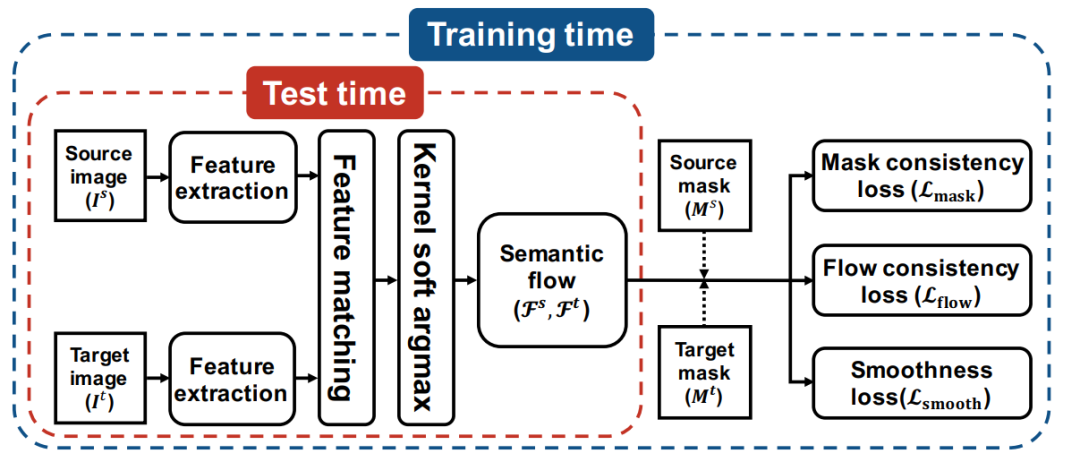
项目背景
数据集介绍及处理

import os
import numpy as np
from PIL import Image
from tqdm import trange
from collections import Counter
label_dir = 'data/aeroscapes/SegmentationClass'
label_dirlist = os.listdir(label_dir)
label_count = Counter()
for l in trange(len(label_dirlist)):
label_image = Image.open(os.path.join(label_dir,label_dirlist[l]))
label_array = Counter(np.array(label_image).flatten())
label_count += label_array
label_count
Counter({0: 696388200,11: 137855496,4: 877424,9: 1117021451,8: 133909912,7: 16946045,10: 881708346,3: 11114500,1: 12114423,2: 1596917,6: 2524067,5: 653619})

with open('data/train.txt','a+') as t:
for tr_line in open('data/aeroscapes/ImageSets/trn.txt'):
tr_line = tr_line.replace('\n','')
t.write('JPEGImages/%s.jpg SegmentationClass/%s.png\n'%(tr_line,tr_line))
print('生成训练集成功!')
with open('data/val.txt','a+') as v:
for val_line in open('data/aeroscapes/ImageSets/val.txt'):
val_line = val_line.replace('\n','')
v.write('JPEGImages/%s.jpg SegmentationClass/%s.png\n'%(val_line,val_line))
print('生成验证集成功!')PaddleSeg
API介绍与模型训练
首先,安装PaddleSeg库。
pip install paddleseg
import paddleseg.transforms as T
train_transforms = [
T.ResizeStepScaling(min_scale_factor=0.75,
max_scale_factor=2.0,
scale_step_size=0.25
),
T.RandomPaddingCrop(crop_size=(1024, 1024)),
T.RandomHorizontalFlip(),
T.RandomVerticalFlip(),
T.RandomDistort(
brightness_range = 0.4,
contrast_range = 0.4,
saturation_range = 0.4
),
T.Normalize(
mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225],
)
]
val_transforms = [
T.Normalize(
mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225],
)
]
数据集处理
from paddleseg.datasets import Dataset
dataset_dir = 'data/aeroscapes'
train_dataset = Dataset(
dataset_root = dataset_dir,
train_path = 'data/train.txt',
num_classes = 12,
transforms = train_transforms,
edge = True,
mode = 'train'
)
val_dataset = Dataset(
dataset_root = dataset_dir,
val_path = 'data/val.txt',
num_classes = 12,
transforms = val_transforms,
mode = 'val'
)
from paddleseg.models import SFNet
from paddleseg.models.backbones import ResNet50_vd
backbone = ResNet50_vd(
output_stride = 8,
pretrained = 'https://bj.bcebos.com/paddleseg/dygraph/resnet50_vd_ssld_v2.tar.gz'
)
model = SFNet(
num_classes = 12,
backbone = backbone,
backbone_indices = [0, 1, 2, 3],
pretrained = 'https://bj.bcebos.com/paddleseg/dygraph/cityscapes/sfnet_resnet50_os8_cityscapes_1024x1024_80k/model.pdparams'
)
from paddle import optimizer
from paddleseg.models.losses import OhemCrossEntropyLoss,LovaszSoftmaxLoss
lr = optimizer.lr.PolynomialDecay(
learning_rate = 0.01,
decay_steps = 10000,
end_lr = 0,
power=0.9,
)
optimizer = optimizer.Momentum(lr, parameters=model.parameters(), momentum=0.9, weight_decay=4.0e-5)
losses = {}
losses['types'] = [LovaszSoftmaxLoss()]
losses['coef'] = [1]
print(losses)
开始训练
from paddleseg.core import train
train(
model=model,
train_dataset=train_dataset, # 训练集的dataset
val_dataset=val_dataset, # 验证集的dataset
optimizer=optimizer, # 优化器
save_dir='output', # 保存路径
iters=80000, # 训练次数
batch_size=2,
save_interval=1400, # 保存的间隔次数
log_iters=10, # 日志打印间隔
num_workers=0,
losses=losses,
use_vdl=True)
预测统计与图表生成
视频分帧
import cv2
def save_rgb(path):
