

机器翻译(machine translation, MT)是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程,输入为源语言句子,输出为相应的目标语言的句子。
本项目是机器翻译领域主流模型 Transformer 的 PaddlePaddle 实现, 包含模型训练,预测以及使用自定义数据等内容。用户可以基于发布的内容搭建自己的翻译模型。
同时推荐用户参考 IPython Notebook demo
paddle安装
本项目依赖于 PaddlePaddle 1.6及以上版本或适当的develop版本,请参考 安装指南 进行安装
下载代码
克隆代码库到本地
git clone https://github.com/PaddlePaddle/models.git
cd models/PaddleNLP/PaddleMT/transformer环境依赖
请参考PaddlePaddle安装说明部分的内容
公开数据集:WMT 翻译大赛是机器翻译领域最具权威的国际评测大赛,其中英德翻译任务提供了一个中等规模的数据集,这个数据集是较多论文中使用的数据集,也是 Transformer 论文中用到的一个数据集。我们也将WMT'16 EN-DE 数据集作为示例提供。运行 gen_data.sh 脚本进行 WMT'16 EN-DE 数据集的下载和预处理(时间较长,建议后台运行)。数据处理过程主要包括 Tokenize 和 BPE 编码(byte-pair encoding)。运行成功后,将会生成文件夹 gen_data,其目录结构如下:
.
├── wmt16_ende_data # WMT16 英德翻译数据
├── wmt16_ende_data_bpe # BPE 编码的 WMT16 英德翻译数据
├── mosesdecoder # Moses 机器翻译工具集,包含了 Tokenize、BLEU 评估等脚本
└── subword-nmt # BPE 编码的代码另外我们也整理提供了一份处理好的 WMT'16 EN-DE 数据以供下载使用,其中包含词典(vocab_all.bpe.32000文件)、训练所需的 BPE 数据(train.tok.clean.bpe.32000.en-de文件)、预测所需的 BPE 数据(newstest2016.tok.bpe.32000.en-de等文件)和相应的评估预测结果所需的 tokenize 数据(newstest2016.tok.de等文件)。
自定义数据:如果需要使用自定义数据,本项目程序中可直接支持的数据格式为制表符 \t 分隔的源语言和目标语言句子对,句子中的 token 之间使用空格分隔。提供以上格式的数据文件(可以分多个part,数据读取支持文件通配符)和相应的词典文件即可直接运行。
以提供的英德翻译数据为例,可以执行以下命令进行模型训练:
# open garbage collection to save memory
export FLAGS_eager_delete_tensor_gb=0.0
# setting visible devices for training
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
python -u main.py \
--do_train True \
--epoch 30 \
--src_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--trg_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--special_token '<s>' '<e>' '<unk>' \
--training_file gen_data/wmt16_ende_data_bpe/train.tok.clean.bpe.32000.en-de \
--batch_size 4096以上命令中传入了执行训练(do_train)、训练轮数(epoch)和训练数据文件路径(注意请正确设置,支持通配符)等参数,更多参数的使用以及支持的模型超参数可以参见 transformer.yaml 配置文件,其中默认提供了 Transformer base model 的配置,如需调整可以在配置文件中更改或通过命令行传入(命令行传入内容将覆盖配置文件中的设置)。可以通过以下命令来训练 Transformer 论文中的 big model:
# open garbage collection to save memory
export FLAGS_eager_delete_tensor_gb=0.0
# setting visible devices for training
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
python -u main.py \
--do_train True \
--epoch 30 \
--src_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--trg_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--special_token '<s>' '<e>' '<unk>' \
--training_file gen_data/wmt16_ende_data_bpe/train.tok.clean.bpe.32000.en-de \
--batch_size 4096 \
--n_head 16 \
--d_model 1024 \
--d_inner_hid 4096 \
--prepostprocess_dropout 0.3训练时默认使用所有 GPU,可以通过 CUDA_VISIBLE_DEVICES 环境变量来设置使用的 GPU 数目。也可以只使用 CPU 训练(通过参数 --use_cuda False 设置),训练速度相对较慢。在执行训练时若提供了 save_model_path(默认为 saved_models),则每隔一定 iteration 后(通过参数 save_step 设置,默认为10000)将保存当前训练的 checkpoint 到相应目录(会保存分别记录了模型参数和优化器状态的 transformer.pdparams 和 transformer.pdopt 两个文件),每隔一定数目的 iteration (通过参数 print_step 设置,默认为100)将打印如下的日志到标准输出:
