# PaddleLite使用华为麒麟NPU预测部署
Paddle Lite是首款支持华为自研达芬奇架构NPU(Kirin 810/990 SoC搭载的NPU)的预测框架。
原理是在线分析Paddle模型,将Paddle算子转成HiAI IR后,调用HiAI IR/Builder/Runtime APIs生成并执行HiAI模型。
## 支持现状
### 已支持的芯片
- Kirin 810/820/990/985/9000
### 已支持的设备
- Kirin 990:HUAWEI Mate 30系列, 荣耀 V20系列, nova 6系列,P40系列,Mate Xs
- Kirin 985:HUAWEI nova 7 5G,nova 7 Pro 5G,荣耀 30
- Kirin 820:HUAWEI nova 7 SE 5G,荣耀 30S
- Kirin 810:HUAWEI nova 5系列,nova 6 SE,荣耀 9X系列,荣耀 Play4T Pro
### 已支持的Paddle模型
- [MobileNetV1](https://paddlelite-demo.bj.bcebos.com/models/mobilenet_v1_fp32_224_fluid.tar.gz)
- [MobileNetV2](https://paddlelite-demo.bj.bcebos.com/models/mobilenet_v2_fp32_224_fluid.tar.gz)
- ResNet系列(例如[ResNet18](https://paddlelite-demo.bj.bcebos.com/models/resnet18_fp32_224_fluid.tar.gz)、[ResNet50](https://paddlelite-demo.bj.bcebos.com/models/resnet50_fp32_224_fluid.tar.gz))
- [SqueezeNet](https://paddlelite-demo.bj.bcebos.com/models/squeezenet_fp32_224_fluid.tar.gz)
- [MnasNet](https://paddlelite-demo.bj.bcebos.com/models/mnasnet_fp32_224_fluid.tar.gz)
- [MobileNet-SSD](https://paddlelite-demo.bj.bcebos.com/models/ssd_mobilenet_v1_pascalvoc_fp32_300_fluid.tar.gz) *
- YOLOv3系列(例如[YOLOv3-MobileNetV3](https://paddlelite-demo.bj.bcebos.com/models/yolov3_mobilenet_v3_prune86_FPGM_320_fp32_fluid.tar.gz)) *
- [Transformer](https://github.com/PaddlePaddle/models/tree/release/1.8/PaddleNLP/machine_translation/transformer) *
- CycleGAN
- 百度内部业务模型(由于涉密,不方便透露具体细节)
带*表示该模型的部分算子不支持华为Kirin NPU加速,而是采用ARM CPU+华为Kirin NPU异构计算方式获得支持。
### 已支持(或部分支持)的Paddle算子
- sigmoid
- relu
- tanh
- relu_clipped
- relu6
- leaky_relu
- softsign
- hard_sigmoid
- log
- sqrt
- square
- thresholded_relu
- batch_norm
- less_than
- concat
- conv2d
- depthwise_conv2d
- conv2d_transpose
- dropout
- elementwise_add
- elementwise_sub
- elementwise_mul
- elementwise_div
- expand
- fusion_elementwise_add_activation
- fusion_elementwise_sub_activation
- fusion_elementwise_mul_activation
- fusion_elementwise_div_activation
- increment
- instance_norm (需要HiAI DDK330)
- fc
- bilinear_interp
- nearest_interp
- layer_norm (需要HiAI DDK330)
- matmul
- mul
- pad2d
- pool2d
- reduce_mean
- reshape
- reshape2
- scale
- shuffle_channel
- softmax
- split
- transpose
- transpose2
- unsqueeze
- unsqueeze2
可以通过访问[https://github.com/PaddlePaddle/Paddle-Lite/blob/develop/lite/kernels/npu/bridges/paddle_use_bridges.h](https://github.com/PaddlePaddle/Paddle-Lite/blob/develop/lite/kernels/npu/bridges/paddle_use_bridges.h)获得最新的算子支持列表。
## 参考示例演示
### 测试设备(HUAWEI Mate30 5G)

### 准备设备环境
- 由于HiAI DDK可能依赖特定版本的ROM,建议用户更新至最新版EMUI系统,具体参考华为官方[手机升级指南](https://consumer.huawei.com/cn/support/update/)。
### 准备交叉编译环境
- 为了保证编译环境一致,建议参考[编译环境准备](../source_compile/compile_env)中的Docker开发环境进行配置。
### 运行图像分类示例程序
- 下载示例程序[PaddleLite-android-demo.tar.gz](https://paddlelite-demo.bj.bcebos.com/devices/huawei/kirin/PaddleLite-android-demo_v2_8_0.tar.gz),解压后清单如下:
```shell
- PaddleLite-android-demo
- image_classification_demo # 基于MobileNetV1的图像分类示例程序
- assets
- images
- tabby_cat.jpg # 测试图片
- labels
- synset_words.txt # 1000分类label文件
- models
- mobilenet_v1_fp32_224_fluid # Paddle fluid non-combined格式的mobilenetv1 float32模型
- mobilenet_v1_fp32_224_for_cpu
- model.nb # 已通过opt转好的、适合ARM CPU的mobilenetv1模型
- mobilenet_v1_fp32_224_for_huawei_kirin_npu
- model.nb # 已通过opt转好的、适合华为Kirin NPU的mobilenetv1模型
- shell # android shell端的示例程序,注意:HiAI存在限制,拥有ROOT权限才能正常运行shell端程序
- CMakeLists.txt # android shell端的示例程序CMake脚本
- build
- image_classification_demo # 已编译好的android shell端的示例程序
- image_classification_demo.cc # 示例程序源码
- build.sh # android shell端的示例程序编译脚本
- run.sh # android shell端的示例程序运行脚本
- apk # 常规android应用程序,无需ROOT
- app
- src
- main
- java # java层代码
- cpp # 自定义的jni实现
- app.iml
- build.gradle
- gradle
...
- libs
- PaddleLite
- bin
- opt # 适合Ubuntu x86平台、预编译的模型优化工具
- armeabi-v7a # 适合armv7架构的PaddleLite预编译库以及HiAI运行时库
- include # PaddleLite头文件,每次版本更新时记得替换掉,否则可能会出现segmentation fault或精度无法对齐的问题
- lib
- libc++_shared.so # HiAI DDK中的so库是基于c++_shared编译生成的,部署时记得带上它
- libpaddle_light_api_shared.so # 用于最终移动端部署的预编译PaddleLite库(tiny publish模式下编译生成的库)
- libpaddle_full_api_shared.so # 用于直接加载Paddle模型进行测试和Debug的预编译PaddleLite库(full publish模式下编译生成的库)
- libhiai.so # HiAI runtime库函数,主要实现模型加载、执行和Tensor的操作
- libhiai_ir.so # HiAI IR/Graph的定义
- libhiai_ir_build.so # HiAI IRGraph转om模型的接口
- libhcl.so # HiAI NPU高性能算子库
- libcpucl.so # HiAI的CPU算子库,PaddleLite中没有用到,理论上可以删掉
- arm64-v8a # 适合armv8架构的PaddleLite预编译库以及HiAI运行时库
- OpenCV # OpenCV 4.2 for android
- object_detection_demo # 基于YOLOv3_MobileNetV3的目标检测示例程序(手动子图划分章节会详细介绍)
```
- Android shell端的示例程序
- 按照以下命令分别运行转换后的ARM CPU模型和华为Kirin NPU模型,比较它们的性能和结果;
```shell
注意:
1)由于HiAI的限制,需要root权限才能执行shell示例程序;
2)run.sh只能在连接设备的系统上运行,不能在docker环境执行(可能无法找到设备),也不能在设备上运行;
3)build.sh需要在docker环境中执行,否则,需要将build.sh的ANDROID_NDK修改为当前环境下的NDK路径;
4)以下执行结果均由armeabi-v7a库生成,如果需要测试arm64-v8a库,可将build.sh的ANDROID_ABI修改成arm64-v8a后重新生成image_classification_demo,同时将run.sh的ANDROID_ABI也修改成arm64-v8a即可)。
运行适用于ARM CPU的mobilenetv1模型
$ cd PaddleLite-android-demo/image_classification_demo/assets/models
$ cp mobilenet_v1_fp32_224_for_cpu/model.nb mobilenet_v1_fp32_224_fluid.nb
$ cd ../../shell
$ ./run.sh
...
