


Attention Mechanism
(注意力机制)
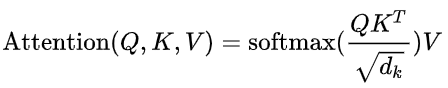
1.1 Self Attention(自注意力机制)
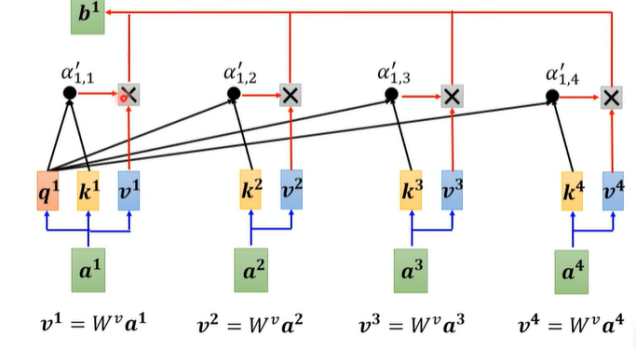
1.2 Multi-head Attention(多头注意力机制)
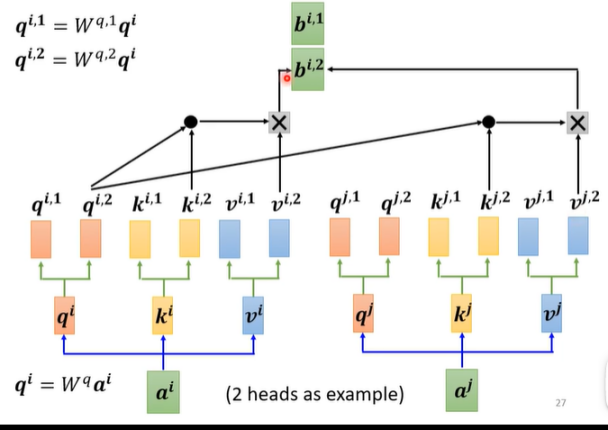
Encoder-Decoder
(编码器-解码器)
Transformer
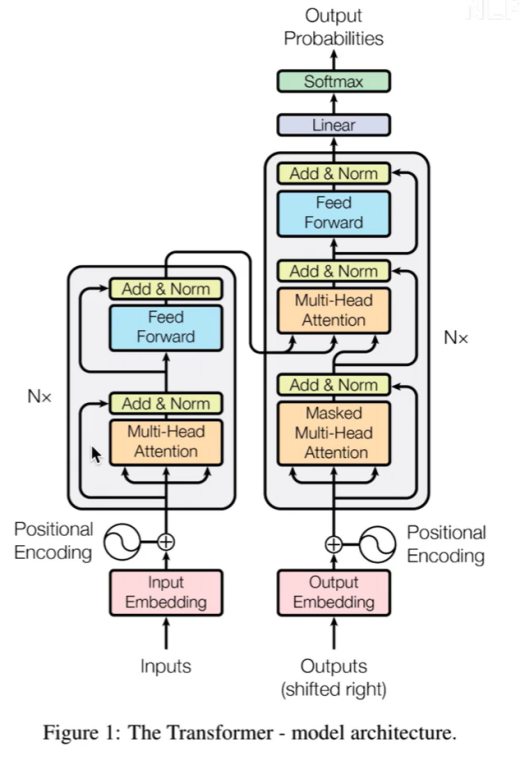
3.1 Encoder
输入部分:Embedding+位置嵌入
Attention Mechanism:上述已说明,此处应用的是Multi-head Attention(多头注意力机制)
FFN(Feed Forward Neural Network):上一步获得的Attention值会送到encoder的FFN模块。FFN是由两层Dense(全连接层)构成,采用ReLU作为激活函数。
3.2 Decoder
mask操作,是对当前单词和之后的单词做mask操作(NLP中的操作)因为是预测后面的词,所以不能让网络看见后面的词
进入Decoder的两条数据,是由Encoder产生的k、v,Decoder只提供q。
Vision Transformer
(ViT)
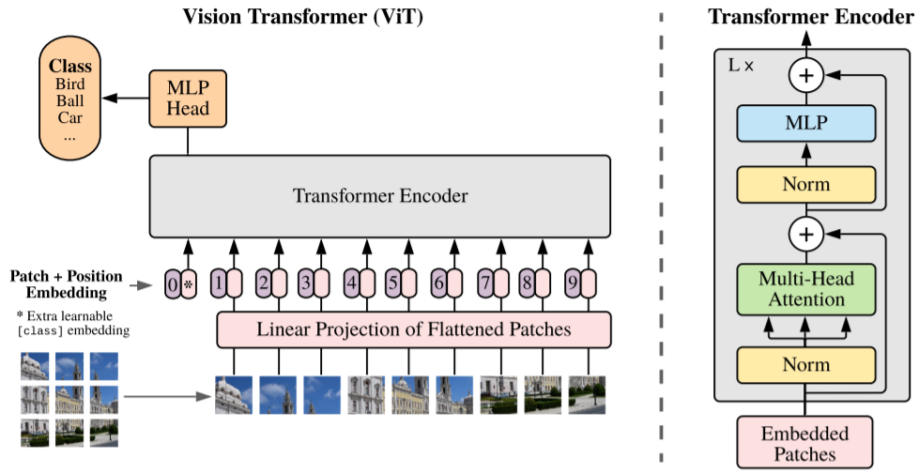
ViT是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。操作步骤如下:
图片分块,展开,做线性变换(形成与时间序列一致的输入)
在块序列首位置添加虚拟开始块,用作后续的图像分类特征
使用Transformer-Encoder进行块编码(ViT未使用Decoder结构)
虚拟块表示作为分类向量,通过MLP进行分类
项目开发框架-飞桨
(PaddlePaddle)
图像特征处理
# 获取图像特征
def forward_features(self, x):
B = x.shape[0]
# Image Patch Embedding
x = self.patch_embed(x)
# 分类 tokens
cls_tokens = self.cls_token.expand((B, -1, -1))
# 拼接 Embedding 和 分类 tokens
x = paddle.concat((cls_tokens, x), axis=1)
# 加入位置嵌入 Position Embedding
x = x + self.pos_embed
# Embedding Dropout
x = self.pos_drop(x)
# Transformer Encoder
# 由多个基础模块组成
for blk in self.blocks:
x = blk(x)
# Norm
x = self.norm(x)
# 提取分类 tokens 的输出
return x[:, 0]
def forward(self, x):
x = paddle.reshape(x, shape=[-1, 3,120,120])
# 获取图像特征
x = self.forward_features(x)
# 图像分类
x = self.head(x)
return x
模型搭建
class VisionTransformer(nn.Layer):
def __init__(self, img_size=120, patch_size=patch_size, in_chans=3, class_dim=train_parameters['class_dim'], embed_dim=dim, depth=num_layers,num_heads=heads, mlp_ratio=4, qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,drop_path_rate=0., norm_layer='nn.LayerNorm', epsilon=1e-5, **args):
super().__init__()
self.class_dim = class_dim # 分类数
self.num_features = self.embed_dim = embed_dim # 线性变换后输出张量的尺寸
