
NNAdapter:飞桨推理 AI 硬件统一适配框架¶
摘要: 近年来,深度学习框架对多硬件的支持加快了 AI 硬件在各领域的落地,为了让更多硬件加入到飞桨硬件生态大家庭,本文介绍了一种新的硬件适配方案————NNAdapter: 飞桨推理 AI 硬件统一适配框架,旨在进一步降低硬件厂商适配门槛、开发和沟通成本。
注意: 为了更好的理解以下内容,可以先从这篇 飞桨推理硬件适配方案 文档对 NNAdapter 有一个快速的认识。
背景¶
随着深度学习技术在各领域的广泛应用,涌现了很多比 CPU, GPU 传统架构更高效的 AI 专用芯片,例如华为昇腾 310 NPU、百度昆仑 XPU、寒武纪 MLU 和谷歌 TPU 等。
但良好的软件生态是 AI 硬件获得成功的关键,它不仅取决于硬件厂商自身软件栈的成熟度,更依赖于是否能够获得深度学习框架的广泛支持,因为后者能够帮助用户简化业务部署过程,降低因硬件差异带来的迁移成本,快速获得更高的性能和能效收益,但如何让厂商以较低成本快速完成硬件适配,又是对深度学习框架提出的一个考验。
目前,飞桨推理框架根据硬件厂商提供的接口层级,将硬件适配分为算子和子图两种方式:前者一般适用于 CPU 、GPU 这类提供低级接口的如通用编程语言/指令集、数学库和算子库的硬件;后者则适用于提供图级别如模型组网、生成接口的硬件,例如:英伟达的 TensorRT、华为昇腾的 CANN 的 GE graph 和 Intel OpenVINO 等,它的优点是屏蔽了硬件细节,模型的优化、生成和执行均由厂商的 SDK 完成,对负责硬件适配的研发人员的能力要求较低,让推理框架更多关注通用优化方法的研究和框架的开发。
近两年来,飞桨轻量推理框架 Paddle Lite 基于子图方式完成了华为昇腾 NPU、华为麒麟 NPU 、芯原 NPU 、联发科 APU 、颖脉 NNA 、寒武纪 MLU 等硬件的适配,但在与硬件厂商合作过程中,逐渐发现了该方案的一些不足之处,主要涉及以下两个方面:
适配门槛高、沟通成本高
要求硬件厂商深入了解推理框架的内部实现、运行机制和编译系统;
硬件厂商获取推理框架的模型、算子定义、量化实现方式等信息所花费的沟通成本较高。
与框架过度耦合、存在重复开发、代码维护成本过高
适配一个新的硬件并跑通一个简单的分类模型,推理框架的文件修改数占总文件修改数的比例高达 50% ;
推理框架算子转硬件算子存在重复开发,并且当推理框架算子发生变更时,需要对所有硬件的适配代码进行升级,厂商维护成本较高;
量化方式、数据布局的转换等通用模块存在重复开发,不仅带来更多的开发工作,而且质量参差不齐的代码将进一步增加厂商维护成本,降低框架的鲁棒性。
简介¶
NNAdapter 是什么?¶
由一系列 C 接口组成的、支撑各种深度学习框架在各种硬件(特别是 AI ASIC 芯片)完成高效推理的通用接口,它是建立深度学习推理框架和硬件的桥梁,实现了推理框架和硬件适配解耦,包含 API 、标准算子定义、 Runtime 和 HAL 标准接口定义四个重要组成部分。
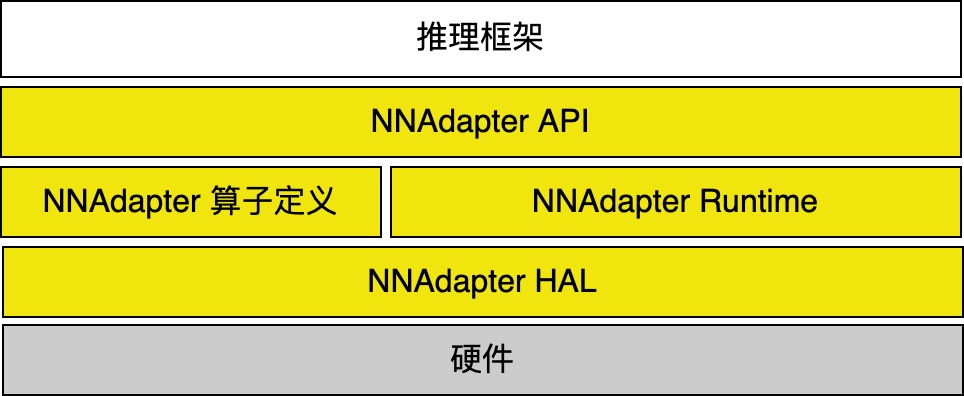
NNAdapter 的目的是什么?¶
降低接入门槛、减少沟通成本:推理框架与硬件适配解耦,不要求硬件厂商深入了解推理框架,只需了解 NNAdapter 的标准算子定义、HAL层标准接口定义、 Runtime 与 HAL 层的调用关系;
减少适配层代码、缩短适配周期:推理框架与硬件适配解耦,使得硬件厂商仅需关注较薄的硬件 HAL 层代码的开发,减少了硬件适配的工作量;
降低维护成本:推理框架与硬件适配解耦,框架的变更和算子升级均被 NNAdapter 与框架的适配层统一吸收,硬件 HAL 层代码不受影响,大大提高了适配层的可维护性。
NNAdapter 做了哪些工作?¶
标准化向上(推理框架)的接口,由设备、多设备统一上下文、模型组网、编译和生成、执行等一系列 C 接口组成;
标准化算子定义,提供稳定的、详细的中间表示层的算子定义(主要参考 ONNX 、 PaddlePaddle 、 PyTorch 和 TensorFlow 的算子),方便硬件厂商快速完成算子映射/转换;
标准化向下(硬件)抽象层( HAL )的接口定义,实现对硬件设备的抽象和封装(屏蔽硬件细节),为 NNAdapter 在不同硬件设备提供统一的访问接口。
重要组成部分¶
API¶
类似于 Google 的 Android NNAPI 、NVIDIA 的 TensorRT 、 Intel 的 OpenVINO ,为了实现与推理框架的完全解耦,方便适配不同的推理框架,需要提供包含设备管理、多设备统一上下文管理、模型组网、编译和生成、执行等在内的、完备的、稳定的 API (参考 NNAPI 命名规则),实现从设备初始化、多设备统一上下文的创建、模型中间表达的建立、设备代码的生成和执行、结果的获取等一系列完整的模型推理链条的打通。具体的,包含以下几类 API (详细说明见『附录』的『 NNAdapter API 』章节):
设备管理
查询设备基本信息,包括设备名称、厂商名称、加速卡类型和 HAL 库版本,以及设备的获取和初始化等。
NNAdapterDevice_acquire, NNAdapterDevice_release, NNAdapterDevice_getName, NNAdapterDevice_getVendor, NNAdapterDevice_getType, NNAdapterDevice_getVersion
多设备统一上下文管理
创建多种设备统一的设备上下文,通过 Key-value 字串的方式为每种设备配置设备运行、模型编译和执行等参数。
NNAdapterContext_create, NNAdapterContext_destroy
模型组网
为了实现与推理框架中模型表达方式的解耦,建立与设备无关的、统一的 NNAdapter 模型
Model的中间表达,需要基于如下 API 将推理框架的模型中的算子、张量对象转化为 NNAdapter 的操作符Operation和操作数Operand。NNAdapterModel_create, NNAdapterModel_destroy, NNAdapterModel_finish, NNAdapterModel_addOperand, NNAdapterModel_setOperandValue, NNAdapterModel_getOperandType, NNAdapterModel_addOperation, NNAdapterModel_identifyInputsAndOutputs
模型编译和生成
基于创建的模型编译实例,通过在 HAL 层库中调用厂商 SDK 实现 NNAdapter 模型的中间表达向目标设备代码的转换。
NNAdapterCompilation_create, NNAdapterCompilation_destroy, NNAdapterCompilation_finish, NNAdapterCompilation_queryInputsAndOutputs
模型执行
创建执行计划实例,设置输入、输出,执行目标设备代码后将结果返回给推理框架。
NNAdapterExecution_create, NNAdapterExecution_destroy, NNAdapterExecution_setInput, NNAdapterExecution_setOutput, NNAdapterExecution_compute
标准算子定义¶
为了建立独立于推理框架的、与设备无关的、Runtime 层与 HAL 层统一的模型中间表达,除了需要定义模型和它包含的操作数和操作符的数据结构,还要对已支持的操作符的类型及参数列表进行标准化。
目前 NNAdapter 参考 ONNX 、PaddlePaddle 、Pytorch 和 TensorFlow 的算子定义完成了 65 个(后续会陆续增加)操作符的定义,形式如下所示(每个标准算子的详细定义见『附录』的『 NNAdapter 标准算子』章节):
typedef enum {
...
/**
* Performs element-wise binary addition(with Numpy-style broadcasting
* https://numpy.org/doc/stable/user/basics.broadcasting.html).
*
* Inputs:
* * 0: input0, a NNADAPTER_FLOAT32,
* NNADAPTER_QUANT_INT8_SYMM_PER_LAYER tensor.
* * 1: input1, a tensor with the same type as input0.
* * 2: fuse_code, a NNADAPTER_INT32 scalar, specifies the activation to the
* result, must be one of NNAdapterFuseCode values.
*
* Outputs:
* * 0: output, the result with the same type as two inputs.
*
* Available since version 1.
*/
NNADAPTER_ADD,
...
} NNAdapterOperationCode;
上述代码节选自 nnadapter.h ,它描述了 逐元素相加操作符 ADD 的基本功能、输入操作数列表、输出操作数列表和所适用的版本。需要注意的是,在模型组网创建一个操作符时,输入、输出操作数列表中的每一个操作数需要严格按照定义的顺序给定。
Runtime¶
Runtime 作为 API 和 HAL 层的桥梁,其作用不仅是将 API 的调用翻译成模型、操作数、操作符的中间表达以及设备 HAL 层接口的调用,还包括设备 HAL 层库的注册、模型缓存的序列化和反序列化。
设备 HAL 层库的注册
用户进程的模型在某个设备上执行第一次推理时, Runtime 的 DeviceManager 发现该设备的 HAL 层库没有被加载,则会根据设备名找到并加载 HAL 库,再依据约定的设备接口描述符号命名规则解析并获得该设备的设备接口描述实例的首地址,进而获得设备的基本信息和各功能函数地址,最后将它注册到
DeviceManager由其统一管理。多种设备间的异构
目前已支持多种设备间的异构,即同一个硬件的不同运算单元,例如联发科芯片的 DSP 和 APU,它将根据每一种设备支持的操作符列表进行子图划分, 按照拓扑顺序在不同的设备中执行模型片段。
模型缓存的序列化和反序列化
Runtime 通过设备 HAL 层库调用厂商 SDK 将模型的中间表示转为设备代码的过程通常耗时较长,一般与模型规模成正比,与芯片 CPU 的处理能力成反比,例如
MobileNetV1全量化模型在的 RK1808 芯片上的编译耗时大约在15秒左右,而ResNet50全量化模型的耗时更是达到分钟级别。因此,模型的在线编译和生成大大增加了用户进程启动后的第一次推理耗时,这在一些应用中是不可接受的,为了避免这个问题,Runtime 支持将已编译的设备代码缓存到文件系统中,而在下一次模型编译时直接加载该缓存文件,这就涉及到缓存文件的序列化和反序列化过程。
HAL 标准接口定义¶
为了屏蔽硬件细节,向 Runtime 提供统一的设备访问接口,我们在 Runtime 和 厂商 SDK 之间建立了 HAL 硬件抽象层,它是由 C 结构体实现的统一设备接口描述、模型、操作数和操作符的中间表达等数据结构组成,代码如下所示(访问 types.h 和 device.h 获得最新代码):
typedef struct Operand {
NNAdapterOperandType type;
void* buffer;
uint32_t length;
} Operand;
typedef struct Argument {
int index;
void* memory;
void* (*access)(void* memory, NNAdapterOperandType* type);
} Argument;
typedef struct Operation {
NNAdapterOperationType type;
std::vector<Operand*> input_operands;
std::vector<Operand*> output_operands;
} Operation;
typedef struct Cache {
const char* token;
const char* dir;
std::vector<NNAdapterOperandType> input_types;
std::vector<NNAdapterOperandType> output_types;
std::vector<uint8_t> buffer;
} Cache;
typedef struct Model {
std::list<Operand> operands;
std::list<Operation> operations;
std::vector<Operand*> input_operands;
std::vector<Operand*> output_operands;
} Model;
typedef struct Device {
// Properties
const char* name;
const char* vendor;
NNAdapterDeviceType type;
int32_t version;
// Interfaces
int (*open_device)(void** device);
void (*close_device)(void* device);
int (*create_context)(void* device, const char* properties, int (*callback)(int event_id, void* user_data), void** context);
void (*destroy_context)(void* context);
int (*create_program)(void* context, Model* model, Cache* cache, void** program);
void (*destroy_program)(void* program);
int (*execute_program)(void* program, uint32_t input_count, Argument* input_arguments, uint32_t output_count, Argument* output_arguments);
} Device;
模型、操作数和操作符的中间表达
为了便于 Runtime 和 HAL 层之间的沟通,还需要建立模型的统一表达,目前采用了较为简单的 C 结构体的表示方法定义了模型
Model、操作数Operand和操作符Operation,其中:1)一个模型由若干个操作数、操作符组成模型的输入、输出操作数会被额外按照顺序依次存储,但操作符不一定是按照拓扑顺序存储的,您可以借助 SortOperationsInTopologicalOrder 实现操作符的拓扑排序。例如在华为昇腾 HAL 层的 对多输出的算子插入 dummy 的 ADD 算子的优化器 的实现中,需要首先调用 SortOperationsInTopologicalOrder 才能获得经过拓扑排序后的操作符列表。而为了方便调试,您还可以通过 Visualize 将模型数据结构输出为 DOT 格式字符串,将其复制到 webgraphviz 即可绘制模型拓扑结构。例如在华为昇腾 HAL 层的 打印优化前后的模型拓扑结构 代码;
2)一个操作符由操作符类型、输入操作数列表和输出操作数列表组成,需要特别注意的是,操作数列表中的元素顺序需要严格按照操作符的定义的顺序依次存放。
设备接口描述
为 Runtime 在不同硬件提供统一的访问接口,需要对硬件的功能进行抽象和封装,涉及设备基本信息和标准功能接口,以下是昇腾 310 HAL 层设备接口描述结构体的实现(访问 driver.cc 获得最新代码):