iter 0 cost: 34.467999 ms
iter 1 cost: 34.514999 ms
iter 2 cost: 34.646000 ms
iter 3 cost: 34.713001 ms
iter 4 cost: 34.612000 ms
iter 5 cost: 34.551998 ms
iter 6 cost: 34.741001 ms
iter 7 cost: 34.655998 ms
iter 8 cost: 35.035000 ms
iter 9 cost: 34.661999 ms
warmup: 5 repeat: 10, average: 34.659999 ms, max: 35.035000 ms, min: 34.467999 ms
results: 3
Top0 tabby, tabby cat - 0.475008
Top1 Egyptian cat - 0.409487
Top2 tiger cat - 0.095745
Preprocess time: 2.040000 ms
Prediction time: 40.704300 ms
Postprocess time: 0.105000 ms
运行适用于华为Kirin NPU的mobilenetv1模型
$ cd PaddleLite-android-demo/image_classification_demo/assets/models
$ cp mobilenet_v1_fp32_224_for_huawei_kirin_npu/model.nb mobilenet_v1_fp32_224_fluid.nb
$ cd ../../shell
$ ./run.sh
...
iter 0 cost: 2.426000 ms
iter 1 cost: 2.428000 ms
iter 2 cost: 2.465000 ms
iter 3 cost: 2.401000 ms
iter 4 cost: 2.406000 ms
iter 5 cost: 2.492000 ms
iter 6 cost: 2.411000 ms
iter 7 cost: 2.397000 ms
iter 8 cost: 2.441000 ms
iter 9 cost: 2.402000 ms
warmup: 5 repeat: 10, average: 2.426900 ms, max: 2.492000 ms, min: 2.397000 ms
results: 3
Top0 tabby, tabby cat - 0.477539
Top1 Egyptian cat - 0.408447
Top2 tiger cat - 0.094788
Preprocess time: 1.724000 ms
Prediction time: 2.426900 ms
Postprocess time: 0.127000 ms
```
- 如果需要更改测试图片,可将图片拷贝到PaddleLite-android-demo/image_classification_demo/assets/images目录下,然后将run.sh的IMAGE_NAME设置成指定文件名即可;
- 如果需要重新编译示例程序,直接运行./build.sh即可。
- 常规Android应用程序
(如果不想按照以下步骤编译Android应用程序,可以直接在Android设备上通过浏览器下载和安装已编译好的apk[image_classification_demo.apk](https://paddlelite-demo.bj.bcebos.com/devices/huawei/kirin/image_classification_demo.apk))
- 访问[https://developer.android.google.cn/studio](https://developer.android.google.cn/studio/)下载安装Android Studio(当前Android demo app是基于Android Studio3.4开发的),如果无法访问,可以从[http://www.android-studio.org](http://www.android-studio.org/)下载;
- 打开Android Studio,在"Welcome to Android Studio"窗口点击"Open an existing Android Studio project",在弹出的路径选择窗口中进入"PaddleLite-android-demo/image_classification_demo/apk"目录,然后点击右下角的"Open"按钮即可导入工程;
- 通过USB连接Android手机、平板或开发板;
- 待工程加载完成后,首先,点击菜单栏的File->Sync Project with Gradle Files手动同步项目构建;然后,点击菜单栏的Build->Rebuild Project按钮,如果提示CMake版本不匹配,请点击错误提示中的'Install CMake xxx.xxx.xx'按钮,重新安装CMake,再次点击菜单栏的Build->Rebuild Project按钮;
- 待工程编译完成后,点击菜单栏的Run->Run 'App'按钮,在弹出的"Select Deployment Target"窗口选择已经连接的Android设备,然后点击"OK"按钮;
- 等待大约1分钟后(第一次时间比较长,需要耐心等待),app已经安装到设备上。默认使用ARM CPU模型进行推理,如下图所示,推理耗时34.8ms,整个流程(含预处理和后处理)的帧率约22fps;

- 点击app界面右下角的设置按钮,在弹出的设置页面点击"Choose pre-installed models",选择"mobilenet_v1_fp32_for_huawei_kirin_npu",点击返回按钮后,app将切换到华为Kirin NPU模型,如下图所示,推理耗时下降到3.4ms,帧率提高到29fps(由于代码中帧率统计限制在30fps以内,因此实际帧率会更高,具体地,您可以手动计算截图中Read GLFBO time、Write GLTexture time、Predict time和Postprocess time的总耗时)。

### 更新模型
- 通过Paddle Fluid训练,或X2Paddle转换得到MobileNetv1 foat32模型[mobilenet_v1_fp32_224_fluid](https://paddlelite-demo.bj.bcebos.com/models/mobilenet_v1_fp32_224_fluid.tar.gz);
- 参考[模型转化方法](../user_guides/model_optimize_tool),利用opt工具转换生成华为Kirin NPU模型,仅需将valid_targets设置为npu,arm即可。
```shell
注意:需要保证opt工具和库版本一致。
$ cd PaddleLite-android-demo/image_classification_demo/assets/models
$ GLOG_v=5 ./opt --model_dir=mobilenet_v1_fp32_224_fluid \
--optimize_out_type=naive_buffer \
--optimize_out=opt_model \
--valid_targets=npu,arm
...
[I 8/12 6:56:25.460 ...elease/Paddle-Lite/lite/core/optimizer.h:229 RunPasses] == Running pass: memory_optimize_pass
[I 8/12 6:56:25.460 ...elease/Paddle-Lite/lite/core/optimizer.h:242 RunPasses] - Skip memory_optimize_pass because the target or kernel does not match.
