2022年5月20日,Wave Summit 2022深度学习开发者峰会线上成功举办,飞桨深度学习开源框架2.3版本正式发布。
新版本框架在深度定制开发能力、全流程的自动化水平等方面有大幅升级,涉及开发、训练、推理部署和云上飞桨各环节。API体系更加丰富,更便捷支持包括AI科学计算在内各领域模型开发;针对高阶开发者深度定制开发需求,飞桨框架2.3版本推出高复用性算子库、高扩展性参数服务器架构,进一步降低框架深度定制开发的成本;推出业内首个全流程自动调优方案,大幅提升性能调优的自动化水平;降低模型压缩技术的应用门槛,推出业内首个开源的自动化压缩功能;深度优化端边云全场景推理引擎,支持开发者取得最佳的部署性能。同时,针对大模型技术发展和产业应用需求,飞桨框架2.3版本的大模型训练和推理能力实现全面升级。此外,为了更好地跟云计算对接,本次升级正式推出“云上飞桨”的能力,包括业内首个异构多云自适应分布式训练架构以及云上部署编排工具PaddleCloud。
飞桨框架2.3版本共包含3200+个commits,共有210+个贡献者参与开发,下面让我们看看该版本的重点更新:
大模型训练和推理能力全面升级
1
更加丰富的API体系
支持各领域模型开发
概率分布类API扩充到2.3版本的25个,新增6个基础分布、13个分布变换及2个KL散度API。
