
split
- paddle.distributed. split ( x: Tensor, size: Size2, operation: Literal['linear', 'embedding'], axis: int = 0, num_partitions: int = 1, gather_out: bool = True, weight_attr: ParamAttrLike | None = None, bias_attr: ParamAttrLike | None = None, name: str | None = None ) Tensor [source]
-
Split the weight of the specified operation into multiple devices and do the computation in parallel.
Now the following three cases are supported.
- Case 1: Parallel Embedding
-
The weight of the embedding operation is a NxM matrix with N rows and M columns. With parallel embedding, the weight is split into num_partitions partitions, each of which is a matrix with (N/num_partitions + 1) rows and M column where the last row as the padding idx.
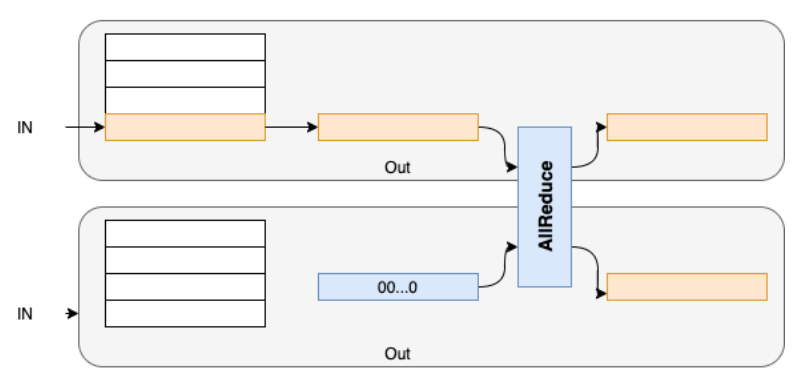
Suppose we split the NxM weight into two partitions on device_0 and device_1 respectively. Then, one each device, the final weight has (N/2 + 1) rows with the index range from 0 to N/2. On device_0, all values in the input within [0, N/2 -1] keep unchanged and all other values are changed to N/2 which is the padding index and are mapped to all zeros after embedding. In the same way, on device_1, the value V in the input within [N/2, N-1] will be changed to (V - N/2), and all other values are changed to N/2 and are mapped to all zeros after embedding. Finally, the results on the two devices are sum-reduced.
The Embedding put on single card is as shown below:

Parallel Embedding is shown as below:
- Case 2: Row Parallel Linear
-
The weight of the linear operation is a NxM matrix with N rows and M columns. With row parallel linear, the weight is split into num_partitions partitions, each of which is a matrix with N/num_partitions rows and M column.
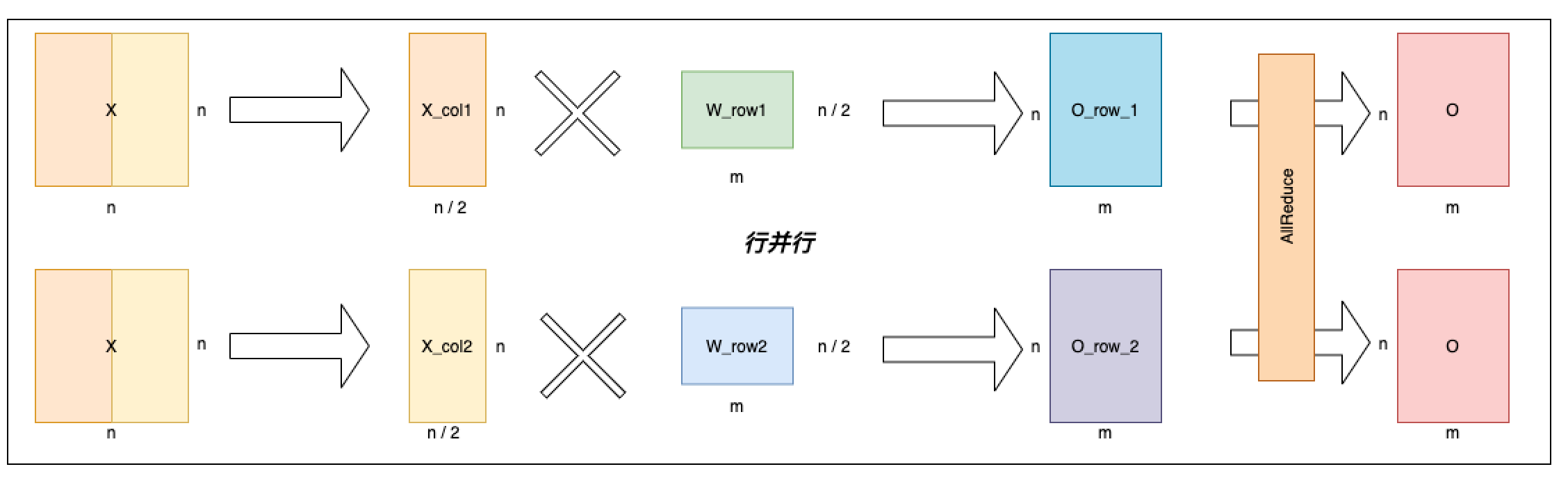
The linear layer put on single card is shown as below, the input variable is represented by X, the weight matrix is represented by W and the output variable is O. The linear layer on single card is simple matrix multiplication operation, O = X * W.

