4%,这也是迄今为止在ImageNet-1k的数据集上以224x224的分辨率下精度最高的网络。
Fix-ResNeXt中,作者使用了更大的图像分辨率,针对训练图片和验证图片数据预处理不一致的情况下做了专门的Fix策略,并使得ResNeXt101_32x48d_wsl拥有了更高的精度,由于其用到了Fix策略,故命名为Fix-ResNeXt101_32x48d_wsl。
Swin Transformer
Swin Transformer 是一种新的视觉Transformer网络,可以用作计算机视觉领域的通用骨干网络。Swin Transformer由移动窗口(shifted windows)表示的层次Transformer结构组成。移动窗口将自注意计算限制在非重叠的局部窗口上,同时允许跨窗口连接,从而提高了网络性能。
解码网络
我们根据显著目标检测研究方向以及语义分割研究方向的内容提出了两个方向可以共用的两个解码网络,Attention Guided Contextual Feature Fusion Network (注意力引导的上下文融合网络,简称ACFFNet)和Feature Mutual Feedback Network(特征互馈网络,简称FMFNet)。
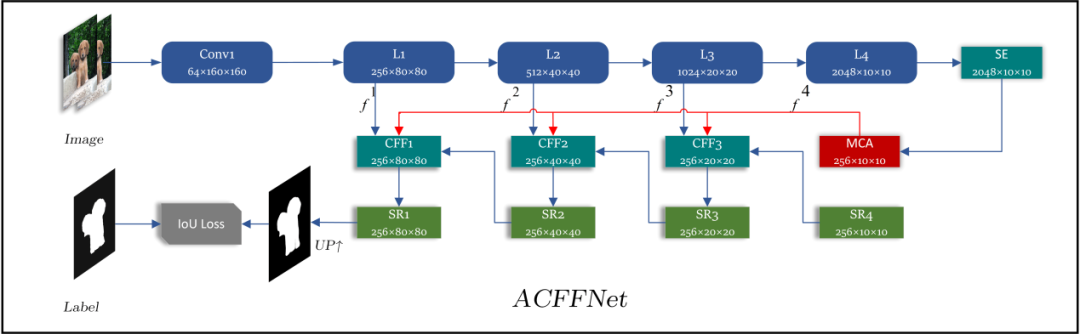
ACFFNet
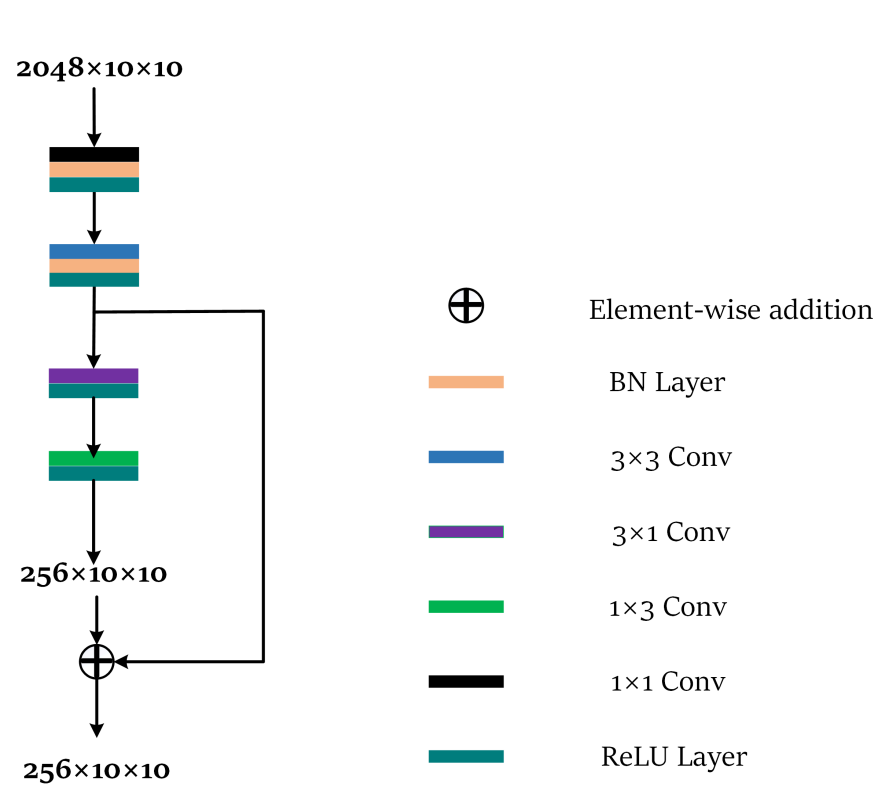
Conv1以及L1、L2、L3、L4是骨干网络提取的特征,SE为Squeeze-and-Excitation Layer。MFR(Multi-filed Feature Refinement Module)以及SR(Self Refirement)模块为ACFFNet网络的关键模块。下面将着重讲解这两个模块。
MFR
class MFRModel(nn.Layer):
def __init__(self, in_channel_left, in_channel_right):
super(MFRModel, self).__init__()
self.conv0 = nn.Conv2D(in_channel_left, 256, 3, 1, 1)
self.bn0 = nn.BatchNorm2D(256)
self.conv1 = nn.Conv2D(in_channel_right, 256, 1)
self.bn1 = nn.BatchNorm2D(256)
self.conv2 = nn.Conv2D(256, 256, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2D(256)
self.conv13 = nn.Conv2D(256, 256, kernel_size=(1, 3), stride=1, padding=(0, 1))
self.bn13 = nn.BatchNorm2D(256)
self.conv31 = nn.Conv2D(256, 256, kernel_size=(3, 1), stride=1, padding=(1, 0))
self.bn31 = nn.BatchNorm2D(256)
def forward(self, left, down):
left = F.relu(self.bn0(self.conv0(left)))
down = F.relu(self.bn1(self.conv1(down)))
left = F.relu(self.bn2(self.conv2(left)))
down = F.relu(self.bn31(self.conv31(down)))
down = self.bn13(self.conv13(down))
return F.relu(left + down)
MFR模块主要通过非对称卷积以及残差连接的方式来细化特征,非对称卷积从不同的感受野提取特征的信息,之后再与原特征互补,从而达到特征优化的作用。
