Loading [Contrib]/a11y/accessibility-menu.js
\u200E
预测流程
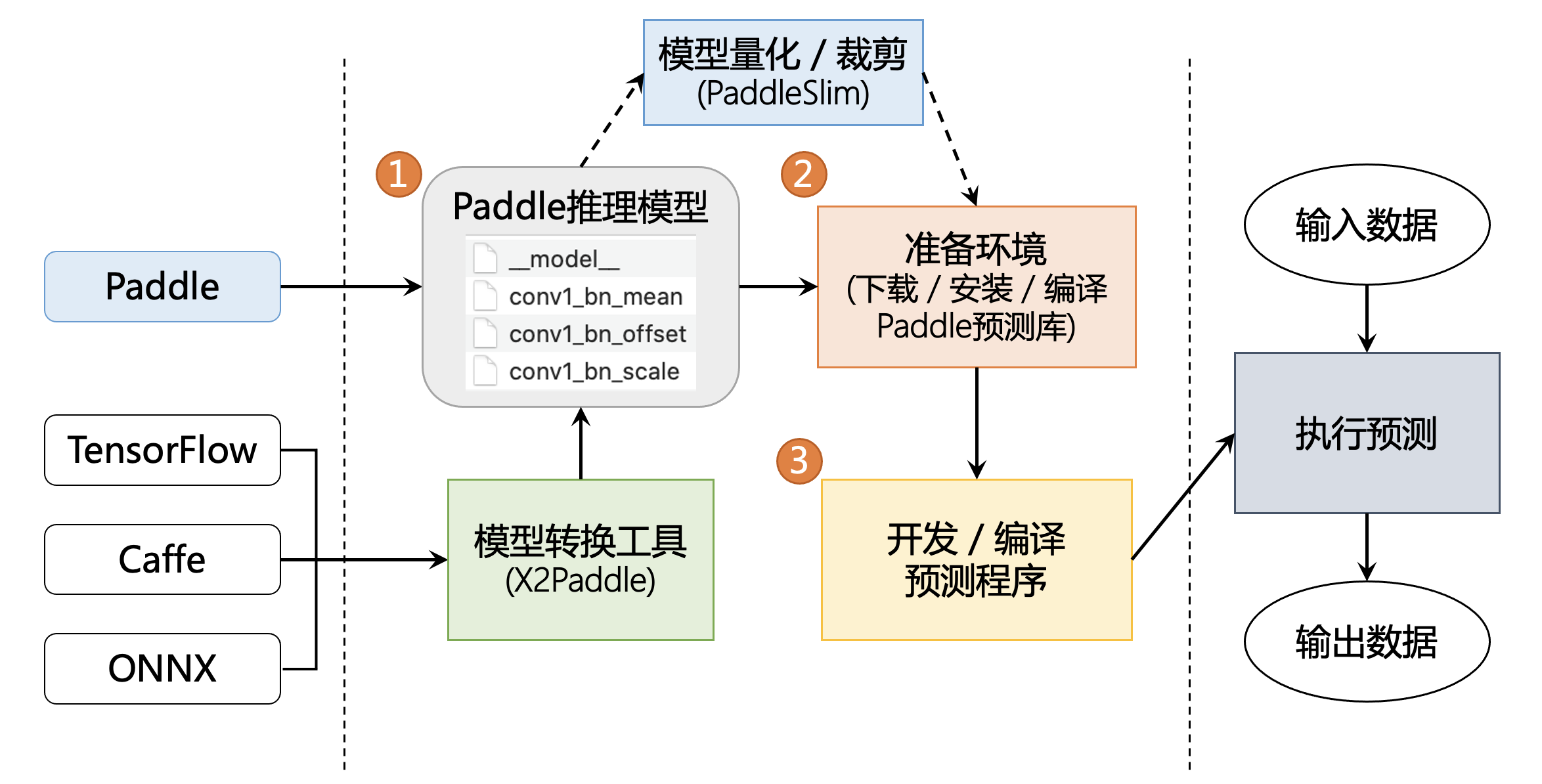
一. 准备模型
Paddle Inference 原生支持由 PaddlePaddle 深度学习框架训练产出的推理模型。新版本 PaddlePaddle 用于推理的模型分别通过 paddle.jit.save (动态图) 与 paddle.static.save_inference_model (静态图) 或 paddle.Model().save (高层API) 保存下来;老版本的 PaddlePaddle 用于推理的模型通过 fluid.io.save_inference_model 这个API保存下来。更详细的说明请参考这里。
如果您手中的模型是由诸如 Caffe、Tensorflow、PyTorch 等框架产出的,那么您可以使用 X2Paddle 工具将模型转换为 PadddlePaddle 格式。
二. 准备环境
1) Python 环境
请参照 官方主页-快速安装 页面进行自行安装或编译,当前支持 pip/conda 安装,docker镜像 以及源码编译等多种方式来准备 Paddle Inference 开发环境。
2) C++ 环境
Paddle Inference 提供了 Ubuntu/Windows/MacOS 平台的官方Release预测库下载,如果您使用的是以上平台,我们优先推荐您通过以下链接直接下载,或者您也可以参照文档进行源码编译。
三. 开发预测程序
Paddle Inference采用 Predictor 进行预测。Predictor 是一个高性能预测引擎,该引擎通过对计算图的分析,完成对计算图的一系列的优化(如OP的融合、内存/显存的优化、 MKLDNN,TensorRT 等底层加速库的支持等),能够大大提升预测性能。
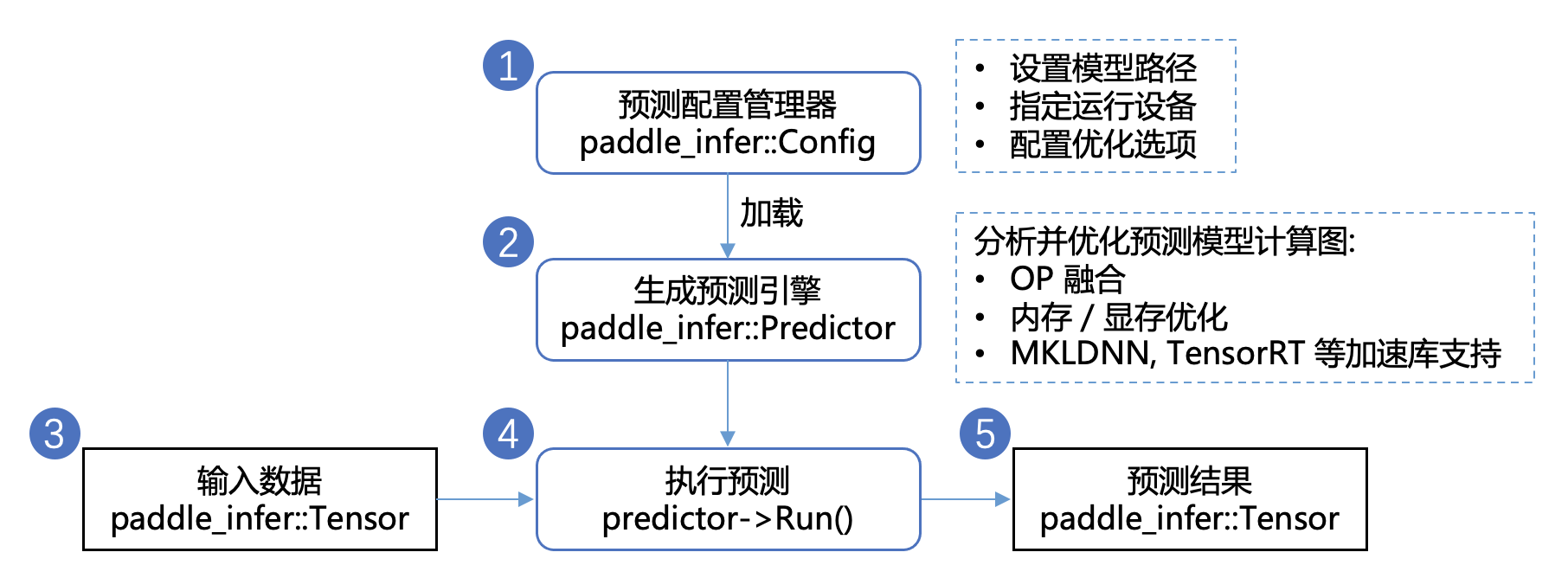
开发预测程序只需要简单的5个步骤 (这里以C++ API为例):
配置推理选项 paddle_infer::Config,包括设置模型路径、运行设备、开启/关闭计算图优化、使用MKLDNN/TensorRT进行部署的加速等。
创建推理引擎 paddle_infer::Predictor,通过调用 CreatePredictor(Config) 接口,一行代码即可完成引擎初始化,其中 Config 为第1步中生成的配置推理选项。