Row Parallel Linear is shown as below. As the name suggests, Row Parallel Linear splits the weight matrix W into [[W_row1], [W_row2]] along the row. And accordingly the input is split along the column into [X_col1, X_col2] and multiply their respective weight matrices. Finally apply AllReduce on the output from each card to get the final output.
- Case 3: Column Parallel Linear
-
The weight of the linear operation is a NxM matrix with N rows and M columns. With column parallel linear, the weight is split into num_partitions partitions, each of which is a matrix with N rows and M/num_partitions column.
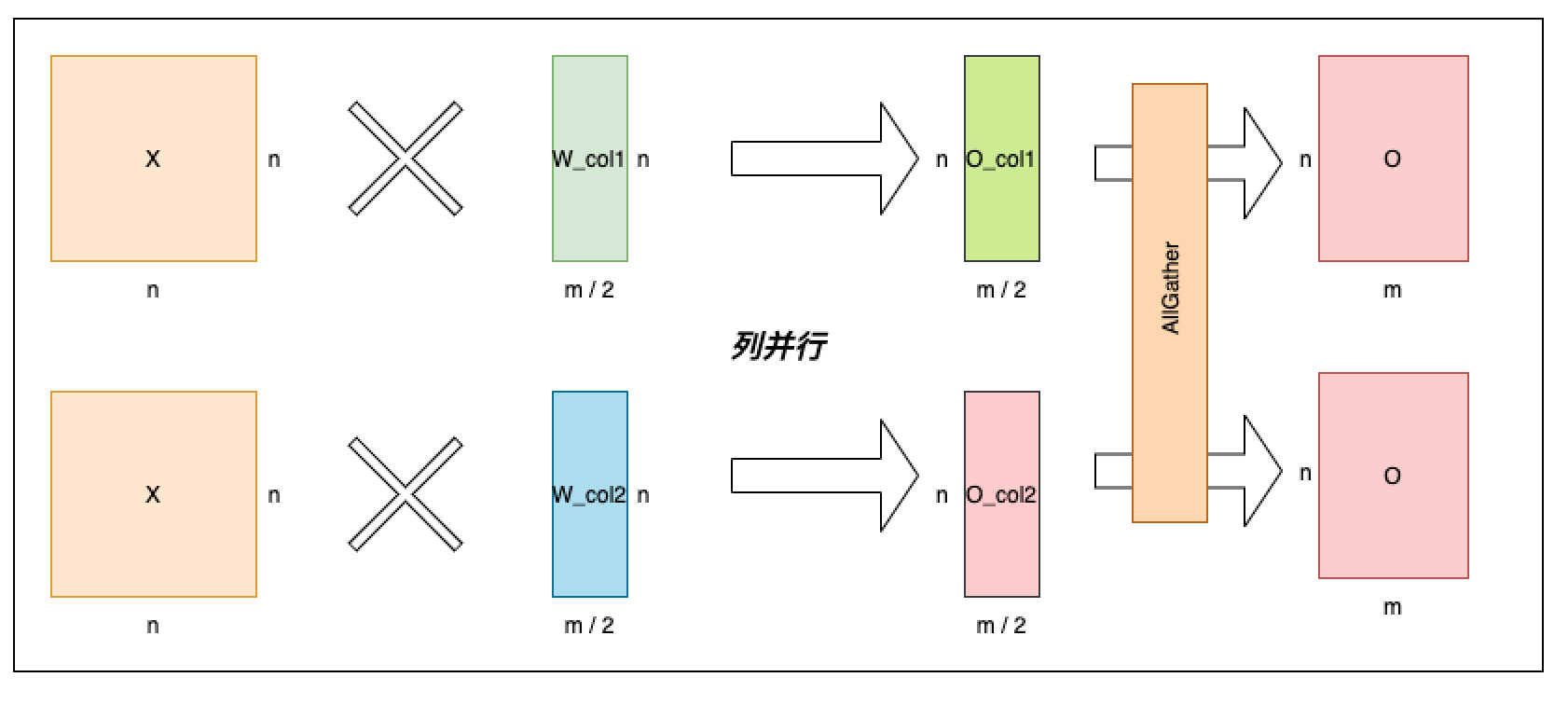
The linear layer put on single card has been illustrated on case 2 and Column Parallel Linear is shown as below. The Column Parallel Linear splits the weight matrix W into [W_col1, W_col2] along the column and these split matrices respectively multiply the input. Finally apply AllGather on the output from each card to get the final output.