# 获得视频的格式
rgb = path + 'videoplayback.avi'
print(rgb)
videoCapture = cv2.VideoCapture(rgb)
# 获得码率及尺寸
fps = videoCapture.get(cv2.CAP_PROP_FPS)
size = (int(videoCapture.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(videoCapture.get(cv2.CAP_PROP_FRAME_HEIGHT)))
fNUMS = videoCapture.get(cv2.CAP_PROP_FRAME_COUNT)
print(fps, size, fNUMS)
# 读帧
success, frame = videoCapture.read()
i = 0
while success:
cv2.imwrite(path + 'origin_jpg/%d.jpg' % i, frame)
i = i + 1
success, frame = videoCapture.read()
videoCapture.release()
save_rgb('./video/')
图像批量预测
%mkdir ./video/predict_png
import paddleseg.transforms as T
from ppseg_predict import predict
from ppseg_predict import get_image_list
transforms = T.Compose([
T.Normalize()
])
image_list,image_dir = get_image_list('video/origin_jpg')
predict(
model,
model_path='output/best_model/model.pdparams', # 模型路径
transforms=transforms, # transform.Compose, 对输入图像进行预处理
image_list=image_list, # list,待预测的图像路径列表。
image_dir=image_dir, # str,待预测的图片所在目录
save_dir='video/predict_png' # str,结果输出路径
)
预测完成后统计每一帧真值图中每种分类的数量,并可视化成统计图表,这一步需要用到pyecharts和phantomjs,需要先安装以下两个库。
pip install pyecharts
pip install snapshot-phantomjs
%mkdir video/chart_bar
%mkdir video/chart_meter
import os
import numpy as np
from PIL import Image
from tqdm import trange
from collections import Counter
from pyecharts.charts import Bar
from pyecharts.charts import Gauge
from pyecharts import options as opts
from snapshot_phantomjs import snapshot
from pyecharts.render import make_snapshot
def count_pixel(img,mode='bar'):
img = np.array(Image.open(img)).flatten()
img_len = len(img)
img_pixels = Counter(img)
if mode == 'bar':
return img_pixels,img_len
if mode == 'meter':
return round(img_pixels[9]/img_len*100,2)
def create_bar_image(img_dir,img_basename):
img_path = os.path.join(img_dir,img_basename)
img_data, total_pixels = count_pixel(img_path,mode='bar')
c = (
Bar(init_opts=opts.InitOpts(width="610px",height="380px"))
.set_global_opts(legend_opts=opts.LegendOpts(is_show=False),yaxis_opts=opts.AxisOpts(min_=0,max_='1'))
.add_xaxis([''])
.add_yaxis(
"Unlabeled",
[round(img_data[0]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(0, 0, 0)'),
)
.add_yaxis(
"Person",
[round(img_data[1]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(192,128,128)'),
)
.add_yaxis(
"Bike",
[round(img_data[2]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(0,128,0)'),
)
.add_yaxis(
"Car",
[round(img_data[3]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(128,128,128)'),
)
.add_yaxis(
"Drone",
[round(img_data[4]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(128,0,0)'),
)
.add_yaxis(
"Boat",
[round(img_data[5]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(0,0,128)'),
)
.add_yaxis(
"Animal",
[round(img_data[6]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(192,0,128)'),
)
.add_yaxis(
"Obstacle",
[round(img_data[7]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(192,0,0)'),
)
.add_yaxis(
"Construction",
[round(img_data[8]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(192,128,0)'),
)
.add_yaxis(
"Vegetation",
[round(img_data[9]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(0,64,0)'),
)
.add_yaxis(
"Road",
[round(img_data[10]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(128,128,0)'),
