
使用流程¶
一: 模型准备¶
Paddle Inference目前支持的模型结构为PaddlePaddle深度学习框架产出的模型格式。因此,在您开始使用 Paddle Inference框架前您需要准备一个由PaddlePaddle框架保存的模型。 如果您手中的模型是由诸如Caffe2、Tensorflow等框架产出的,那么我们推荐您使用 X2Paddle 工具进行模型格式转换。
二: 环境准备¶
1) Python 环境
安装Python环境有以下三种方式:
# 拉取镜像,该镜像预装Paddle 1.8 Python环境
docker pull hub.baidubce.com/paddlepaddle/paddle:1.8.0-gpu-cuda10.0-cudnn7-trt6
export CUDA_SO="$(\ls /usr/lib64/libcuda* | xargs -I{} echo '-v {}:{}') $(\ls /usr/lib64/libnvidia* | xargs -I{} echo '-v {}:{}')"
export DEVICES=$(\ls /dev/nvidia* | xargs -I{} echo '--device {}:{}')
export NVIDIA_SMI="-v /usr/bin/nvidia-smi:/usr/bin/nvidia-smi"
docker run $CUDA_SO $DEVICES $NVIDIA_SMI --name trt_open --privileged --security-opt seccomp=unconfined --net=host -v $PWD:/paddle -it hub.baidubce.com/paddlepaddle/paddle:1.8.0-gpu-cuda10.0-cudnn7-trt6 /bin/bash
2) C++ 环境
获取c++预测库有以下三种方式:
官网 下载预编译库
使用docker镜像
# 拉取镜像,在容器内主目录~/下存放c++预编译库。
docker pull hub.baidubce.com/paddlepaddle/paddle:1.8.0-gpu-cuda10.0-cudnn7-trt6
export CUDA_SO="$(\ls /usr/lib64/libcuda* | xargs -I{} echo '-v {}:{}') $(\ls /usr/lib64/libnvidia* | xargs -I{} echo '-v {}:{}')"
export DEVICES=$(\ls /dev/nvidia* | xargs -I{} echo '--device {}:{}')
export NVIDIA_SMI="-v /usr/bin/nvidia-smi:/usr/bin/nvidia-smi"
docker run $CUDA_SO $DEVICES $NVIDIA_SMI --name trt_open --privileged --security-opt seccomp=unconfined --net=host -v $PWD:/paddle -it hub.baidubce.com/paddlepaddle/paddle:1.8.0-gpu-cuda10.0-cudnn7-trt6 /bin/bash
参照接下来的 `预测库编译 <./source_compile.html>`_页面进行自行编译。
三:使用Paddle Inference执行预测¶
使用Paddle Inference进行推理部署的流程如下所示。
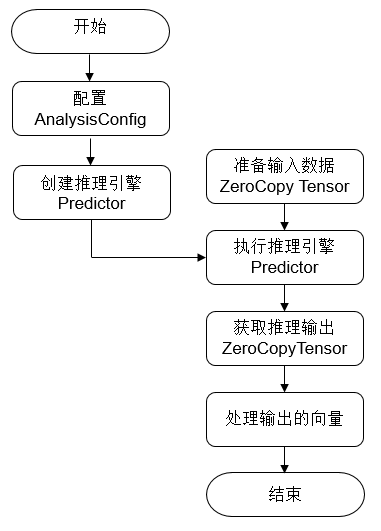
配置推理选项。 AnalysisConfig 是飞桨提供的配置管理器API。在使用Paddle Inference进行推理部署过程中,需要使用 AnalysisConfig 详细地配置推理引擎参数,包括但不限于在何种设备(CPU/GPU)上部署( config.EnableUseGPU )、加载模型路径、开启/关闭计算图分析优化、使用MKLDNN/TensorRT进行部署的加速等。参数的具体设置需要根据实际需求来定。
创建 AnalysisPredictor 。 AnalysisPredictor 是Paddle Inference提供的推理引擎。你只需要简单的执行一行代码即可完成预测引擎的初始化 std::unique_ptr<PaddlePredictor> predictor = CreatePaddlePredictor(config) ,config为1步骤中创建的 AnalysisConfig。
准备输入数据。执行 auto input_names = predictor->GetInputNames() ,您会获取到模型所有输入tensor的名字,同时通过执行 auto tensor = predictor->GetInputTensor(input_names[i]) ; 您可以获取第i个输入的tensor,通过 tensor->copy_from_cpu(data) 方式,将data中的数据拷贝到tensor中。
调用predictor->ZeroCopyRun()执行推理。
获取推理输出。执行 auto out_names = predictor->GetOutputNames() ,您会获取到模型所有输出tensor的名字,同时通过执行 auto tensor = predictor->GetOutputTensor(out_names[i]) ; 您可以获取第i个输出的tensor。通过 tensor->copy_to_cpu(data) 将tensor中的数据copy到data指针上