

以下是本例的简要目录结构及说明:
.
├── README.md # 文档
├── train.py # 训练脚本 全词表 cross-entropy
├── train_sample_neg.py # 训练脚本 sample负例 包含bpr loss 和cross-entropy
├── infer.py # 预测脚本 全词表
├── infer_sample_neg.py # 预测脚本 sample负例
├── net.py # 网络结构
├── text2paddle.py # 文本数据转paddle数据
├── cluster_train.py # 多机训练
├── cluster_train.sh # 多机训练脚本
├── utils # 通用函数
├── convert_format.py # 转换数据格式
├── vocab.txt # 小样本字典
├── train_data # 小样本训练目录
└── test_data # 小样本测试目录GRU4REC模型的介绍可以参阅论文Session-based Recommendations with Recurrent Neural Networks。
论文的贡献在于首次将RNN(GRU)运用于session-based推荐,相比传统的KNN和矩阵分解,效果有明显的提升。
论文的核心思想是在一个session中,用户点击一系列item的行为看做一个序列,用来训练RNN模型。预测阶段,给定已知的点击序列作为输入,预测下一个可能点击的item。
session-based推荐应用场景非常广泛,比如用户的商品浏览、新闻点击、地点签到等序列数据。
支持三种形式的损失函数, 分别是全词表的cross-entropy, 负采样的Bayesian Pairwise Ranking和负采样的Cross-entropy.
我们基本复现了论文效果,recall@20的效果分别为
全词表 cross entropy : 0.67
负采样 bpr : 0.606
负采样 cross entropy : 0.605
运行样例程序可跳过'RSC15 数据下载及预处理'部分
运行命令 下载RSC15官网数据集
curl -Lo yoochoose-data.7z https://s3-eu-west-1.amazonaws.com/yc-rdata/yoochoose-data.7z
7z x yoochoose-data.7zGRU4REC的数据过滤,下载脚本https://github.com/hidasib/GRU4Rec/blob/master/examples/rsc15/preprocess.py,
注意修改文件路径
line12: PATH_TO_ORIGINAL_DATA = './'
line13:PATH_TO_PROCESSED_DATA = './'
注意使用python3 执行脚本
python preprocess.py生成的数据格式如下
SessionId ItemId Time
1 214536502 1396839069.277
1 214536500 1396839249.868
1 214536506 1396839286.998
1 214577561 1396839420.306
2 214662742 1396850197.614
2 214662742 1396850239.373
2 214825110 1396850317.446
2 214757390 1396850390.71
2 214757407 1396850438.247数据格式需要转换, 运行脚本如下
python convert_format.py模型的训练及测试数据如下,一行表示一个用户按照时间顺序的序列
214536502 214536500 214536506 214577561
214662742 214662742 214825110 214757390 214757407 214551617
214716935 214774687 214832672
214836765 214706482
214701242 214826623
214826835 214826715
214838855 214838855
214576500 214576500 214576500
214821275 214821275 214821371 214821371 214821371 214717089 214563337 214706462 214717436 214743335 214826837 214819762
214717867 214717867根据训练和测试文件生成字典和对应的paddle输入文件
需要将训练文件放到目录raw_train_data下,测试文件放到目录raw_test_data下,并生成对应的train_data,test_data和vocab.txt文件
python text2paddle.py raw_train_data/ raw_test_data/ train_data test_data vocab.txt转化后生成的格式如下,可参考train_data/small_train.txt
197 196 198 236
93 93 384 362 363 43
336 364 407
421 322
314 388
128 58
138 138
46 46 46
34 34 57 57 57 342 228 321 346 357 59 376
110 110具体的参数配置可运行
python train.py -h全词表cross entropy 训练代码
gpu 单机单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py --train_dir train_data --use_cuda 1 --batch_size 50 --model_dir model_outputcpu 单机训练
python train.py --train_dir train_data --use_cuda 0 --batch_size 50 --model_dir model_outputgpu 单机多卡训练
CUDA_VISIBLE_DEVICES=0,1 python train.py --train_dir train_data --use_cuda 1 --parallel 1 --batch_size 50 --model_dir model_output --num_devices 2cpu 单机多卡训练
CPU_NUM=10 python train.py --train_dir train_data --use_cuda 0 --parallel 1 --batch_size 50 --model_dir model_output --num_devices 10负采样 bayesian pairwise ranking loss(bpr loss) 训练