[I 8/12 6:56:25.461 ...te/lite/core/mir/generate_program_pass.h:37 GenProgram] insts.size 1
[I 8/12 6:56:25.683 ...e-Lite/lite/model_parser/model_parser.cc:593 SaveModelNaive] Save naive buffer model in 'opt_model.nb' successfully
替换自带的华为Kirin NPU模型
$ cp opt_model.nb mobilenet_v1_fp32_224_for_huawei_kirin_npu/model.nb
```
- 注意:opt生成的模型只是标记了华为Kirin NPU支持的Paddle算子,并没有真正生成华为Kirin NPU模型,只有在执行时才会将标记的Paddle算子转成HiAI IR并组网得到HiAI IRGraph,然后生成并执行华为Kirin NPU模型(具体原理请参考Pull Request[#2576](https://github.com/PaddlePaddle/Paddle-Lite/pull/2576));
- 不同模型,不同型号(ROM版本)的华为手机,在执行阶段,由于某些Paddle算子无法完全转成HiAI IR,或目标手机的HiAI版本过低等原因,可能导致HiAI模型无法成功生成,在这种情况下,Paddle Lite会调用ARM CPU版算子进行运算完成整个预测任务。
### 更新支持华为Kirin NPU的PaddleLite库
- 下载PaddleLite源码和最新版HiAI DDK
```shell
$ git clone https://github.com/PaddlePaddle/Paddle-Lite.git
$ cd Paddle-Lite
$ git checkout
$ wget https://paddlelite-demo.bj.bcebos.com/devices/huawei/kirin/hiai_ddk_lib_330.tar.gz
$ tar -xvf hiai_ddk_lib_330.tar.gz
```
- 编译并生成PaddleLite+HuaweiKirinNPU for armv8 and armv7的部署库
```shell
For armv8
tiny_publish
$ ./lite/tools/build_android.sh --android_stl=c++_shared --with_extra=ON --with_log=ON --with_huawei_kirin_npu=ON --huawei_kirin_npu_sdk_root=./hiai_ddk_lib_330
full_publish
$ ./lite/tools/build_android.sh --android_stl=c++_shared --with_extra=ON --with_log=ON --with_huawei_kirin_npu=ON --huawei_kirin_npu_sdk_root=./hiai_ddk_lib_330 full_publish
For armv7
tiny_publish
$ ./lite/tools/build_android.sh --arch=armv7 --android_stl=c++_shared --with_extra=ON --with_log=ON --with_huawei_kirin_npu=ON --huawei_kirin_npu_sdk_root=./hiai_ddk_lib_330
full_publish
$ ./lite/tools/build_android.sh --arch=armv7 --android_stl=c++_shared --with_extra=ON --with_log=ON --with_huawei_kirin_npu=ON --huawei_kirin_npu_sdk_root=./hiai_ddk_lib_330 full_publish
备注:由于HiAI DDK的so库均基于c++_shared构建,建议将android stl设置为c++_shared,更多选项还可以通过 "./lite/tools/build_android.sh help" 查看。
```
- 将编译生成的build.lite.android.armv8.gcc/inference_lite_lib.android.armv8.npu/cxx/include替换PaddleLite-android-demo/libs/PaddleLite/arm64-v8a/include目录;
- 将tiny_publish模式下编译生成的build.lite.android.armv8.gcc/inference_lite_lib.android.armv8.npu/cxx/lib/libpaddle_light_api_shared.so替换PaddleLite-android-demo/libs/PaddleLite/arm64-v8a/lib/libpaddle_light_api_shared.so文件;
- 将full_publish模式下编译生成的build.lite.android.armv8.gcc/inference_lite_lib.android.armv8.npu/cxx/lib/libpaddle_full_api_shared.so替换PaddleLite-android-demo/libs/PaddleLite/arm64-v8a/lib/libpaddle_full_api_shared.so文件;
- 将编译生成的build.lite.android.armv7.gcc/inference_lite_lib.android.armv7.npu/cxx/include替换PaddleLite-android-demo/libs/PaddleLite/armeabi-v7a/include目录;
- 将tiny_publish模式下编译生成的build.lite.android.armv7.gcc/inference_lite_lib.android.armv7.npu/cxx/lib/libpaddle_light_api_shared.so替换PaddleLite-android-demo/libs/PaddleLite/armeabi-v7a/lib/libpaddle_light_api_shared.so文件;
- 将full_publish模式下编译生成的build.lite.android.armv7.gcc/inference_lite_lib.android.armv7.npu/cxx/lib/libpaddle_full_api_shared.so替换PaddleLite-android-demo/libs/PaddleLite/armeabi-v7a/lib/libpaddle_full_api_shared.so文件。
## 如何支持CPU+华为Kirin NPU异构计算?
- 上述示例中所使用的MobileNetv1 foat32模型[mobilenet_v1_fp32_224_fluid](https://paddlelite-demo.bj.bcebos.com/models/mobilenet_v1_fp32_224_fluid.tar.gz),它的所有算子均能成功转成华为Kirin NPU的HiAI IR,因此,能够获得非常好的加速效果;
- 而实际情况是,你的模型中可能存在华为Kirin NPU不支持的算子,尽管opt工具可以成功生成ARM CPU+华为Kirin NPU的异构模型,但可能因为一些限制等原因,模型最终执行失败或性能不够理想;
- 我们首先用一个简单的目标检测示例程序让你直观感受到ARM CPU+华为Kirin NPU异构模型带来的性能提升;然后,简要说明一下华为Kirin NPU接入PaddleLite的原理;最后,详细介绍如何使用『自定义子图分割』功能生成正常运行的ARM CPU+华为Kirin NPU异构模型。
### 运行目标检测示例程序
- 『运行图像分类示例程序』章节中的[PaddleLite-android-demo.tar.gz](https://paddlelite-demo.bj.bcebos.com/devices/huawei/kirin/PaddleLite-android-demo_v2_8_0.tar.gz)同样包含基于[YOLOv3_MobileNetV3](https://paddlelite-demo.bj.bcebos.com/models/yolov3_mobilenet_v3_prune86_FPGM_320_fp32_fluid.tar.gz)的目标检测示例程序;
```shell
- PaddleLite-android-demo
- image_classification_demo # 基于MobileNetV1的图像分类示例程序
- libs # PaddleLite和OpenCV预编译库
- object_detection_demo # 基于YOLOv3_MobileNetV3的目标检测示例程序
- assets
- images
- kite.jpg # 测试图片
- labels
- coco-labels-2014_2017.txt # coco数据集的label文件
- models
- yolov3_mobilenet_v3_prune86_FPGM_fp32_320_fluid # Paddle fluid combined格式的、剪枝后的YOLOv3_MobileNetV3 float32模型
- yolov3_mobilenet_v3_prune86_FPGM_fp32_320_for_cpu
- model.nb # 已通过opt转好的、适合ARM CPU的YOLOv3_MobileNetV3模型
- yolov3_mobilenet_v3_prune86_FPGM_fp32_320_for_hybrid_cpu_huawei_kirin_npu
- model.nb # 已通过opt转好的、适合ARM CPU+华为Kirin NPU的YOLOv3_MobileNetV3异构模型
- subgraph_custom_partition_config_file.txt # YOLOv3_MobileNetV3自定义子图分割配置文件
- shell # android shell端的示例程序,注意:HiAI存在限制,拥有ROOT权限才能正常运行shell端程序
- CMakeLists.txt # android shell端的示例程序CMake脚本
- build
- object_detection_demo # 已编译好的android shell端的示例程序
- object_detection_demo.cc.cc # 示例程序源码
- build.sh # android shell端的示例程序编译脚本
- run.sh # android shell端的示例程序运行脚本
- apk # 常规android应用程序,无需ROOT
```
- 运行Android shell端的示例程序
- 参考『运行图像分类示例程序』章节的类似步骤,通过以下命令比较ARM CPU模型、ARM CPU+华为Kirin NPU异构模型的性能和结果;
```shell
运行YOLOv3_MobileNetV3 ARM CPU模型
$ cd PaddleLite-android-demo/object_detection_demo/assets/models
$ cp yolov3_mobilenet_v3_prune86_FPGM_fp32_320_for_cpu/model.nb yolov3_mobilenet_v3_prune86_FPGM_fp32_320_fluid.nb
$ cd ../../shell
$ ./run.sh
...
warmup: 5 repeat: 10, average: 53.963000 ms, max: 54.161999 ms, min: 53.562000 ms
results: 24
[0] person - 0.986361 211.407288,334.633301,51.627228,133.759537
[1] person - 0.879052 261.493347,342.849823,40.597961,120.775108
...