SR
class SRModel(nn.Layer):
def __init__(self, in_channel):
super(SRModel, self).__init__()
self.conv1 = nn.Conv2D(in_channel, 256, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2D(256)
self.conv2 = nn.Conv2D(256, 512, kernel_size=3, stride=1, padding=1)
def forward(self, x):
out1 = F.relu(self.bn1(self.conv1(x)))
out2 = self.conv2(out1)
w, b = out2[:, :256, :, :], out2[:, 256:, :, :]
return F.relu(w * out1 + b)
SR模块是参考的2020年CVPR顶会《Global Context-Aware Progressive Aggregation Network for Salient Object Detection》里面提出是SR模块,可以起到填补预测图出现孔洞的作用。
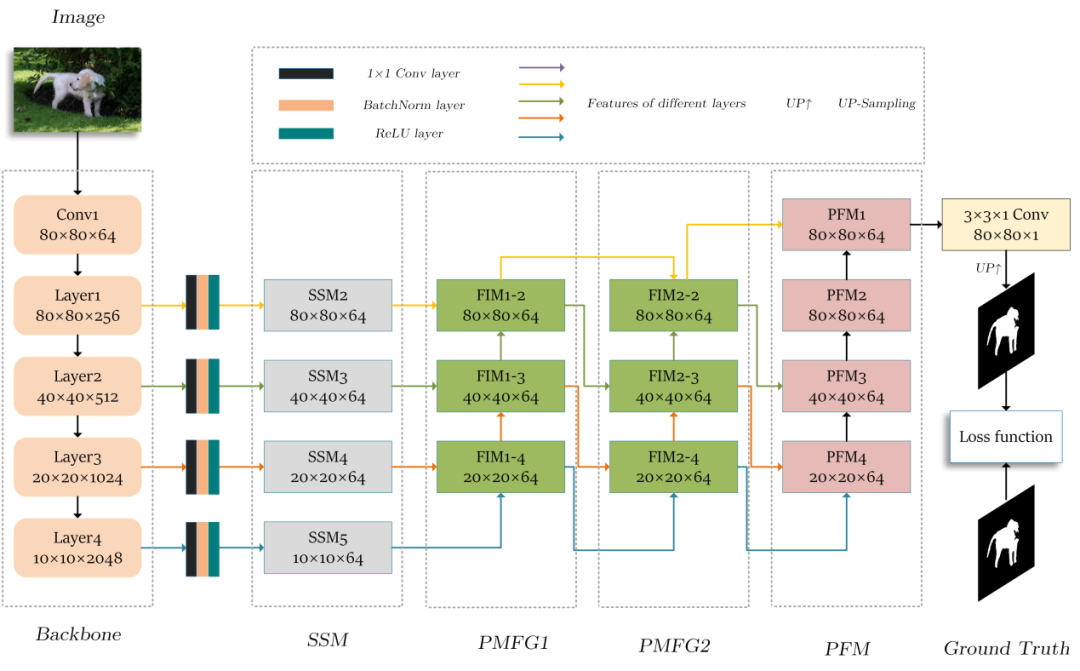
FMFNet
FMFNet的关键模块为FIM(Feature Interaction Module)模块,主要作用为细化上下文特征信息,去除背景噪音以及细化边界。
FIM
class FIM(nn.Layer):
def __init__(self):
super(FIM, self).__init__()
self.cv1 = nn.Conv2D(64, 64, 3, 1, 1)
self.bn1 = nn.BatchNorm2D(64)
self.cv2 = nn.Conv2D(64, 64, 3, 1, 1)
self.bn2 = nn.BatchNorm2D(64)
self.cv3 = nn.Conv2D(64, 64, 3, 1, 1)
self.bn3 = nn.BatchNorm2D(64)
self.cv4 = nn.Conv2D(64, 64, 3, 1, 1)
self.bn4 = nn.BatchNorm2D(64)
self.initialize()
def forward(self, l, h):
h_l = F.interpolate(h, size=l.shape[2:], mode='bilinear', align_corners=True)
l_h = F.interpolate(l, size=h.shape[2:], mode='bilinear', align_corners=True)
h_l = F.relu(self.bn1(self.cv1(h_l)))
l_h = F.relu(self.bn2(self.cv2(l_h)))
l_h_l = self.bn3(self.cv3(l * h_l))
h_l_h = self.bn4(self.cv4(h * l_h))
l = F.relu(l_h_l + l)
h = F.relu(h_l_h + h)
return l, h
高低层特征分别与邻层特征交互,再通过残差连接的方式细化特征,最终实现多层特征的优化。
模型融合
模型融合是比赛提分的关键,不同模型的融合可以实现互补,尤其是在不同阈值下,可以更完善地找到目标。为了实现不同模型的融合,我们根据3个骨干网络2个解码网络的搭配,配置了4个完整的网络,即Res2Net200 + ACFFNet、Res2Net200 + FMFNet、SwinT + ACFFNet、ResNeXt101 + ACFFNet。
模型融合采取的策略为不同模型结果图的加权融合。经过多次不同权重的尝试,确定最终的权重比为0.4:0.2:0.2:0.2,分别对应上述的四个模型。至此,得分为B榜的0.80428。