新增4个自动微分API:Jacobian、Hessian、jvp、vjp并应用到赛桨PaddleScience中,同时支持lazy模式的计算,能够在复杂偏微分方程组中避免计算无用导数项,提升计算性能。
新增11个稀疏张量API,支持创建 COO、CRS格式的Sparse Tensor,并能与Tensor互相转换,已经应用到3D检测(支持自动驾驶),图神经网络和NLP模型中。
新增2个拟牛顿法二阶优化API:minimize_bfgs和minimize_lbfgs,已应用到赛桨PaddleScience中,加快了模型收敛速度。
2
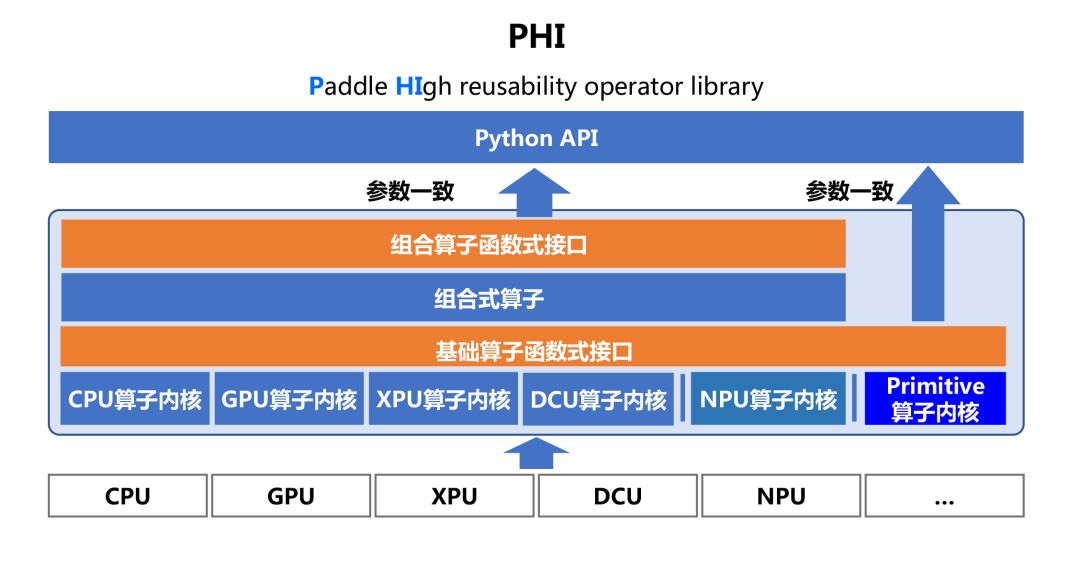
高复用性算子库PHI
降低算子开发门槛
3
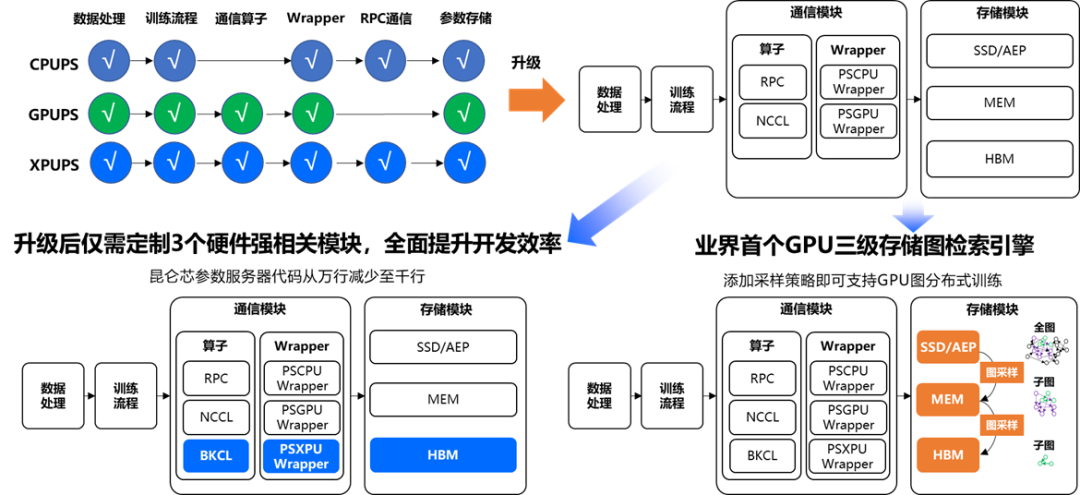
高扩展性通用异构参数服务器
提升二次开发体验
参数服务器架构在搜索推荐系统应用非常广泛。飞桨框架在2.0版本推出了业内首个通用异构参数服务器架构,在2.3版本中我们进一步提升其扩展性,主要是将其中的基础模块通用化,提升二次开发体验,高效支持产业应用中广泛的定制开发需求。
4
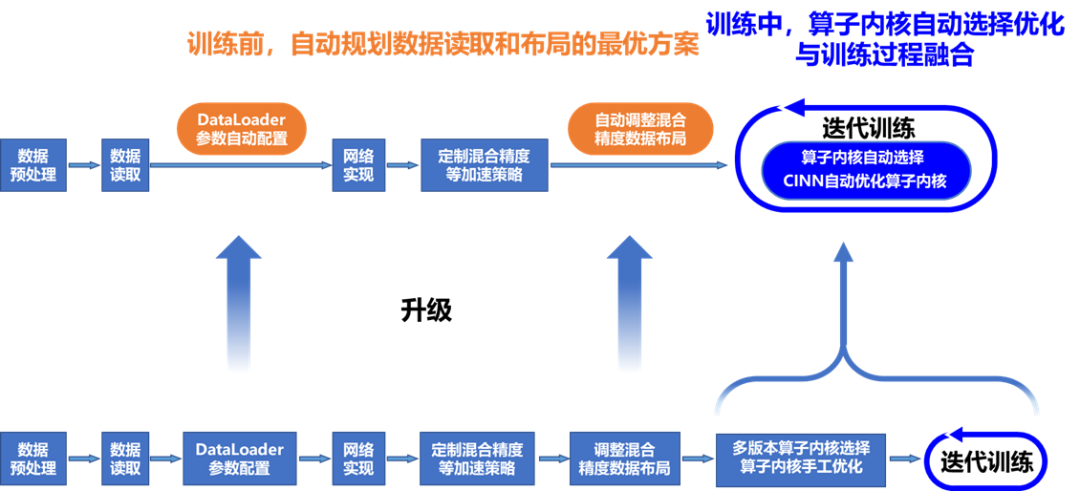
全流程硬件感知的性能自动调优
持平专家级手工优化