[2019-08-02 15:30:51,656 INFO train.py:262] step_idx: 150100, epoch: 32, batch: 1364, avg loss: 2.880427, normalized loss: 1.504687, ppl: 17.821888, speed: 3.34 step/s
[2019-08-02 15:31:19,824 INFO train.py:262] step_idx: 150200, epoch: 32, batch: 1464, avg loss: 2.955965, normalized loss: 1.580225, ppl: 19.220257, speed: 3.55 step/s
[2019-08-02 15:31:48,151 INFO train.py:262] step_idx: 150300, epoch: 32, batch: 1564, avg loss: 2.951180, normalized loss: 1.575439, ppl: 19.128502, speed: 3.53 step/s
[2019-08-02 15:32:16,401 INFO train.py:262] step_idx: 150400, epoch: 32, batch: 1664, avg loss: 3.027281, normalized loss: 1.651540, ppl: 20.641024, speed: 3.54 step/s
[2019-08-02 15:32:44,764 INFO train.py:262] step_idx: 150500, epoch: 32, batch: 1764, avg loss: 3.069125, normalized loss: 1.693385, ppl: 21.523066, speed: 3.53 step/s
[2019-08-02 15:33:13,199 INFO train.py:262] step_idx: 150600, epoch: 32, batch: 1864, avg loss: 2.869379, normalized loss: 1.493639, ppl: 17.626074, speed: 3.52 step/s
[2019-08-02 15:33:41,601 INFO train.py:262] step_idx: 150700, epoch: 32, batch: 1964, avg loss: 2.980905, normalized loss: 1.605164, ppl: 19.705633, speed: 3.52 step/s
[2019-08-02 15:34:10,079 INFO train.py:262] step_idx: 150800, epoch: 32, batch: 2064, avg loss: 3.047716, normalized loss: 1.671976, ppl: 21.067181, speed: 3.51 step/s
[2019-08-02 15:34:38,598 INFO train.py:262] step_idx: 150900, epoch: 32, batch: 2164, avg loss: 2.956475, normalized loss: 1.580735, ppl: 19.230072, speed: 3.51 step/s以英德翻译数据为例,模型训练完成后可以执行以下命令对指定文件中的文本进行翻译:
# open garbage collection to save memory
export FLAGS_eager_delete_tensor_gb=0.0
# setting visible devices for prediction
export CUDA_VISIBLE_DEVICES=0
python -u main.py \
--do_predict True \
--src_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--trg_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--special_token '<s>' '<e>' '<unk>' \
--predict_file gen_data/wmt16_ende_data_bpe/newstest2014.tok.bpe.32000.en-de \
--batch_size 32 \
--init_from_params trained_params/step_100000 \
--beam_size 5 \
--max_out_len 255 \
--output_file predict.txt 由 predict_file 指定的文件中文本的翻译结果会输出到 output_file 指定的文件。执行预测时需要设置 init_from_params 来给出模型所在目录,更多参数的使用可以在 transformer.yaml 文件中查阅注释说明并进行更改设置。注意若在执行预测时设置了模型超参数,应与模型训练时的设置一致,如若训练时使用 big model 的参数设置,则预测时对应类似如下命令:
# open garbage collection to save memory
export FLAGS_eager_delete_tensor_gb=0.0
# setting visible devices for prediction
export CUDA_VISIBLE_DEVICES=0
python -u main.py \
--do_predict True \
--src_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--trg_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--special_token '<s>' '<e>' '<unk>' \