损失函数分析
def iou_loss(pred, mask):
pred = F.sigmoid(pred)
inter = (pred*mask).sum(axis=(2,3))
union = (pred+mask).sum(axis=(2,3))
iou = 1-(inter+1)/(union-inter+1)
return iou.mean()
训练策略
采用PaddleSeg进行数据以及模型的搭建,因此也是在PaddleSeg进行训练。训练过程中为了防止过拟合,采用手动提前停止的策略。每个网络训练约3小时左右即可完成训练过程。由于添加了多尺度预测,4个网络的预测时间约为1个半小时。
B榜提分过程
提升思路
飞桨使用心得及建议
虽然算不上是飞桨的老用户,但是在比赛过程中也越来越了解飞桨,认知态度也从一开始使用量不多、生态小的片面认识转到开发队伍庞大、功能丰富,也慢慢掌握了飞桨的使用。我是从PyTorch框架转向飞桨的,可以说飞桨开源框架v2.0及以上的版本可以完全做到PyTorch的无痛迁移。
使用飞桨时,一开始依然是编码处理数据,搭建网络,编写训练过程,虽然繁琐并且代码量大,但并没有觉得特别麻烦。只有通过慢慢实现以及不断摸索,才会对飞桨的代码有所了解,才可以根据实际任务对代码文件进行修改以符合自己的要求。后来接触到了PaddleSeg图像分割套件,才发现使用最新的分割模型对自己的数据集进行图像分割也可以很方便。慢慢的通过PaddleOCR、PaddleDet、PaddleNLP,了解了飞桨更庞大的内容体系。
我从新人慢慢蜕变成飞桨的贡献者,还是有许多经验和建议分享给刚接触飞桨或者刚接触深度学习的新手。在飞桨的初使用中,可以说是在Python的学习中,建议使用Anaconda来创建python环境。使用conda可以解决大部分的环境问题,并且使用conda安装GPU版本的PaddlePaddle仅需要一行代码即可,同时还会安装cuDNN以及CUDA。
关于学习飞桨,踏实看文档、看教程、多写代码是提升框架使用能力的基本方法。飞桨AI Studio的项目模块既可以看到开发者们奇思妙想的想法,也可以看到其他大神们行云流水的代码,对自我提升有很大的帮助。另外,遇到报错首先还是要自己尝试解决问题,独立解决问题是程序员很重要的技能,实在不好解决可以给飞桨提issue。
致谢
最后感谢我的队友以及飞桨官方的工作人员,包括GT哥,生而为弟等等。飞桨是我通过这次比赛才接触到的深度学习平台,并且在不断学习和使用过程中也加深了对飞桨的了解。尽管飞桨大量的套件是我之前学习的深度学习框架所不具有的,但是从其他框架迁移到飞桨并不费力。总之,感谢百度飞桨举办本次比赛,不仅带给我很多惊喜,而且让我有机会展示自己。
飞桨其他比赛火热报名中
NLP方向
问答摘要与推理:
https://aistudio.baidu.com/aistudio/competition/detail/80
中文新闻文本标题分类:
https://aistudio.baidu.com/aistudio/competition/detail/107
面向事实一致性的生成评测比赛:
https://aistudio.baidu.com/aistudio/competition/detail/105
CV方向
钢铁缺陷检测挑战赛:
https://aistudio.baidu.com/aistudio/competition/detail/114
PALM眼底彩照中黄斑中央凹定位:
https://aistudio.baidu.com/aistudio/competition/detail/86
PALM病理性近视病灶检测与分割:
https://aistudio.baidu.com/aistudio/competition/detail/88
长按下方二维码立即
Star

更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