[22] kite - 0.272905 362.982941,119.011330,14.060059,11.157372
[23] kite - 0.254866 216.051910,175.607956,70.241974,23.265827
Preprocess time: 4.882000 ms
Prediction time: 53.963000 ms
Postprocess time: 0.548000 ms
运行YOLOv3_MobileNetV3 ARM CPU+华为Kirin NPU异构模型
$ cd PaddleLite-android-demo/object_detection_demo/assets/models
$ cp yolov3_mobilenet_v3_prune86_FPGM_fp32_320_for_hybrid_cpu_huawei_kirin_npu/model.nb yolov3_mobilenet_v3_prune86_FPGM_fp32_320_fluid.nb
$ cd ../../shell
$ ./run.sh
...
warmup: 5 repeat: 10, average: 23.767200 ms, max: 25.287001 ms, min: 22.292000 ms
results: 24
[0] person - 0.986164 211.420929,334.705780,51.559906,133.627930
[1] person - 0.879287 261.553680,342.857300,40.531372,120.751106
...
[22] kite - 0.271422 362.977722,119.014709,14.053833,11.162636
[23] kite - 0.257437 216.123276,175.631500,70.095078,23.248249
Preprocess time: 4.951000 ms
Prediction time: 23.767200 ms
Postprocess time: 1.015000 ms
```
- 运行常规Android应用程序
(如果不想按照以下步骤编译Android应用程序,可以直接在Android设备上通过浏览器下载和安装已编译好的apk[object_detection_demo.apk](https://paddlelite-demo.bj.bcebos.com/devices/huawei/kirin/object_detection_demo.apk))
- 参考『运行图像分类示例程序』章节的类似步骤,通过Android Studio导入"PaddleLite-android-demo/object_detection_demo/apk"工程,生成和运行常规Android应用程序;
- 默认使用ARM CPU模型进行推理,如下图所示,推理耗时55.1ms,整个流程(含预处理和后处理)的帧率约15fps;

- 选择"yolov3_mobilenet_v3_for_hybrid_cpu_huawei_kirin_npu"后,如下图所示,推理耗时下降到26.9ms,帧率提高到28fps

### PaddleLite是如何支持华为Kirin NPU的?
- PaddleLite是如何加载Paddle模型并执行一次推理的?
- 如下图左半部分所示,Paddle模型的读取和执行,�经历了Paddle推理模型文件的加载和解析、计算图的转化、图分析和优化、运行时程序的生成和执行等步骤:
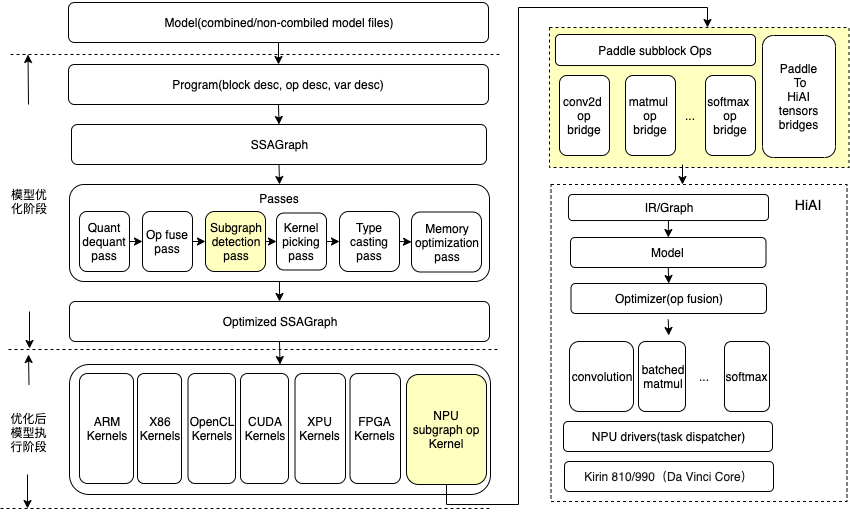
- Paddle推理模型文件的加载和解析:基于ProtoBuf协议对Paddle推理模型文件进行反序列化,解析生成网络结构(描述算子和张量的关系)和参数信息(包括算子属性和权重张量);
- 计算图的转化:为了更好的描述网络拓扑结构和方便后续的优化,依据算子的输入、出张量关系,构建一个由算子节点、张量节点组成的有向无环图;
- 图分析和优化:由一些列pass(优化器)组成,pass是用于描述一个计算图优化生成另一个计算图的过程;例如conv2d_bn_fuse_pass,它用于将模型中每一个conv2d、batch_norm相连的算子对融合成一个conv2d算子以便获得性能上的提升;
- 运行时程序的生成和执行:按照拓扑顺序遍历最终优化后的计算图,生成算子kernel列表,依次执行每一个算子kernel后即完成一次模型的推理。
- PaddleLite是如何支持华为NPU呢?