# 调用之前定义PatchEmbed函数,此函数的操作:
# 保证图像一定能够完整切块,获取图像切块的个数
self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.pos_embed = self.create_parameter(shape=(1, num_patches + 1, embed_dim), default_initializer=zeros_) # 位置编码
self.add_parameter("pos_embed", self.pos_embed)
self.cls_token = self.create_parameter( # 分类令牌,可训练
shape=(1, 1, embed_dim), default_initializer=zeros_)
self.add_parameter("cls_token", self.cls_token)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x for x in paddle.linspace(0, drop_path_rate, depth)]
# 调用Block函数,此函数为Block类实现Transformer encoder的一个层
self.blocks = nn.LayerList([
Block( dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, epsilon=epsilon)
for i in range(depth)])
self.norm = eval(norm_layer)(embed_dim, epsilon=epsilon)
# Classifier head
self.head = nn.Linear(
embed_dim, class_dim) if class_dim > 0 else Identity()
trunc_normal_(self.pos_embed)
trunc_normal_(self.cls_token)
self.apply(self._init_weights)
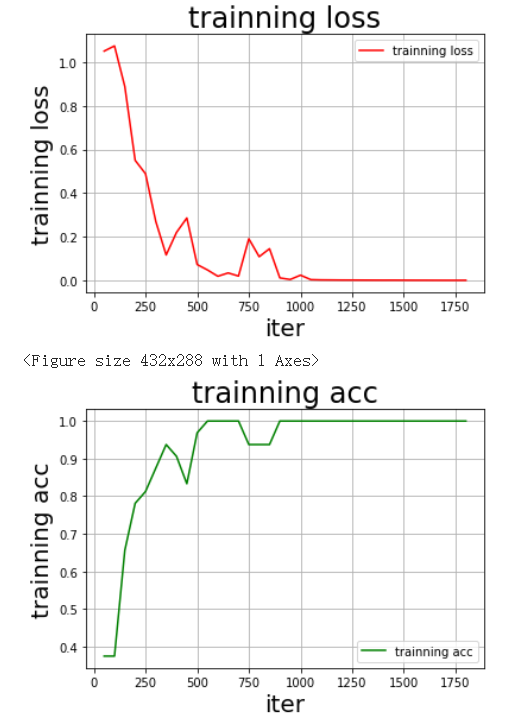
训练效果
小结

飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END

Attention Mechanism
(注意力机制)
1.1 Self Attention(自注意力机制)
1.2 Multi-head Attention(多头注意力机制)
Encoder-Decoder
(编码器-解码器)
Transformer
3.1 Encoder
输入部分:Embedding+位置嵌入
Attention Mechanism:上述已说明,此处应用的是Multi-head Attention(多头注意力机制)
FFN(Feed Forward Neural Network):上一步获得的Attention值会送到encoder的FFN模块。FFN是由两层Dense(全连接层)构成,采用ReLU作为激活函数。
3.2 Decoder
mask操作,是对当前单词和之后的单词做mask操作(NLP中的操作)因为是预测后面的词,所以不能让网络看见后面的词
进入Decoder的两条数据,是由Encoder产生的k、v,Decoder只提供q。
Vision Transformer
(ViT)
ViT是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。操作步骤如下:
图片分块,展开,做线性变换(形成与时间序列一致的输入)
在块序列首位置添加虚拟开始块,用作后续的图像分类特征
使用Transformer-Encoder进行块编码(ViT未使用Decoder结构)
虚拟块表示作为分类向量,通过MLP进行分类
项目开发框架-飞桨
(PaddlePaddle)
图像特征处理
# 获取图像特征
def forward_features(self, x):
B = x.shape[0]
# Image Patch Embedding
x = self.patch_embed(x)
# 分类 tokens
cls_tokens = self.cls_token.expand((B, -1, -1))