点击阅读原文,欢迎在飞桨论坛讨论交流~~
END

赛题背景
监督学习模型的优异性能要以大量标注数据作为支撑,可现实中获得数量可观的标注数据十分耗费人力物力。于是,半监督学习逐渐成为深度学习领域的热门研究方向,只需要少量标注数据就可以完成模型训练过程,更适用于现实场景中的各种任务。
比赛任务
本次比赛采用IoU曲线作为评价指标,要求选手基于少量有标注数据训练模型,使分类网络具有目标定位能力,实现半监督目标定位任务。更多详细信息,详见比赛页:
https://aistudio.baidu.com/aistudio/competition/detail/78
竞赛算法介绍
本次比赛属于语义分割的范畴,确切来说是二分类语义分割,即将背景像素点归类为0(黑色),物体像素点归类为255(白色)。目前语义分割领域最为常用的就是以端到端为目标的编码器-解码器架构,以实现像素级别的输出,从而提高分割的精度。
实现这一目标的方法为全卷积神经网络(Fully Convolutional Network, FCN),见图2,全卷积神经网络中的编码器起到提取不同尺度特征信息的作用,通常由分类网络如ResNet、VGG提取输入图片的特征及语义信息, 这样的分类网络又被称为FCN中的骨干网络。
提取的不同尺度特征具有不同的语义信息,浅层特征具有较大的分辨率以及明显的物体轮廓信息,但也包含了复杂的背景噪音,深层特征具有较小的分辨率以及探测物体的位置信息,但小分辨率往往带来了粗糙的物体边界,而语义分割则需要精细的物体边界。因此,解码器就实现了深层浅层特征的融合,以定位具有清晰边界的目标物体。
因此,本次参赛采用的是以全卷积神经网络为基础的目标定位算法。
图2. 全卷积神经网络
冠军团队方案详解
团队成员
张晋(上海应用技术大学研究生)、佟兴宇(中国移动-人工智能工程师)、张九鑫(东北大学研究生)、李吉平(迈瑞生物-监护算法工程师)、李想(上海应用技术大学研究生)。其中,张晋和佟兴宇负责模型的搭建和调试,张九鑫、李吉平和李想三位成员负责分析数据以及提出模型改进方法。
赛题数据分析
训练数据集包括50,000幅像素级有标注的图像,共包含500个类,每个类100幅图像;
总共为50,000张图片,经过分析后可以看出,赛题要求为定位目标的位置,而赛题数据给出的是500个类别,所以并不能把赛题归为500类分类问题。而应归类为50000张图片前景与背景的2分类问题。
赛题要求将图片中的目标定位出来,与显著目标检测任务相同的是,该赛题的某些图片中存在多个目标,但并不是所有目标都是检测目标,从图3可以看到,多条鱼的图像中,只有三条在标签图中存在。因此,网络的搭建中如果加入注意力模块则会更好地辅助网络寻找检测目标。
图3. 训练集图片
另外,我们对图片的尺寸做了大致的统计分析,如图4,横坐标为尺寸区间,纵坐标为在该尺寸区间的图片数量,可以看出图片高度在300-500居多,宽度在450-500居多。并计算了平均尺寸,大约为(384, 448),在数据处理过程中图片可以转换尺寸到均值尺寸以获得更全面的图片信息。
评价指标分析
本次比赛使用IoU曲线作为评价指标,即利用预测目标的定位概率图,计算不同阈值下预测结果与真实目标之间的IoU分数,最后取一个最高点作为最终分数。IoU的计算公式为:
对于本次比赛,图像处理的输出应该为经过sigmoid激活函数处理后归一化到[0,1]范围内的float32小数。存为图像则需要再乘255,并转化为int类型的灰度图。提交测试分数时,会根据[0, 255] 选择255个阈值来进行计算,大于阈值的设为正例,小于阈值的设为负例,从而计算IoU分数,选择最高的IoU分数作为成绩。
若在处理过程中自定阈值将图像处理为只存在0和255的像素点,即黑白图,则会导致在各个判断阈值之下的IoU得分相同,从而无法选择出最高的IoU分数。这是影响比赛得分的一个关键点。
整体思路分析
数据分析:举办方提供了50,000幅像素级有标注的图像作为训练集,并没有提供额外的验证集,因此我们在训练集的基础上划分4%的数据即2000张图片作为验证集。采用了固定随机种子的方法保证每次启动训练都会划分到相同的验证集与训练集。