- 为了支持华为Kirin NPU,我们额外增加了(如上图标黄的区域):Subgraph detection pass、NPU subgraph op kernel和Paddle2HiAI op/tensor bridges。其中Subgraph detection pass是后续自定义子图划分涉及的关键步骤;
- Subgraph detection pass:该pass的作用是遍历计算图中所有的算子节点,标记能够转成HiAI IR的算子节点,然后通过图分割算法,将那些支持转为HiAI IR的、相邻的算子节点融合成一个subgraph(子图)算子节点(需要注意的是,这个阶段算子节点并没有真正转为HiAI IR,更没有生成HiAI模型);
- NPU subgraph op kernel:根据Subgraph detection pass的分割结果,在生成的算子kernel列表中,可能存在多个subgraph算子kernel;每个subgraph算子kernel,都会将它所包裹的、能够转成HiAI IR的、所有Paddle算子,如上图右半部所示,依次调用对应的op bridge,组网生成一个HiAI Graph,最终,调用HiAI Runtime APIs生成并执行华为Kirin NPU模型;
- Paddle2HiAI op/tensor bridges:Paddle算子/张量转HiAI IR/tensor的桥接器,其目的是将Paddle算子、输入、输出张量转为HiAI组网IR和常量张量。
### 编写配置文件完成自定义子图分割,生成华为Kirin NPU与ARM CPU的异构模型
- 为什么需要进行手动子图划分?如果模型中存在不支持转HiAI IR的算子,Subgraph detection pass会在没有人工干预的情况下,可能将计算图分割为许多小的子图,而出现如下问题:
- 过多的子图会产生频繁的CPU<->NPU数据传输和NPU任务调度,影响整体性能;
- 由于华为Kirin NPU模型暂时不支持dynamic shape,因此,如果模型中存在输入和输出不定长的算子(例如一些检测类算子,NLP类算子),在模型推理过程中,可能会因输入、输出shape变化而不断生成HiAI模型,从而导致性能变差,更有可能使得HiAI模型生成失败。
- 实现原理
- Subgraph detection pass在执行分割任务前,通过读取指定配置文件的方式获得禁用华为Kirin NPU的算子列表,实现人为干预分割结果的目的。
- 具体步骤(以YOLOv3_MobileNetV3目标检测示例程序为例)
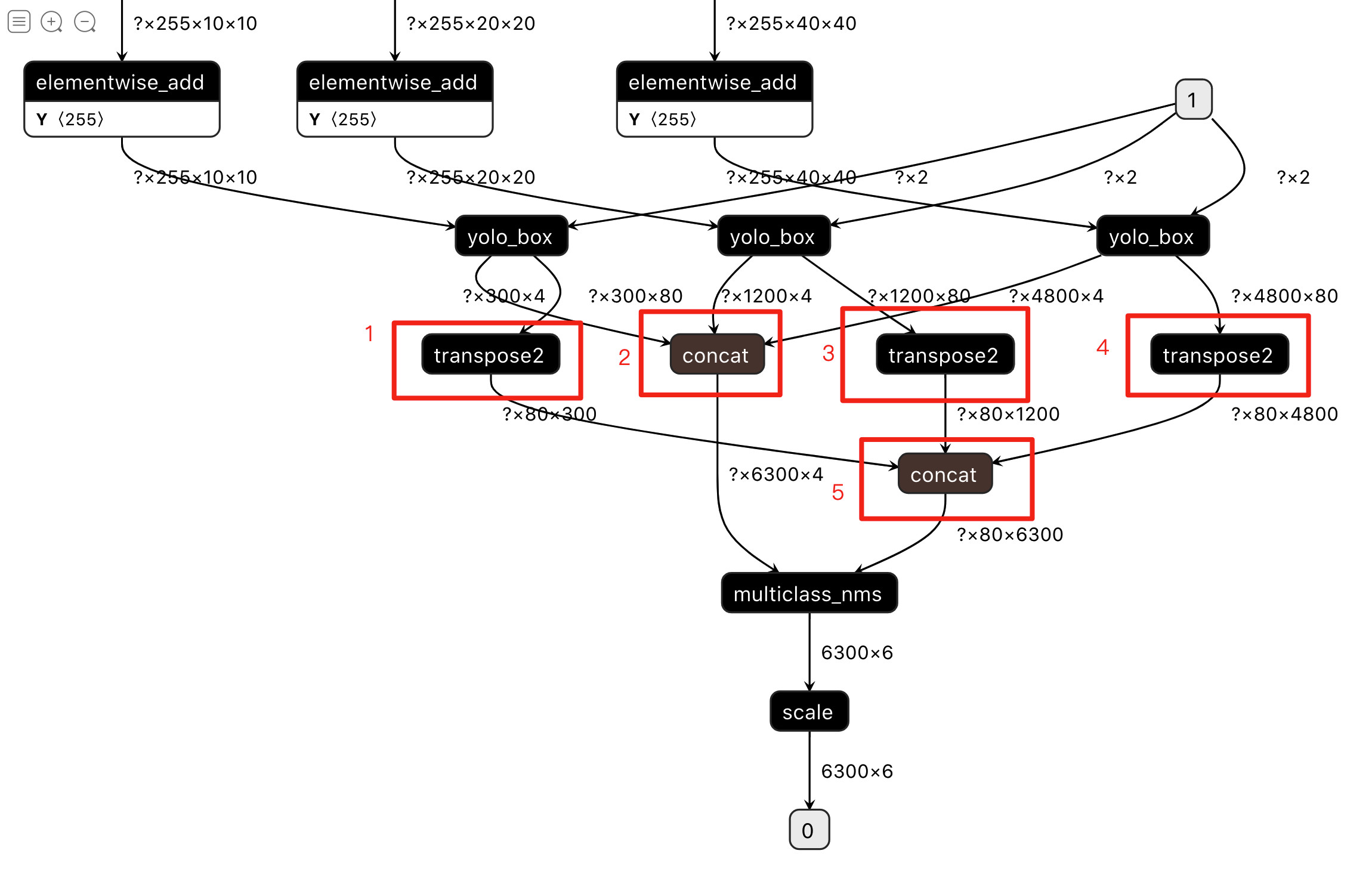
- 步骤1:查看[YOLOv3_MobileNetV3](https://paddlelite-demo.bj.bcebos.com/models/yolov3_mobilenet_v3_prune86_FPGM_320_fp32_fluid.tar.gz)的模型结构,具体是将PaddleLite-android-demo/object_detection_demo/assets/models/yolov3_mobilenet_v3_prune86_FPGM_fp32_320_fluid目录下的model复制并重名为__model__后,拖入[Netron页面](https://lutzroeder.github.io/netron/)即得到如下图所示的网络结构(部分):
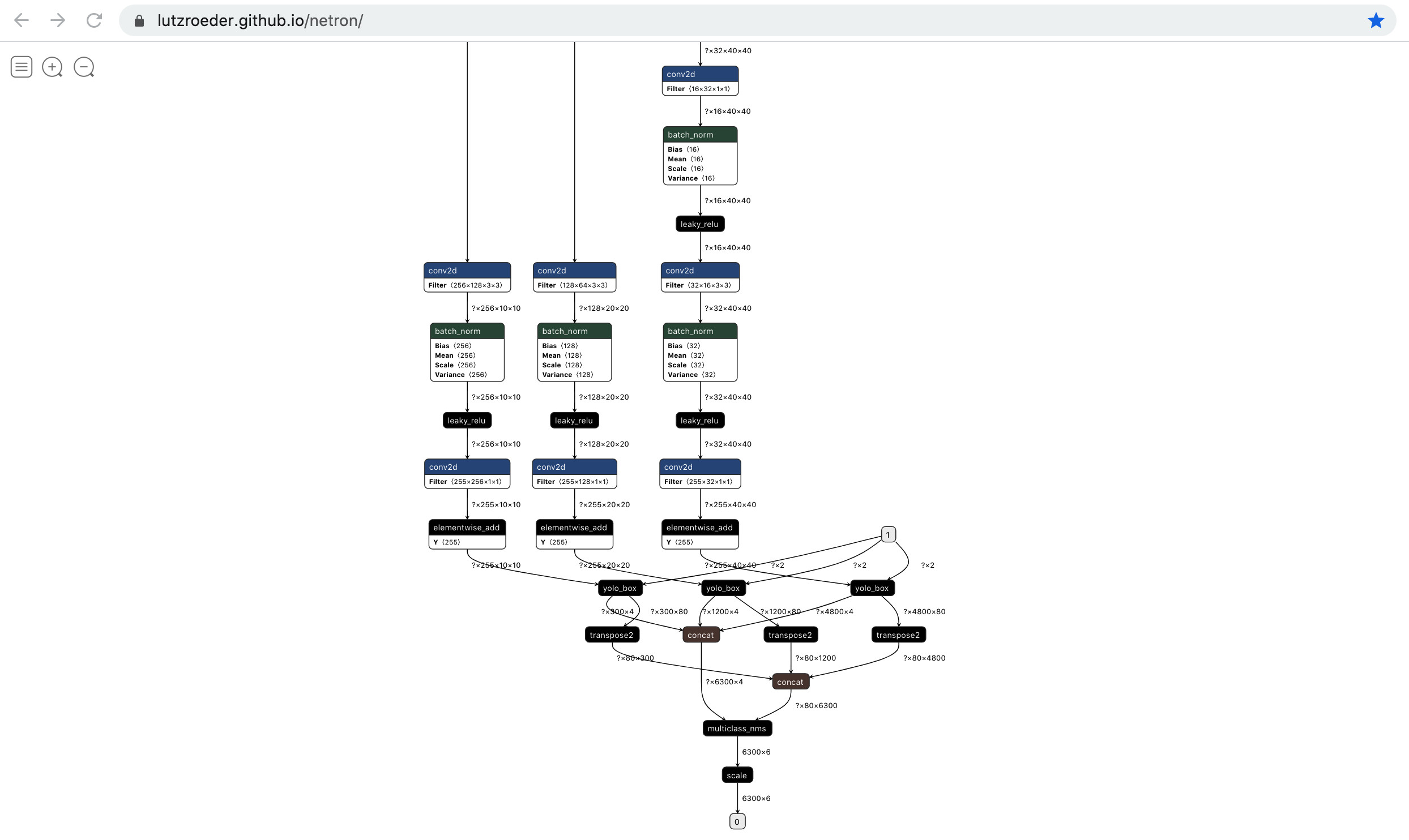
- 步骤2:访问[https://github.com/PaddlePaddle/Paddle-Lite/blob/develop/lite/kernels/npu/bridges/paddle_use_bridges.h](https://github.com/PaddlePaddle/Paddle-Lite/blob/develop/lite/kernels/npu/bridges/paddle_use_bridges.h)查看已支持的算子列表,发现华为Kirin NPU不支持yolo_box、multiclass_nms这两个算子;
- 步骤3:如果直接使用opt工具生成华为Kirin NPU模型,会发现整个网络被分割成3个子图(即3个subgraph op),subgraph1为MobileNetV3 backbone,subgraph2为1个transpose2和1个concat,subgraph3为2个transpose2和1个concat,它们都将运行在华为Kirin NPU上;
```shell
$ cd PaddleLite-android-demo/object_detection_demo/assets/models
$ GLOG_v=5 ./opt --model_file=yolov3_mobilenet_v3_prune86_FPGM_fp32_320_fluid/model \
--param_file=yolov3_mobilenet_v3_prune86_FPGM_fp32_320_fluid/params \
