Graphcore在2016年成立于英国,其智能处理器(IPU)硬件和Poplar软件帮助创新者在机器智能方面实现了新突破。IPU是第一个专为机器智能设计的处理器,与通常用于人工智能的其他计算硬件相比,具有显著的性能优势。

如何开始
(How to get started)
环境准备
通过源码编译安装
(1)下载源码
git clone -b paddle_bert_release https://github.com/graphcore/Paddle.git
docker build -t paddlepaddle/paddle:dev-ipu-2.3.0 \
-f tools/dockerfile/Dockerfile.ipu .
# 例:生成POD16(16个IPU)配置文件:
vipu create partition ipu --size 16
ipu.conf将会生成在以下路径:
ls ~/.ipuof.conf.d/
docker run --ulimit memlock=-1:-1 --net=host --cap-add=IPC_LOCK \
--device=/dev/infiniband/ --ipc=host --name paddle-ipu-dev \
-v ${HOST_IPUOF_PATH}:/ipuof \
-e IPUOF_CONFIG_PATH=/ipuof/ipu.conf \
-it paddlepaddle/paddle:dev-ipu-2.3.0 bash
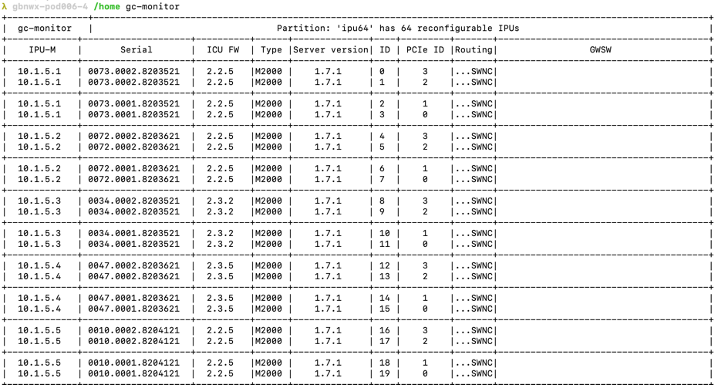
gc-monitor
git clone -b paddle_bert_release https://github.com/graphcore/Paddle.git
cd Paddle
cmake -DPYTHON_EXECUTABLE=/usr/bin/python \
-DWITH_PYTHON=ON -DWITH_IPU=ON -DPOPLAR_DIR=/opt/poplar \
-DPOPART_DIR=/opt/popart -G "Unix Makefiles" -H`pwd` -B`pwd`/build
cmake --build \`pwd`/build --config Release --target paddle_python -j$(nproc)
pip install -U build/python/dist/paddlepaddle-0.0.0-cp37-cp37m-linux_x86_64.whl
python -c "import paddle; print(paddle.fluid.is_compiled_with_ipu())"