模型分析:在训练的过程中,我们发现不同模型融合的效果图可以有效捕捉到图像的不同细节信息,从而提高IoU分数。最终,我们采用3种不同骨干网络和2种不同解码网络构建的4个模型进行融合,并分配不同的权重,达到B榜的最终成绩。
代码实现:
在整个比赛过程中,我们团队使用飞桨以及相关套件PaddleClas和PaddleSeg进行模型的搭建、损失函数的设计、数据的封装处理以及评价指标的实现。PaddleClas提供了大量预训练的图像分类网络,并通过半监督知识蒸馏的方法提高了部分模型的准确率,这为我们后面获得高分提供了坚实的基础。
我们在PaddleClas中选择了三个骨干网络:Res2Net200_vd_26w_4s_ssld、ResNeXt101_32x16d_wsl
和SwinTransformer_large_patch4_window12_384,作为骨干网络。这三个骨干网络都是PaddleClas实现的具有高准确率的分类网络。
PaddleSeg可以快速实现语义分割任务。模型主要由飞桨提供的深度学习模块API“paddle.nn”实现,数据处理由飞桨提供的数据处理模块API”paddle.io.Dataset”实现,并将这些模块放到PaddleSeg中方便后续调参训练预测等操作。
另外,在阅读PaddleSeg的源码时,特别惊喜的发现PaddleSeg的预测代码额外提供了多尺度预测以及翻转预测等操作,我们使用了多尺度预测以及水平翻转这些方法进行预测,以加强最终预测结果的图像边缘点的置信度。
骨干网络的选择
如上所述,FCN由编码器(骨干网络)和解码器组成,图像分类网络经常被选为骨干网络,因为图像分类网络能提取更好的图片信息,以方便在后续的特征融合中生成高质量的效果图。
因此我们在PaddleClas中的ImageNet预训练模型库选择Top-1 Acc分别为0.851、0.8424和0.8719的Res2Net200_vd_26w_4s_ssld(以下简称为Res2Net200)、ResNeXt101_32x16d_wsl(以下简称为ResNeXt101)
和SwinTransformer_large_patch4_window12_384 (以下简称为SwinT384) 三种骨干网络作测试。
其中Res2Net和ResNeXt均为ResNet的变体形式,Swin Transformer是一种新的视觉Transformer网络,可以用作计算机视觉领域的通用骨干网络。
可以说,骨干网络的选取是决定成败最为关键的一步,骨干网络提取的特征直接影响到后续特征处理以及特征融合的效果,间接影响到结果图的质量。
Res2Net
相较于ResNet,Res2Net将输入分成几部分,一组卷积核从对应的一组输入特征图中提取信息。前面得到的信息送到另一组卷积核中作为输入。重复此操作,直到处理完所有输入特征图。最后,每组输出的特征图通过拼接操作送入1x1的卷积中用于进行特征融合。Res2Net着重于分割类型的任务,其中改进的物体识别能力发挥了作用。
ResNeXt
ResNeXt是facebook于2016年提出的一种对ResNet的改进版网络。ResNeXt是ResNet和Inception的结合体, ResNext的每一个分支都采用相同的拓扑结构。ResNeXt的本质是分组卷积(Group Convolution),通过变量基数(Cardinality)来控制组的数量。
分组卷积是普通卷积和深度可分离卷积的一个折中方案,即每个分支产生的Feature Map的通道数为n(n>1)。在2019年,facebook通过弱监督学习研究了该系列网络在ImageNet上的精度上限,为了区别之前的ResNeXt网络,该系列网络的后缀为wsl,其中wsl是弱监督学习(weakly-supervised-learning)的简称。