CUDA_VISIBLE_DEVICES=0 python train_sample_neg.py --loss bpr --use_cuda 1负采样 cross entropy 训练
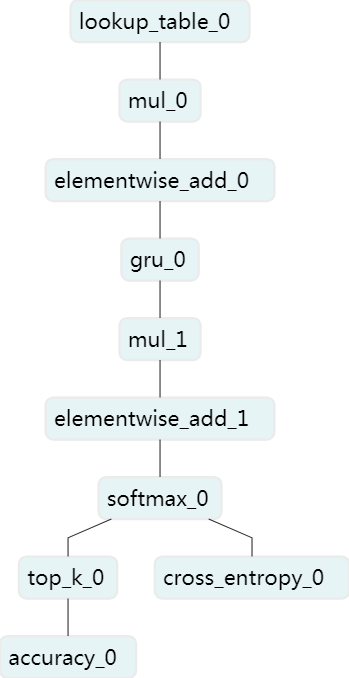
CUDA_VISIBLE_DEVICES=0 python train_sample_neg.py --loss ce --use_cuda 1可在net.py network 函数中调整网络结构,当前的网络结构如下:
emb = fluid.layers.embedding(
input=src,
size=[vocab_size, hid_size],
param_attr=fluid.ParamAttr(
initializer=fluid.initializer.Uniform(
low=init_low_bound, high=init_high_bound),
learning_rate=emb_lr_x),
is_sparse=True)
fc0 = fluid.layers.fc(input=emb,
size=hid_size * 3,
param_attr=fluid.ParamAttr(
initializer=fluid.initializer.Uniform(
low=init_low_bound, high=init_high_bound),
learning_rate=gru_lr_x))
gru_h0 = fluid.layers.dynamic_gru(
input=fc0,
size=hid_size,
param_attr=fluid.ParamAttr(
initializer=fluid.initializer.Uniform(
low=init_low_bound, high=init_high_bound),
learning_rate=gru_lr_x))
fc = fluid.layers.fc(input=gru_h0,
size=vocab_size,
act='softmax',
param_attr=fluid.ParamAttr(
initializer=fluid.initializer.Uniform(
low=init_low_bound, high=init_high_bound),
learning_rate=fc_lr_x))
cost = fluid.layers.cross_entropy(input=fc, label=dst)
acc = fluid.layers.accuracy(input=fc, label=dst, k=20)我们在Tesla K40m单GPU卡上训练的日志如下所示
epoch_1 start
step:100 ppl:441.468
step:200 ppl:311.043
step:300 ppl:218.952
step:400 ppl:186.172
step:500 ppl:188.600
step:600 ppl:131.213
step:700 ppl:165.770
step:800 ppl:164.414
step:900 ppl:156.470
step:1000 ppl:174.201
step:1100 ppl:118.619
step:1200 ppl:122.635
step:1300 ppl:118.220
step:1400 ppl:90.372
step:1500 ppl:135.018
step:1600 ppl:114.327
step:1700 ppl:141.806
step:1800 ppl:93.416
step:1900 ppl:92.897
step:2000 ppl:121.703
step:2100 ppl:96.288
step:2200 ppl:88.355
step:2300 ppl:101.737
step:2400 ppl:95.934
step:2500 ppl:86.158
step:2600 ppl:80.925
step:2700 ppl:202.219
step:2800 ppl:106.828
step:2900 ppl:91.458
step:3000 ppl:105.988
step:3100 ppl:87.067
step:3200 ppl:92.651
step:3300 ppl:101.145
step:3400 ppl:91.247
step:3500 ppl:107.656
step:3600 ppl:89.410
...
...
step:15700 ppl:76.819
step:15800 ppl:62.257
step:15900 ppl:81.735
epoch:1 num_steps:15907 time_cost(s):4154.096032
model saved in model_recall20/epoch_1
...运行命令 全词表运行infer.py, 负采样运行infer_sample_neg.py。
CUDA_VISIBLE_DEVICES=0 python infer.py --test_dir test_data/ --model_dir model_output/ --start_index 1 --last_index 10 --use_cuda 1model:model_r@20/epoch_1 recall@20:0.613 time_cost(s):12.23
model:model_r@20/epoch_2 recall@20:0.647 time_cost(s):12.33
model:model_r@20/epoch_3 recall@20:0.662 time_cost(s):12.38
model:model_r@20/epoch_4 recall@20:0.669 time_cost(s):12.21
model:model_r@20/epoch_5 recall@20:0.673 time_cost(s):12.17
model:model_r@20/epoch_6 recall@20:0.675 time_cost(s):12.26
model:model_r@20/epoch_7 recall@20:0.677 time_cost(s):12.25
model:model_r@20/epoch_8 recall@20:0.679 time_cost(s):12.37
model:model_r@20/epoch_9 recall@20:0.680 time_cost(s):12.22
model:model_r@20/epoch_10 recall@20:0.681 time_cost(s):12.2可参考cluster_train.py 配置其他多机环境
运行命令本地模拟多机场景
sh cluster_train.sh注意本地模拟需要关闭代理
{kind=link}