目前各个框架都在性能方面做了很多优化,但对开发者而言,要想充分发挥框架的极致性能,往往需要对框架以及硬件特性非常熟悉,通过调整各种配置才能实现,这对开发者的要求非常高,所以性能调优也常常成为开发者苦恼的问题。针对这一痛点,飞桨框架2.3版本大幅提升性能调优的自动化水平,推出的业内首个全流程自动调优方案,使得开发者更便捷获得框架最优性能体验。
针对不同硬件环境下默认的DataLoader参数配置无法发挥硬件最优性能的问题,飞桨实现了DataLoader参数自动搜索功能,结合硬件特性达到最优性能配置;
训练中
5
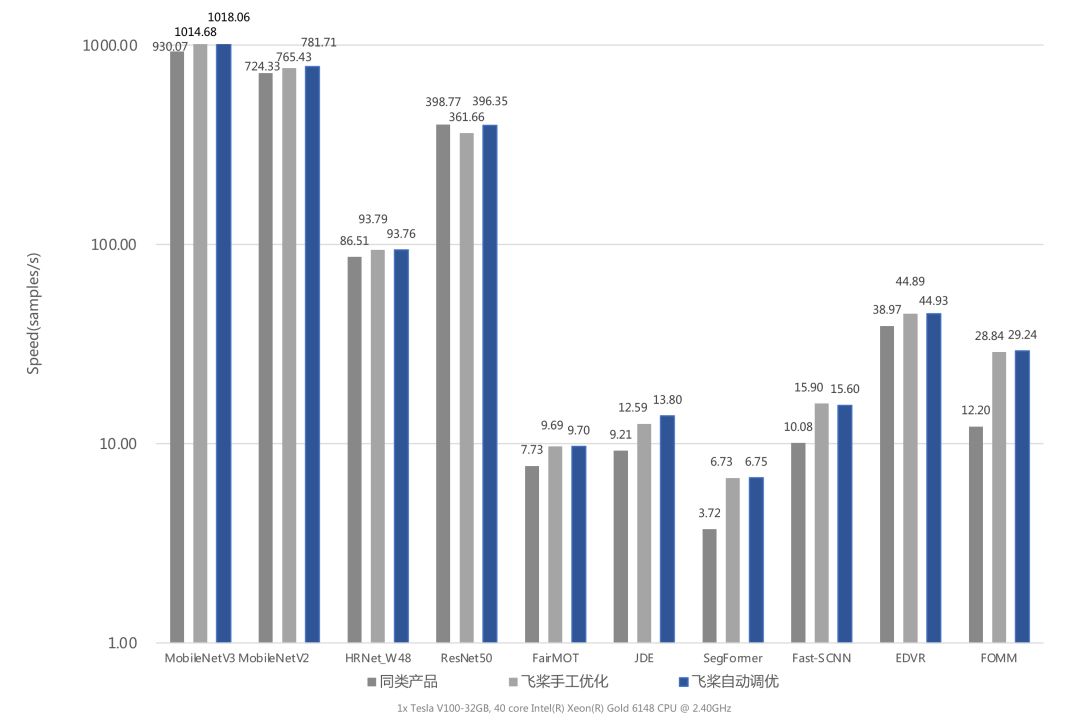
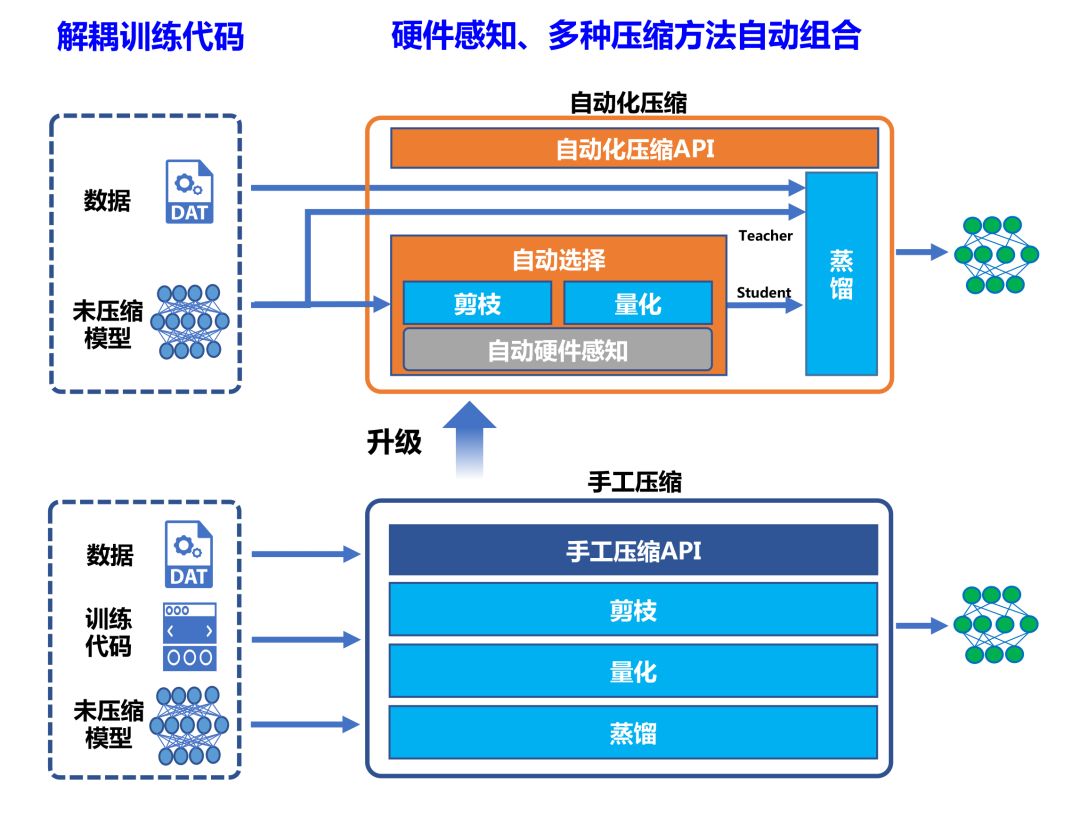
自动化压缩和推理引擎深度性能优化
高效支撑全场景部署落地
在产业落地的过程中,由于实际场景在硬件设备、推理性能等方面的约束,常常需要模型压缩的技术。然而模型压缩要想做到模型精度和推理性能的平衡,非常有挑战。以往开发者需要考虑模型训练、硬件环境等复杂因素,凭借实验从大量的压缩策略中选择适合的策略。
同时,飞桨推理引擎也在持续进行深度的性能优化,支持开发者取得最佳的部署性能。本次升级,飞桨在数据处理、计算图优化、执行调度、软硬件融合的内核调优等方面进一步进行深度优化,推理性能进一步提升。以端侧为例,在ARM CPU上,我们支持了稀疏计算功能,在高通865手机,FP32精度单线程下,稀疏度75%,相对稠密模型性能有高达30%提升,并且精度损失<1%。在边缘、云也都实现了深度优化,实现了端、边、云多平台推理性能的全面提升。