... export "C" nnadapter::hal::Device __nnadapter_device__huawei_ascend_npu = { .name = "huawei_ascend_npu", .vendor = "Huawei", .type = NNADAPTER_ACCELERATOR, .version = 1, .open_device = nnadapter::huawei_ascend_npu::OpenDevice, .close_device = nnadapter::huawei_ascend_npu::CloseDevice, .create_context = nnadapter::huawei_ascend_npu::CreateContext, .destroy_context = nnadapter::huawei_ascend_npu::DestroyContext, .create_program = nnadapter::huawei_ascend_npu::CreateProgram, .destroy_program = nnadapter::huawei_ascend_npu::DestroyProgram, .execute_program = nnadapter::huawei_ascend_npu::ExecuteProgram, };
在注册一个新的设备时,要求对
Device结构的所有成员进行赋值,涉及设备基本信息和从open_device到execute_program的设备标准功能接口的设置,特别是后者,它们被 Runtime 调用的时机如下图所示(详细过程可参考下一章节的『应用程序、 Paddle Lite 、NNAdapter 和硬件 SDK 之间的详细调用过程』)。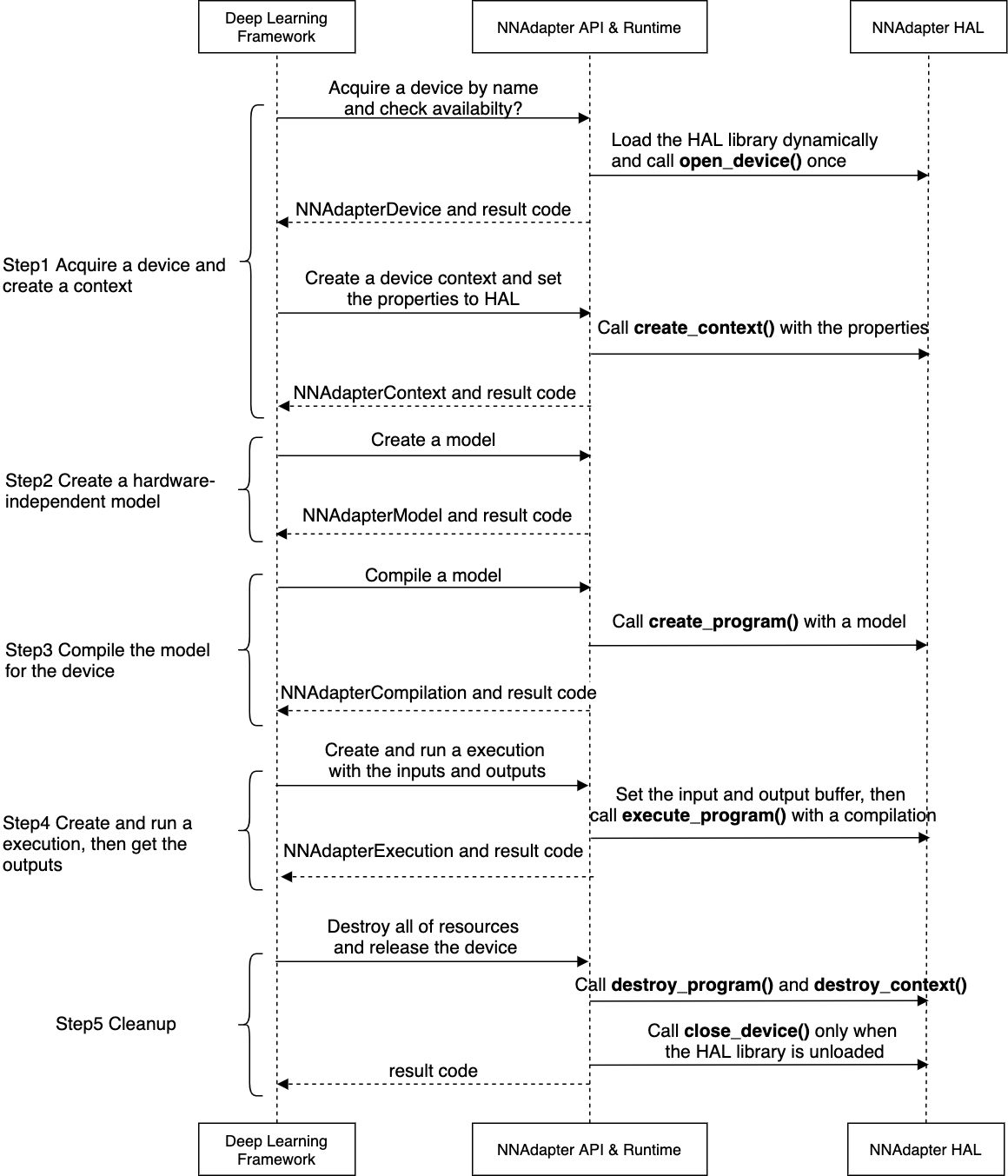
Paddle Lite 中的具体实现¶
方案实现¶
如下图所示,目前 NNAdapter 作为一个后端以子图方式接入到 Paddle Lite 中,如下步骤简单描述了 Paddle Lite 从模型的加载和解析、图优化、子图算子的执行,再到 NNAdapter HAL 层库调用硬件 SDK 执行的整个过程:
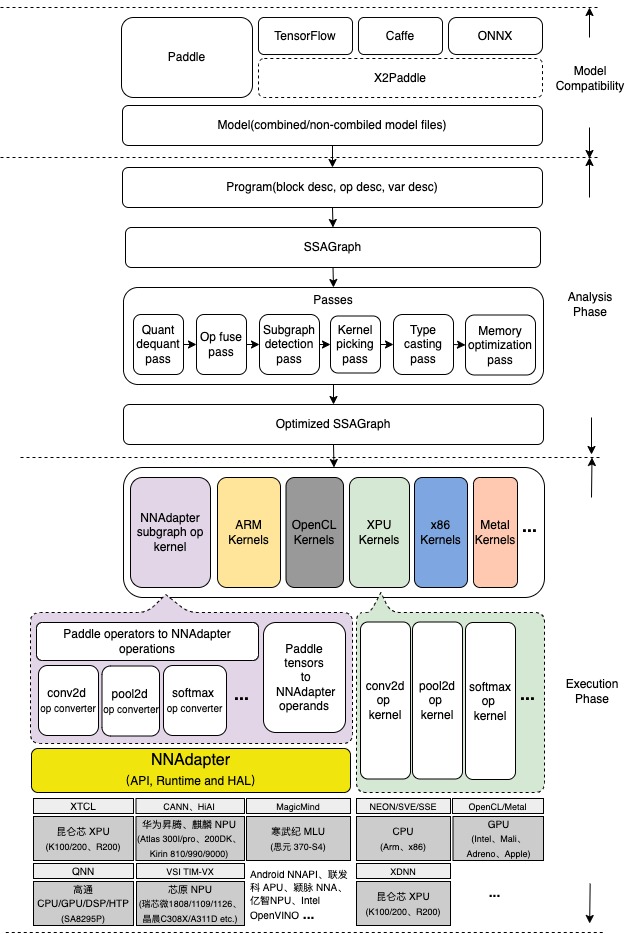
模型文件的加载和解析
Paddle 模型由程序
Program、块Block、算子Operator和变量Variable组成,程序由若干块组成,块由若干算子和变量组成,变量包括中间变量和持久化变量,如卷积的权值,经序列化保存后形成 Combined 和 Non-combined 两种形式的模型文件, Non-combined 形式的模型由一个网络拓扑结构文件 model 和一系列以变量名命名的参数文件组成, Combined 形式的模型由一个网络拓扑结构文件 model 和一个合并后的参数文件 params 组成,其中网络拓扑结构文件是基于 Protocol Buffers 格式以 Paddle proto 文件描述的规则序列化后的文件。计算图的转化
将每个块按照如下规则生成对应的计算图的过程:每个算子或变量都对应计算图的一个节点,节点间的有向边由算子的输入、输出决定(依赖关系确定边的方向),算子节点与变量节点相邻。
图分析和优化
将一系列 pass (优化器,用于描述一个计算图变换得到另一个计算图的处理过程)按照一定的顺序依次应用到每个块对应的计算图的过程,包括量化信息处理、算子融合、 Kernel 选择、类型转化、上下文创建、内存复用优化和子图检测等,实现不同设备的适配、高效的计算和更少的内存占用。其中,子图检测作为 NNAdapter 的关键模块,承担着硬件子图划分的工作,具体地,基于设备已支持的算子列表,将连续支持的算子融合形成一个子图,并在子图算子执行时将其转为 NNAdapter 模型下发给设备 HAL 层库实现子图向设备代码的转换。
运行时程序的生成和执行
按照拓扑顺序遍历优化后的计算图,生成算子和 Kernel 列表的过程。
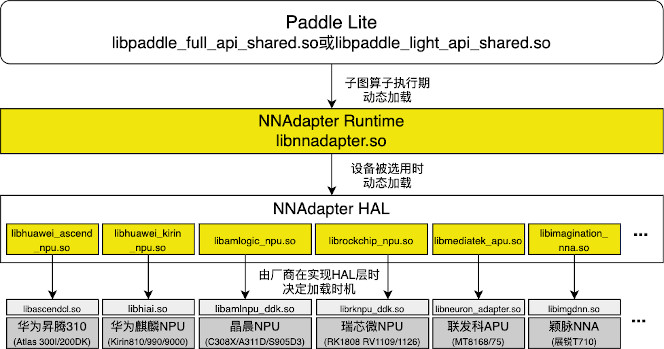
用户视角下各编译产物之间的调用关系¶
下图描述了用户视角下的 Paddle Lite 推理框架、 NNAdapter Runtime 和 NNAdapter 硬件 HAL 层库之间的调用关系。
用户 APP 首先调用 Paddle Lite 动态库 libpaddle_full_api_shared.so 和 libpaddle_light_api_shared.so 并设置 NNAdapter 设备名称,在其首次推理时会加载 NNAdapter Runtime 动态库 libnnadapter.so ,然后根据用户设置的设备名称加载 NNAdapter 硬件 HAL 层动态库,例如华为昇腾 310 NPU 的 HAL 层库 libhuawei_ascend_npu.so ,最后调用硬件厂商的软件栈完成推理,例如华为昇腾 310 NPU 的 CANN 框架的 libascendcl.so 。
Paddle Lite 为 NNAdapter 新增的接口¶
设备查询和设置
check_nnadapter_device_name
bool check_nnadapter_device_name(const std::string& device_name)
通过设备名称查询设备是否可用,设备名称包括
huawei_ascend_npu,huawei_kirin_npu,amlogic_npu,rockchip_npu,mediatek_apu,imagination_nna等,已支持设备的最新列表可在 NNAdapter HAL 中查询。参数:
device_name:设备 HAL 层库的名称,例如: huawei_ascend_npu 。
返回值:设备可用则返回 TRUE 。
set_nnadapter_device_names
void set_nnadapter_device_names(const std::vector<std::string>& device_names)
设置模型在哪些设备中运行。
参数:
device_names:设备名称列表。
返回值:无。
设备上下文的参数设置
set_nnadapter_context_properties
void set_nnadapter_context_properties(const std::string& context_properties)
将设备参数传递给设备 HAL 层库。
参数:
context_properties:以 Key-value 字串的形式表示设备参数,例如:如果希望使用 Atlas 300 I 3000/3010 加速卡(由四颗昇腾 310 芯片组成)的第 0 个昇腾 310 芯片,可以设置 “HUAWEI_ASCEND_NPU_SELECTED_DEVICE_IDS=0;” 。
返回值:无。
模型缓存
set_nnadapter_model_cache_dir
void set_nnadapter_model_cache_dir(const std::string& model_cache_dir)
启用模型编译缓存功能,设置编译后的设备程序的缓存文件(以 .nnc 为扩展名)的存储目录,它能够跳过每次进程启动且模型首次推理时的编译步骤,减少首次推理耗时。
参数:
model_cache_dir:模型缓存目录。
返回值:无。
set_nnadapter_model_cache_buffers
void set_nnadapter_model_cache_buffers(const std::string& model_cache_token, const std::vector<char>& model_cache_buffer)
设置模型缓存的标识和数据,子图在编译生成设备程序时,如果成功匹配到
model_cache_token,则跳过模型编译步骤,直接使用缓存数据恢复设备程序(需要设备 HAL 层库的支持),该接口通常用于从内存中设置解密后的模型缓存数据。参数:
model_cache_token:根据子图输入、输出、设备信息按照一定规则生成的唯一标识子图的 32 个字符,它实现方式可以参考 model_cache_token 的计算。
model_cache_buffer:
model_cache_token对应子图和设备的模型缓存数据。
返回值:无。
自定义子图分割
set_nnadapter_subgraph_partition_config_path
void set_nnadapter_subgraph_partition_config_path(const std::string& subgraph_partition_config_path)
设置自定义子图分割配置文件路径,用于将某些算子强制异构到 CPU ,防止因切分成过多子图而导致的性能下降,内存增加。该配置文件的规则如下:
1)每行记录用于唯一标识某一个或某一类需要被强制异构到 CPU 的算子。
2)每行记录由『算子类型:输入张量名列表:输出张量名列表』组成,即以冒号分隔算子类型、输入和输出张量名列表,以逗号分隔输入、输出张量名列表中的每个张量名。
3)可省略输入、输出张量名列表中的部分张量名,如果不设置任何输入、输出张量列表,则代表计算图中该类型的所有算子节点均被强制异构到CPU。
用法举例:
op_type0:var_name0,var_name1:var_name2 表示将类型为 op_type0 、输入张量为 var_name0 和 var_name1 、输出张量为 var_name2 的算子强制异构到 CPU 上 op_type1::var_name3 表示将类型为 op_type1 、任意输入张量、输出张量为 var_name3 的算子强制异构到 CPU 上 op_type2:var_name4 表示将类型为 op_type2 、输入张量为 var_name4 、任意输出张量的算子强制异构到 CPU 上 op_type3 表示任意类型为 op_type3 的算子均被强制异构到CPU上
为了方便唯一标识模型中的某一个算子,可以在使用 cxxconfig 加载Paddle模型进行 nb 模型转换或直接推理时,设置 GLOG_v=5 打印完整调试信息,然后以
subgraph operators为关键字搜索,例如: ssd_mobilenet_v1_relu_voc_fp32_300 模型运行在华为麒麟 NPU 时,将得到如下调试信息:subgraph clusters: 1 digraph G { node_1150[label="batch_norm_0.tmp_3"] node_1154[label="batch_norm_1.tmp_3"] node_1190[label="batch_norm_10.tmp_3"] node_1194[label="batch_norm_11.tmp_3"] ... node_1426->node_1427 node_1427->node_1428 node_1428->node_1429 } // end G subgraph operators: feed:feed:image conv2d:image,conv1_weights,conv1_bn_offset:batch_norm_0.tmp_3 depthwise_conv2d:batch_norm_0.tmp_3,conv2_1_dw_weights,conv2_1_dw_bn_offset:batch_norm_1.tmp_3 conv2d:batch_norm_1.tmp_3,conv2_1_sep_weights,conv2_1_sep_bn_offset:batch_norm_2.tmp_3 ... box_coder:concat_0.tmp_0,concat_1.tmp_0,reshape2_0.tmp_0:box_coder_0.tmp_0 multiclass_nms:box_coder_0.tmp_0,transpose_12.tmp_0:save_infer_model/scale_0.tmp_0 fetch:save_infer_model/scale_0.tmp_0:fetch
其中:
1)
subgraph operators一行的后面是模型经过 Paddle Lite 各种优化 Pass 后的全部算子集合,可以非常方便的作为自定义子图分割配置文件的内容,这也将成为我们在硬件适配时快速调通目标模型的好帮手(即先将所有算子强制异构到 CPU 上,然后一行一行的删掉,让它们跑在目标设备上,这种方法可以快速定位问题算子,完成整个模型的调通)。2)
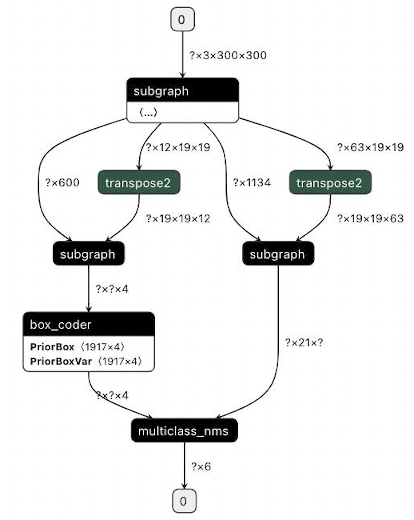
subgraph clusters一行的后面是经过子图检测后的子图个数,它下面从digraph G {开始到} // end G结束的部分则是用于可视化子图检测后的模型拓扑结构的 DOT 格式字符串,可将其复制到 webgraphviz 进行可视化,其中不同颜色的算子代表所属不同的子图。同样的,以 ssd_mobilenet_v1_relu_voc_fp32_300 为例,下面两张图展示了使用自定义子图分割配置前后的子图融合结果的对比:
1)未使用自定义子图分割配置:
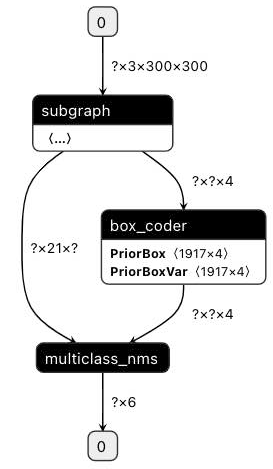
2)使用如下自定义子图配置:
transpose2:conv2d_22.tmp_1:transpose_0.tmp_0,transpose_0.tmp_1 transpose2:conv2d_23.tmp_1:transpose_1.tmp_0,transpose_1.tmp_1
注意:该接口仅用于 cxxconfig 加载 Paddle 模型生成 nb 模型或直接推理时使用。
set_nnadapter_subgraph_partition_config_buffer
void set_nnadapter_subgraph_partition_config_buffer(const std::string& subgraph_partition_config_buffer)
设置自定义子图分割配置内容,该接口通常用于加、解密场景。
参数:
subgraph_partition_config_buffer:自定义子图分割配置的内容,与
set_nnadapter_subgraph_partition_config_path中阐述的一致。
返回值:无。
应用程序、 Paddle Lite 、NNAdapter 和硬件 SDK 之间的详细调用过程¶
提示:如果图片太小看不清,可以在图片上方点击右键并选择『在新标签页中打开该图片』。
查询设备是否可用,将设置的设备名称列表、设备上下文参数、模型缓存数据存储在 Paddle Lite 的 Scope 中( Scope 与 Predictor 绑定。通常存储模型的张量数据)。
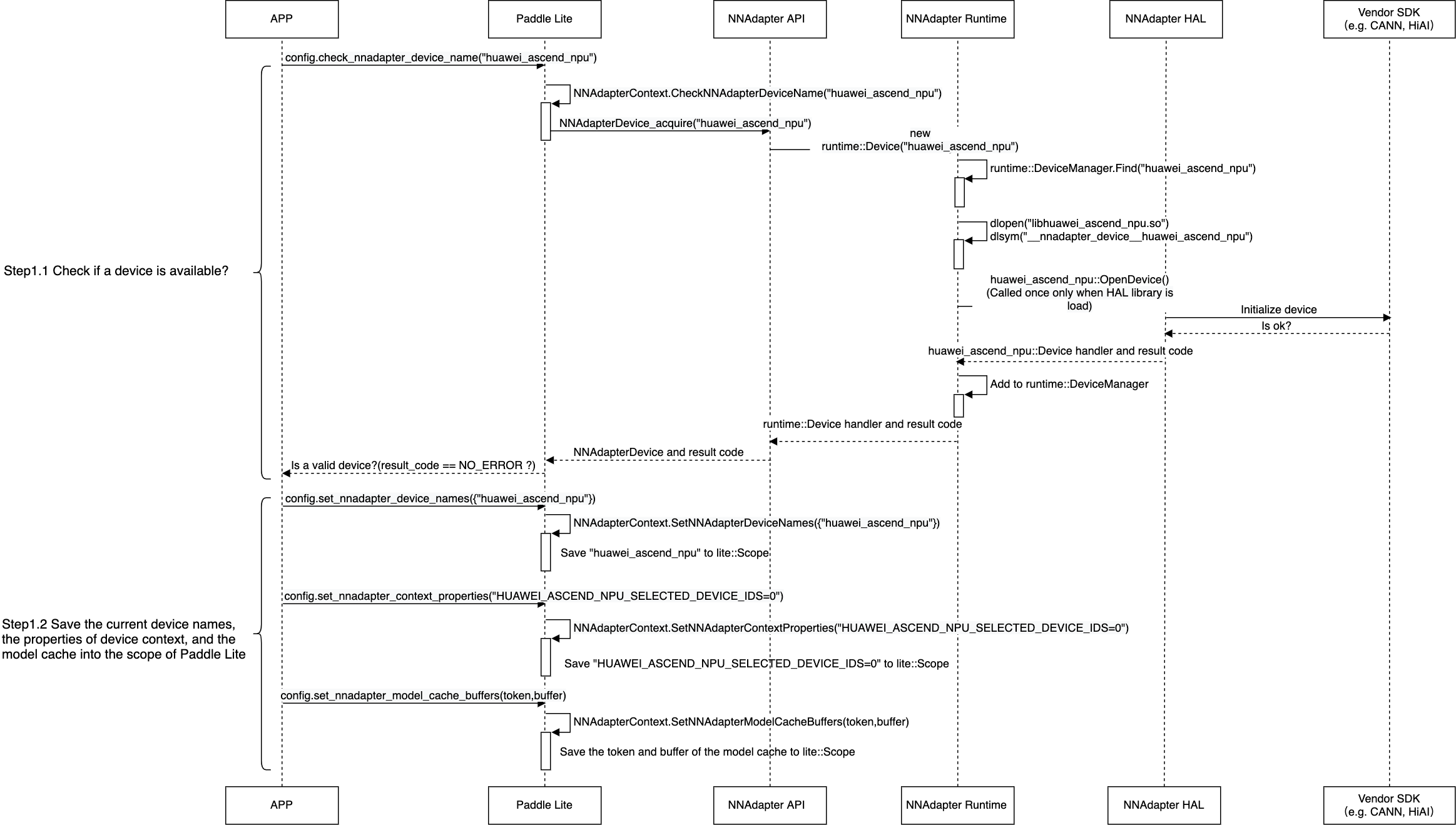
从 Scope 中获取设备名称列表、设备上下文参数,创建设备实例、设备统一上下文实例和与设备无关的模型实例。
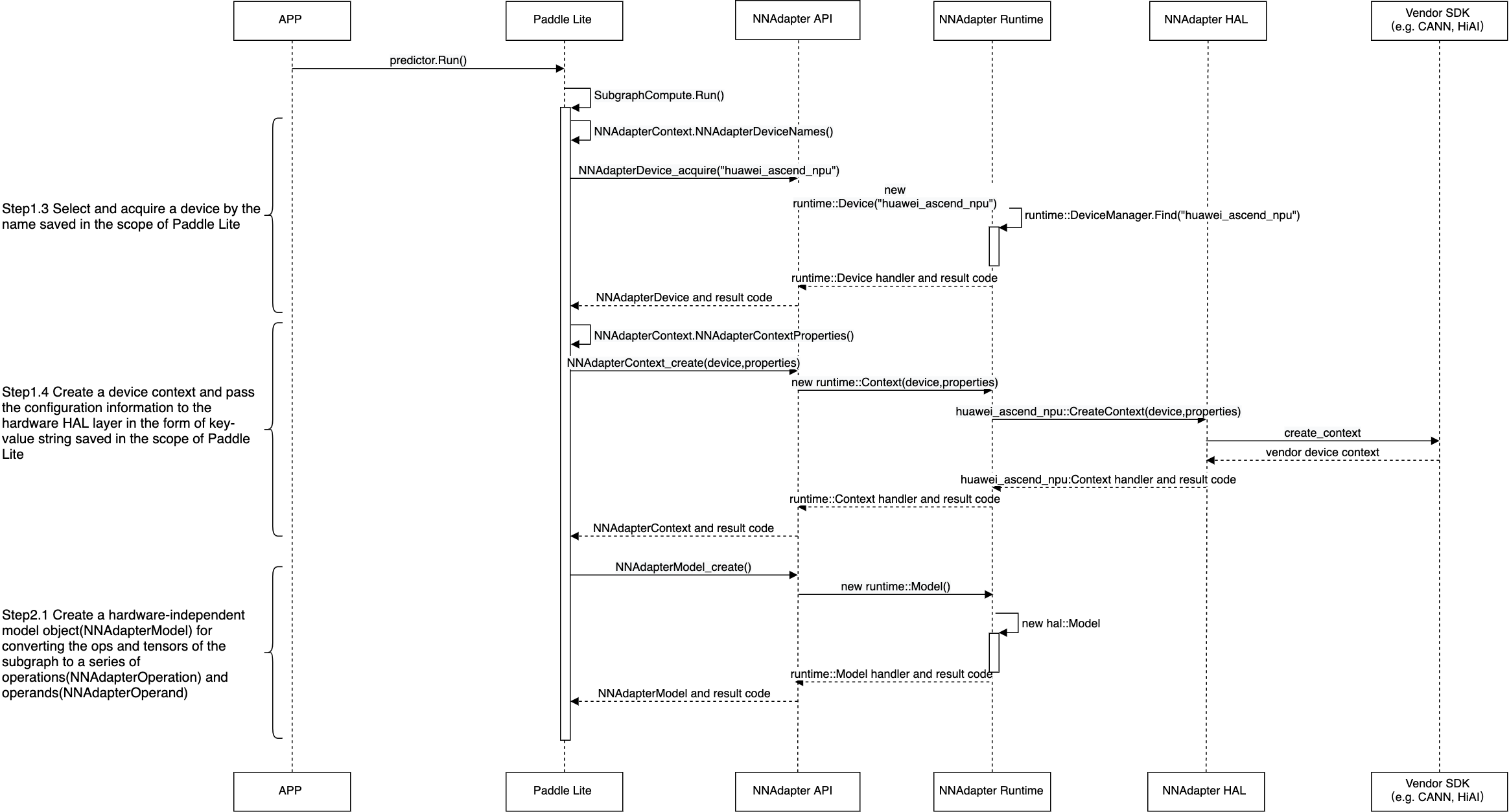
将 Paddle Lite 子图中的张量和算子全部转换为 NNAdapter 的操作数和操作符后加入到模型实例中。
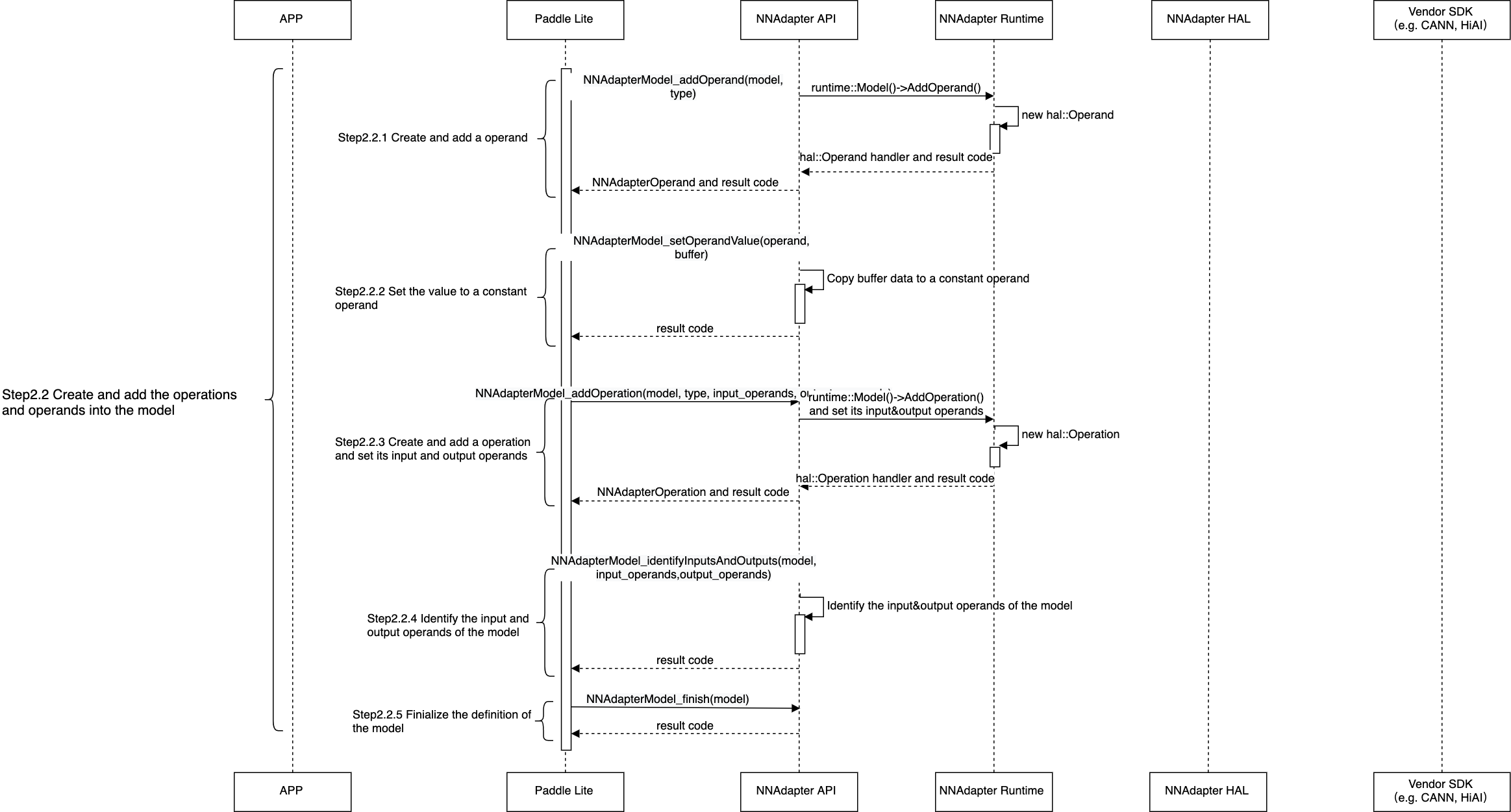
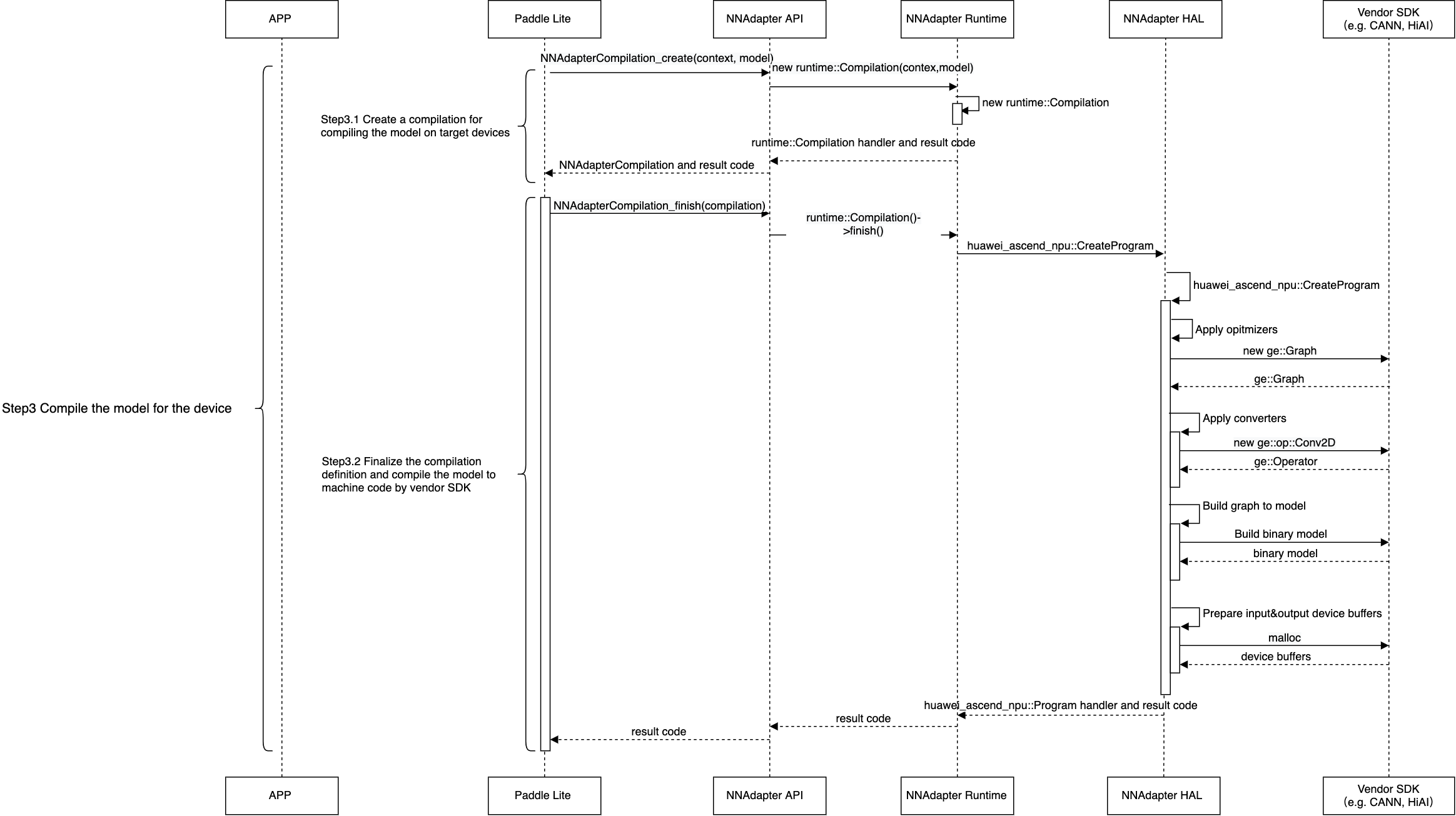
创建编译实例,从模型缓存中直接恢复设备程序,或通过目标设备的 HAL 层库调用硬件 SDK ,将模型实例编译生成设备程序。
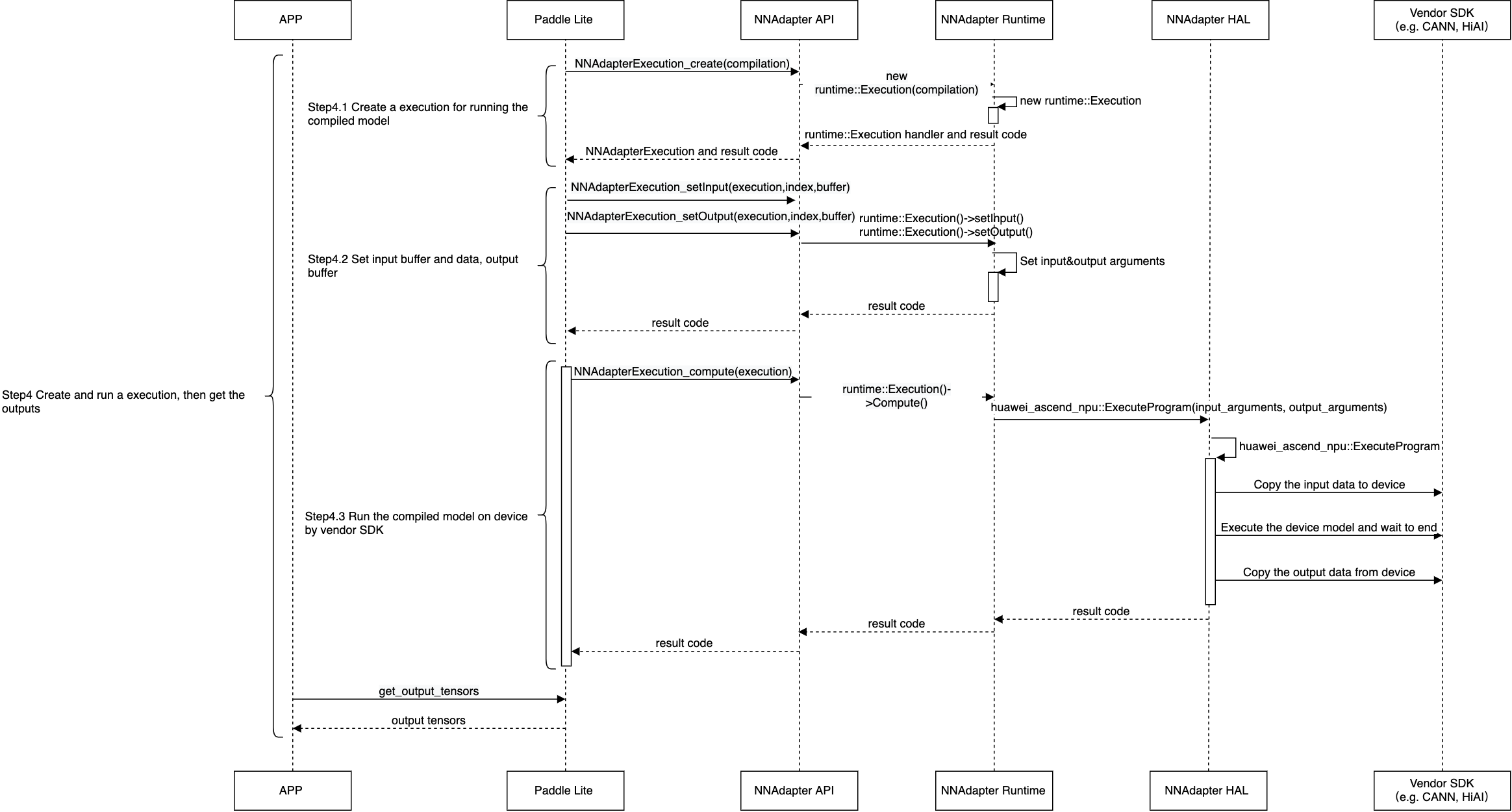
创建执行计划实例,设置输入、输出内存和访问函数,在设备程序执行完毕后,将结果返回给应用程序。
基于 NNAdapter 的硬件适配实践¶
一般流程¶
从 driver 目录中的复制一份 HAL 作为参考(AI 加速卡类硬件可以参考华为昇腾 NPU