为了能有更强的特征提取能力,研究者将其网络宽度进一步放大,其中最大的ResNeXt101_32x48d_wsl拥有8亿个参数,将其在9.4亿的弱标签图片下训练并在ImageNet-1k上做finetune,最终在ImageNet-1k的top-1达到了85.4%,这也是迄今为止在ImageNet-1k的数据集上以224x224的分辨率下精度最高的网络。
Fix-ResNeXt中,作者使用了更大的图像分辨率,针对训练图片和验证图片数据预处理不一致的情况下做了专门的Fix策略,并使得ResNeXt101_32x48d_wsl拥有了更高的精度,由于其用到了Fix策略,故命名为Fix-ResNeXt101_32x48d_wsl。
Swin Transformer
Swin Transformer 是一种新的视觉Transformer网络,可以用作计算机视觉领域的通用骨干网络。Swin Transformer由移动窗口(shifted windows)表示的层次Transformer结构组成。移动窗口将自注意计算限制在非重叠的局部窗口上,同时允许跨窗口连接,从而提高了网络性能。
解码网络
我们根据显著目标检测研究方向以及语义分割研究方向的内容提出了两个方向可以共用的两个解码网络,Attention Guided Contextual Feature Fusion Network (注意力引导的上下文融合网络,简称ACFFNet)和Feature Mutual Feedback Network(特征互馈网络,简称FMFNet)。
ACFFNet
Conv1以及L1、L2、L3、L4是骨干网络提取的特征,SE为Squeeze-and-Excitation Layer。MFR(Multi-filed Feature Refinement Module)以及SR(Self Refirement)模块为ACFFNet网络的关键模块。下面将着重讲解这两个模块。
MFR
class MFRModel(nn.Layer):
def __init__(self, in_channel_left, in_channel_right):
super(MFRModel, self).__init__()
self.conv0 = nn.Conv2D(in_channel_left, 256, 3, 1, 1)
self.bn0 = nn.BatchNorm2D(256)
self.conv1 = nn.Conv2D(in_channel_right, 256, 1)
self.bn1 = nn.BatchNorm2D(256)
self.conv2 = nn.Conv2D(256, 256, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2D(256)
self.conv13 = nn.Conv2D(256, 256, kernel_size=(1, 3), stride=1, padding=(0, 1))
self.bn13 = nn.BatchNorm2D(256)
self.conv31 = nn.Conv2D(256, 256, kernel_size=(3, 1), stride=1, padding=(1, 0))
self.bn31 = nn.BatchNorm2D(256)
def forward(self, left, down):
left = F.relu(self.bn0(self.conv0(left)))
down = F.relu(self.bn1(self.conv1(down)))
left = F.relu(self.bn2(self.conv2(left)))
down = F.relu(self.bn31(self.conv31(down)))
down = self.bn13(self.conv13(down))
return F.relu(left + down)
MFR模块主要通过非对称卷积以及残差连接的方式来细化特征,非对称卷积从不同的感受野提取特征的信息,之后再与原特征互补,从而达到特征优化的作用。