准备输入数据,需要以下几个步骤
先通过 auto input_names = predictor->GetInputNames() 获取模型所有输入 Tensor 的名称
再通过 auto tensor = predictor->GetInputTensor(input_names[i]) 获取输入 Tensor 的指针
最后通过 tensor->copy_from_cpu(data),将 data 中的数据拷贝到 tensor 中
执行预测,只需要运行predictor->Run()一行代码,即可完成预测执行
获得预测结果,需要以下几个步骤
先通过 auto out_names = predictor->GetOutputNames() 获取模型所有输出 Tensor 的名称
再通过 auto tensor = predictor->GetOutputTensor(out_names[i]) 获取输出 Tensor的 指针
最后通过 tensor->copy_to_cpu(data),将 tensor 中的数据 copy 到 data 指针上
Paddle Inference 提供了C, C++, Python, Golang 四种API的使用示例和开发说明文档,您可以参考示例中的说明快速了解使用方法,并集成到您自己的项目中去。
文档反馈
预测流程 — Paddle-Inference documentation
预测流程
一. 准备模型
Paddle Inference 原生支持由 PaddlePaddle 深度学习框架训练产出的推理模型。新版本 PaddlePaddle 用于推理的模型分别通过 paddle.jit.save (动态图) 与 paddle.static.save_inference_model (静态图) 或 paddle.Model().save (高层API) 保存下来;老版本的 PaddlePaddle 用于推理的模型通过 fluid.io.save_inference_model 这个API保存下来。更详细的说明请参考这里。
如果您手中的模型是由诸如 Caffe、Tensorflow、PyTorch 等框架产出的,那么您可以使用 X2Paddle 工具将模型转换为 PadddlePaddle 格式。
二. 准备环境
1) Python 环境
请参照 官方主页-快速安装 页面进行自行安装或编译,当前支持 pip/conda 安装,docker镜像 以及源码编译等多种方式来准备 Paddle Inference 开发环境。