huawei_ascend_npu, SoC 类硬件可以参考华为麒麟 NPUhuawei_kirin_npu)。基于参考硬件的 HAL 代码开发目标硬件的 HAL ,主要涉及 cmake 脚本的修改、 设备接口的实现(设备初始化、模型转换、编译和执行)。
模型转换:将 NNAdapter HAL 中的
Model转成厂商 SDK 中的模型的表示,其工作主要在于实现Operation到厂商 SDK 中的算子的表示的转换器,例如:华为昇腾 NPU HAL 中的NNADAPTER_ADD操作符到 CANN SDK 的ge::op::Add的转换,代码涉及以下三个部分:NNADAPTER_ADD 到 ge::op::Add 的转换器的实现 和 NNADAPTER_ADD 到 ge::op::Add 的转换器的注册 :在 HAL 层的
Model到厂商 SDK 模型转换步骤的Operation转换过程中,用于保证正确调用指定的转换器生成并添加厂商 SDK 的算子表示,进而基于厂商 SDK 完成模型转换。Paddle 算子 elementwise_add 到 NNADAPTER_ADD 转换器的注册 :具体是在转换器注册的设备名称字串中添加目标硬件的名称,其主要用于在 Paddle 模型的子图分割阶段中告诉子图分割算法哪些 Paddle 算子可以放在哪些硬件上执行,即哪些算子可以融合成一个 NNAdapter 子图,且在 NNAdapter 算子 Kernel 执行时,能够该子图转换为 NNAdapter 模型,进而传递到硬件的 HAL 层做进一步的转换。
基于 PaddleLite-generic-demo 跑通第一个分类模型:当目标硬件的 HAL 层代码开发完成后(前期仅需开发一个
NNADAPTER_SOFTMAX的转换器即可),需要验证 HAL 层到厂商 SDK 的链路是否打通,为方便厂商和用户测试,我们提供了包含图像分类和目标检测模型的 Demo 的压缩包,它支持 NNAdapter 目前已支持的所有硬件,覆盖 x86 Linux 、ARM Linux 和 Android 系统,可以本地执行或基于 ssh 或 adb 方式推送到远端设备上执行,各硬件的文档均涉及 Demo 的使用方法,具体可以访问:华为昇腾 NPU 、华为麒麟 NPU 、联发科 APU 和颖脉 NNA 等。模型、算子转换器调试方法:调试 Demo 中的模型有时候并不是一帆风顺,可能在模型转换过程中出现
core dump,也可能在模型跑通后发现结果无法与 CPU 结果对齐,这些问题尝尝源于部分 NNAdapter 操作符到厂商 SDK 算子的转换器的 BUG 导致的,有效的解决办法是:先将模型中所有 Paddle 算子强制跑在 CPU 上,然后根据模型拓扑顺序,逐步将 Paddle 算子放在目标硬件上执行,通过二分法、排除法最终定位到有问题的算子转换器上,具体可以参考上一章节中『自定义子图分割』。
添加算子、模型的单元测试
添加算子单元测试:为了持续验证每一个算子转化器能否正常工作,覆盖 Paddle 算子的所有功能,需要增加目标硬件的算子单元测试,具体步骤如下:
单元测试新增目标硬件的支持:增加目标硬件宏定义、单测设置目标硬件名称。
在目标算子单测增加宏定义和精度验证阈值,例如:在 softmax 单测增加华为昇腾 NPU 的支持,仅需添加 2 行代码。
添加模型单元测试:为了验证新合入的代码对已支持的模型是否有影响(正常跑通且精度对齐),需要在指定模型的单元测试中增加对目标硬件的支持,例如:在 MobileNetV1 模型增加华为昇腾 NPU 的支持,仅需添加 3~4 行代码(注意:全量化模型的单测为
test_mobilenet_v1_int8_per_channel_nnadapter和test_mobilenet_v1_int8_per_layer_nnadapter)。为了实现持续交付,需要向飞桨团队提供至少3套测试硬件,用于目标硬件的测试环境并加入到 Paddle Lite CI 系统。
添加用户说明文档,示例:华为昇腾 NPU 的文档源码。
提交代码和文档:当代码和文档都已经准备好了后,就可以向 Paddle Lite 的 github 代码仓库 发起 Pull request 了,但只有飞桨研发同学完成 code reivew 后方可合入主线,具体方法如下:
参考 Docker 统一编译环境搭建 准备 Docker 开发环境(注意:必须使用 Paddle Lite Docker 容器环境,因为代码提交时将使用 git pre-commit hooks 进行代码风格检查,而它使用的 clang-format 被严格限制在 3.8 版本)
注册 github 账户,将 Paddle Lite 代码仓库 Fork 到自己的账户.
将自己 github 账户的 Paddle Lite 仓库克隆到本地。
# git clone https://github.com/UserName/Paddle-Lite # cd Paddle-Lite
创建本地分支:从 develop 分支创建一个新的本地分支,命名规则为 UserName/FeatureName ,例如 hongming/print_ssa_graph
$ git checkout -b UserName/FeatureName
启用 pre-commit 钩子: pre-commit 作为 git 预提交钩子,帮助我们在 git commit 时进行自动代码( C++,Python )格式化和其它检查(如每个文件只有一个 EOL ,Git 中不要添加大文件等),可通过以下命令进行安装(注意:pre-commit 测试是 Travis-CI 中单元测试的一部分,不满足钩子的 PR 不能被提交到 Paddle Lite ):
$ pip install pre-commit $ pre-commit install
修改代码:提交代码前通过 git status 和 git diff 命令查看代码改动是否符合预期,避免提交不必要或错误的修改。
$ git status On branch hongming/print_ssa_graph Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) (commit or discard the untracked or modified content in submodules) modified: lite/core/optimizer/optimizer.h $ git diff diff --git a/lite/core/optimizer/optimizer.h b/lite/core/optimizer/optimizer.h index 00e9e07..1b273af 100644 --- a/lite/core/optimizer/optimizer.h +++ b/lite/core/optimizer/optimizer.h @@ -55,7 +55,8 @@ class Optimizer { if (passes.empty()) { std::vector<std::string> passes_local{ - {"lite_quant_dequant_fuse_pass", // + {"graph_visualze", + "lite_quant_dequant_fuse_pass", // "lite_conv_elementwise_fuse_pass", // conv-elemwise-bn提交代码:git add 命令添加需要修改的文件,放弃提交可用 git reset 命令,放弃修改可使用 git checkout – [file_name] 命令,每次代码提交时都需要填写说明,以便让他人知道这次提交做了哪些修改,可通过 git commit 命令完成,修改提交说明可通过 git commit –amend 命令;为了触发 CI ,提交说明最后结束前必须回车换行,然后添加 test=develop ,如果本次提交的 Pull request 仅修改 doc 目录下的文档,则额外加上 test=document_fix 加快 CI 流水线。
$ git add lite/core/optimizer/optimizer.h $ git status On branch hongming/print_ssa_graph Changes to be committed: (use "git reset HEAD <file>..." to unstage) modified: lite/core/optimizer/optimizer.h $ git commit -m "Add graph_visualze pass to output ssa graph > test=develop" CRLF end-lines remover...................................................Passed Check for added large files..............................................Passed Check for merge conflicts................................................Passed Check for broken symlinks................................................Passed Detect Private Key.......................................................Passed Fix End of Files.........................................................Passed clang-format.............................................................Passed cpplint..................................................................Passed copyright_checker........................................................Passed [hongming/print_ssa_graph 75ecdce] Add graph_visualze pass to output ssa graph test=develop 1 file changed, 2 insertions(+), 1 deletion(-)同步本地仓库代码:在准备发起 Pull Request 前,需要将原仓库 https://github.com/PaddlePaddle/Paddle-Lite 的 develop 分支的最新代码同步到本地仓库的新建分支。首先通过 git remote -v 命令查看当前远程仓库的名字,然后通过 git remote add 命令添加原 Paddle Lite 仓库地址,最后使用 git fetch 和 git pull 命令将本地分支更新到最新代码。
$ git remote -v origin https://github.com/UserName/Paddle-Lite.git (fetch) origin https://github.com/UserName/Paddle-Lite.git (push) $ git remote add upstream https://github.com/PaddlePaddle/Paddle-Lite $ git remote origin upstream $ git fetch upstream remote: Enumerating objects: 105, done. remote: Counting objects: 100% (105/105), done. remote: Compressing objects: 100% (6/6), done. remote: Total 142 (delta 99), reused 100 (delta 99), pack-reused 37 Receiving objects: 100% (142/142), 52.47 KiB | 2.00 KiB/s, done. Resolving deltas: 100% (103/103), completed with 45 local objects. From https://github.com/PaddlePaddle/Paddle-Lite a1527e8..d6cdb1e develop -> upstream/develop 2136df9..17a58b6 gh-pages -> upstream/gh-pages 1091ab8..55be873 image-sr-v2 -> upstream/image-sr-v2 * [new branch] release/v2.2.0 -> upstream/release/v2.2.0 * [new tag] v2.2.0 -> v2.2.0 $ git branch develop * hongming/print_ssa_graph $ git pull upstream develop From https://github.com/PaddlePaddle/Paddle-Lite * branch develop -> FETCH_HEAD Removing lite/kernels/npu/bridges/transpose_op_test.cc Removing lite/kernels/npu/bridges/batch_norm_op_test.cc Merge made by the 'recursive' strategy. lite/kernels/npu/bridges/batch_norm_op_test.cc | 168 ------------------------------------------------------------------------------------------------ lite/kernels/npu/bridges/transpose_op.cc | 2 +- lite/kernels/npu/bridges/transpose_op_test.cc | 153 --------------------------------------------------------------------------------------- lite/tests/kernels/CMakeLists.txt | 4 +-- lite/tests/kernels/batch_norm_compute_test.cc | 2 ++ lite/tests/kernels/transpose_compute_test.cc | 44 ++++++++++++------------- mobile/test/CMakeLists.txt | 6 ++++ mobile/test/net/test_mobilenet_male2fe.cpp | 66 ++++++++++++++++++++++++++++++++++++++ 8 files changed, 99 insertions(+), 346 deletions(-) delete mode 100644 lite/kernels/npu/bridges/batch_norm_op_test.cc delete mode 100644 lite/kernels/npu/bridges/transpose_op_test.cc create mode 100644 mobile/test/net/test_mobilenet_male2fe.cpp
Push 到远程仓库:将本地的修改推送到自己账户下的 Paddle Lite 仓库,即 https://github.com/UserName/Paddle-Lite 。