> True
BERT-Base 训练体验
- phase1: sequence_length=128预训练
- phase2: sequence_length=384预训练
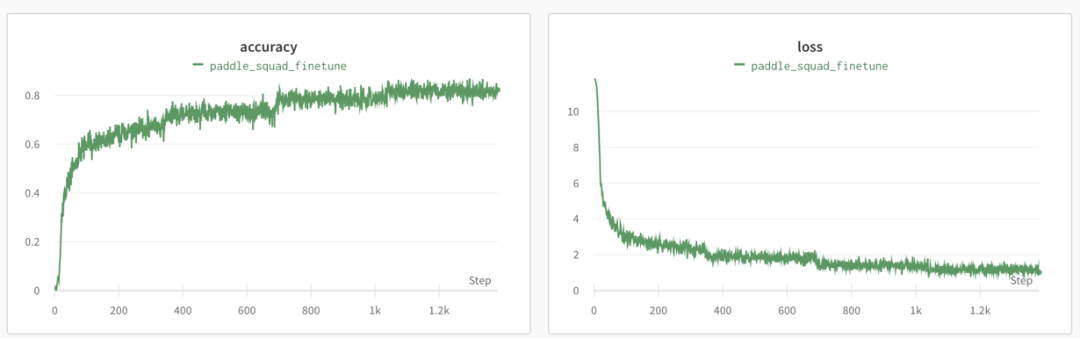
- SQuAD fine-tune
- SQuAD validation
数据准备
cd data/
vim create_datasets_from_start.sh
cd ../
bash scripts/data_download.sh wiki_only
curl --create-dirs -L https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json -o data/squad/train-v1.1.json
curl --create-dirs -L https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json -o data/squad/dev-v1.1.json
PaddleNLP环境准备
pip3.7 install jieba h5py colorlog colorama seqeval multiprocess numpy==1.19.2 paddlefsl==1.0.0 six==1.13.0 wandb
pip3.7 install torch==1.7.0+cpu -f https://download.pytorch.org/whl/cpu/torch_stable.html
pip3.7 install torch-xla@https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.7-cp37-cp37m-linux_x86_64.whl
pip3.7 install git+https://github.com/graphcore/PaddleNLP.git@paddle_bert_release
开始训练
./run_stage.sh ipu phase1 _ pretrained_128_model
./run_stage.sh ipu phase2 pretrained_128_model pretrained_384_model
./run_stage.sh ipu SQuAD pretrained_384_model finetune_model
./run_stage.sh ipu validation finetune_model _
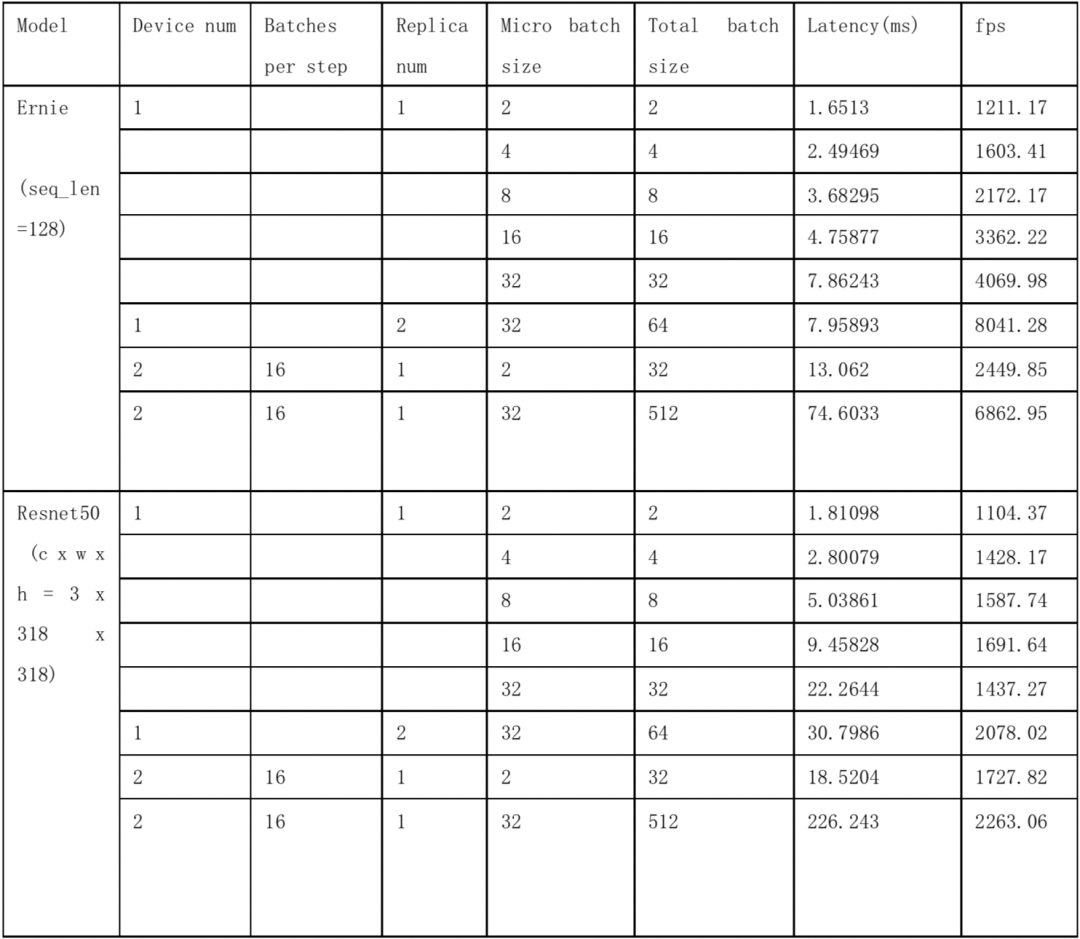
BERT-Base
精度与性能