# 拼接 Embedding 和 分类 tokens
x = paddle.concat((cls_tokens, x), axis=1)
# 加入位置嵌入 Position Embedding
x = x + self.pos_embed
# Embedding Dropout
x = self.pos_drop(x)
# Transformer Encoder
# 由多个基础模块组成
for blk in self.blocks:
x = blk(x)
# Norm
x = self.norm(x)
# 提取分类 tokens 的输出
return x[:, 0]
def forward(self, x):
x = paddle.reshape(x, shape=[-1, 3,120,120])
# 获取图像特征
x = self.forward_features(x)
# 图像分类
x = self.head(x)
return x
模型搭建
class VisionTransformer(nn.Layer):
def __init__(self, img_size=120, patch_size=patch_size, in_chans=3, class_dim=train_parameters['class_dim'], embed_dim=dim, depth=num_layers,num_heads=heads, mlp_ratio=4, qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,drop_path_rate=0., norm_layer='nn.LayerNorm', epsilon=1e-5, **args):
super().__init__()
self.class_dim = class_dim # 分类数
self.num_features = self.embed_dim = embed_dim # 线性变换后输出张量的尺寸
# 调用之前定义PatchEmbed函数,此函数的操作:
# 保证图像一定能够完整切块,获取图像切块的个数
self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.pos_embed = self.create_parameter(shape=(1, num_patches + 1, embed_dim), default_initializer=zeros_) # 位置编码
self.add_parameter("pos_embed", self.pos_embed)
self.cls_token = self.create_parameter( # 分类令牌,可训练
shape=(1, 1, embed_dim), default_initializer=zeros_)
self.add_parameter("cls_token", self.cls_token)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x for x in paddle.linspace(0, drop_path_rate, depth)]
# 调用Block函数,此函数为Block类实现Transformer encoder的一个层
self.blocks = nn.LayerList([
Block( dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, epsilon=epsilon)
for i in range(depth)])
self.norm = eval(norm_layer)(embed_dim, epsilon=epsilon)
# Classifier head
self.head = nn.Linear(
embed_dim, class_dim) if class_dim > 0 else Identity()
trunc_normal_(self.pos_embed)
trunc_normal_(self.cls_token)
self.apply(self._init_weights)
训练效果
小结
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END