$ git branch develop * hongming/print_ssa_graph $ git push origin hongming/print_ssa_graph Counting objects: 8, done. Delta compression using up to 2 threads. Compressing objects: 100% (8/8), done. Writing objects: 100% (8/8), 868 bytes | 0 bytes/s, done. Total 8 (delta 6), reused 0 (delta 0) remote: Resolving deltas: 100% (6/6), completed with 6 local objects. remote: remote: Create a pull request for 'hongming/print_ssa_graph' on GitHub by visiting: remote: https://github.com/UserName/Paddle-Lite/pull/new/hongming/print_ssa_graph remote: To https://github.com/UserName/Paddle-Lite.git * [new branch] hongming/print_ssa_graph -> hongming/print_ssa_graph
发起 Pull Request :登录 github ,在自己账户下找到并进入 UserName/Paddle-Lite 仓库,这时会自动提示创建 Pull Request ,点击 Create Pull Request 按钮,一般来说会自动选择比较更改的仓库和分支,如果需要手动设置,可将 base repository 选择为 PaddlePaddle/Paddle-Lite , base 分支为 develop ,然后将 head repository 选择为 UserName/Paddle-Lite ,compare分支为 hongming/print_ssa_graph 。 PR(Pull Request) 的标题必须用英文概括本次提交的修改内容,例如修复了什么问题,增加了什么功能。同时,为了便于其他人快速得知该PR影响了哪些模块,应该在标题前添加中括号 + 模块名称进行标识,例如 “[HuaweiKirinNPU][KunlunxinXPU] Temporarily toggle printing ssa graph, test=develop” 。 PR 的描述必须详细描述本次修改的原因/背景、解决方法、对其它模块会产生何种影响(例如生成库的大小增量是多少),性能优化的 PR 需要有性能对比数据等。
签署 CLA 协议:在首次向 Paddle Lite 提交 Pull Request 时,您需要您签署一次 CLA(Contributor License Agreement) 协议,以保证您的代码可以被合入。
等待 CI 测试完成:您在 Pull Request 中每提交一次新的 commit 后,都会触发一系列 CI 流水线(根据场景/硬件的不同,一般会有多个流水线),它将会在几个小时内完成,只需保证带有 Required 的流水线通过即可。例如下图所示,每项流水线测试通过后,都会在前面打勾,否则打叉,可点击 Details 查看日志定位错误原因:

PR Review :每个 PR 需要至少一个评审人 apporve 后才能进行代码合入,而且在请评审人 review 代码前,必须保证 CI 测试完成并通过全部测试项,否则评审人一般不做评审。根据 PR 修改的模块不同,代码评审人选择也不一样。例如:涉及到 Core 和 API 模块,需要 @Superjomn 进行 Review ,涉及到 Subgraph 相关的修改,需要 @hong19860320 或 @zhupengyang 进行 Review 。评审人的每个意见都必须回复,同意评审意见且按其修改完的,给个简单的 Done 即可,对评审意见不同意的,请给出您自己的反驳理由。
PR 合入:一般 PR 会有多次 commit ,原则上是尽量少的 commit ,且每个 commit 的内容不能太随意。在合入代码时,需要对多个 commit 进行 squash commits after push ,该 PR 在评审人 approve 且 CI 完全通过后,会出现 “Squash and Merge” 按钮,如上图所示,届时可以联系 Paddle 同学完成 PR 的合入。
附录¶
NNAdapter API¶
NNAdapter_getVersion
int NNAdapter_getVersion(uint32_t* version)
获取 NNAdapter 版本值。
参数:
version:存储返回 NNAdapter 的版本值。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterDevice_acquire
NNAdapterDevice_acquire(const char* name, NNAdapterDevice** device)
通过名称获取设备实例。
参数:
name:通过该名称加载并注册设备 HAL 库后(仅发生在进程首次调用时),创建一个设备实例。
device:存储创建后的设备实例。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterDevice_release
NNAdapterDevice_release(NNAdapterDevice* device)
释放设备实例(注意:只有进程退出时,才会释放设备 HAL 层库)。
参数:
device:需要销毁的设备实例。
返回值:无。
NNAdapterDevice_getName
int NNAdapterDevice_getName(const NNAdapterDevice* device, const char** name)
获得设备名称。
参数:
device:设备实例。
name:存储返回的设备名称。
返回值:无。
NNAdapterDevice_getVendor
int NNAdapterDevice_getVendor(const NNAdapterDevice* device, const char** vendor)
获得设备厂商名称。
参数:
device:设备实例。
vendor:存储返回的设备厂商名称。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterDevice_getType
int NNAdapterDevice_getType(const NNAdapterDevice* device, NNAdapterDeviceType* type)
获得设备类型。
参数:
device:设备实例。
type:存储返回的设备类型值,由
NNAdapterDeviceCode定义,NNADAPTER_CPU代表 CPU ,NNADAPTER_GPU代表 GPU ,NNADAPTER_ACCELERATOR代表神经网络加速器。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterDevice_getVersion
int NNAdapterDevice_getVersion(const NNAdapterDevice* device, int32_t* version)
获取设备HAL动态链接库的版本值。
参数:
device:设备实例。
version:存储返回的设备 HAL 层库的版本值。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterContext_create
int NNAdapterContext_create(NNAdapterDevice** devices, uint32_t num_devices, const char* properties, NNAdapterContext** context)
为多种设备创建一个统一设备上下文,并通过 Key-value 字符串的形式将设备的参数信息传递给每一个设备 HAL 层库。
参数:
devices:设备实例列表。
num_devices:
devices中设备实例的个数。properties:设备参数信息,按照 Key-value 字符串的形式表示设备参数信息,例如: “HUAWEI_ASCEND_NPU_SELECTED_DEVICE_IDS=0” 表示只使用昇腾 310 卡中第 0 个核心。
context:存储创建后的统一设备上下文实例。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterContext_destroy
void NNAdapterContext_destroy(NNAdapterContext* context)
销毁统一设备上下文实例。
参数:
context:需要销毁的统一设备上下文实例。
返回值:无。
NNAdapterModel_create
int NNAdapterModel_create(NNAdapterModel** model)
创建一个空的、与设备无关的模型实例。
参数:
model:存储创建后的模型实例。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterModel_destroy
void NNAdapterModel_destroy(NNAdapterModel* model)
销毁模型实例及相关资源。
参数:
model:需要销毁的模型实例。
返回值:无。
NNAdapterModel_finish
int NNAdapterModel_finish(NNAdapterModel* model)
结束模型组网。
参数:
model:模型实例。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterModel_addOperand
int NNAdapterModel_addOperand(NNAdapterModel* model, const NNAdapterOperandType* type, NNAdapterOperand** operand)
向模型中增加一个操作数,即神经网络模型中的张量。
参数:
model:模型实例。
type:操作数的类型,由
NNAdapterOperandType定义,包含精度类型、数据布局、生命周期、维度信息和量化信息。operand:存储新增的操作数实例。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterModel_setOperandValue
int NNAdapterModel_setOperandValue(NNAdapterOperand* operand, void* buffer, uint32_t length, bool copy)
设置常量操作数的值。
参数:
operand:操作数实例。
buffer:常量数据的内存地址。
lenght:常量数据的内存大小(字节)。
copy:是否创建常量数据的内存副本,否则将直接引用
buffer。后者要求在模型编译前都不允许修改buffer指向的内容。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterModel_getOperandType
int NNAdapterModel_getOperandType(NNAdapterOperand* operand, NNAdapterOperandType** type)
查询操作数的类型。
参数:
operand:操作数实例。
type:存储返回的操作数类型。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterModel_addOperation
int NNAdapterModel_addOperation(NNAdapterModel* model, NNAdapterOperationType type, uint32_t input_count, NNAdapterOperand** input_operands, uint32_t output_count, NNAdapterOperand** output_operands, NNAdapterOperation** operation)
向模型中增加一个操作符,并设置它的输入、输出操作数,即神经网络模型中的算子。
参数:
model:模型实例。
type:操作符类型,由
NNAdapterOperationCode定义,包含二维卷积NNADAPTER_CONV_2D,最大值池化NNADAPTER_AVERAGE_POOL_2D,均值池化NNADAPTER_MAX_POOL_2D等操作符。input_count:输入操作数的数量。
input_operands:输入操作数列表,需严格按照每一个操作符的定义依次将对应的输入操作数加入到列表中。
output_count:输出操作数的数量。
output_operands:输出操作数列表,需严格按照每一个操作符的定义依次将对应的输出操作数加入到列表中。
operation:存储新增的操作符实例。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterModel_identifyInputsAndOutputs
int NNAdapterModel_identifyInputsAndOutputs(NNAdapterModel* model, uint32_t input_count, NNAdapterOperand** input_operands, uint32_t output_count, NNAdapterOperand** output_operands)
标识模型的输入、输出操作数,其生命周期将被标记为
NNADAPTER_MODEL_INPUT和NNADAPTER_MODEL_OUTPUT类型。参数:
model:模型实例。
input_count:输入操作数的数量。
input_operands:输入操作数列表,不约束每一个操作符顺序。
output_count:输出操作数的数量。
output_operands:输出操作数列表,不约束每一个操作符顺序。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterCompilation_create
int NNAdapterCompilation_create(NNAdapterModel* model, const char* cache_token, void* cache_buffer, uint32_t cache_length, const char* cache_dir, NNAdapterContext* context, NNAdapterCompilation** compilation)
创建一个编译实例,基于指定的统一设备上下文,为多种设备(当前版本仅支持一种设备)编译模型实例或直接加载模型缓存。如果同时设置模型实例和模型缓存参数,则优先加载模型缓存,因此存在以下三种情况:
1)当设置
cache_token,cache_buffer和cache_length时,则直接从内存中加载模型缓存,此时将忽略model参数。2)当设置
cache_token和cache_dir时,将从 <cache_dir> 指定的目录中查找并尝试加载 <cache_token>.nnc 模型缓存文件,成功加载后将忽略model参数,否则在调用NNAdapterCompilation_finish完成模型实例model的在线编译后,在 <cache_dir> 目录中生成 <cache_token>.nnc 文件。3)当