SR
class SRModel(nn.Layer):
def __init__(self, in_channel):
super(SRModel, self).__init__()
self.conv1 = nn.Conv2D(in_channel, 256, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2D(256)
self.conv2 = nn.Conv2D(256, 512, kernel_size=3, stride=1, padding=1)
def forward(self, x):
out1 = F.relu(self.bn1(self.conv1(x)))
out2 = self.conv2(out1)
w, b = out2[:, :256, :, :], out2[:, 256:, :, :]
return F.relu(w * out1 + b)
SR模块是参考的2020年CVPR顶会《Global Context-Aware Progressive Aggregation Network for Salient Object Detection》里面提出是SR模块,可以起到填补预测图出现孔洞的作用。
FMFNet
FMFNet的关键模块为FIM(Feature Interaction Module)模块,主要作用为细化上下文特征信息,去除背景噪音以及细化边界。
FIM
class FIM(nn.Layer):
def __init__(self):
super(FIM, self).__init__()
self.cv1 = nn.Conv2D(64, 64, 3, 1, 1)
self.bn1 = nn.BatchNorm2D(64)
self.cv2 = nn.Conv2D(64, 64, 3, 1, 1)
self.bn2 = nn.BatchNorm2D(64)
self.cv3 = nn.Conv2D(64, 64, 3, 1, 1)
self.bn3 = nn.BatchNorm2D(64)
self.cv4 = nn.Conv2D(64, 64, 3, 1, 1)
self.bn4 = nn.BatchNorm2D(64)
self.initialize()
def forward(self, l, h):
h_l = F.interpolate(h, size=l.shape[2:], mode='bilinear', align_corners=True)
l_h = F.interpolate(l, size=h.shape[2:], mode='bilinear', align_corners=True)
h_l = F.relu(self.bn1(self.cv1(h_l)))
l_h = F.relu(self.bn2(self.cv2(l_h)))
l_h_l = self.bn3(self.cv3(l * h_l))
h_l_h = self.bn4(self.cv4(h * l_h))
l = F.relu(l_h_l + l)
h = F.relu(h_l_h + h)
return l, h
高低层特征分别与邻层特征交互,再通过残差连接的方式细化特征,最终实现多层特征的优化。
模型融合
模型融合是比赛提分的关键,不同模型的融合可以实现互补,尤其是在不同阈值下,可以更完善地找到目标。为了实现不同模型的融合,我们根据3个骨干网络2个解码网络的搭配,配置了4个完整的网络,即Res2Net200 + ACFFNet、Res2Net200 + FMFNet、SwinT + ACFFNet、ResNeXt101 + ACFFNet。
模型融合采取的策略为不同模型结果图的加权融合。经过多次不同权重的尝试,确定最终的权重比为0.4:0.2:0.2:0.2,分别对应上述的四个模型。至此,得分为B榜的0.80428。
损失函数分析