--optimize_out_type=protobuf \
--optimize_out=opt_model \
--valid_targets=npu,arm
...
[4 8/12 14:12:50.559 ...e/Paddle-Lite/lite/core/mir/ssa_graph.cc:27 CheckBidirectionalConnection] node count 398
[4 8/12 14:12:50.560 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement feed host/any/any
[4 8/12 14:12:50.560 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement feed host/any/any
[4 8/12 14:12:50.560 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement subgraph npu/any/NCHW
[4 8/12 14:12:50.560 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement yolo_box arm/float/NCHW
[4 8/12 14:12:50.561 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement yolo_box arm/float/NCHW
[4 8/12 14:12:50.561 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement yolo_box arm/float/NCHW
[4 8/12 14:12:50.561 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement subgraph npu/any/NCHW
[4 8/12 14:12:50.561 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement subgraph npu/any/NCHW
[4 8/12 14:12:50.561 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement multiclass_nms host/float/NCHW
[4 8/12 14:12:50.561 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement fetch host/any/any
[I 8/12 14:12:50.561 ...te/lite/core/mir/generate_program_pass.h:37 GenProgram] insts.size 1
[4 8/12 14:12:50.836 ...e-Lite/lite/model_parser/model_parser.cc:308 SaveModelPb] Save protobuf model in 'opt_model' successfully
注意:为了方便查看优化后的模型,上述命令将`optimize_out_type`参数设置为protobuf,执行成功后将opt_model目录下的model文件复制为__model__并拖入Netron页面进行可视化。
```
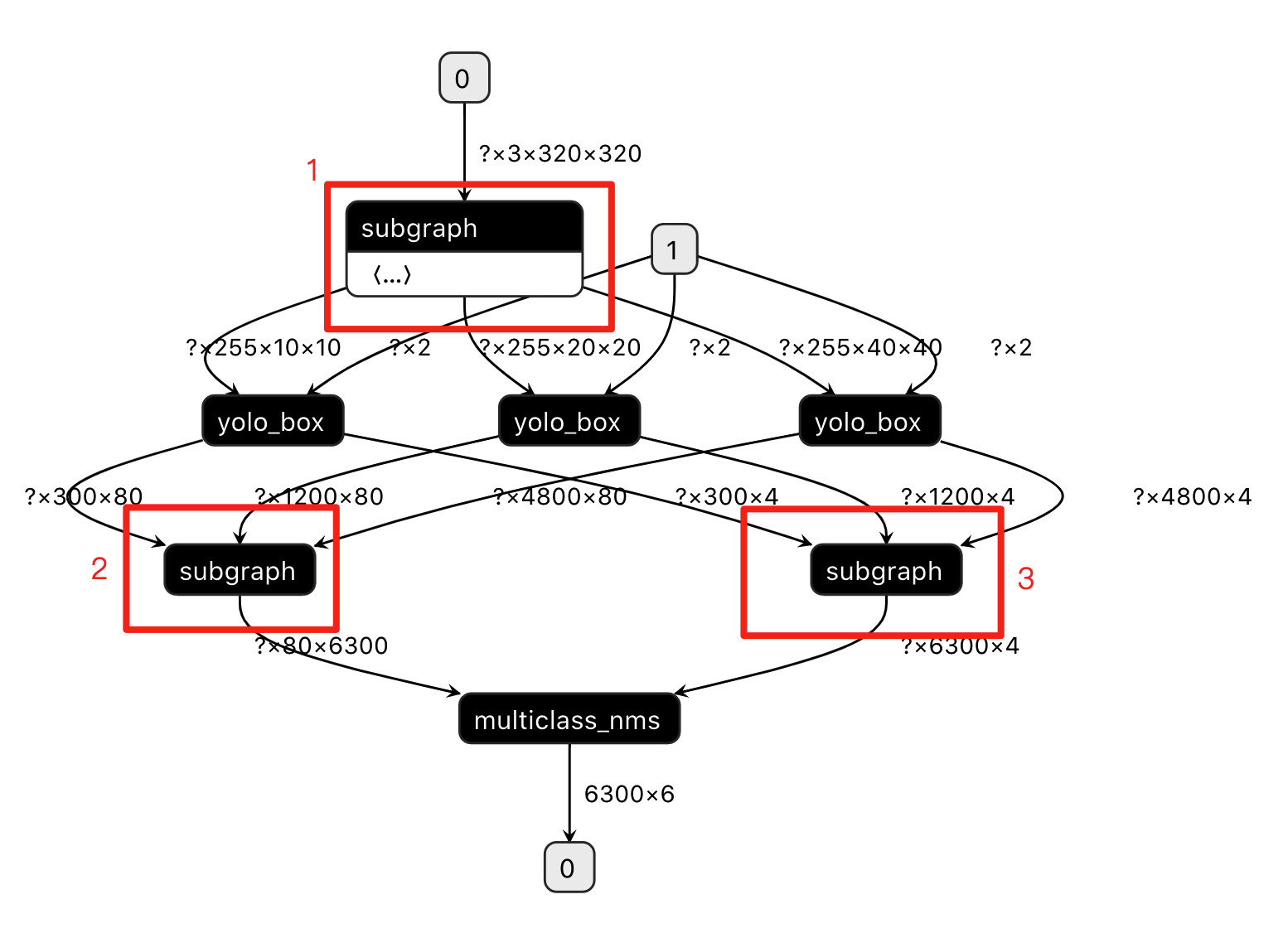
- 步骤4:为了防止ARM CPU与华为Kirin NPU频繁切换,去除subgraph2和subgraph3,强制让transpose2和concat运行在ARM CPU上。那么,我们就需要通过环境变量SUBGRAPH_CUSTOM_PARTITION_CONFIG_FILE设置『自定义子图分割配置文件』,实现人为干预分割结果;
```shell
$ cd PaddleLite-android-demo/object_detection_demo/assets/models
$ cat ./subgraph_custom_partition_config_file.txt
transpose2:yolo_box0.tmp_1:transpose_0.tmp_0,transpose_0.tmp_1
transpose2:yolo_box1.tmp_1:transpose_1.tmp_0,transpose_1.tmp_1
transpose2:yolo_box2.tmp_1:transpose_2.tmp_0,transpose_2.tmp_1
concat:yolo_box0.tmp_0,yolo_box1.tmp_0,yolo_box2.tmp_0:concat_2.tmp_0
concat:transpose_0.tmp_0,transpose_1.tmp_0,transpose_2.tmp_0:concat_3.tmp_0