cache_token,cache_buffer,cache_length和cache_dir均未被设置时,则在调用NNAdapterCompilation_finish后完成模型实例model的在线编译。需要注意的是,由于未设置cache_token和cache_dir,在编译完成后将不会生成模型缓存文件,将使得在模型首次推理时都会进行模型的在线编译,导致首次推理耗时过长。参数:
model:模型实例。
cache_token:模型缓存唯一标识。
cache_buffer:模型缓存的内存地址。
cache_length:模型缓存的内存大小(字节),必须与
cache_buffer成对使用。cache_dir:模型缓存的目录。
context:统一设备上下文实例。
compilation:存储创建的编译实例。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterCompilation_destroy
void NNAdapterCompilation_destroy(NNAdapterCompilation* compilation)
销毁编译实例。
参数:
compilation:需要销毁的编译实例。
返回值:无。
NNAdapterCompilation_finish
int NNAdapterCompilation_finish(NNAdapterCompilation* compilation)
结束编译配置的设置,调用设备 HAL 层库对
NNAdapterCompilation_create中的模型实例model进行在线编译并生成设备程序。参数:
compilation:编译实例。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterCompilation_queryInputsAndOutputs
int NNAdapterCompilation_queryInputsAndOutputs(NNAdapterCompilation* compilation, uint32_t* input_count, NNAdapterOperandType** input_types, uint32_t* output_count, NNAdapterOperandType** output_types)
查询编译后的模型的输入、输出操作数的数量和类型,必须在
NNAdapterCompilation_finish执行后才能调用,可以通过以下两次调用获得输入、输出操作数数量和类型信息。1)当
input_types和output_types为 NULL 时,则仅查询输入、输出操作数的数量并将值存储在input_count和output_count。2)当
input_types和output_types不为 NULL 时,则将输入、输出操作数的类型依次存储在input_types和output_types(要求调用方根据input_count和output_count分配它们的内存)。参数:
compilation:编译实例。
input_count:存储返回的输入操作数的数量,不允许为 NULL 。
input_types:存储返回的输入操作数列表。
output_count:存储返回的输出操作数的数量,不允许为 NULL 。
output_types:存储返回的输出操作数列表。
返回值:调用成功则返回NNADAPTER_NO_ERROR。
NNAdapterExecution_create
int NNAdapterExecution_create(NNAdapterCompilation* compilation, NNAdapterExecution** execution)
基于编译实例创建一个执行计划实例。
为了方便理解
NNAdapterCompilation和NNAdapterExecution的区别,可以将NNAdapterCompilation简单理解为已经编译好的设备代码,而NNAdapterExecution代表如何执行它,可以是顺序依次执行,也可以并行执行,可以是同步执行,也可以是异步执行,但目前 NNAdapter 仅支持同步顺序执行。参数:
compilation:编译实例。
execution:存储创建的执行计划实例。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterExecution_destroy
void NNAdapterExecution_destroy(NNAdapterExecution* execution)
销毁执行计划实例。
参数:
execution:需要销毁的执行计划实例。
返回值:无。
NNAdapterExecution_setInput
int NNAdapterExecution_setInput(NNAdapterExecution* execution, int32_t index, void* memory, void* (*access)(void* memory, NNAdapterOperandType* type))
设置执行计划输入操作数的内存实例和访问函数。
为了能够让HAL层库更加灵活的访问推理框架的张量对象,在设置执行计划的输入时,要求设置内存实例
memory和内存实例访问函数access,例如:typedef struct { NNAdapterOperandPrecisionCode precision; uint32_t dimensions_count; int32_t dimensions_data[NNADAPTER_MAX_SIZE_OF_DIMENSIONS]; void* buffer; size_t length; } Memory; void* access_input_memory(void* memory, NNAdapterOperandType* type) { Memory* handle = reinterpret_cast<Memory*>(memory); // Return the dimensions and the host buffer to HAL memcpy(type->dimensions.data, handle->dimensions_data, handle->dimensions_count); return handle->buffer; } Memory input; NNAdapterExecution_setInput(execution, index, reinterpret_cast<void*>(&input), access_input_memory);
参数:
execution:执行计划实例。
index:模型输入操作数的索引。
memory:模型输入操作数的内存实例,不限定为具体的缓存首地址,用户可自行封装后通过 std::reinterpret_cast<void*>() 强制转为 void* 类型。
access:内存实例访问函数,HAL层库将通过
access函数访问memory获得 host 端缓存实际地址。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterExecution_setOutput
int NNAdapterExecution_setOutput(NNAdapterExecution* execution, int32_t index, void* memory, void* (*access)(void* memory, NNAdapterOperandType* type))
设置执行计划输出操作数的内存实例和访问函数。
基于
NNAdapterExecution_setInput示例中的memory的定义实现输出内存实例的访问函数access:void* access_output_memory(void* memory, NNAdapterOperandType* type) { Memory* handle = reinterpret_cast<Memory*>(memory); // Get the buffer length according to the type->precision and type->dimensions size_t request_length = GetBufferLength(type); if (request_length > handle->length) { free(handle->buffer); handle->buffer = malloc(request_length); assert(handle->buffer); handle->length = request_length; } // Tell the inference framework the output dimensions and return the host buffer to HAL memcpy(handle->dimensions_data, type->dimensions.data, type->dimensions.count); handle->dimensions_count = type->dimensions.count; return handle->buffer; } Memory output; NNAdapterExecution_setOutput(execution, index, reinterpret_cast<void*>(&output), access_output_memory);
参数:
execution:执行计划实例。
index:模型输出操作数的索引。
memory:模型输出操作数的内存实例,不限定为具体的缓存首地址,用户可自行封装后通过 std::reinterpret_cast<void*>() 强制转为 void* 类型。
access:内存实例访问函数,HAL层库将通过
access函数访问memory获得 host 端缓存实际地址。
返回值:调用成功则返回 NNADAPTER_NO_ERROR 。
NNAdapterExecution_compute
int NNAdapterExecution_compute(NNAdapterExecution* execution)
同步调度执行计划实例。
参数:
execution:执行计划实例。
返回值:无。
NNAdapter 标准算子¶
NNADAPTER_ABS
逐元素取绝对值:
output= abs(input) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_ADAPTIVE_AVERAGE_POOL_2D
二维自适应平均池化。
输入:
0 : input ,输入操作数,形状:[N, C_in, H_in, W_in] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : output_shape ,输出操作数的高和宽,形状: [2] ,类型: NNADAPTER_INT32 、 NNADAPTER_INT64 ,取值: 两个元素的值分别表示 H_out 和 W_out 。
输出:
0 : output ,输出操作数,形状: [N, C_in, H_out, W_out] ,类型与输入操作数
input相同。
NNADAPTER_ADAPTIVE_MAX_POOL_2D
二维自适应最大池化。
输入:
0 : input ,输入操作数,形状: [N, C_in, H_in, W_in] ,类型: NNADAPTER_FLOAT32 , NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : output_shape ,输出操作数的高和宽,形状: [2] ,类型: NNADAPTER_INT32 、 NNADAPTER_INT64 ,取值: 两个元素的值分别表示 H_out 和 W_out 。
2 : return_indices ,是否输出最大值的索引,形状: [1] ,类型: NNADAPTER_BOOL8 ,取值: true 、false ,默认是 false 。
3 : return_indices_dtype ,最大值的索引的类型,形状为 [1] ,类型: NNADAPTER_INT32 ,取值: NNADAPTER_INT32 或 NNADAPTER_INT64 。
输出:
0 : output ,输出操作数,形状: [N, C_in, H_out, W_out] ,类型与输入操作数
input相同。1 : indices ,输出最大值的索引操作数, 是否输出由输入操作数
return_indices决定,形状与输出操作数output相同,类型:NNADAPTER_INT32 、 NNADAPTER_INT64 ,由输入操作数return_indices_dtype决定。
NNADAPTER_ADD
逐元素相加:
output=input0+input1,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。2 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型与输入操作数input0和input1相同。
NNADAPTER_AND
逐元素逻辑与:
output=input0&&input1,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_BOOL8 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型与输入操作数input0和input1相同。
NNADAPTER_ARG_MAX
沿给定
axis轴计算输入操作数input的最大元素的索引值。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : axis , 在
axis轴上计算最大元素的索引值, 形状: [1] ,类型: NNADAPTER_INT32 ,取值:axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致。2 : keepdim ,是否保留
axis轴,如果保留,则输出操作数在该轴上的尺寸是 1 ,形状: [1] ,类型: NNADAPTER_BOOL8 ,取值: true 、 false 。3 : dtype ,输出的索引值的数据类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNADAPTER_INT32 、 NNADAPTER_INT64 ,默认是 NNADAPTER_INT64 。
输出:
0 : output ,输出操作数,形状:由输入操作数
input和keepdim决定,类型: NNADAPTER_INT32 、 NNADAPTER_INT64 ,由输入操作数dtype决定。
NNADAPTER_ARG_MIN
沿给定
axis轴计算输入操作数input的最小元素的索引值。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : axis , 在给定的轴上计算最小元素的索引值, 形状: [1] ,类型: NNADAPTER_INT32 ,取值:
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致。2 : keepdim ,是否保留操作的轴,形状: [1] ,类型: NNADAPTER_BOOL8 , 取值: true 、 false 。
3 : dtype ,输出的索引值的数据类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值:NNADAPTER_INT32 、 NNADAPTER_INT64 ,默认是 NNADAPTER_INT64 。
输出:
0 : output ,输出操作数,形状:由输入操作数
input和keepdim决定,类型: NNADAPTER_INT32 、 NNADAPTER_INT64 ,由输入操作数dtype决定.
