项目难点:
如何从零标注电表数据,选择何种标注软件能够最快速度构建数据集?
技术路线的选择也面临多方面的问题,例如是通过文字检测来反向微调,还是通过目标检测从零训练?
项目方案:
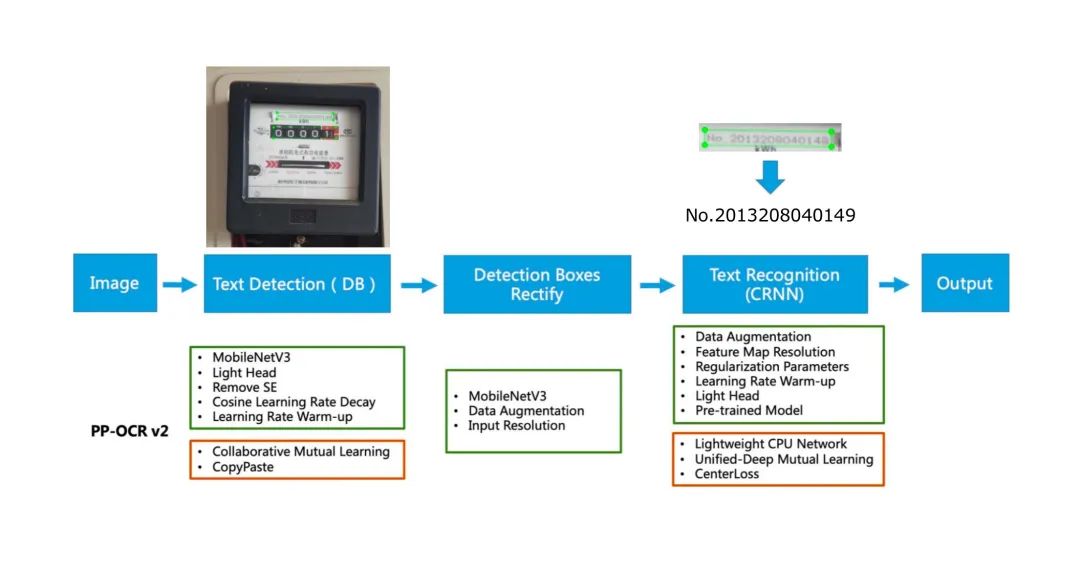
基于上述难点,飞桨开发者技术专家不断进行尝试,最终选用了飞桨文字识别套件PaddleOCR中的PP-OCR模型进行了微调与优化,其检测部分基于DB的分割方法实现,直接解决了电表数据中的倾斜问题,通过再造数据集来扩充识别数据集,训练识别模型。PP-OCR模型经过大量实验,其泛化性也足以支撑复杂垂类场景下的效果。
方案优化:
在优化方面,首先对PP-OCR模型的检测部分进行初步微调,然后通过对数据的进一步分析,发现原始图像分辨率较大,进而调整EastRandomCropData的尺寸,放大输入模型前的图像尺度。通过CopyPaste数据增强解决数据量小的问题,并且根据实际情况调小学习率。
项目效果:
最终在评测数据集上从原先的Hmeans=0.3优化到0.85。除此之外,本项目也尝试了一部分目标检测算法。具体的优化过程和详细解释,欢迎大家关注直播!
产业实践范例教程
助力企业跨越AI落地鸿沟
真实产业场景:与实际具有AI应用的企业合作共建,选取企业高频需求的AI应用场景如智慧城市-安全帽检测、智能制造-表计读数等;
完整代码实现:提供可一键运行的代码,在“AI Studio一站式开发平台”上使用免费算力一键Notebook运行;
详细过程解析:深度解析从数据准备和处理、模型选择、模型优化和部署的AI落地全流程,共享可复用的模型调参和优化经验;
直达项目落地:百度高工手把手教用户进行全流程代码实践,轻松直达项目POC阶段。
精彩课程预告