目前Graphcore的IPU支持通过飞桨框架做大规模的模型训练任务,也支持通过Paddle Inference库执行高性能的推理任务。
BERT训练 (BERT trainning)
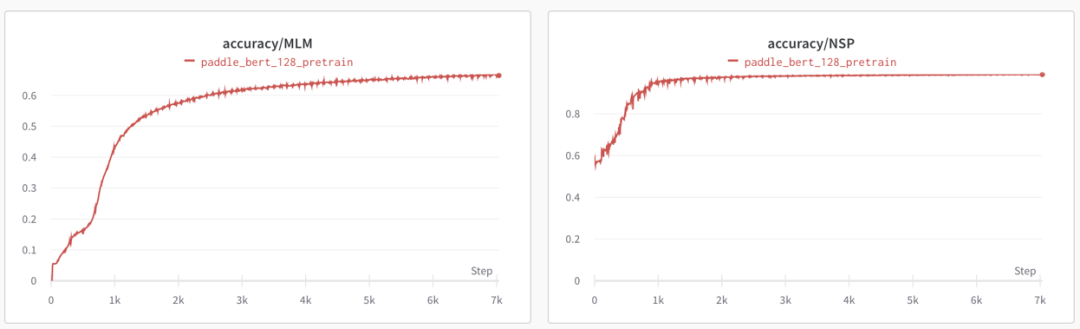
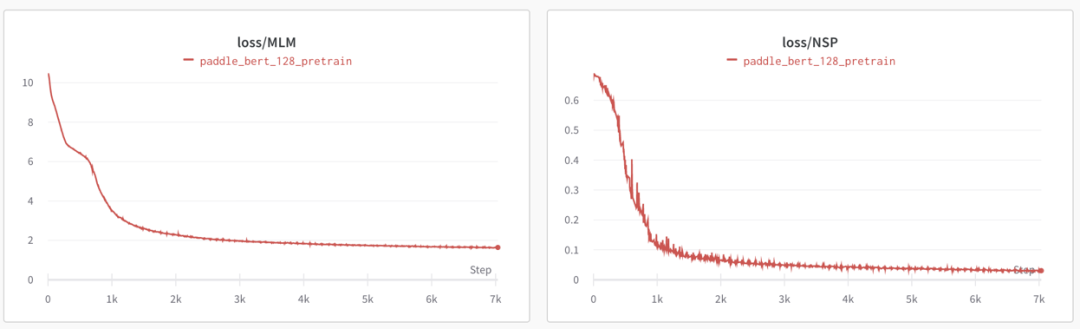
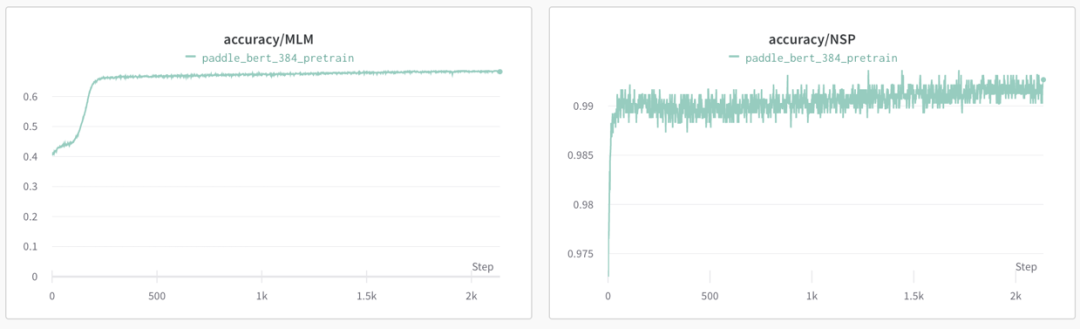
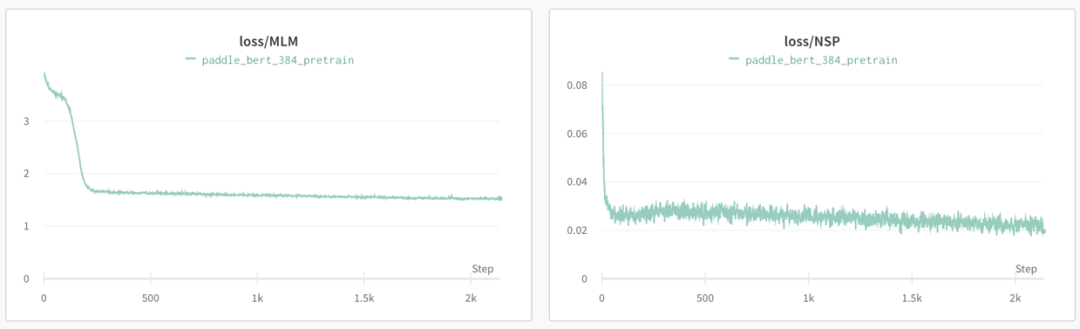
Pretrain Phase1 (sequence_length=128):
Paddle Inference 推理 (FP16)
word2vec推理演示
生成Paddle Inference原生推理库
cmake -DPYTHON_EXECUTABLE=/usr/bin/python \
-DWITH_PYTHON=ON –DON_INFER=ON -DWITH_IPU=ON -DPOPLAR_DIR=/opt/poplar \
-DPOPART_DIR=/opt/popart -G "Unix Makefiles" -H`pwd` -B`pwd`/build
cmake --build \`pwd`/build --config Release --target paddle_python -j$(nproc)

wget -q http://paddle-inference-dist.bj.bcebos.com/word2vec.Inference.model.tar.gz
编写Paddle Inference推理代码
#include <iostream>
#include <vector>
#include <numeric>
#include <string>
#include "paddle/fluid/inference/api/paddle_inference_api.h"
#include "gflags/gflags.h"
#include "glog/logging.h"
DEFINE_string(infer_model, "", "Directory of the inference model.");
using paddle_infer::Config;
using paddle_infer::Predictor;
using paddle_infer::CreatePredictor;
void inference(std::string model_path, bool use_ipu, std::vector<float> *out_data) {
//# 1. Create Predictor with a config.