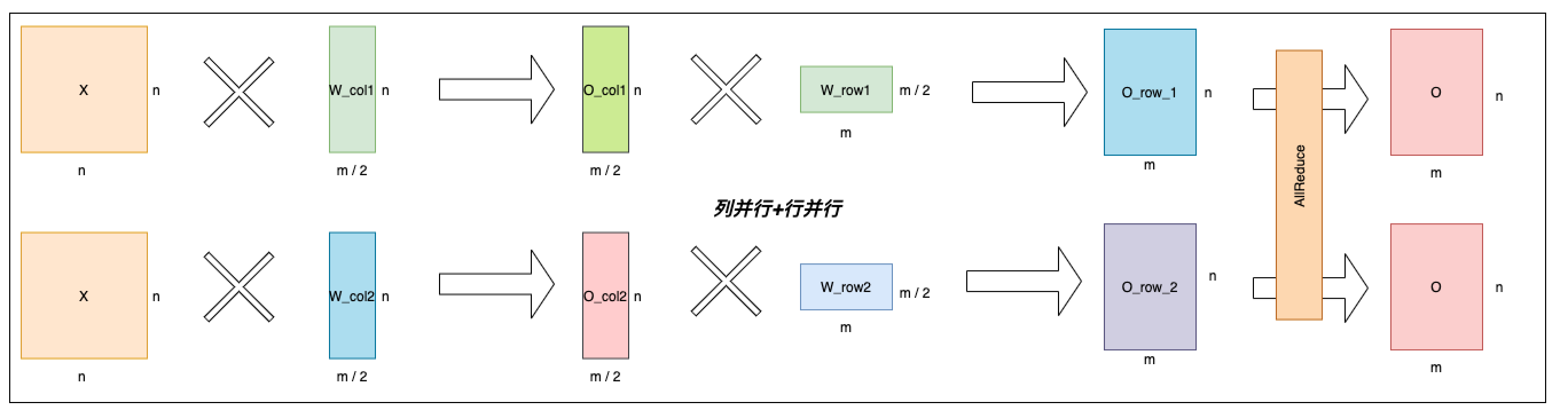
As observed, the column parallel linear and row parallel linear can be combined to skip one ALLGATHER communication operator. Furthermore the Attention and MLP can be combined to improve the performance as shown below.
- Parameters
-
x (Tensor) – Input tensor. It’s data type should be float16, float32, float64, int32 or int64.
size (list|tuple) – A list or tuple with two elements indicating the shape of the weight.
operation (str) – The name of the operation. The supported operations are ‘linear’ and ‘embedding’.
axis (int, Optional) – Indicate along which axis to split the weight. Default: 0.
num_partitions (int, Optional) – How many parts the weight is partitioned. Default: 1.
gather_out (bool, Optional) – Whether to gather the output after computation. By default, the output on each partitions will be gathered after computation. Default: True.
weight_attr (ParamAttr, Optional) – The parameter attribute for the learnable weights(Parameter) of the specified operation. Default: None.
bias_attr (ParamAttr, Optional) – The parameter attribute for the bias of the specified operation. Default: None.
name (str, Optional) – The default value is None. Normally there is no need for user to set this property. Default: None. For more information, please refer to Name.
- Returns
-
Tensor.
Examples
>>> >>> import paddle >>> import paddle.distributed.fleet as fleet >>> paddle.enable_static() >>> paddle.set_device(f'gpu:{paddle.distributed.ParallelEnv().dev_id}') >>> fleet.init(is_collective=True) >>> data = paddle.randint(0, 8, shape=[10,4]) >>> emb_out = paddle.distributed.split( ... data, ... (8, 8), ... operation="embedding", ... num_partitions=2)