--predict_file gen_data/wmt16_ende_data_bpe/newstest2014.tok.bpe.32000.en-de \
--batch_size 32 \
--init_from_params trained_params/step_100000 \
--beam_size 5 \
--max_out_len 255 \
--output_file predict.txt \
--n_head 16 \
--d_model 1024 \
--d_inner_hid 4096 \
--prepostprocess_dropout 0.3预测结果中每行输出是对应行输入的得分最高的翻译,对于使用 BPE 的数据,预测出的翻译结果也将是 BPE 表示的数据,要还原成原始的数据(这里指 tokenize 后的数据)才能进行正确的评估。评估过程具体如下(BLEU 是翻译任务常用的自动评估方法指标):
# 还原 predict.txt 中的预测结果为 tokenize 后的数据
sed -r 's/(@@ )|(@@ ?$)//g' predict.txt > predict.tok.txt
# 若无 BLEU 评估工具,需先进行下载
# git clone https://github.com/moses-smt/mosesdecoder.git
# 以英德翻译 newstest2014 测试数据为例
perl gen_data/mosesdecoder/scripts/generic/multi-bleu.perl gen_data/wmt16_ende_data/newstest2014.tok.de < predict.tok.txt可以看到类似如下的结果:
BLEU = 26.35, 57.7/32.1/20.0/13.0 (BP=1.000, ratio=1.013, hyp_len=63903, ref_len=63078)使用本项目中提供的内容,英德翻译 base model 和 big model 八卡训练 100K 个 iteration 后测试有大约如下的 BLEU 值:
| 测试集 | newstest2014 | newstest2015 | newstest2016 |
|---|---|---|---|
| Base | 26.35 | 29.07 | 33.30 |
| Big | 27.07 | 30.09 | 34.38 |
我们这里提供了对应有以上 BLEU 值的 base model 和 big model 的模型参数提供下载使用(注意,模型使用了提供下载的数据进行训练和测试)。
Transformer 是论文 Attention Is All You Need 中提出的用以完成机器翻译(machine translation, MT)等序列到序列(sequence to sequence, Seq2Seq)学习任务的一种全新网络结构,其完全使用注意力(Attention)机制来实现序列到序列的建模1。
相较于此前 Seq2Seq 模型中广泛使用的循环神经网络(Recurrent Neural Network, RNN),使用(Self)Attention 进行输入序列到输出序列的变换主要具有以下优势:
O(n * d * d) (n 个时间步,每个时间步计算 d 维的矩阵向量乘法),在 Self-Attention 中计算复杂度为 O(n * n * d) (n 个时间步两两计算 d 维的向量点积或其他相关度函数),n 通常要小于 d 。Transformer 中引入使用的基于 Self-Attention 的序列建模模块结构,已被广泛应用在 Bert 2等语义表示模型中,取得了显著效果。
Transformer 同样使用了 Seq2Seq 模型中典型的编码器-解码器(Encoder-Decoder)的框架结构,整体网络结构如图1所示。
![]()
图 1. Transformer 网络结构图
可以看到,和以往 Seq2Seq 模型不同,Transformer 的 Encoder 和 Decoder 中不再使用 RNN 的结构。
Transformer 中的 Encoder 由若干相同的 layer 堆叠组成,每个 layer 主要由多头注意力(Multi-Head Attention)和全连接的前馈(Feed-Forward)网络这两个 sub-layer 构成。
此外,每个 sub-layer 后还施以 Residual Connection 3和 Layer Normalization 4来促进梯度传播和模型收敛。
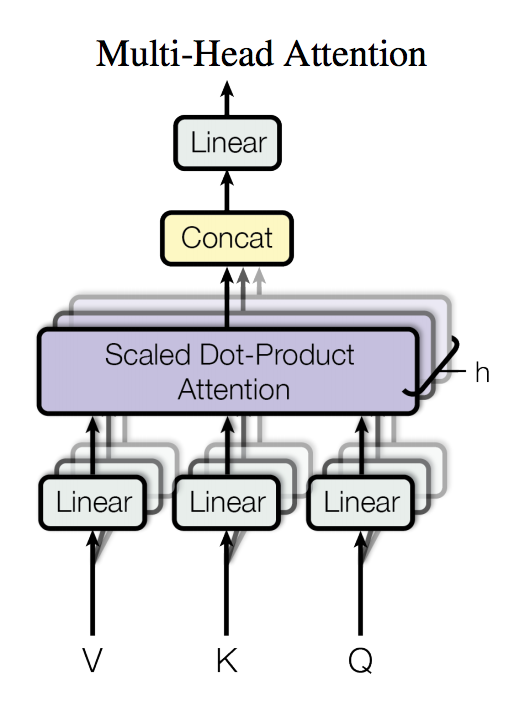
图 2. Multi-Head Attention
Decoder 具有和 Encoder 类似的结构,只是相比于组成 Encoder 的 layer ,在组成 Decoder 的 layer 中还多了一个 Multi-Head Attention 的 sub-layer 来实现对 Encoder 输出的 Attention,这个 Encoder-Decoder Attention 在其他 Seq2Seq 模型中也是存在的。
Q: 预测结果中样本数少于输入的样本数是什么原因
A: 若样本中最大长度超过 transformer.yaml 中 max_length 的默认设置,请注意运行时增大 --max_length 的设置,否则超长样本将被过滤。
Q: 预测时最大长度超过了训练时的最大长度怎么办
A: 由于训练时 max_length 的设置决定了保存模型 position encoding 的大小,若预测时长度超过 max_length,请调大该值,会重新生成更大的 position encoding 表。
2019/08/16 进行了规范化,更新了 Paddle 接口的使用
如果你可以修复某个issue或者增加一个新功能,欢迎给我们提交PR。如果对应的PR被接受了,我们将根据贡献的质量和难度进行打分(0-5分,越高越好)。如果你累计获得了10分,可以联系我们获得面试机会或者为你写推荐信。
![]()
图 1. Transformer 网络结构图
图 2. Multi-Head Attention
{kind=link}