Config config;
config.SetModel(FLAGS_infer_model);
if (use_ipu) {
// ipu_device_num, ipu_micro_batch_size
config.EnableIpu(1, 4);
}
auto predictor = CreatePredictor(config);
//# 2. Prepare input/output tensor.
auto input_names = predictor->GetInputNames();
std::vector<int64_t> data{1, 2, 3, 4};
// For simplicity, we set all the slots with the same data.
for (auto input_name : input_names) {
auto input_tensor = predictor->GetInputHandle(input_name);
input_tensor->Reshape({4, 1});
input_tensor->CopyFromCpu(data.data());
}
//# 3. Run
predictor->Run();
//# 4. Get output.
auto output_names = predictor->GetOutputNames();
auto output_tensor = predictor->GetOutputHandle(output_names[0]);
std::vector<int> output_shape = output_tensor->shape();
int out_num = std::accumulate(output_shape.begin(), output_shape.end(), 1,
std::multiplies<int>());
out_data->resize(out_num);
output_tensor->CopyToCpu(out_data->data());
}
int main(int argc, char *argv[]) {
::GFLAGS_NAMESPACE::ParseCommandLineFlags(&argc, &argv, true);
std::vector<float> ipu_result;
std::vector<float> cpu_result;
inference(FLAGS_infer_model, true, &ipu_result);
inference(FLAGS_infer_model, false, &cpu_result);
for (size_t i = 0; i < ipu_result.size(); i++) {
CHECK_NEAR(ipu_result[i], cpu_result[i], 1e-6);
}
LOG(INFO) << "Finished";
}
编译生成推理Demo程序
编译方法:
CMakeList.txt:
cmake_minimum_required(VERSION 3.0)
project(cpp_inference_demo CXX C)
include_directories("${PADDLE_LIB}/")
set(PADDLE_LIB_THIRD_PARTY_PATH "${PADDLE_LIB}/third_party/install/")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}protobuf/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}glog/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}gflags/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}xxhash/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}cryptopp/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}mkldnn/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}mklml/include")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}protobuf/lib")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}glog/lib")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}gflags/lib")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}xxhash/lib")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}cryptopp/lib")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}ipu")
link_directories("/opt/poplar/lib")
link_directories("/opt/popart/lib")
link_directories("${PADDLE_LIB}/paddle/lib")
set(EXTERNAL_LIB "-lrt -ldl -lpthread")
set(DEPS ${DEPS}
${PADDLE_LIB_THIRD_PARTY_PATH}mkldnn/lib/libdnnl.so.2
${PADDLE_LIB_THIRD_PARTY_PATH}mklml/lib/libiomp5.so
paddle_inference paddle_ipu flags
glog gflags protobuf xxhash cryptopp
${EXTERNAL_LIB})
set(CMAKE_CXX_FLAGS "-std=c++11")
add_executable(${DEMO_NAME} ${DEMO_NAME}.cc)
target_link_libraries(${DEMO_NAME} ${DEPS})
#!/bin/bash
mkdir -p build
cd build
rm -rf *
DEMO_NAME=ipu_word2vec_sample
LIB_DIR=${PADDLE_INFERENCE_INSTALL_DIR}
cmake .. -DPADDLE_LIB=${LIB_DIR} -DDEMO_NAME=${DEMO_NAME}
make –j
./compile.sh
./ipu_word2vec_sample –-infer_model=word2vec.inference.model
其他Demo体验
MNIST demo

关注公众号,获取更多技术内容~