图像理解任务复杂多样,单纯的目标检测已经不能满足你了?
作为目标检测领域的扛把子,PaddleDetection当然不仅仅提供通用目标检测算法,还拥有多个业界先进、实用的关键点检测和多目标跟踪算法。除了可以准确识别、定位目标,还可以对移动的目标进行连续跟踪、分析路径,甚至进行姿态、行为分析!
再加上已有的超越YOLOv5的单阶段目标检测算法:PPYOLOv2、霸榜PaperWithCode的AnchorFree算法:PAFNet、旋转框检测、实例分割等等明星算法,PaddleDetection已经可以全方位、立体式地满足开发者各个维度的需求,助力你成为目标检测界的懂王!
这么用心研发的高水准产品,还不赶紧收藏上车!
传送门:
https://github.com/PaddlePaddle/PaddleDetection
下面,让我们来详细看看PaddleDetection最近上新的这两样“宝贝”:关键点检测和多目标跟踪,有什么厉害之处!
关键点检测
正如下图中展示的,关键点检测技术可以提取目标特定关键点的位置以及整体结构。以人体关键点检测为例,提取的信息则是人体关节位置以及关节点间的整体关联结构。
人体关键点检测在安防、医疗、影视等领域中有极广泛的应用场景,例如进行打斗等异常动作、运动分析评估、演员动作捕捉与姿态迁移等等。
除了可以检测人体关键点外,手部关键点也因为是实现人机、人车交互中手势识别的关键,被各界开发者高度重视。
而人脸关键点检测,更是人脸识别、脸部动作捕捉、迁移技术的基础支撑及核心关键。
还有很多业界大神基于关键点检测技术进行生物行为分析研究。
关键点检测技术这么神通广大,那它原理具体是怎样的呢?
以人体关键点检测为例,主流的算法分为top-down和bottom-up两大类。
像下图所示的,先检测出人,再对每个人分别检测关键点,就是Top-down的方式。也就是先使用检测算法得出图中每一个人体所在位置,对单个人的区域进行截图,再使用top-down关键点算法对每个单人截图进行单人关键点位置检测,最后再根据截图位置映射回原图。HRNet就是典型的Top-Down算法。
而bottom-up方法则相反:先对整图直接查找每一类关键点所在位置,然后各类关键点再根据特定规则进行group组合以区分属于的不同的人。近年比较优秀的算法HigherHRNet以及在其基础上的改进版SWAHR都属于这类算法。
无论你是明确的希望使用某一类方法,还是想要对两类方法进行对比、组合试验,PaddleDetection都能很好的满足你!
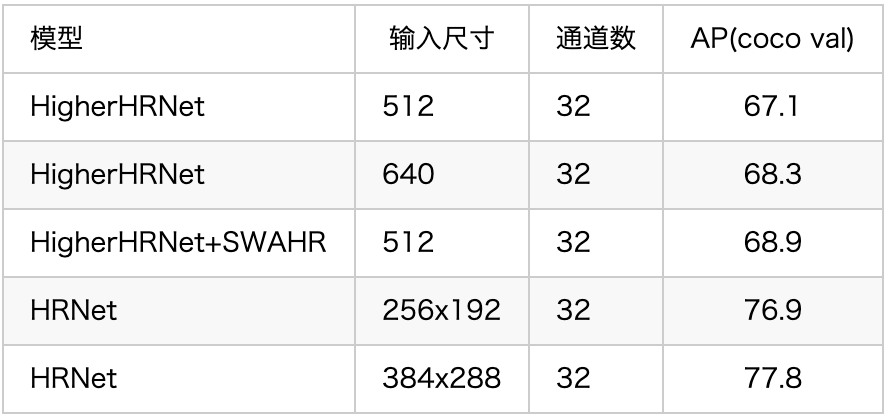
下面的表格就是PaddleDetection提供的两类经典算法在COCO数据集、不同输入尺寸下的数据展示。
多目标跟踪
多目标跟踪(Multiple Object Tracking,MOT)指的是在视频序列中同时检测多个目标的轨迹。它的应用范围也非常广泛,比如安防监控和自动驾驶等场景中的行人、车辆跟踪及轨迹分析等等。
当前主流的MOT策略是tracking by detection,这种策略将整个多目标跟踪任务拆分为两部分:检测 + Embedding。检测部分即针对视频,检测出每一帧中的潜在目标。Embedding则将检出的目标分配和更新到已有的对应轨迹上(即ReID重识别任务)。根据这两部分实现的顺序,主流的多目标跟踪算法可以划分为SDE系列和JDE系列2类。