2) C++ 环境
Paddle Inference 提供了 Ubuntu/Windows/MacOS 平台的官方Release预测库下载,如果您使用的是以上平台,我们优先推荐您通过以下链接直接下载,或者您也可以参照文档进行源码编译。
三. 开发预测程序
Paddle Inference采用 Predictor 进行预测。Predictor 是一个高性能预测引擎,该引擎通过对计算图的分析,完成对计算图的一系列的优化(如OP的融合、内存/显存的优化、 MKLDNN,TensorRT 等底层加速库的支持等),能够大大提升预测性能。
开发预测程序只需要简单的5个步骤 (这里以C++ API为例):
配置推理选项 paddle_infer::Config,包括设置模型路径、运行设备、开启/关闭计算图优化、使用MKLDNN/TensorRT进行部署的加速等。
创建推理引擎 paddle_infer::Predictor,通过调用 CreatePredictor(Config) 接口,一行代码即可完成引擎初始化,其中 Config 为第1步中生成的配置推理选项。
准备输入数据,需要以下几个步骤
先通过 auto input_names = predictor->GetInputNames() 获取模型所有输入 Tensor 的名称
再通过 auto tensor = predictor->GetInputTensor(input_names[i]) 获取输入 Tensor 的指针
最后通过 tensor->copy_from_cpu(data),将 data 中的数据拷贝到 tensor 中
执行预测,只需要运行predictor->Run()一行代码,即可完成预测执行
获得预测结果,需要以下几个步骤
先通过 auto out_names = predictor->GetOutputNames() 获取模型所有输出 Tensor 的名称
再通过 auto tensor = predictor->GetOutputTensor(out_names[i]) 获取输出 Tensor的 指针
最后通过 tensor->copy_to_cpu(data),将 tensor 中的数据 copy 到 data 指针上
Paddle Inference 提供了C, C++, Python, Golang 四种API的使用示例和开发说明文档,您可以参考示例中的说明快速了解使用方法,并集成到您自己的项目中去。