6
大模型训练和推理能力全面升级
提供训推一体全流程方案
针对MoE模型的海量稀疏参数,飞桨采用了包括HBM显存/MEM内存/AEP/SSD等在内的通用多级存储模式,实现36机即可训练十万亿模型,并采用2D预取调度和参数融合提高异构存储效率。同时针对All-to-All通信压力,研发了硬件拓扑感知层次通信,通信效率提升20%。针对MoE训练中的负载不均衡情况,提出弹性训练通过增删节点平衡负载,整体效率提升18%。此外,针对MoE大模型推理,飞桨提出Ring Memory Offloading策略,有效解决单节点大模型训练推理存储问题,减少显存碎片。
更多详情请见:
SE-MoE: A Scalable and Efficient Mixture-of-Experts Distributed Training and Inference System(https://arxiv.org/abs/2205.10034).
针对生物计算蛋白质结构分析模型存在多分支特征计算、中间计算结果较大、参数量小、参数个数较多、小算子较多等特点,飞桨提出了分支并行分布式策略提高并行效率,数千个参数、梯度、优化器变量使用张量融合策略和BF16通信策略以提高通信及参数更新效率,小算子使用算子融合策略提高计算效率等;此外,进一步支持了GPU/DCU等多种硬件环境下端到端的高扩展分布式训练。