NNADAPTER_ASSIGN
将输入操作数的数据拷贝至输出操作数。
输入:
0 : input ,输入操作数,数据类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_AVERAGE_POOL_2D
二维平均池化。
输入:
0 : input ,输入操作数,形状: [N, C_in, H_in, W_in] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : auto_pad ,填充模式,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterAutoPadCode 类型的任意值, NNADAPTER_AUTO_PAD_NONE 表示由输入操作数
pads显式指定填充大小, NNADAPTER_AUTO_PAD_SAME 表示自动计算填充大小保证输出与输入的形状相同,NNADAPTER_AUTO_PAD_VALID 表示不填充。2 : pads ,填充大小,可选,形状: [4] ,类型: NNADAPTER_INT32 ,取值:四个元素的值分别表示 height_top , height_bottom , width_left , width_right 。
3 : kernel_shape ,核的高和宽,形状: [2] ,类型: NNADAPTER_INT32 ,取值: 两个元素的值分别表示 kernel_height , kernel_width 。
4 : strides ,步长的高和宽,形状: [2] ,类型: NNADAPTER_INT32 ,取值:两个元素的值分别表示 stride_height , stride_width 。
5 : ceil_mode ,是否用 ceil 函数计算输出的高和宽,形状: [1] ,类型:NNADAPTER_BOOL8 , 取值: true 、 false ,默认是 false 。
6 : count_include_pad ,计算时是否包含填充区域,形状: [1] ,类型: NNADAPTER_BOOL8 ,取值: true 、 false ,默认是 false 。
7 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作出,形状: [N, C_out, H_out, W_out] ,类型与输入操作数
input相同 。当 ceil_mode 为 false 时,
H_out = floor((H_in + padding_height_top + padding_height_bottom - filter_height) / stride_height + 1)
W_out = floor((W_in + padding_width_left + padding_width_right - filter_width) / stride_width + 1)
当 ceil_mode 为 true 时,
H_out = ceil((H_in + padding_height_top + padding_height_bottom - filter_height) / stride_height + 1)
W_out = ceil((W_in + padding_width_left + padding_width_right - filter_width) / stride_width + 1)
NNADAPTER_BATCH_NORMALIZATION
按批次正则化,根据均值和方差对批数据的每个通道进行正则化,具体实现方式请参考论文 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift https://arxiv.org/pdf/1502.03167.pdf 。
输入:
0 : input ,输入操作数,形状: [N, C ,…] ,输入维度要求大于 2 ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : scale ,缩放,形状: [C] ,类型: NNADAPTER_FLOAT32 。
2 : bias ,偏移,形状: [C] ,类型: NNADAPTER_FLOAT32 。
3 : mean ,均值,形状: [C] ,类型: NNADAPTER_FLOAT32 。
4 : variance ,方差,形状: [C] ,类型: NNADAPTER_FLOAT32 。
5 : epsilon ,加上方差上防止发生除零错误的极小值,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值:任意浮点数,默认是 1e-5。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_CAST
数据类型转换。
输入:
0 : input ,输入操作数,类型: NNADAPTER_BOOL8 、 NNADAPTER_INT8 、 NNADAPTER_UINT8 、 NNADAPTER_INT16 、 NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_FLOAT16 、 NNADAPTER_FLOAT32 、 NNADAPTER_FLOAT64 。
1 : dtype ,目标类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNADAPTER_BOOL8 、 NNADAPTER_INT8 、 NNADAPTER_UINT8 、 NNADAPTER_INT16 、 NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_FLOAT16 、 NNADAPTER_FLOAT32 、 NNADAPTER_FLOAT64 、 NNADAPTER_FLOAT64 。
输出:
0 : output ,输出操作数,类型与
dtype相同,形状和input相同。
NNADAPTER_CHANNEL_SHUFFLE
通道混洗重排,它将输入通道分成
group个子组,并通过逐一从每个子组中选择元素来获得新的顺序: C_out[k * group + g] = C_in[g * size + k] ,其中 size = C_in / group ,具体实现请参考论文 https://arxiv.org/pdf/1707.01083.pdf 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : group ,子组的数目,必须整除
input的通道数,形状: [1] ,类型: NNADAPTER_FLOAT32。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_CLIP
对所有元素进行剪裁,使其限制在 [
min,max] 内:output= min(max(input,min),max) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : min ,裁剪的最小值,形状: [1] , 类型与
input相同。2 : max ,裁剪的最大值,形状: [1] , 类型与
input相同。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_CONCAT
沿
axis轴将多个输入进行拼接。输入:
0 ~ n-1 : input0 ~ inputn-1 :输入 0 ~ n-1 个的操作数,形状:除
axis轴的维度不同,所有输入的其它维度数必须相同,类型:NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。n : axis ,沿该轴进行拼接,形状: [1] ,类型: NNADAPTER_INT32 ,取值:
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致。
输出:
0 : output ,输出操作数,与输入操作数
input0~inputn-1的类型相同。
NNADAPTER_CONV_2D
二维卷积。
输入:
0 : input ,输入操作数,形状: [N, C_in, H_in, W_in] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : filter ,卷积核参数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 、 NNADAPTER_QUANT_INT8_SYMM_PER_CHANNEL ,形状满足如下约束:
如果是常规卷积,那么形状是 [C_out, C_in, filter_height, filter_width] ,其中 C_out 和 C_in 分别表示输出和输出的通道数, filter_height 和 filter_width 分别是卷积核的高和宽。
如果是深度可分离卷积,那么形状是 [C_out, 1, filter_height, filter_width] ,其中 C_out 是输出通道数, filter_height 和 filter_width 分别是卷积核的高和宽。
2 : bias ,偏置,形状: [C_out] ,类型满足如下约束:
如果输入类型是 NNADAPTER_FLOAT32 ,那么类型和输入一致。
如果卷积核类型是 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER ,那么类型为 NNADAPTER_QUANT_INT32_SYMM_PER_LAYER ,且 bias_scale == input_scale * filter_scale 。
如果卷积核类型是 NNADAPTER_QUANT_INT8_SYMM_PER_CHANNEL ,那么类型为 NNADAPTER_QUANT_INT32_SYMM_PER_CHANNEL ,且对于每个输出通道 i ,满足:bias_scale[i] = input_scale * filter_scale[i] 。
3 : auto_pad ,填充模式,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterAutoPadCode 类型的任意值, NNADAPTER_AUTO_PAD_NONE 表示由输入操作数
pads显式指定填充大小, NNADAPTER_AUTO_PAD_SAME 表示自动计算填充大小保证输出与输入的形状相同,NNADAPTER_AUTO_PAD_VALID 表示不填充。4 : pads ,填充大小,可选,形状: [4] , 类型: NNADAPTER_INT32 ,取值:四个元素的值分别表示 height_top , height_bottom , width_left , width_right 。
5 : strides ,步长的高和宽,形状: [2] ,类型: NNADAPTER_INT32 ,取值:两个元素的值分别表示 stride_height , stride_width 。
6 : group ,卷积分组数, 形状: [1] ,类型: NNADAPTER_INT32 ,取值满足如下约束:
如果是常规卷积,那么
group必须为 1 。如果是深度可分离卷积,那么必须满足:
group= C_out = C_in 。
7 : dilations ,空洞的高和宽,形状: [2] ,类型: NNADAPTER_INT32 ,取值: 两个元素的值分别表示 dilations_height , dilations_width 。
8 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作数,类型与输入
input相同,形状: [N, C_out, H_out, W_out],计算公式如下:H_out = (H_in + padding_height_top + padding_height_bottom - (dilation_height * (filter_height - 1) + 1)) / stride_height + 1
W_out = (W_in + padding_width_left + padding_width_right - (dilation_width * (filter_width - 1) + 1)) / stride_width + 1
NNADAPTER_CONV_2D_TRANSPOSE
二维转置(反)卷积。
输入 :
0 : input,输入操作数,形状: [N, C_in, H_in, W_in] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : filter ,卷积核参数,形状: [C_out, C_in, filter_height, filter_width] ,其中 C_out 和 C_in 分别表示输出和输出的通道数, filter_height 和 filter_width 分别是卷积核的高和宽, 类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 、 NNADAPTER_QUANT_INT8_SYMM_PER_CHANNEL 。
2 : bias ,偏置,形状: [C_out] ,类型满足如下约束:
如果输入类型是 NNADAPTER_FLOAT32 ,那么类型和输入一致。
如果卷积核类型是 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER ,那么类型为 NNADAPTER_QUANT_INT32_SYMM_PER_LAYER ,且 bias_scale == input_scale * filter_scale 。
如果卷积核类型是 NNADAPTER_QUANT_INT8_SYMM_PER_CHANNEL ,那么类型为 NNADAPTER_QUANT_INT32_SYMM_PER_CHANNEL ,且对于每个输出通道 i ,满足:bias_scale[i] = input_scale * filter_scale[i] 。
3 : auto_pad ,填充模式,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterAutoPadCode 类型的任意值, NNADAPTER_AUTO_PAD_NONE 表示由输入操作数
pads显式指定填充大小, NNADAPTER_AUTO_PAD_SAME 表示自动计算填充大小保证输出与输入的形状相同,NNADAPTER_AUTO_PAD_VALID 表示不填充。4 : pads ,填充大小,可选,形状: [4] , 类型: NNADAPTER_INT32 ,取值:四个元素的值分别表示 height_top , height_bottom , width_left , width_right 。
5 : strides ,步长的高和宽,形状: [2] ,类型: NNADAPTER_INT32 ,取值:两个元素的值分别表示 stride_height , stride_width 。
6 : group ,卷积分组数, 形状: [1] ,类型: NNADAPTER_INT32 ,取值满足如下约束:
如果是常规卷积,那么
group必须为 1 。如果是深度可分离卷积,那么必须满足:
group= C_out = C_in 。
7 : dilations ,空洞的高和宽,形状: [2] ,类型: NNADAPTER_INT32 ,取值: 两个元素的值分别表示 dilations_height , dilations_width 。
8 : output_padding ,输出填充大小,可选, 形状: [2] , 类型: NNADAPTER_INT32 ,取值:两个元素的值分别表示 output_pad_height , output_pad_width 。
9 : output_shape ,输出操作数的宽和高,可选,形状: [2] , 类型: NNADAPTER_INT32 、 NNADAPTER_INT64 ,取值:两个元素的值分别表示 output_height , output_width 。
10 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出 :
0 : output ,输出操作数,类型与输入
input相同,形状: [N, C_out, H_out, W_out],计算公式如下:H_out = (H_in - 1) * stride_height - padding_height_top - padding_height_bottom + (dilation_height * (filter_height - 1)) + 1 + output_padding_height
W_out = (W_in - 1) * stride_width - padding_width_left - padding_width_right + (dilation_width * (filter_width - 1) + 1)) + 1 + output_padding_width
NNADAPTER_COS
逐元素取余弦值:
output= cos(input) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_CUM_SUM
沿给定
axis轴计算累加和。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : axis ,沿该轴计算累加和,形状: [1] ,类型: NNADAPTER_INT32 ,取值:
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致,默认是 -1 。2 : exclusive ,是否排除第一个元素,即累加后的结果的第一个元素为零,类型: NNADAPTER_NOOL8 , 取值: true 、 false ,默认是 false 。
3 : reverse ,是否反向执行累加和,类型: NNADAPTER_NOOL8 ,取值: true 、 false ,默认是 false 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_DEFORMABLE_CONV_2D
二维可变形卷积。
输入:
0 : input ,输入操作数,形状: [N, C_in, H_in, W_in] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : offset ,输入坐标偏移,形状: [N, 2 * deformable_groups * H_f * W_f, H_in, W_in] ,类型和输入操作数
input相同。2 : mask , 输入掩码,形状: [N, deformable_groups * H_f * W_f, H_in, W_in] ,类型和输入操作数
input相同。3 : filter ,卷积核参数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 、 NNADAPTER_QUANT_INT8_SYMM_PER_CHANNEL ,形状满足如下约束:
如果是常规卷积,那么形状是 [C_out, C_in, filter_height, filter_width] ,其中 C_out 和 C_in 分别表示输出和输出的通道数, filter_height 和 filter_width 分别是卷积核的高和宽。
如果是深度可分离卷积,那么形状是 [C_out, 1, filter_height, filter_width] ,其中 C_out 是输出通道数, filter_height 和 filter_width 分别是卷积核的高和宽。
4 : bias ,偏置,形状: [C_out] ,类型满足如下约束:
如果输入类型是 NNADAPTER_FLOAT32 ,那么类型和输入一致。
如果卷积核类型是 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER ,那么类型为 NNADAPTER_QUANT_INT32_SYMM_PER_LAYER ,且 bias_scale == input_scale * filter_scale 。
如果卷积核类型是 NNADAPTER_QUANT_INT8_SYMM_PER_CHANNEL ,那么类型为 NNADAPTER_QUANT_INT32_SYMM_PER_CHANNEL ,且对于每个输出通道 i ,满足:bias_scale[i] = input_scale * filter_scale[i] 。
5 : pads ,填充大小,可选,形状: [4] , 类型: NNADAPTER_INT32 ,取值:四个元素的值分别表示 height_top , height_bottom , width_left , width_right 。
6 : strides ,步长的高和宽,形状: [2] ,类型: NNADAPTER_INT32 ,取值:两个元素的值分别表示 stride_height , stride_width 。
7 : group ,卷积分组数, 形状: [1] ,类型: NNADAPTER_INT32 ,取值满足如下约束:
如果是常规卷积,那么
group必须为 1 。如果是深度可分离卷积,那么必须满足:
group= C_out = C_in 。
8 : deformable_group ,可变形卷积组数,形状: [1] , 类型: NNADAPTER_INT32 。
9 : dilations ,空洞的高和宽,形状: [2] ,类型: NNADAPTER_INT32 ,取值: 两个元素的值分别表示 dilations_height , dilations_width 。
10 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作数,类型与输入
input相同,形状: [N, C_out, H_out, W_out],计算公式如下:H_out = (H_in + padding_height_top + padding_height_bottom - (dilation_height * (filter_height - 1) + 1)) / stride_height + 1
W_out = (W_in + padding_width_left + padding_width_right - (dilation_width * (filter_width - 1) + 1)) / stride_width + 1
NNADAPTER_DEQUANTIZE
反量化:
output= (input- zero_point) * scale , 其中 zero_point 和 scale 来自输入操作数input的类型参数,如果采用对称量化,则有:zero_point = 0 。输入:
0 : input ,输入操作数,类型: NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 、 NNADAPTER_QUANT_INT8_SYMM_PER_CHANNEL 、 NNADAPTER_QUANT_UINT8_ASYMM_PER_LAYER 、 NNADAPTER_QUANT_UINT8_ASYMM_PER_CHANNEL 。
输出:
0 : output ,输出操作数,类型:NNADAPTER_FLOAT32,形状和
input相同。
NNADAPTER_DIV
逐元素除:
output=input0/input1,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。2 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型与输入操作数input0和input1相同。
NNADAPTER_EQUAL
逐元素关系等于:
output=input0==input1,与 Numpy 的广播规则 https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_BOOL8 、NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型: NNADAPTER_BOOL8 。
NNADAPTER_EXP
逐元素计算 e 的次幂:
output= e^input。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_EXPAND
根据给定的形状对输入进行扩展,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。
输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : shape ,给定扩展后的形状,形状:任意一维操作数,类型: NNADAPTER_INT32 、 NNADAPTER_INT64 。
输出:
0 : output ,输出操作数,形状与
shape的值相同,类型和input相同。
NNADAPTER_FILL
创建指定形状和类型的操作数,将其所有元素值全部填充为同一个值。
输入:
0 : shape ,输出操作数的形状,形状:任意一维操作数,类型: NNADAPTER_INT32 、 NNADAPTER_INT64 .
1 : value ,填充值,形状: [1] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_BOOL .
输出:
0 : output,输出操作数,形状与
shape的值相同,类型和值与value相同。
NNADAPTER_FILL_LIKE
根据给定操作数的形状创建一个新的操作数,将其所有元素值全部填充为同一个值。
输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 ,NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : value ,填充值,形状: [1] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_BOOL .
输出:
0 : output,输出操作数,形状与输入操作数
input相同,类型和值与value相同。
NNADAPTER_FLATTEN
根据给定的
start_axis和stop_axis起、止轴将连续的维度进行展开。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 , NNADAPTER_QUANT_INT8_SYMM_PER_LAYER , NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : start_axis ,展开的起始维度,形状: [1] ,类型: NNADAPTER_INT32 。
2 : end_axis ,展开的结束维度,形状: [1] ,类型: NNADAPTER_INT32 。
输出:
0: output ,输出操作数,类型与输入操作数
input相同.
