

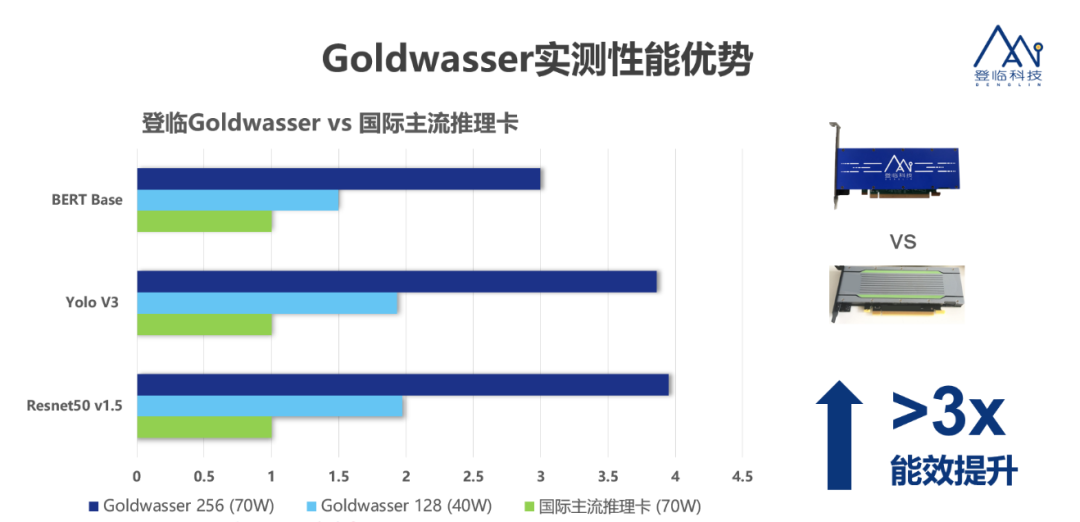
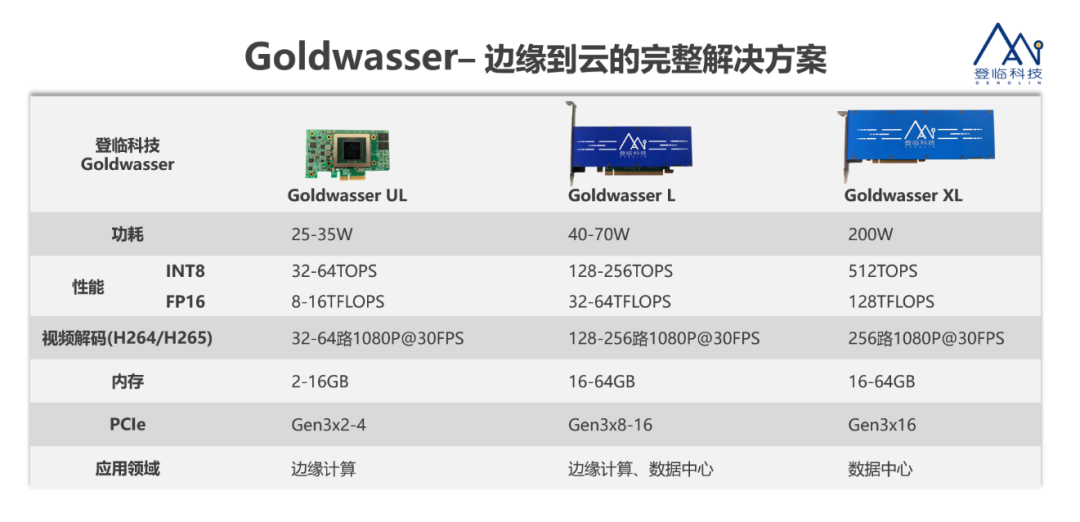

如何利用Paddle Inference
跑通登临GPU+产品
A. 环境准备
B. 用Paddle-dINNE进行推理
配置推理选项
import numpy as np
import paddle.inference as paddle_infer
#子图转onnx 子图工具
import p2o_converter
def create_predictor():
config = paddle_infer.Config("./resnet50/model", "./resnet50/params")
# 打开dlNNE。此接口的详细介绍请见下文
config.enable_dlnne(max_batch_size = 1,
min_subgraph_size = 3,
precision_mode=paddle_infer.PrecisionType.Float32)
predictor = paddle_infer.create_predictor(config)
return predictor
def run(predictor, img):
# 准备输入
input_names = predictor.get_input_names()
for i, name in enumerate(input_names):
input_tensor = predictor.get_input_handle(name)
input_tensor.reshape(img[i].shape)
input_tensor.copy_from_cpu(img[i].copy())
# 推理
predictor.run()
results = []
# 获取输出
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_handle(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
if __name__ == '__main__':
pred = create_predictor()
img = np.ones((1, 3, 224, 224)).astype(np.float32)
result = run(pred, [img])
print ("class index: ", np.argmax(result[0][0]))
config.enable_dlnne(max_batch_size = 1,
min_subgraph_size = 3,
precision_mode=paddle_infer.PrecisionType.Float32)enable_dlnne 接口各参数的介绍如下:
max_batch_size
precision_mode



飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END

如何利用Paddle Inference
跑通登临GPU+产品
A. 环境准备
B. 用Paddle-dINNE进行推理
配置推理选项
import numpy as np
import paddle.inference as paddle_infer
#子图转onnx 子图工具
import p2o_converter
def create_predictor():
config = paddle_infer.Config("./resnet50/model", "./resnet50/params")
# 打开dlNNE。此接口的详细介绍请见下文
config.enable_dlnne(max_batch_size = 1,
min_subgraph_size = 3,
precision_mode=paddle_infer.PrecisionType.Float32)
predictor = paddle_infer.create_predictor(config)
return predictor
def run(predictor, img):
# 准备输入
input_names = predictor.get_input_names()
for i, name in enumerate(input_names):
input_tensor = predictor.get_input_handle(name)
input_tensor.reshape(img[i].shape)
input_tensor.copy_from_cpu(img[i].copy())
# 推理
predictor.run()
results = []
# 获取输出
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_handle(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
if __name__ == '__main__':
pred = create_predictor()
img = np.ones((1, 3, 224, 224)).astype(np.float32)
result = run(pred, [img])
print ("class index: ", np.argmax(result[0][0]))
config.enable_dlnne(max_batch_size = 1,
min_subgraph_size = 3,
precision_mode=paddle_infer.PrecisionType.Float32)enable_dlnne 接口各参数的介绍如下:
max_batch_size
precision_mode
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END