def iou_loss(pred, mask):
pred = F.sigmoid(pred)
inter = (pred*mask).sum(axis=(2,3))
union = (pred+mask).sum(axis=(2,3))
iou = 1-(inter+1)/(union-inter+1)
return iou.mean()
训练策略
采用PaddleSeg进行数据以及模型的搭建,因此也是在PaddleSeg进行训练。训练过程中为了防止过拟合,采用手动提前停止的策略。每个网络训练约3小时左右即可完成训练过程。由于添加了多尺度预测,4个网络的预测时间约为1个半小时。
B榜提分过程
提升思路
飞桨使用心得及建议
虽然算不上是飞桨的老用户,但是在比赛过程中也越来越了解飞桨,认知态度也从一开始使用量不多、生态小的片面认识转到开发队伍庞大、功能丰富,也慢慢掌握了飞桨的使用。我是从PyTorch框架转向飞桨的,可以说飞桨开源框架v2.0及以上的版本可以完全做到PyTorch的无痛迁移。
使用飞桨时,一开始依然是编码处理数据,搭建网络,编写训练过程,虽然繁琐并且代码量大,但并没有觉得特别麻烦。只有通过慢慢实现以及不断摸索,才会对飞桨的代码有所了解,才可以根据实际任务对代码文件进行修改以符合自己的要求。后来接触到了PaddleSeg图像分割套件,才发现使用最新的分割模型对自己的数据集进行图像分割也可以很方便。慢慢的通过PaddleOCR、PaddleDet、PaddleNLP,了解了飞桨更庞大的内容体系。
我从新人慢慢蜕变成飞桨的贡献者,还是有许多经验和建议分享给刚接触飞桨或者刚接触深度学习的新手。在飞桨的初使用中,可以说是在Python的学习中,建议使用Anaconda来创建python环境。使用conda可以解决大部分的环境问题,并且使用conda安装GPU版本的PaddlePaddle仅需要一行代码即可,同时还会安装cuDNN以及CUDA。
关于学习飞桨,踏实看文档、看教程、多写代码是提升框架使用能力的基本方法。飞桨AI Studio的项目模块既可以看到开发者们奇思妙想的想法,也可以看到其他大神们行云流水的代码,对自我提升有很大的帮助。另外,遇到报错首先还是要自己尝试解决问题,独立解决问题是程序员很重要的技能,实在不好解决可以给飞桨提issue。
致谢
最后感谢我的队友以及飞桨官方的工作人员,包括GT哥,生而为弟等等。飞桨是我通过这次比赛才接触到的深度学习平台,并且在不断学习和使用过程中也加深了对飞桨的了解。尽管飞桨大量的套件是我之前学习的深度学习框架所不具有的,但是从其他框架迁移到飞桨并不费力。总之,感谢百度飞桨举办本次比赛,不仅带给我很多惊喜,而且让我有机会展示自己。
飞桨其他比赛火热报名中
NLP方向
问答摘要与推理:
https://aistudio.baidu.com/aistudio/competition/detail/80
中文新闻文本标题分类:
https://aistudio.baidu.com/aistudio/competition/detail/107
面向事实一致性的生成评测比赛:
https://aistudio.baidu.com/aistudio/competition/detail/105
CV方向
钢铁缺陷检测挑战赛:
https://aistudio.baidu.com/aistudio/competition/detail/114
PALM眼底彩照中黄斑中央凹定位:
https://aistudio.baidu.com/aistudio/competition/detail/86
PALM病理性近视病灶检测与分割:
https://aistudio.baidu.com/aistudio/competition/detail/88
长按下方二维码立即
Star
更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
点击阅读原文,欢迎在飞桨论坛讨论交流~~
END