NNADAPTER_FLOOR
逐元素向下取整:
output= floor(input) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_FLOOR_DIV
逐元素相除并向下取整:
output= floor (input0/input1) ,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。2 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型与输入操作数input0和input1相同。
NNADAPTER_FULLY_CONNECTED
全链接层:
output= activation(input*weight’ +bias) 。输入:
0 : input ,输入操作数,形状:两维及以上,如果大于两维,将会被平展成两维 [batch_size, input_size] ,其中 input_size =
weight[1] , batch_size = num_elements / input_size , num_elements 是input的元素个数, 类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。1 : weight ,权重参数,形状: [num_units, input_size] ,其中 num_units 代表全链接层输出节点个数(或输出特征大小), input_size 为全链接层输入节点个数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 、 NNADAPTER_QUANT_INT8_SYMM_PER_CHANNEL 。
2 : bias ,偏置,形状: [num_units] ,类型满足如下约束:
如果权重类型是 NNADAPTER_FLOAT32 ,那么类型和输入一致。
如果权重类型是 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER ,那么类型为 NNADAPTER_QUANT_INT32_SYMM_PER_LAYER ,且 bias_scale == input_scale * weight_scale 。
如果权重类型是 NNADAPTER_QUANT_INT8_SYMM_PER_CHANNEL ,那么类型为 NNADAPTER_QUANT_INT32_SYMM_PER_CHANNEL ,且对于每个输出通道 i ,满足:bias_scale[i] = input_scale * weight_scale[i] 。
3 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作数,形状: [batch_size, num_units] ,类型与输入操作数
input相同。
NNADAPTER_GATHER
沿着给定的轴根据索引获取指定的单个或多个条目。
输入:
0 : input , 输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : indices ,索引,类型: NNADAPTER_INT32 、 NNADAPTER_INT64 ,假设维度为 Q,取值:不能超过输入操作数
input在axis维度的长度。2 : axis ,在给定的轴上根据索引获取单个或多个条目,形状: [1] ,类型: NNADAPTER_INT32 ,取值:
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致。
输出:
0 : output ,输出操作数,类型和输入操作数
input相同,维度是 Q + (R - 1) 。
NNADAPTER_GELU
逐元素计算高斯误差线性单元激活值,具体实现请参考论文 https://arxiv.org/abs/1606.08415 。
输入:
0 : input , 输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : approximate ,是否使用近似计算,形状: [1] ,类型: NNADAPTER_BOOL8 ,取值:true 、 false 。
输出
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_GREATER
逐元素关系大于:
output=input0>input1,与 Numpy 的广播规则 https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_BOOL8 、NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型: NNADAPTER_BOOL8 。
NNADAPTER_GREATER
逐元素关系大于等于:
output=input0>=input1,与 Numpy 的广播规则 https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_BOOL8 、NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型: NNADAPTER_BOOL8 。
NNADAPTER_GRID_SAMPLE
基于 flow field 网格的对输入进行双线性插值采样,网格通常由 affine_grid 生成, 形状为 [N, H, W, 2] ,它是 [N, H, W] 的采样点的 (x, y) 坐标。 其中,x 坐标是输入数据的 W 维度的索引,y 坐标是 H 维度的索引,最终输出采样值为采样点的四个最接近的角点的双线性插值结果,输出形状为 [N, C, H, W] 。
输入:
0 : input ,输入操作数 ,形状: [N, C, H, W] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : grid ,网格数据,形状: [N, H, W, 2] , 类型: NNADAPTER_FLOAT32。
2 : align_corners ,输入和输出四个角落像素的中心是否对齐,是否保留角点像素的值,形状: [1] ,类型: NNADAPTER_BOOL8 ,取值: true 、 false 。
3 :mode ,插值方式,形状: [1] ,类型: NNADAPTER_INT32 ,取值:NNAdapterInterpolateMode 类型的任意值, NNADAPTER_INTERPOLATE_MODE_NONE 、 NNADAPTER_INTERPOLATE_MODE_BILINEAR 、 NNADAPTER_INTERPOLATE_MODE_NEAREST 。
4 :pad_mode ,当索引超过输入的图像大小时的填充方式,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterPadMode 类型的任意值, NNADAPTER_PAD_MODE_NONE 、 NNADAPTER_PAD_MODE_CONSTANT 、 NNADAPTER_PAD_MODE_REFLECT 、 NNADAPTER_PAD_MODE_REPLICATE 、 NNADAPTER_PAD_MODE_EDGE 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_GROUP_NORMALIZATION
按组正则化,根据均值和方差对通道进行分组正则化,具体实现方式请参考论文 Group Normalization https://arxiv.org/abs/1803.08494 。
输入:
0 : input ,输入操作数,形状: [N, C ,…] ,输入维度要求大于 2 ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : scale ,缩放,形状: [C] ,类型: NNADAPTER_FLOAT32 。
2 : bias ,偏移,形状: [C] ,类型: NNADAPTER_FLOAT32 。
3 : epsilon ,加上方差上防止发生除零错误的极小值,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值:任意浮点数,默认是 1e-5。
4 :groups ,通道分组数, 形状: [1],类型:NNADAPTER_INT32 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_HARD_SIGMOID
逐元素计算分段线性逼近激活值:
output= max(0, min(1,alpha*input+beta)) 。输入:
0 : input , 输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : alpha , 斜率,形状: [1] ,类型: NNADAPTER_FLOAT32 。
2 : beta ,截距,形状: [1] ,类型: NNADAPTER_FLOAT32 。
输出:
0 : output , 输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_HARD_SWISH
逐元素计算 hardswish 激活值:
output=input* max(0, min(1,alpha*input+beta)) 。输入:
0 : input , 输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : alpha , 斜率,形状: [1] ,类型: NNADAPTER_FLOAT32 。
2 : beta ,截距,形状: [1] ,类型: NNADAPTER_FLOAT32 。
输出:
0 : output , 输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_INSTANCE_NORMALIZATION
按实例正则化,根据每个样本的每个通道的均值和方差信息进行正则化, 具体实现请参考论文 Instance Normalization: The Missing Ingredient for Fast Stylization https://arxiv.org/abs/1607.08022 。
输入:
0 : input ,输入操作数,形状: [N, C ,…] ,输入维度要求大于 2 ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : scale ,缩放,形状: [C] ,类型: NNADAPTER_FLOAT32 。
2 : bias ,偏移,形状: [C] ,类型: NNADAPTER_FLOAT32 。
3 : epsilon ,加上方差上防止发生除零错误的极小值,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值:任意浮点数,默认是 1e-5 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_LAYER_NORMALIZATION
按层正则化,具体实现请参考论文 Layer Normalization https://arxiv.org/pdf/1607.06450v1.pdf 。
输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : scale ,缩放,形状:
begin_norm_axis轴到 rank(input) 的全部维度 ,类型: NNADAPTER_FLOAT32 。2 : bias ,偏移,形状:
begin_norm_axis轴到 rank(input) 的全部维度 ,类型: NNADAPTER_FLOAT32 。3 : begin_norm_axis ,归一化将沿着
begin_norm_axis轴到 rank(input) 的维度执行,形状: [1] ,类型: NNADAPTER_INT32 。4 : epsilon ,加上方差上防止发生除零错误的极小值,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值:任意浮点数,默认是 1e-5 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_LEAKY_RELU
逐元素计算修正线性单元激活值: 当
input>= 0 时,output=input; 当input< 0 时,output=alpha*input。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : alpha ,公式中当输入小于零时的斜率,形状: [1] ,类型: NNADAPTER_FLOAT32。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_LESS
逐元素关系小于:
output=input0<input1,与 Numpy 的广播规则 https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_BOOL8 、NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型: NNADAPTER_BOOL8 。
NNADAPTER_LESS_EQUAL
逐元素关系小于等于:
output=input0<=input1,与 Numpy 的广播规则 https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_BOOL8 、NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型: NNADAPTER_BOOL8 。
NNADAPTER_LOG
逐元素计算自然对数:
output= ln(input) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_LOG_SOFTMAX
沿着给定的轴逐元素计算 log softmax 激活值:
output= log(exp(input) / reduce_sum(exp(input), axis=axis, keepdims=true)) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER tensor 。
1 : axis ,指定运算的轴,形状: [1] ,类型: NNADAPTER_INT32 ,取值:
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致,默认是 1 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_LP_NORMALIZATION
沿给定轴进行 Lp 正则化: 当
p= 1 时,output= input / (sum(abs(input)) +epsilon) ; 当p= 2 时,output=input/ (sqrt(sum(input^2)) +epsilon) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : axis ,在给定的轴上进行 Lp 正则化,形状: [1] ,类型: NNADAPTER_INT32 ,取值:
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致,默认是 1 。2 : p ,正则化的指数,形状: [1] ,类型: NNADAPTER_INT32 ,取值: 1 、2 ,默认是 2 。
3 : epsilon ,加上方差上防止发生除零错误的极小值,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值:任意浮点数,默认是 1e-5 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_LRN
局部响应正则化层,用于对局部输入区域正则化,执行一种侧向抑制,具体实现参考论文:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32。
1 : size ,累加的通道数,形状: [1] ,类型: NNADAPTER_INT32 ,取值:任意整数,默认是 5
2 : bias ,位移,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值:任意浮点数,默认是 1.f 。
3 : alpha ,缩放参数,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值:任意浮点数,默认是 1e-4 。
4 : beta ,指数参数,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值:任意浮点数,默认是 0.75f 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_MAT_MUL
计算两个操作数的乘积,计算方法与 numpy.matmul https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.matmul.html 相同。
输入:
0 : x ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : y ,输入操作数 1 ,类型与输入操作数
x相同。2 : transpose_x , 是否对
x的最后两维转置,形状: [1] , 类型:NNADAPTER_BOOL8 ,取值: true 、 false ,默认是 false 。3 : transpose_y, 是否对
y的最后两维转置,形状: [1] , 类型:NNADAPTER_BOOL8 ,取值: true 、 false ,默认是 false 。
输出:
0: output, 形状:由输入操作数
x和y广播后的形状决定,类型与输入操作数x和y相同。
NNADAPTER_MAX
逐元素取最大值:
output= max(input0,input1) ,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。2 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型与输入操作数input0和input1相同。
NNADAPTER_MAX_POOL_2D
二维最大池化。
输入:
0 : input ,输入操作数,形状:[N, C_in, H_in, W_in] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : auto_pad ,填充模式,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterAutoPadCode 类型的任意值, NNADAPTER_AUTO_PAD_NONE 表示由输入操作数
pads显式指定填充大小, NNADAPTER_AUTO_PAD_SAME 表示自动计算填充大小保证输出与输入的形状相同,NNADAPTER_AUTO_PAD_VALID 表示不填充。2 : pads ,填充大小,可选,形状: [4] ,类型: NNADAPTER_INT32 ,取值:四个元素的值分别表示 height_top , height_bottom , width_left , width_right 。
3 : kernel_shape ,核的高和宽,形状: [2] ,类型: NNADAPTER_INT32 ,取值: 两个元素的值分别表示 kernel_height , kernel_width 。
4 : strides ,步长的高和宽,形状: [2] ,类型: NNADAPTER_INT32 ,取值:两个元素的值分别表示 stride_height , stride_width 。
5 : ceil_mode ,是否用 ceil 函数计算输出的高和宽,形状: [1] ,类型:NNADAPTER_BOOL8 , 取值: true 、 false ,默认是 false 。
6 : return_indices ,是否输出最大值的索引,形状: [1] ,类型: NNADAPTER_BOOL8 ,取值: true 、false ,默认是 false 。
7 : return_indices_dtype ,最大值的索引的类型,形状为 [1] ,类型: NNADAPTER_INT32 ,取值: NNADAPTER_INT32 或 NNADAPTER_INT64 。
8 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作出,形状: [N, C_out, H_out, W_out] ,类型与输入操作数
input相同 。当 ceil_mode 为 false 时,
H_out = floor((H_in + padding_height_top + padding_height_bottom - filter_height) / stride_height + 1)
W_out = floor((W_in + padding_width_left + padding_width_right - filter_width) / stride_width + 1)
当 ceil_mode 为 true 时,
H_out = ceil((H_in + padding_height_top + padding_height_bottom - filter_height) / stride_height + 1)
W_out = ceil((W_in + padding_width_left + padding_width_right - filter_width) / stride_width + 1)
1 : indices ,输出最大值的索引操作数, 是否输出由输入操作数
return_indices决定,形状与输出操作数output相同,类型:NNADAPTER_INT32 、 NNADAPTER_INT64 ,由输入操作数return_indices_dtype决定。
NNADAPTER_MESHGRID
根据给定的多个向量创建多个网格。
输入:
0 : input0 ~ inputn-1 ,输入 0 ~ n-1 个的操作数,形状:任意一维操作数, [d0], [d1], … [dn-1] ,类型:NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output0 ~ outputn-1 ,输出 n 个操作数,形状: [d0, d1, …, dn-1],类型与输入操作数
input0~inputn-1相同。
NNADAPTER_MIN
逐元素取最小值:
output= min(input0,input1) ,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。2 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型与输入操作数input0和input1相同。
NNADAPTER_MUL
逐元素相乘:
output=input0*input1,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。2 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型与输入操作数input0和input1相同。
NNADAPTER_NOT
逐元素逻辑非:
output= !input。输入:
0 : input ,输入操作数,类型: NNADAPTER_BOOL8 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_NOT_EQUAL
逐元素关系不等于:
output=input0!=input1,与 Numpy 的广播规则 https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_BOOL8 、NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型: NNADAPTER_BOOL8 。
NNADAPTER_OR
逐元素逻辑或:
output=input0||input1,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_BOOL8 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型与输入操作数input0和input1相同。
NNADAPTER_PAD
多维填充。
输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_INT32 、 NNADAPTER_INT64 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : pads , 填充大小,形状: [2 * rank(
input)] ,类型: NNADAPTER_INT32 ,取值: 根据每个维度设置填充大小,每个元素代表的含义为: x0_begin, x0_end, x1_begin, x1_end, … ,其中 x0_begin 和 x0_end 分别代表第 0 维的左、右边界的填充大小。2 : mode ,填充模式, 形状: [1] , 类型: NNADAPTER_INT32 ,取值: NNAdapterPadModeCode 类型的任意值, NNADAPTER_PAD_MODE_NONE 、 NNADAPTER_PAD_MODE_CONSTANT 、 NNADAPTER_PAD_MODE_REFLECT 、 NNADAPTER_PAD_MODE_REPLICATE 、 NNADAPTER_PAD_MODE_EDGE 。
3 : value ,填充值,仅当填充模式为 NNADAPTER_PAD_MODE_CONSTANT 时有效,形状: [1] ,类型与输入操作数
input相同。
输出:
0: output ,输出操作数,形状:由输入操作数
input的形状和pads的值决定,类型与输入操作数input相同。
NNADAPTER_POW
逐元素计算指数:
output=input0^input1,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。2 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型与输入操作数input0和input1相同。
NNADAPTER_PRIOR_BOX
在 SSD ( Single Shot MultiBox Detector )模型中用于生成候选框,输入的每个位产生 N 个候选框, N 由
min_sizes,max_sizes和aspect_ratios的数目决定,候选框的尺寸在 (min_size,max_size) 之间,该尺寸根据aspect_ratios在序列中生成。输入:
0 : input ,特征 ,形状: [N, C, H, W] ,类型: NNADAPTER_FLOAT32 。
1 : image ,图像 ,形状: [N, C, H, W] ,类型: NNADAPTER_FLOAT32 。
2 : min_sizes , 生成的候选框的最小尺寸,形状: 任意一维操作数,类型: NNADAPTER_FLOAT32 。
3 : max_sizes , 生成的候选框的最大尺寸,形状: 任意一维操作数,类型: NNADAPTER_FLOAT32 。
4 : aspect_ratios ,生成的候选框的长宽比,形状: 任意一维操作数,类型: NNADAPTER_FLOAT32 。
5 : variances ,候选框中解码的方差,形状: 任意一维操作数,类型: NNADAPTER_FLOAT32 。
6 : flip ,是否翻转,形状: [1] ,类型: NNADAPTER_BOOL ,取值: true 、 false ,默认是 false 。
7 : clip ,是否裁剪,形状: [1] ,类型: NNADAPTER_BOOL ,取值: true 、 false ,默认是 false 。
8 : step_w ,候选框在 W 维度的步长,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值: 0.0 表示自动计算候选框在 W 维度的步长。
9 : step_h ,候选框在 H 维度的步长,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值: 0.0 表示自动计算候选框在 H 维度的步长。