$ export SUBGRAPH_CUSTOM_PARTITION_CONFIG_FILE=./subgraph_custom_partition_config_file.txt
$ GLOG_v=5 ./opt --model_file=yolov3_mobilenet_v3_prune86_FPGM_fp32_320_fluid/model \
--param_file=yolov3_mobilenet_v3_prune86_FPGM_fp32_320_fluid/params \
--optimize_out_type=protobuf \
--optimize_out=opt_model \
--valid_targets=npu,arm
...
[4 8/12 14:15:37.609 ...e/Paddle-Lite/lite/core/mir/ssa_graph.cc:27 CheckBidirectionalConnection] node count 401
[4 8/12 14:15:37.610 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement feed host/any/any
[4 8/12 14:15:37.610 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement feed host/any/any
[4 8/12 14:15:37.610 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement subgraph npu/any/NCHW
[4 8/12 14:15:37.610 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement yolo_box arm/float/NCHW
[4 8/12 14:15:37.610 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement transpose2 arm/float/NCHW
[4 8/12 14:15:37.610 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement yolo_box arm/float/NCHW
[4 8/12 14:15:37.610 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement transpose2 arm/float/NCHW
[4 8/12 14:15:37.611 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement yolo_box arm/float/NCHW
[4 8/12 14:15:37.611 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement transpose2 arm/float/NCHW
[4 8/12 14:15:37.611 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement concat arm/any/NCHW
[4 8/12 14:15:37.611 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement concat arm/any/NCHW
[4 8/12 14:15:37.611 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement multiclass_nms host/float/NCHW
[4 8/12 14:15:37.611 ...e/lite/core/mir/generate_program_pass.cc:46 Apply] Statement fetch host/any/any
[I 8/12 14:15:37.611 ...te/lite/core/mir/generate_program_pass.h:37 GenProgram] insts.size 1
[4 8/12 14:15:37.998 ...e-Lite/lite/model_parser/model_parser.cc:308 SaveModelPb] Save protobuf model in 'opt_model'' successfully
```
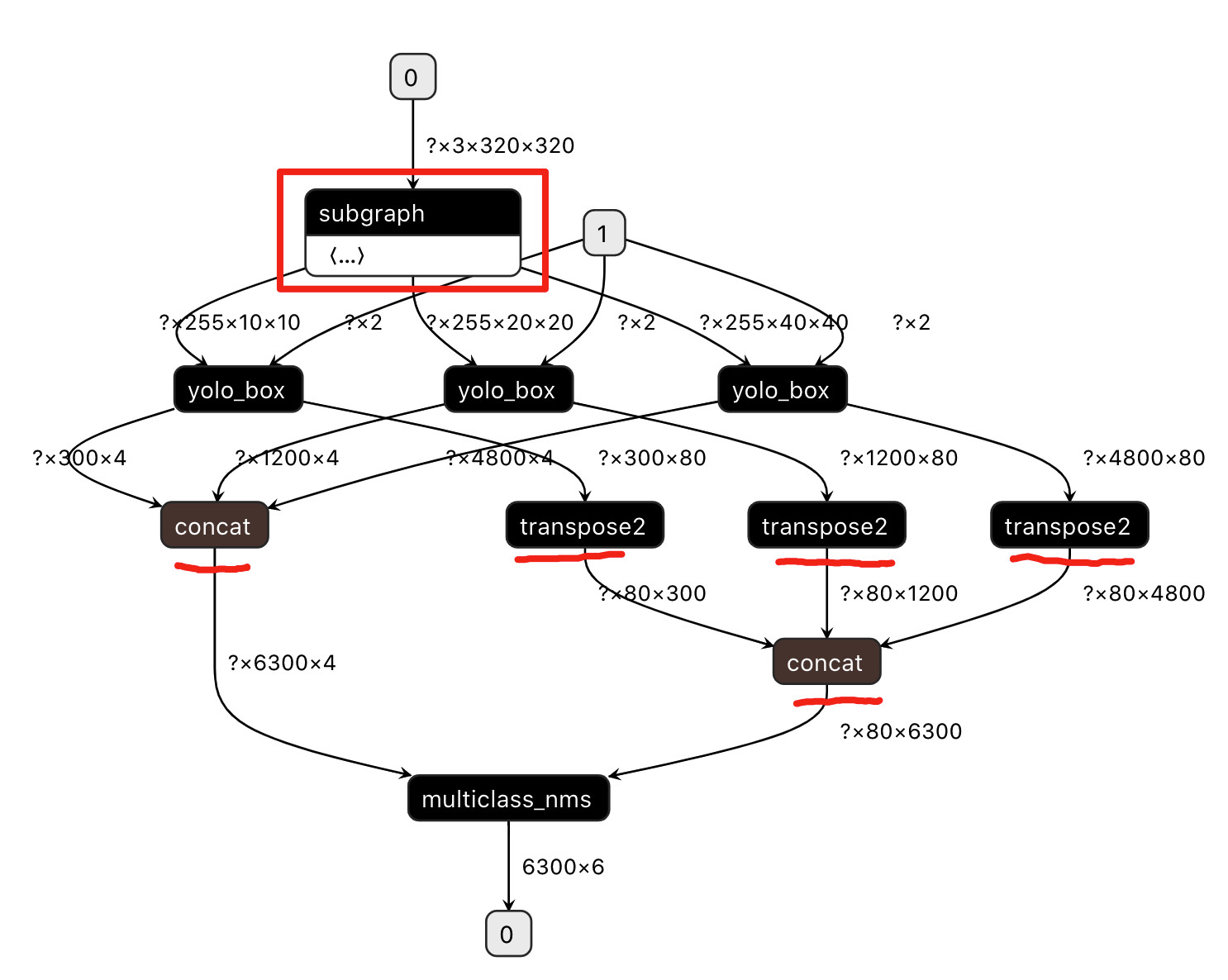
- 步骤5:上述步骤中,PaddleLite-android-demo/object_detection_demo/assets/models/subgraph_custom_partition_config_file.txt是示例自带的『自定义子图分割配置文件』,它的格式是什么样的呢?
