

$ hub install word2vec_skipgram==1.1.0
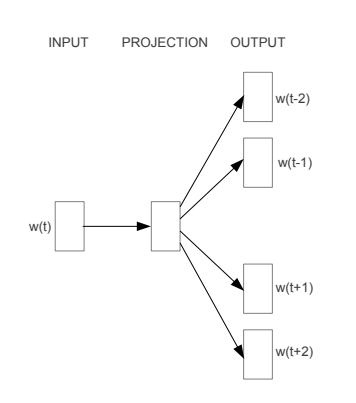
SKipGram模型框架图
更多详情请参考论文
获取该Module的预训练program以及program相应的输入输出。
参数
返回
代码示例
import paddlehub as hub
# Load word2vec pretrained model
module = hub.Module(name="word2vec_skipgram")
inputs, outputs, program = module.context(trainable=True)
# Must feed all the tensor of module need
word_ids = inputs["text"]
# Use the pretrained word embeddings
embedding = outputs["emb"]paddlepaddle >= 1.8.0
paddlehub >= 1.8.0
1.0.0
初始发布
1.1.0
模型升级,支持用于文本分类,文本匹配等各种任务迁移学习