10 : offset , 候选框中心位移 ,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值: 默认是 0.5 。
11 : min_max_aspect_ratios_order ,最大、最小宽高比的顺序,形状: [1] ,类型: NNADAPTER_BOOL ,取值: true 、 false , true 表示候选框的输出以 [min, max, aspect_ratios] 的顺序输出,和 Caffe 保持一致,但需要注意的是,该顺序会影响后面卷基层的权重顺序,但不影响最后的检测结果,默认是 false 。
输出:
0 : boxes ,候选框,形状: [H, W, num_priors, 4] ,其中 num_priors 输入每位的总框数, 类型: NNADAPTER_FLOAT32 。
1 : variances ,候选框方差,形状: [H, W, num_priors, 4] ,其中 num_priors 输入每位的总框数, 类型: NNADAPTER_FLOAT32 。
NNADAPTER_PRELU
逐元素计算参数化修正线性单元激活值:当
input>= 0 时,output=input;当input< 0 时,output=slope*input。输入:
0 : input ,输入操作数,形状: [N, C, …] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : alpha ,公式中当输入小于零时的斜率,形状: [1] 或 [C] ,类型: NNADAPTER_FLOAT32。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_QUANTIZE
量化:
output=input/scale+zero_point。输入:
0 : input ,输入操作数,形状: [N, C, …] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_FLOAT32 。
1 : axis ,沿该轴量化,仅在 per-channel 或 per-axis 量化方式时有效,由
scale的形状决定,形状: [1] ,类型: NNADAPTER_INT32 ,取值:axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致,默认是 1 。2 : scale ,量化公式中的 scale 参数,形状: [1] 或 [C] ,[C] 代表量化方式为 per-channel 或 per-axis,[1] 代表 per-layer 或 per-tensor 量化方式,类型: NNADAPTER_FLOAT32。
3 : zero_point ,量化公式中的 zero_point 参数,形状: 必须与
scale相同,类型: NNADAPTER_FLOAT32。
输出:
0 : output ,输出操作数,类型: NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 、 NNADAPTER_QUANT_INT8_SYMM_PER_CHANNEL 、 NNADAPTER_QUANT_UINT8_ASYMM_PER_LAYER 、 NNADAPTER_QUANT_UINT8_ASYMM_PER_CHANNEL ,由
scale和zero_point决定,形状和input相同。
NNADAPTER_RANGE
生成一个由以步长
step均匀分隔给定数值区间 [start,end) 的连续数值组成的操作数。输入:
0 : start ,起点,形状: [1] ,类型: NNADAPTER_FLOAT32, NNADAPTER_INT32 。
1 : end ,终点(但不包括该值),与输入操作数
start的形状和类型相同。2 : step ,步长,与输入操作数
start的形状和类型相同。
输出:
0 : output ,输出操作数,形状:一维操作数,长度由
start、end、step共同决定, 类型与输入操作数start相同。
NNADAPTER_REDUCE_MAX
沿着给定的单个或多个轴计算最大值。
输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : axes ,给定的单个或多个轴,形状:任意一维操作数,类型: NNADAPTER_INT32 ,取值: 每个
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致,如果是空,则对所有维度计算并返回单个元素。2 : keepdim ,输出操作数是否保留减小的维度。
输出:
0 : output ,输出操作数,形状:由
input、axes、keepdim共同决定, 类型与输入操作数input相同。
NNADAPTER_REDUCE_MEAN
沿着给定的单个或多个轴计算平均值。
输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : axes ,给定的单个或多个轴,形状:任意一维操作数,类型: NNADAPTER_INT32 ,取值: 每个
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致,如果是空,则对所有维度计算并返回单个元素。2 : keepdim ,输出操作数是否保留减小的维度。
输出:
0 : output ,输出操作数,形状:由
input、axes、keepdim共同决定, 类型与输入操作数input相同。
NNADAPTER_REDUCE_SUM
沿着给定的单个或多个轴计算和。
输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : axes ,给定的单个或多个轴,形状:任意一维操作数,类型: NNADAPTER_INT32 ,取值: 每个
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致,如果是空,则对所有维度计算并返回单个元素。2 : keepdim ,输出操作数是否保留减小的维度。
输出:
0 : output ,输出操作数,形状:由
input、axes、keepdim共同决定, 类型与输入操作数input相同。
NNADAPTER_RELU
逐元素计算线性整流单元激活值:
output= max(0,input) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_RELU6
逐元素计算线性整流单元激活值:
output= min(6, max(0,input)) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_RESHAPE
改变形状,维持所包含的元素的数量和数值不变。
输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : shape ,目标形状,类型: 一维操作数,类型: NNADAPTER_INT32 、 NNADAPTER_INT64 ,取值: 所有元素的值中最多只能有一个是 -1 , 0 代表和原来相应位置的维度相同。
输出:
0 : output ,输出操作数,形状:由
shape和input的形状计算获得,类型与输入操作数input相同。
NNADAPTER_RESIZE_NEAREST
基于最临近插值法调整图像大小,输出的高和宽按照
shape、scales顺序确定优先级。输入:
0 : input ,输入操作数,形状: 类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : shape ,输出形状, 形状: [2] ,类型: NNADAPTER_INT32 、 NNADAPTER_INT64 。
2 : scales ,输入的高度和宽度的乘数因子, 形状: [2] ,类型: NNADAPTER_FLOAT32 ,取值:
shape和scales必须至少设置一个。3 : align_corners ,输入和输出四个角落像素的中心是否对齐,是否保留角点像素的值,形状: [1] ,类型: NNADAPTER_BOOL8 ,取值: true 、 false 。
输出:
0 : output ,输出操作数,形状:由
shape、scales、input的维度计算获得,类型与输入操作数input相同。
NNADAPTER_RESIZE_LINEAR
基于双向性插值法调整图像大小,输出的高和宽按照
shape、scales顺序确定优先级。输入:
0 : input ,输入操作数,形状: 类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : shape ,输出形状, 形状: [2] ,类型: NNADAPTER_INT32 、 NNADAPTER_INT64 。
2 : scales ,输入的高度和宽度的乘数因子, 形状: [2] ,类型: NNADAPTER_FLOAT32 ,取值:
shape和scales必须至少设置一个。3 : align_corners ,输入和输出四个角落像素的中心是否对齐,是否保留角点像素的值,形状: [1] ,类型: NNADAPTER_BOOL8 ,取值: true 、 false 。
4 : align_mode ,计算坐标时的对齐方式,形状, [1] ,类型: NNADAPTER_INT32 ,取值: 0 表示 src_idx = scale *(dst_indx + 0.5)- 0.5,1 表示 src_idx = scale * dst_index 。
输出:
0 : output ,输出操作数,形状:由
shape、scales、input的维度计算获得,类型与输入操作数input相同。
NNADAPTER_ROI_ALIGN
在指定输入的感兴趣区域上基于双线性插值以获得固定大小的特征图,具体实现请参考论文 Mask R-CNN https://arxiv.org/abs/1703.06870 。
输入:
0 : input ,输入操作数,形状: [N, C, H, W] ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : rois ,感兴趣区域( regions of interest )的矩形框坐标,形状: [rois_num, 4] ,其中 rois_num 是感兴趣区域的数量,类型: NNADAPTER_FLOAT32 ,取值:所有元素按照 [[x1, y1, x2, y2], …] 顺序排列 。
2 : batch_indices ,每个感兴趣区域所对应的输入批次的索引, 形状: [rois_num] ,类型: NNADAPTER_INT32 。
3 : output_height ,输出高度,形状: [1] ,类型: NNADAPTER_INT32 。
4 : output_width ,输出宽度,形状: [1] ,类型: NNADAPTER_INT32 。
5 : sampling_ratio ,插值的采样点数目,形状: [1] ,类型: NNADAPTER_INT32 ,取值:如果 <= 0 ,将自适应 roi_width 和 output_width ,在高度上同样适用。
6 : spatial_scale ,空间比例因子,将
rois中的坐标从其输入尺寸按比例映射到输入特征图的尺寸,形状: [1] , 类型: NNADAPTER_FLOAT32 。7 : aligned ,计算坐标时是否对齐,形状, [1] ,类型: NNADAPTER_BOOL8 ,取值: true 、 false , true 表示 src_idx = scale *(dst_indx + 0.5)- 0.5,false 表示 src_idx = scale * dst_index 。
输出:
0 : output ,输出操作数,形状: [N, C, output_height, output_width] ,类型与输入操作数
input相同。
NNADAPTER_ROLL
沿给定维度滚动张量输入。超出最后位置的元素将在第一个位置重新引入,如果不设置 axes,则张量将在滚动之前展开变平,然后恢复为原始形状。。
输入 :
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : shifts ,表示张量元素移动的位置数,给定的单个或多个轴,形状:任意一维操作数,类型: NNADAPTER_INT32 。
2 : axes ,表示滚动的单个或多个轴,形状:任意一维操作数,类型: NNADAPTER_INT32 。
输出 :
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_RSQRT
逐元素计算平方根的倒数:
output= 1 / (sqrt(input)) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_SHAPE
获得输入的形状。
输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : dtype ,输出类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNADAPTER_INT32 或 NNADAPTER_INT64 。
Outputs:
0 : output ,输出操作数,形状: 一维操作数, 类型: NNADAPTER_INT32 、 NNADAPTER_INT64 。
NNADAPTER_SIGMOID
逐元素计算 sigmoid 激活值:
output= 1 / (1 + exp(-input)) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_SIN
逐元素取正弦值:
output= sin(input) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_SLICE
沿着多个轴生成
input的片段。类似 numpy : https://docs.scipy.org/doc/numpy/reference/arrays.indexing.html ,沿着axes的每个轴以starts、ends、step为起始、终止、步长获取input的片段。如果starts[i]、ends[i]为负数,则需要加上输入input对应轴axes[i]的维度dims[axes[i]]。如果starts[i]或ends[i]的值大于dims[axes[i]],将被截断到dims[axes[i]] - 1。如果dims[axes[i]]维度未知,建议将ends[i]设置为INT_MAX,反向则设置为INT_MIN。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER tensor 。
1 : axes ,沿着多个轴切片,可选,形状:一维操作数,类型: NNADAPTER_INT32 ,取值:如果不设置,则表示 [0, 1, …, len(
starts) - 1] 。2 : starts ,起始索引值,形状与输入操作数
axes相同,类型: NNADAPTER_INT32 。3 : ends ,结束索引值,形状与输入操作数
axes相同,类型: NNADAPTER_INT32 。4 : steps ,结束索引值,形状与输入操作数
axes相同,类型: NNADAPTER_INT32 ,取值: 默认值是 1。
输出:
0 : output ,输出操作数,形状:由
axes、starts、ends、steps和input的维度计算获得,类型与输入操作数input相同。
NNADAPTER_SOFTMAX
沿着给定的轴逐元素计算 softmax 激活值:
output= exp(input) / reduce_sum(exp(input), axis=axis, keepdims=true) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER tensor 。
1 : axis ,指定运算的轴,形状: [1] ,类型: NNADAPTER_INT32 ,取值:
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致,默认是 1 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_SOFTPLUS
逐元素计算 softplus 激活值:
output= log(1 + exp^(beta*input)) /beta,考虑数值稳定性,当beta*input> threshold ,公式转变为线性函数output=input。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : alpha ,公式中当输入小于零时的斜率,形状: [1] ,类型: NNADAPTER_FLOAT32。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_SPLIT
沿着给定的轴将输入分割成多个子部分。
输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : axis ,待分割的轴, 形状: [1] ,类型: NNADAPTER_INT32 ,取值:
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致。2 : split ,每个子部分的数量,形状:一维操作数,类型: NNADAPTER_INT32 ,取值:所有元素之和必须等于
input在axis轴的维度。
输出:
0 ~ n-1 : output0 ~ outputn-1 ,操作数列表,每个操作数的形状由
axis、split和input的维度计算获得,类型与输入操作数input相同。
NNADAPTER_SQUARE
逐元素计算平方:
output=input^2 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_SQUEEZE
沿给定
axes轴删除input的形状中长度为 1 的维度。输入 :
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : axes ,给定的单个或多个轴,形状:任意一维操作数,类型: NNADAPTER_INT32 ,取值: 每个
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致,如果是空,则删除所有维度中长度为 1 的维度。
输出 :
0 : output ,输出操作数,与输入操作数
input的类型相同。
NNADAPTER_STACK
沿给定
axis轴对输入进行堆叠操作,要求所有输入的形状相同。输入 :
0 ~ n-1 : input0 ~ inputn-1 ,输入 0 ~ n-1 个的操作数,形状:所有输入的维度数必须相同,类型:NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
n :axis ,沿该轴堆叠,形状: [1] ,类型: NNADAPTER_INT32 ,取值:
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致。
输出 :
0 : output ,输出操作数,与输入操作数
input0~inputn-1的类型相同。
NNADAPTER_SUB
逐元素相减:
output=input0-input1,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。2 : fuse_code ,融合的激活函数类型,形状: [1] ,类型: NNADAPTER_INT32 ,取值: NNAdapterFuseCode 类型的任意值, NNADAPTER_FUSED_NONE 、 NNADAPTER_FUSED_RELU 、 NNADAPTER_FUSED_RELU1 、 NNADAPTER_FUSED_RELU6 。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0和input1广播后的形状决定,类型与输入操作数input0和input1相同。
NNADAPTER_SUM
多个输入逐元素求和:
output=input0+input1+ … +inputn-1,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同。输入:
0 ~ n-1 : input0 ~ inputn-1 ,输入 0 ~ n-1 个的操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,形状:由输入操作数
input0~inputn-1广播后的形状决定,类型与输入操作数input0~inputn-1相同。
NNADAPTER_SWISH
逐元素计算 swish 激活值:
output=input/ (1 + e ^ (-input)) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_TANH
逐元素计算 tanh 激活值:
output= tanh(input) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
输出:
0 : output ,输出操作数,与输入操作数
input的形状和类型相同。
NNADAPTER_TILE
沿着输入的每个维度 i 复制
repeats[i]次。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : repeats ,每个维度的复制次数,形状: [rank(
input)] ,类型: NNADAPTER_INT32 。
输出:
0 : output ,输出操作数,形状:维数与
input相同,且 output_dims[i] = input_dims[i] * repeats[i] ,类型:与输入操作数input相同。
NNADAPTER_TOP_K
沿给定的轴
axis在input中查找最大或最小的前k个值和索引。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_INT32, NNADAPTER_INT64 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : k ,查找并返回的数量,类型:NNADAPTER_INT32 、 NNADAPTER_INT64。
2 : axis ,沿该轴查找,形状: [1] ,类型: NNADAPTER_INT32 ,取值:
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致。3 : largest ,是否返回最大的
k个值,类型: NNADAPTER_BOOL8 ,取值: true 、 false , false 代表返回最小的k个值。4 : sorted ,返回的结果是否按有序排列,类型: NNADAPTER_BOOL8 ,取值: true 、 false 。
5 : return_indices_dtype ,返回索引的类型,类型: NNADAPTER_INT32 ,取值: NNADAPTER_INT32 、 NNADAPTER_INT64 。
输出:
0 : output ,返回的
k个值,类型:与输入操作数input相同。1 : indices ,返回的
k个值的索引,类型:NNADAPTER_INT32 或 NNADAPTER_INT64 。
NNADAPTER_TRANSPOSE
根据
perm对输入进行数据重排,类似于 numpy.transpose https://numpy.org/doc/stable/reference/generated/numpy.transpose.html 。例如:输入的形状为 (1, 2, 4) ,perm为 (1, 0, 2) ,输出形状为 (2, 1, 3) 。输入:
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : perm , 维度索引列表, 形状: [rank(
input)] ,类型: NNADAPTER_INT32 。
输出:
0 : output ,输出操作数,形状:维数与
input相同,且 output_dims[i] = input_dims[perm[i]] ,类型:与输入操作数input相同。
NNADAPTER_UNSQUEEZE
沿给定
axes轴在input的形状中插入长度为 1 的维度。输入 :
0 : input ,输入操作数,类型: NNADAPTER_FLOAT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
1 : axes ,给定的单个或多个轴,形状:任意一维操作数,类型: NNADAPTER_INT32 ,取值: 每个
axis的有效范围是 [-R, R) , R 是输入操作数input的维度,当axis为负数时,效果与axis+ R 一致,如果是空,则删除所有维度中长度为 1 的维度。
输出 :
0 : output ,输出操作数,与输入操作数
input的类型相同。
NNADAPTER_WHERE
根据条件
condition从input0或input1中选择元素作为输出,广播规则与 Numpy https://numpy.org/doc/stable/user/basics.broadcasting.html 相同, 行为与 numpy.where https://numpy.org/doc/stable/reference/generated/numpy.where.html 相同。输入 :
0 : condition ,选择
input0或input1的条件,类型: NNADAPTER_BOOL8 ,取值:对应位置的值为 true,则输出的相应位置返回input0的元素,否则返回input1的元素。1 : input0 ,输入操作数 0 ,类型: NNADAPTER_FLOAT32 、 NNADAPTER_INT32 、 NNADAPTER_QUANT_INT8_SYMM_PER_LAYER 。
2 : input1 ,输入操作数 1 ,类型与输入操作数
input0相同。
输出 :
0 : output ,输出操作数,与输入操作数
input的类型相同。
NNADAPTER_YOLO_BOX
基于YOLOv3网络的输出结果,生成YOLO检测框, 具体细节可以参考 https://www.paddlepaddle.org.cn/documentation/docs/zh/2.1/api/paddle/vision/ops/yolo_box_cn.html#yolo-box 。
输入 :
0 : input ,输入操作数,形状: [N, C, H, W],类型: NNADAPTER_FLOAT32 ,取值:第二维(C)存储每个 anchor box 位置坐标,每个 anchor box 的置信度分数和 one hot key 。
1 : imgsize ,图像大小,按输入图像比例调整输出框的大小,形状: [N, 2] ,类型: NNADAPTER_INT32 。
2 : anchors ,anchor 的宽度和高度,需要逐对解析,形状: [2] ,类型: NNADAPTER_INT32 。
3 : class_num ,类别总数,形状: [1] ,类型: NNADAPTER_INT32 。
4 : conf_thresh ,检测框的置信度得分阈值,置信度得分低于阈值的框应该被忽略,形状: [1] ,类型: NNADAPTER_FLOAT32 。
5 : downsample_ratio ,下采样率,形状: [1] ,类型: NNADAPTER_INT32 。
6 : clip_bbox ,是否将输出的 bbox 裁剪到
imgsize范围内,形状: [1] ,类型: NNADAPTER_BOOL8,取值: true 、false ,默认是 true 。7 : scale_x_y ,缩放解码边界框的中心点,形状: [1] ,类型: NNADAPTER_FLOAT32 ,取值: 默认是 1.0 。
8 : iou_aware ,是否使用 IoU-aware ,形状: [1] ,类型: NNADAPTER_BOOL8 。
9 : iou_aware_factor ,IoU-aware 因子大小,形状: [1] ,类型: NNADAPTER_FLOAT32 。
输出 :
0 : output ,检测框坐标,形状: [N, M, 4] ,其中 N 表示批数量,M 表示检测框的数量,最后一个维度存储检测框的坐标,类型: NNADAPTER_FLOAT32 ,取值: 每四个元素代表检测框的 xmin 、 ymin 、 xmax 和 ymax 。
1 : scores ,检测框得分,形状: [N, M,
class_num] ,类型: NNADAPTER_FLOAT32 。