)
.add_yaxis(
"Sky",
[round(img_data[11]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(0,128,128)'),
)
)
make_snapshot(snapshot,c.render(),os.path.join('./video/chart_bar',img_basename).replace('jpg','png'))
def create_meter_image(img_dir,img_basename):
img_path = os.path.join(img_dir,img_basename)
green_pixels = count_pixel(img_path,mode='meter')
c = (
Gauge(init_opts=opts.InitOpts(width="350px", height="350px"))
.add(series_name="", data_pair=[["", green_pixels]],pointer=opts.GaugePointerOpts(length='70%',width=4))
.set_global_opts(
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(
color=[[0.15, "#fd666d"], [0.25, "#fddd60"], [1, "#91cc75"]], width=15
)
)
)
)
make_snapshot(snapshot,c.render(),os.path.join('./video/chart_meter',img_basename).replace('jpg','png'))
predict_img_dir = 'video/predict_png/grey_prediction/'
predict_imgs = os.listdir(predict_img_dir)
for pi in trange(len(predict_imgs)):
create_bar_image(predict_img_dir,predict_imgs[pi])
create_meter_image(predict_img_dir,predict_imgs[pi])
视频合成
%mkdir video/board
import numpy as np
from PIL import Image
from tqdm import trange
NUM_FRAMES = 1309 #总帧数
for pid in trange(NUM_FRAMES):
background_board = Image.open('board.jpg')
origin_frame = Image.open('video/origin_jpg/{}.jpg'.format(pid)).resize((660,370))
predict_frame = Image.open('video/predict_png/pseudo_color_prediction/{}.png'.format(pid)).resize((660,370))
bar_chart = Image.open('video/chart_bar/{}.png'.format(pid)).resize((620,340))
meter_chart = Image.open('video/chart_meter/{}.png'.format(pid)).resize((400,400))
bar_r,bar_g,bar_b,bar_a = bar_chart.split()
meter_r,meter_g,meter_b,meter_a = meter_chart.split()
background_board.paste(origin_frame,(120,230))
background_board.paste(predict_frame,(1150,230))
background_board.paste(bar_chart,(160,700),mask=bar_a)
background_board.paste(meter_chart,(1300,700),mask=meter_a)
background_board.save('video/board/{}.png'.format(pid))
import os
import cv2
def images_to_video(path,width,height,output_name):
fps = 30 # 帧率
num_frames = NUM_FRAMES
img_width = width
img_height = height
out = cv2.VideoWriter(output_name, cv2.VideoWriter_fourcc(*"mp4v"), fps,(img_width,img_height))
for i in trange(num_frames):
filepath = path +str(i) + ".png"
out.write(cv2.imread(filepath))
out.release()
images_to_video('video/board/',1920,1080,'borad.mp4')
总结

飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END

项目背景
数据集介绍及处理
import os
import numpy as np
from PIL import Image
from tqdm import trange
from collections import Counter
label_dir = 'data/aeroscapes/SegmentationClass'
label_dirlist = os.listdir(label_dir)
label_count = Counter()
for l in trange(len(label_dirlist)):
label_image = Image.open(os.path.join(label_dir,label_dirlist[l]))
label_array = Counter(np.array(label_image).flatten())
label_count += label_array
label_count
Counter({0: 696388200,11: 137855496,4: 877424,9: 1117021451,8: 133909912,7: 16946045,10: 881708346,3: 11114500,1: 12114423,2: 1596917,6: 2524067,5: 653619})
with open('data/train.txt','a+') as t:
for tr_line in open('data/aeroscapes/ImageSets/trn.txt'):
tr_line = tr_line.replace('\n','')
t.write('JPEGImages/%s.jpg SegmentationClass/%s.png\n'%(tr_line,tr_line))
print('生成训练集成功!')