- 每行记录由『算子类型:输入张量名列表:输出张量名列表』组成(即以分号分隔算子类型、输入和输出张量名列表),以逗号分隔输入、输出张量名列表中的每个张量名;
- 可省略输入、输出张量名列表中的部分张量名(如果不设置任何输入、输出张量列表,则代表计算图中该类型的所有算子节点均被强制运行在ARM CPU上);
- 示例说明:
```
op_type0:var_name0,var_name1:var_name2 表示将算子类型为op_type0、输入张量为var_name0和var_name1、输出张量为var_name2的节点强制运行在ARM CPU上
op_type1::var_name3 表示将算子类型为op_type1、任意输入张量、输出张量为var_name3的节点强制运行在ARM CPU上
op_type2:var_name4 表示将算子类型为op_type2、输入张量为var_name4、任意输出张量的节点强制运行在ARM CPU上
op_type3 表示任意算子类型为op_type3的节点均被强制运行在ARM CPU上
```
- 步骤6:对于YOLOv3_MobileNetV3的模型,我们如何得到PaddleLite-android-demo/object_detection_demo/assets/models/subgraph_custom_partition_config_file.txt的配置呢?
- 重新在Netron打开PaddleLite-android-demo/object_detection_demo/assets/models/yolov3_mobilenet_v3_prune86_FPGM_fp32_320_fluid模型,如下图所示,1~5号节点需要强制放在ARM CPU上运行。
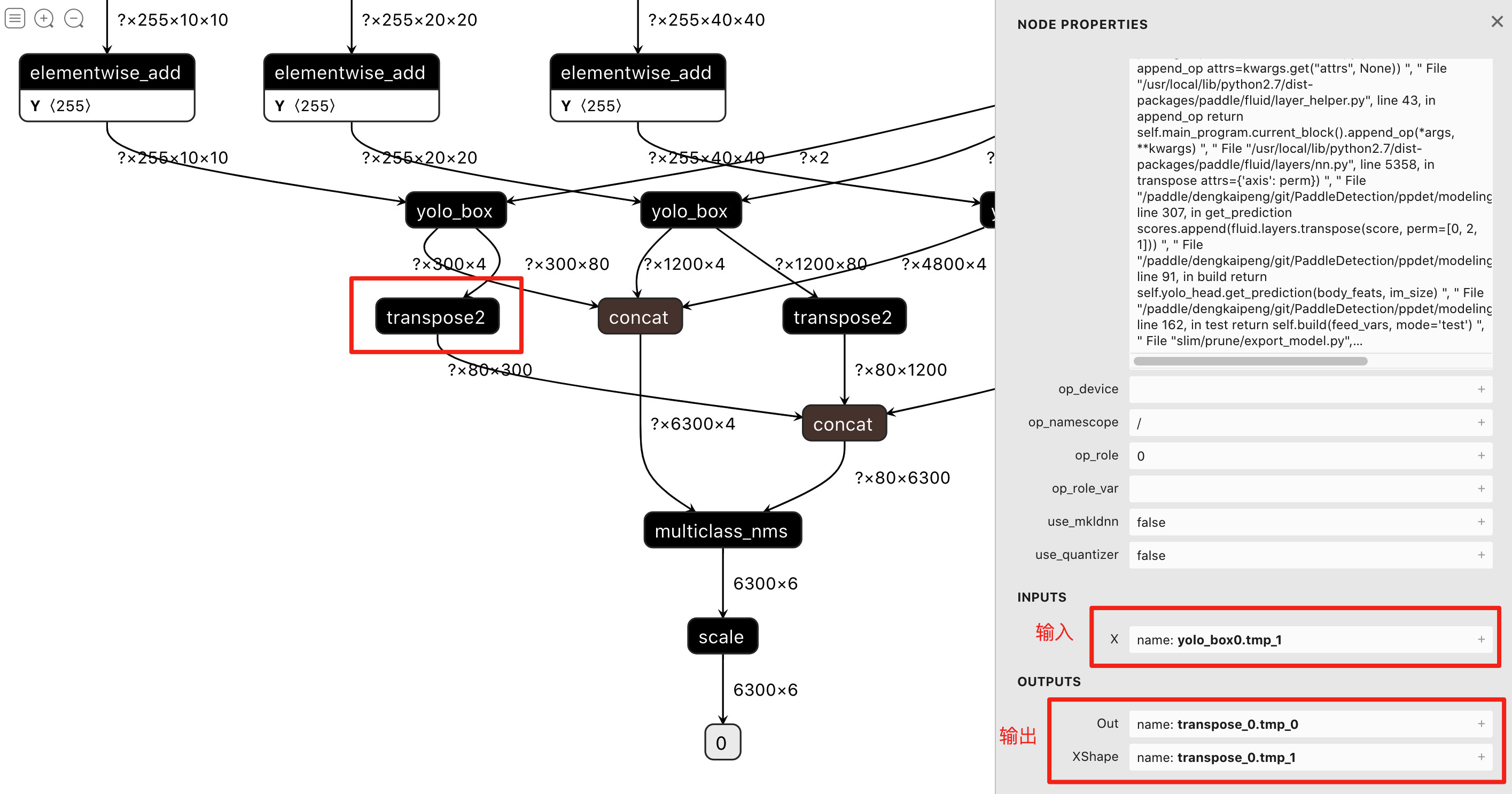
- 在Netron中依次点击1~5号节点,右侧将显示每个节点的输入、输出张量名称,如下图所示,1号节点为transpose2类型算子,它的输入为yolo_box0.tmp1、输出为transpose_0.tmp_0,transpose_0.tmp_1,即可得到配置文件的第一条记录"transpose2:yolo_box0.tmp_1:transpose_0.tmp_0,transpose_0.tmp_1";
- 步骤7:将步骤4中的"optimize_out_type"修改为naive_buffer,重新执行步骤4即可以生成用于部署的ARM CPU+华为Kirin NPU异构模型。
## 其它说明
- 华为达芬奇架构的NPU内部大量采用float16进行运算,因此,预测结果会存在偏差,但大部分情况下精度不会有较大损失,可参考[Paddle-Lite-Demo](https://github.com/PaddlePaddle/Paddle-Lite-Demo)中Image Classification Demo for Android对同一张图片CPU与华为Kirin NPU的预测结果。
- 华为Kirin 810/990 Soc搭载的自研达芬奇架构的NPU,与Kirin 970/980 Soc搭载的寒武纪NPU不一样,同样的,与Hi3559A、Hi3519A使用的NNIE也不一样,Paddle Lite只支持华为自研达芬奇架构NPU。
- 我们正在持续增加能够适配HiAI IR的Paddle算子bridge/converter,以便适配更多Paddle模型,同时华为研发同学也在持续对HiAI IR性能进行优化。