下面,就让我们详细看看这两系列算法的区别:
SDE系列:
JDE系列:
不要以为我们只是说说罢了,这里我们介绍的这2系列3种多目标跟踪(MOT)算法,在PaddleDetection中都提供了高性能实现。
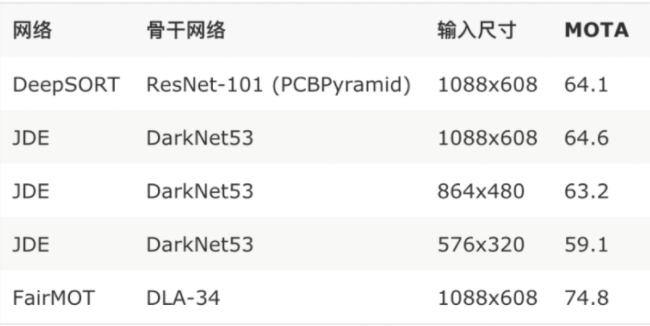
采用业界通用多目标检测评估方法:将6个公开数据集组成一个大规模、多标签的联合数据集(包括Caltech Pedestrian, CityPersons, CUHK-SYSU, PRW, ETHZ, MOT17和MOT16),其中MOT16作为评测数据集。采用MOTA作为评估指标,结果如下表所示:
在MOT-16 Test Set上结果
除此之外,PaddleDetection还可以将关键点检测和多目标技术相结合,获取更多人体姿态相关信息。例如我们使用多目标跟踪算法FairMot获取行人位置及id信息,结合关键点检测HRNet算法检测行人关键点得到最终输出结果,得到如下图所示效果:

PaddleDetection全貌
对PaddleDetection熟悉的小伙伴可能比较清楚,除了本篇介绍的关键点检测及多目标跟踪能力外,PaddleDetection作为中国产业实践中目标检测领域一柄重器,能力可谓完备而强大,简单的可以概括为以下三个方面:
全明星算法阵容:
全功能覆盖:
除全系列通用目标检测算法外,额外覆盖旋转框检测、实例分割、行人检测、人脸检测、车辆检测等垂类任务。
简单易用、全流程打通:
不仅全面支持动态图开发,可以顺畅的完成动静转化;还从数据预处理、算法训练调优、压缩、多端部署等全流程、各环节顺畅打通,极大程度地提升了用户开发的易用性,加速了算法产业应用落地的速度。
你还在等什么?!如此用心研发的高水准产品,还不赶紧Star收藏上车!
传送门:
https://github.com/PaddlePaddle/PaddleDetection
想要与官方开发团队交流?马上微信扫码加入PaddleDetection技术交流群!更多课程及产品动态,将在微信群里第一时间公告。
扫描上面二维码添加运营小姐姐微信
通过后回复「检测」系统自动邀请加入技术群
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END

图像理解任务复杂多样,单纯的目标检测已经不能满足你了?
作为目标检测领域的扛把子,PaddleDetection当然不仅仅提供通用目标检测算法,还拥有多个业界先进、实用的关键点检测和多目标跟踪算法。除了可以准确识别、定位目标,还可以对移动的目标进行连续跟踪、分析路径,甚至进行姿态、行为分析!
再加上已有的超越YOLOv5的单阶段目标检测算法:PPYOLOv2、霸榜PaperWithCode的AnchorFree算法:PAFNet、旋转框检测、实例分割等等明星算法,PaddleDetection已经可以全方位、立体式地满足开发者各个维度的需求,助力你成为目标检测界的懂王!
这么用心研发的高水准产品,还不赶紧收藏上车!
传送门:
https://github.com/PaddlePaddle/PaddleDetection
下面,让我们来详细看看PaddleDetection最近上新的这两样“宝贝”:关键点检测和多目标跟踪,有什么厉害之处!
