

运行本目录下的程序示例需要使用PaddlePaddle v1.0 版本。如果您的PaddlePaddle安装版本低于此要求,请按照安装文档 中的说明更新PaddlePaddle安装版本。
以下是本例目录包含的文件以及对应说明:
.
├── sentiment.py # 情感倾向分析主函数,包括训练、预估、预测部分
├── nets.py # 本例中涉及的各种网络结构均定义在此文件中,若进一步修改模型结构,请查看此文件
├── utils.py # 定义通用的函数,例如加载词典,读入数据等
├── README.md # 说明文档
├── C-API # 模型预测C-API接口情感倾向分析针对带有主观描述的中文文本,可自动判断该文本的情感极性类别并给出相应的置信度。情感类型分为积极、消极、 中性。情感倾向分析能够帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为企业提供有力的决策支持。本次我们开放 AI开放平台中情感倾向分析采用的模型(http://ai.baidu.com/tech/nlp/sentiment_classify ), 提供给用户使用。
nets.py 中包含一下模型:
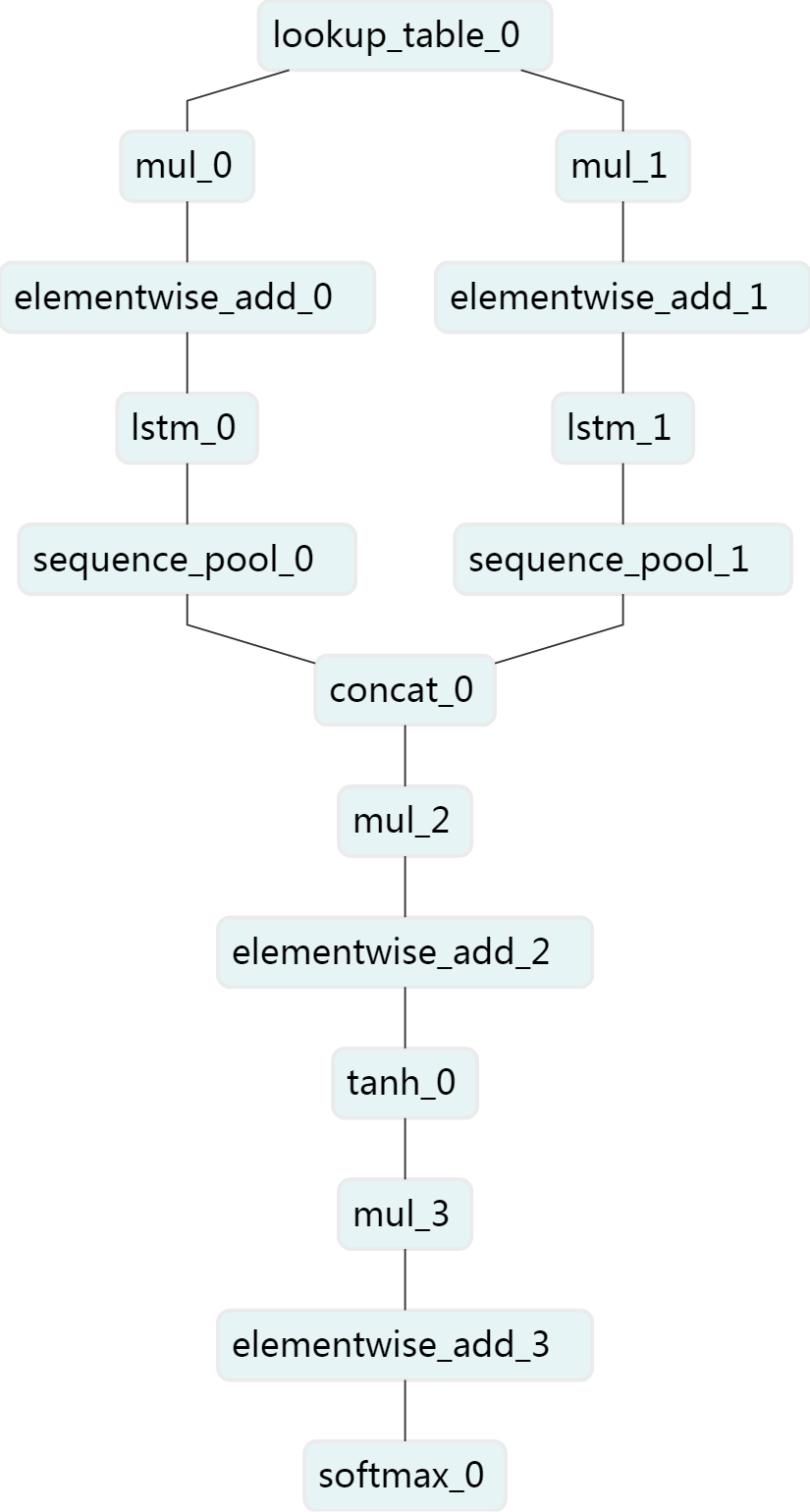
bow_net:Bow(Bag Of Words)模型,是一个非序列模型。使用基本的全连接结构。cnn_net:浅层CNN模型,是一个基础的序列模型,能够处理变长的序列输入,提取一个局部区域之内的特征。gru_net:单层GRU模型,序列模型,能够较好地解序列文本中长距离依赖的问题。lstm_net:单层LSTM模型,序列模型,能够较好地解决序列文本中长距离依赖的问题。bilstm_net:双向单层LSTM模型,序列模型,通过采用双向lstm结构,更好地捕获句子中的语义特征。AI平台上情感倾向分析模块采用此模型进行训练和预测。数据格式:每一行为一条样本,以`\t`分隔,第一列是类别标签,第二列是输入文本的内容,文本内容中的词语以空格间隔。以下是两条示例数据:
```
2 特 喜欢 这种 好看的 狗狗
2 这 真是 惊艳 世界 的 中国 黑科技
0 环境 特别 差 ,脏兮兮 的 ,再也 不去 了
```
注:我们在data目录下,提供了少量的训练和测试示例数据,详见data/train_data/corpus.train和data/test_data/corpus.test根据上述训练数据,统计出现的词语构建词典,供模型训练使用(可以根据词频对词典的大小进行限制),词典的格式为:每行一个词典项,以下是词典的示例:
```
喜欢
特
脏兮兮
...