with open('data/val.txt','a+') as v:
for val_line in open('data/aeroscapes/ImageSets/val.txt'):
val_line = val_line.replace('\n','')
v.write('JPEGImages/%s.jpg SegmentationClass/%s.png\n'%(val_line,val_line))
print('生成验证集成功!')PaddleSeg
API介绍与模型训练
首先,安装PaddleSeg库。
pip install paddleseg
import paddleseg.transforms as T
train_transforms = [
T.ResizeStepScaling(min_scale_factor=0.75,
max_scale_factor=2.0,
scale_step_size=0.25
),
T.RandomPaddingCrop(crop_size=(1024, 1024)),
T.RandomHorizontalFlip(),
T.RandomVerticalFlip(),
T.RandomDistort(
brightness_range = 0.4,
contrast_range = 0.4,
saturation_range = 0.4
),
T.Normalize(
mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225],
)
]
val_transforms = [
T.Normalize(
mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225],
)
]
数据集处理
from paddleseg.datasets import Dataset
dataset_dir = 'data/aeroscapes'
train_dataset = Dataset(
dataset_root = dataset_dir,
train_path = 'data/train.txt',
num_classes = 12,
transforms = train_transforms,
edge = True,
mode = 'train'
)
val_dataset = Dataset(
dataset_root = dataset_dir,
val_path = 'data/val.txt',
num_classes = 12,
transforms = val_transforms,
mode = 'val'
)
from paddleseg.models import SFNet
from paddleseg.models.backbones import ResNet50_vd
backbone = ResNet50_vd(
output_stride = 8,
pretrained = 'https://bj.bcebos.com/paddleseg/dygraph/resnet50_vd_ssld_v2.tar.gz'
)
model = SFNet(
num_classes = 12,
backbone = backbone,
backbone_indices = [0, 1, 2, 3],
pretrained = 'https://bj.bcebos.com/paddleseg/dygraph/cityscapes/sfnet_resnet50_os8_cityscapes_1024x1024_80k/model.pdparams'
)
from paddle import optimizer
from paddleseg.models.losses import OhemCrossEntropyLoss,LovaszSoftmaxLoss
lr = optimizer.lr.PolynomialDecay(
learning_rate = 0.01,
decay_steps = 10000,
end_lr = 0,
power=0.9,
)
optimizer = optimizer.Momentum(lr, parameters=model.parameters(), momentum=0.9, weight_decay=4.0e-5)
losses = {}
losses['types'] = [LovaszSoftmaxLoss()]
losses['coef'] = [1]
print(losses)
开始训练
from paddleseg.core import train
train(
model=model,
train_dataset=train_dataset, # 训练集的dataset
val_dataset=val_dataset, # 验证集的dataset
optimizer=optimizer, # 优化器
save_dir='output', # 保存路径
iters=80000, # 训练次数
batch_size=2,
save_interval=1400, # 保存的间隔次数
log_iters=10, # 日志打印间隔
num_workers=0,
losses=losses,
use_vdl=True)
预测统计与图表生成
视频分帧
import cv2
def save_rgb(path):
# 获得视频的格式
rgb = path + 'videoplayback.avi'
print(rgb)
videoCapture = cv2.VideoCapture(rgb)
# 获得码率及尺寸
fps = videoCapture.get(cv2.CAP_PROP_FPS)
size = (int(videoCapture.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(videoCapture.get(cv2.CAP_PROP_FRAME_HEIGHT)))
fNUMS = videoCapture.get(cv2.CAP_PROP_FRAME_COUNT)
print(fps, size, fNUMS)
# 读帧
success, frame = videoCapture.read()
i = 0
while success:
cv2.imwrite(path + 'origin_jpg/%d.jpg' % i, frame)
i = i + 1
success, frame = videoCapture.read()
videoCapture.release()
save_rgb('./video/')
图像批量预测
%mkdir ./video/predict_png
import paddleseg.transforms as T
from ppseg_predict import predict
from ppseg_predict import get_image_list
transforms = T.Compose([
T.Normalize()
])
image_list,image_dir = get_image_list('video/origin_jpg')
predict(
model,
model_path='output/best_model/model.pdparams', # 模型路径
transforms=transforms, # transform.Compose, 对输入图像进行预处理
image_list=image_list, # list,待预测的图像路径列表。
image_dir=image_dir, # str,待预测的图片所在目录
save_dir='video/predict_png' # str,结果输出路径
)
预测完成后统计每一帧真值图中每种分类的数量,并可视化成统计图表,这一步需要用到pyecharts和phantomjs,需要先安装以下两个库。
pip install pyecharts
pip install snapshot-phantomjs
%mkdir video/chart_bar
%mkdir video/chart_meter
import os
import numpy as np
from PIL import Image
from tqdm import trange
from collections import Counter
from pyecharts.charts import Bar
from pyecharts.charts import Gauge
from pyecharts import options as opts
from snapshot_phantomjs import snapshot
from pyecharts.render import make_snapshot
def count_pixel(img,mode='bar'):
img = np.array(Image.open(img)).flatten()
img_len = len(img)
img_pixels = Counter(img)
if mode == 'bar':
return img_pixels,img_len