飞桨整体推出了针对大模型的压缩、推理、服务化全流程部署方案。该方案通过面向大模型的精度无损模型压缩技术、自适应分布式推理技术,可自动感知硬件特性,完成模型压缩、自动切分和混合并行推理计算,可比模型测试达到领先性能。并且,整体方案通用且可扩展,能广泛支持不同种类的模型结构高速推理,目前已支撑了如自然语言理解、对话、跨模态生成等大模型的实时在线应用。
7
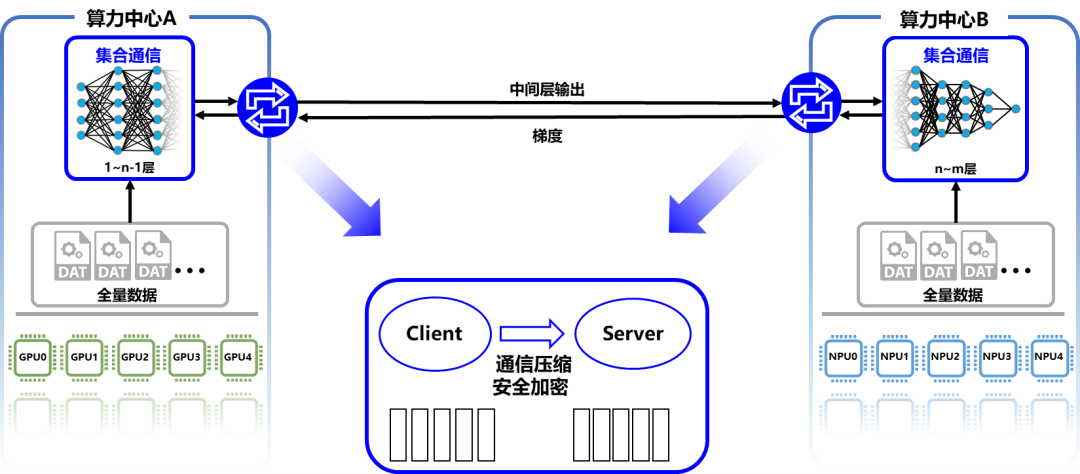
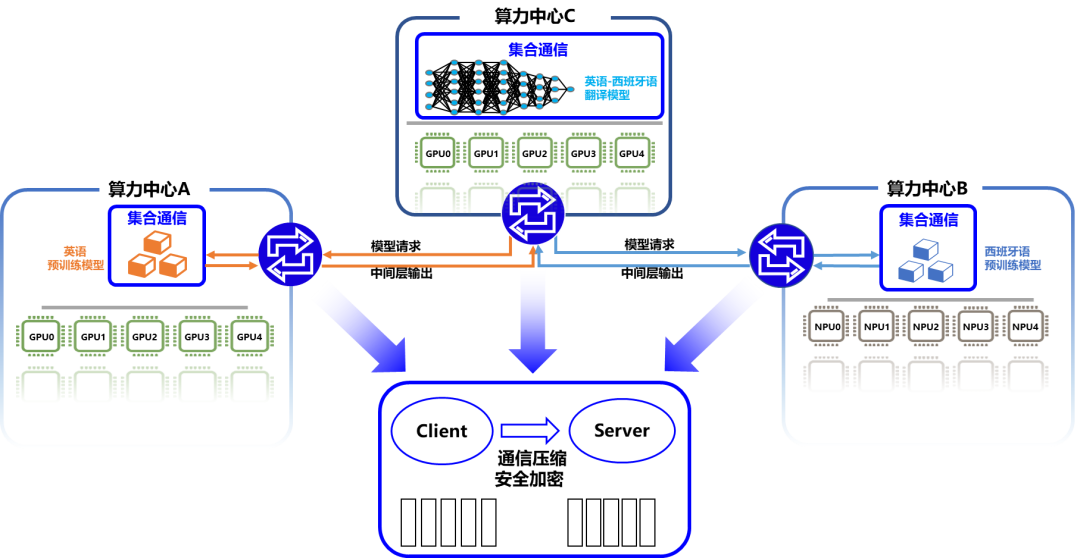
异构多云自适应分布式训练
实现算力和模型共享
更多详情请见:
Nebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters(https://arxiv.org/abs/2205.09470).
7
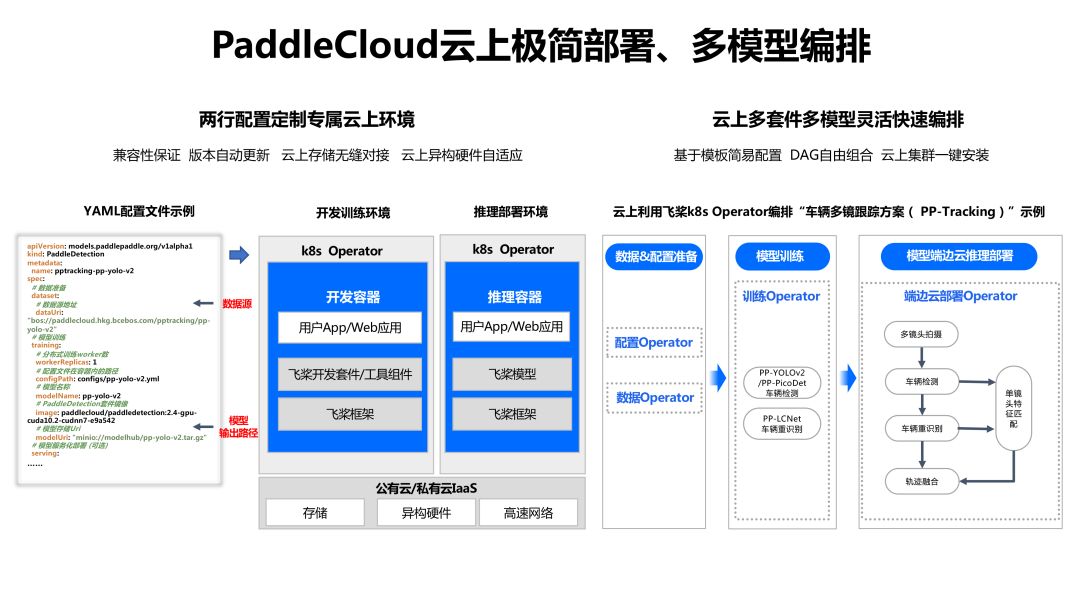
云上飞桨编排部署工具PaddleCloud
支持极简安装与多模型编排
相关阅读

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~