```
注:我们在data目录下,提供了示例词典数据,详见data/train.vocab python sentiment_classify.py \
--train_data_path ./data/train_data/corpus.train \ # 训练数据路径
--word_dict_path ./data/train.vocab \ # 词典路径
--mode train \ # train模式
--model_path ./models # 模型保存路径 python sentiment_classify.py \
--test_data_path ./data/test_data/corpus.test \ # 测试数据路径
--word_dict_path ./data/train.vocab \ # 词典路径
--mode eval \ # eval模式
--model_path ./models/epoch0/ # 预测模型路径 python sentiment_classify.py \
--test_data_path ./data/test_data/corpus.test \ # 测试数据路径
--word_dict_path ./data/train.vocab \ # 词典路径
--mode infer \ # infer模式
--model_path ./models/epoch0/ # 预测模型路径本教程还提供了C-API的预测方式,C-API中接入了lac模块(github/baidu/lac)用于分词处理,调用C-API的方式如下所示:$ git clone https://github.com/PaddlePaddle/Paddle.git
$ cd Paddle
$ git checkout v0.14.0增加一行:SET(CMAKE_CXX_COMPILER "g++的绝对路径")
例如:SET(CMAKE_CXX_COMPILER "/opt/compiler/gcc-4.8.2/bin/g++")$ mkdir build
$ cd build
cmake -DCMAKE_BUILD_TYPE=Release -DWITH_PYTHON=OFF -DWITH_MKL=ON -DWITH_MKLDNN=OFF -DWITH_GPU=OFF -DWITH_FLUID_ONLY=ON ..编译PaddlePaddle并部署Fluid Inference, 默认部署到Paddle/build/fluid_install_dir
$ make
$ make inference_lib_dist配置boost库
$ cp third_party/boost/src/extern_boost/boost_1_41_0.tar.gz fluid_install_dir/third_party/install/
$ cd fluid_install_dir/third_party/install/
$ tar zxvf boost_1_41_0.tar.gz
$ rm boost_1_41_0.tar.gz
$ cd -克隆lac代码,修改Makefile
cd fluid_install_dir/third_party/install/
git clone https://github.com/baidu/lac
修改CMakeList.txt, 将:
SET(PADDLE_ROOT ../../../fluid_install_dir)
改为
SET(PADDLE_ROOT 你的PaddlePaddle Fluid Inference部署路径)编译lac代码
$ cmake .
$ make install克隆本模块代码,添加环境变量,编译
git clone https://github.com/baidu/Senta
export PADDLE_ROOT=你的PaddlePaddle Fluid Inference部署路径
export GCC_BIN=你的g++绝对路径(4.8.2版本)
cd C-API
make clean;make预测运行配置config的目录结构如下(可通过C-API/download.sh下载获得):
.
├─Senta # 情感倾向分析模型
├─lac/conf # lac模(可在git上下载最新lac模型使用:https://github.com/baidu/lac)
├─train.vocab # 训练数据词典(见上面数据准备)添加动态库路径(首次运行):
export LD_LIBRARY_PATH=${PADDLE_ROOT}/third_party/install/mklml/lib: \
${PADDLE_ROOT}/paddle/fluid/inference:$LD_LIBRARY_PATH
运行预测
./bin/senti_cls_dnn \
./config \ # 模型路径(包括lac+情感分类模型)
5 \ # 线程数
< test.txt我们在C-API目录下给出了bilstm_net模型的下载脚本download.sh,可供用户下载使用(模型可支持C-API、python两种预测方式),该模型在百度自建数据集上的效果分类准确率为90%。
如果你可以修复某个issue或者增加一个新功能,欢迎给我们提交PR。如果对应的PR被接受了,我们将根据贡献的质量和难度 进行打分(0-5分,越高越好)。如果你累计获得了10分,可以联系我们获得面试机会或为你写推荐信。
提交PR前请确定你的代码符合如下要求:
{kind=link}