if mode == 'meter':
return round(img_pixels[9]/img_len*100,2)
def create_bar_image(img_dir,img_basename):
img_path = os.path.join(img_dir,img_basename)
img_data, total_pixels = count_pixel(img_path,mode='bar')
c = (
Bar(init_opts=opts.InitOpts(width="610px",height="380px"))
.set_global_opts(legend_opts=opts.LegendOpts(is_show=False),yaxis_opts=opts.AxisOpts(min_=0,max_='1'))
.add_xaxis([''])
.add_yaxis(
"Unlabeled",
[round(img_data[0]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(0, 0, 0)'),
)
.add_yaxis(
"Person",
[round(img_data[1]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(192,128,128)'),
)
.add_yaxis(
"Bike",
[round(img_data[2]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(0,128,0)'),
)
.add_yaxis(
"Car",
[round(img_data[3]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(128,128,128)'),
)
.add_yaxis(
"Drone",
[round(img_data[4]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(128,0,0)'),
)
.add_yaxis(
"Boat",
[round(img_data[5]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(0,0,128)'),
)
.add_yaxis(
"Animal",
[round(img_data[6]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(192,0,128)'),
)
.add_yaxis(
"Obstacle",
[round(img_data[7]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(192,0,0)'),
)
.add_yaxis(
"Construction",
[round(img_data[8]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(192,128,0)'),
)
.add_yaxis(
"Vegetation",
[round(img_data[9]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(0,64,0)'),
)
.add_yaxis(
"Road",
[round(img_data[10]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(128,128,0)'),
)
.add_yaxis(
"Sky",
[round(img_data[11]/total_pixels,2)],
itemstyle_opts=opts.ItemStyleOpts(color='rgb(0,128,128)'),
)
)
make_snapshot(snapshot,c.render(),os.path.join('./video/chart_bar',img_basename).replace('jpg','png'))
def create_meter_image(img_dir,img_basename):
img_path = os.path.join(img_dir,img_basename)
green_pixels = count_pixel(img_path,mode='meter')
c = (
Gauge(init_opts=opts.InitOpts(width="350px", height="350px"))
.add(series_name="", data_pair=[["", green_pixels]],pointer=opts.GaugePointerOpts(length='70%',width=4))
.set_global_opts(
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(
color=[[0.15, "#fd666d"], [0.25, "#fddd60"], [1, "#91cc75"]], width=15
)
)
)
)
make_snapshot(snapshot,c.render(),os.path.join('./video/chart_meter',img_basename).replace('jpg','png'))
predict_img_dir = 'video/predict_png/grey_prediction/'
predict_imgs = os.listdir(predict_img_dir)
for pi in trange(len(predict_imgs)):
create_bar_image(predict_img_dir,predict_imgs[pi])
create_meter_image(predict_img_dir,predict_imgs[pi])
视频合成
%mkdir video/board
import numpy as np
from PIL import Image
from tqdm import trange
NUM_FRAMES = 1309 #总帧数
for pid in trange(NUM_FRAMES):
background_board = Image.open('board.jpg')
origin_frame = Image.open('video/origin_jpg/{}.jpg'.format(pid)).resize((660,370))
predict_frame = Image.open('video/predict_png/pseudo_color_prediction/{}.png'.format(pid)).resize((660,370))
bar_chart = Image.open('video/chart_bar/{}.png'.format(pid)).resize((620,340))
meter_chart = Image.open('video/chart_meter/{}.png'.format(pid)).resize((400,400))
bar_r,bar_g,bar_b,bar_a = bar_chart.split()
meter_r,meter_g,meter_b,meter_a = meter_chart.split()
background_board.paste(origin_frame,(120,230))
background_board.paste(predict_frame,(1150,230))
background_board.paste(bar_chart,(160,700),mask=bar_a)
background_board.paste(meter_chart,(1300,700),mask=meter_a)
background_board.save('video/board/{}.png'.format(pid))
import os
import cv2
def images_to_video(path,width,height,output_name):
fps = 30 # 帧率
num_frames = NUM_FRAMES
img_width = width
img_height = height
out = cv2.VideoWriter(output_name, cv2.VideoWriter_fourcc(*"mp4v"), fps,(img_width,img_height))
for i in trange(num_frames):
filepath = path +str(i) + ".png"
out.write(cv2.imread(filepath))
out.release()
images_to_video('video/board/',1920,1080,'borad.mp4')
总结
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END