关键点检测
正如下图中展示的,关键点检测技术可以提取目标特定关键点的位置以及整体结构。以人体关键点检测为例,提取的信息则是人体关节位置以及关节点间的整体关联结构。
人体关键点检测在安防、医疗、影视等领域中有极广泛的应用场景,例如进行打斗等异常动作、运动分析评估、演员动作捕捉与姿态迁移等等。
除了可以检测人体关键点外,手部关键点也因为是实现人机、人车交互中手势识别的关键,被各界开发者高度重视。
而人脸关键点检测,更是人脸识别、脸部动作捕捉、迁移技术的基础支撑及核心关键。
还有很多业界大神基于关键点检测技术进行生物行为分析研究。
关键点检测技术这么神通广大,那它原理具体是怎样的呢?
以人体关键点检测为例,主流的算法分为top-down和bottom-up两大类。
像下图所示的,先检测出人,再对每个人分别检测关键点,就是Top-down的方式。也就是先使用检测算法得出图中每一个人体所在位置,对单个人的区域进行截图,再使用top-down关键点算法对每个单人截图进行单人关键点位置检测,最后再根据截图位置映射回原图。HRNet就是典型的Top-Down算法。
而bottom-up方法则相反:先对整图直接查找每一类关键点所在位置,然后各类关键点再根据特定规则进行group组合以区分属于的不同的人。近年比较优秀的算法HigherHRNet以及在其基础上的改进版SWAHR都属于这类算法。
无论你是明确的希望使用某一类方法,还是想要对两类方法进行对比、组合试验,PaddleDetection都能很好的满足你!
下面的表格就是PaddleDetection提供的两类经典算法在COCO数据集、不同输入尺寸下的数据展示。
多目标跟踪
多目标跟踪(Multiple Object Tracking,MOT)指的是在视频序列中同时检测多个目标的轨迹。它的应用范围也非常广泛,比如安防监控和自动驾驶等场景中的行人、车辆跟踪及轨迹分析等等。
当前主流的MOT策略是tracking by detection,这种策略将整个多目标跟踪任务拆分为两部分:检测 + Embedding。检测部分即针对视频,检测出每一帧中的潜在目标。Embedding则将检出的目标分配和更新到已有的对应轨迹上(即ReID重识别任务)。根据这两部分实现的顺序,主流的多目标跟踪算法可以划分为SDE系列和JDE系列2类。
下面,就让我们详细看看这两系列算法的区别:
SDE系列:
JDE系列:
不要以为我们只是说说罢了,这里我们介绍的这2系列3种多目标跟踪(MOT)算法,在PaddleDetection中都提供了高性能实现。
采用业界通用多目标检测评估方法:将6个公开数据集组成一个大规模、多标签的联合数据集(包括Caltech Pedestrian, CityPersons, CUHK-SYSU, PRW, ETHZ, MOT17和MOT16),其中MOT16作为评测数据集。采用MOTA作为评估指标,结果如下表所示:
在MOT-16 Test Set上结果
除此之外,PaddleDetection还可以将关键点检测和多目标技术相结合,获取更多人体姿态相关信息。例如我们使用多目标跟踪算法FairMot获取行人位置及id信息,结合关键点检测HRNet算法检测行人关键点得到最终输出结果,得到如下图所示效果:
PaddleDetection全貌
对PaddleDetection熟悉的小伙伴可能比较清楚,除了本篇介绍的关键点检测及多目标跟踪能力外,PaddleDetection作为中国产业实践中目标检测领域一柄重器,能力可谓完备而强大,简单的可以概括为以下三个方面:
全明星算法阵容:
全功能覆盖:
除全系列通用目标检测算法外,额外覆盖旋转框检测、实例分割、行人检测、人脸检测、车辆检测等垂类任务。
简单易用、全流程打通:
不仅全面支持动态图开发,可以顺畅的完成动静转化;还从数据预处理、算法训练调优、压缩、多端部署等全流程、各环节顺畅打通,极大程度地提升了用户开发的易用性,加速了算法产业应用落地的速度。
你还在等什么?!如此用心研发的高水准产品,还不赶紧Star收藏上车!
传送门:
https://github.com/PaddlePaddle/PaddleDetection
想要与官方开发团队交流?马上微信扫码加入PaddleDetection技术交流群!更多课程及产品动态,将在微信群里第一时间公告。
扫描上面二维码添加运营小姐姐微信
通过后回复「检测」系统自动邀请加入技术群
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END