爷青回!AI把《灌篮高手》角色真人化,最帅的居然不是流川枫?
最近,一位外国博主AIみかん搞了个事情,更是让网友们掀起了一波超强回忆杀:
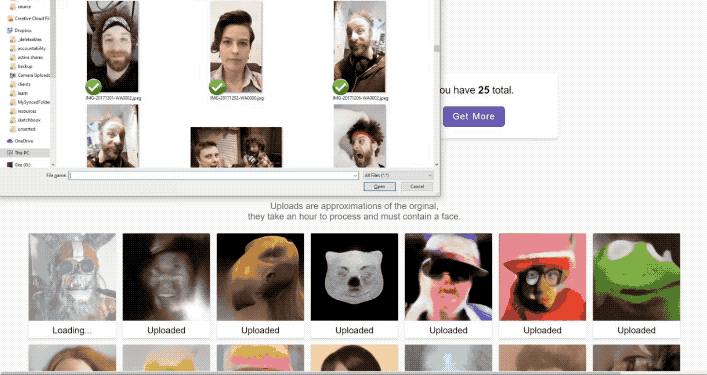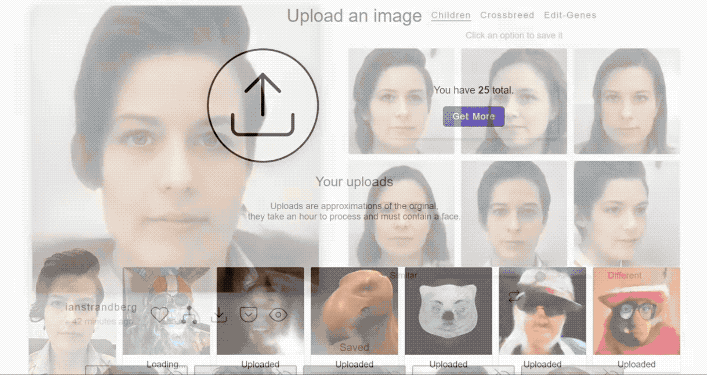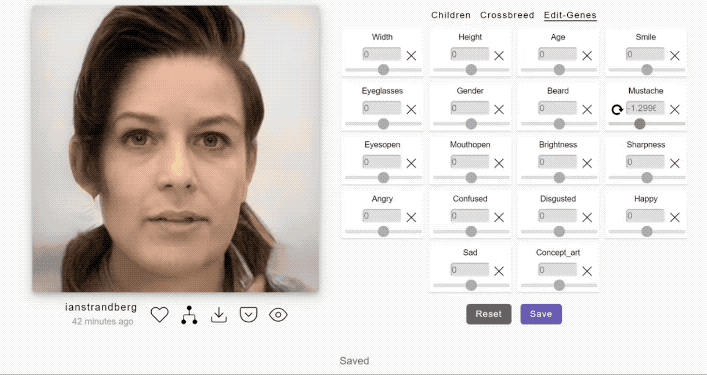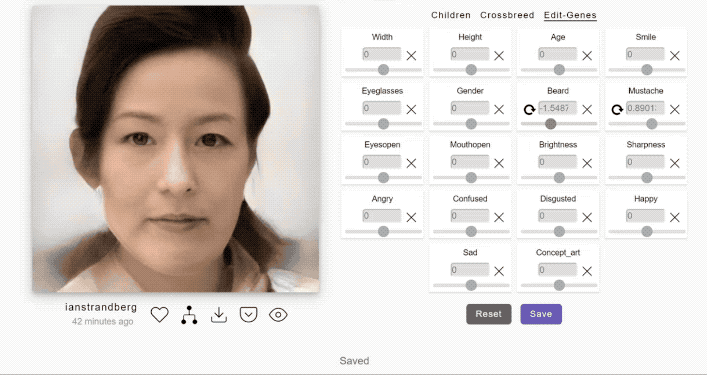
例如我们熟悉的主角樱木花道,在AI的一通操作后,他的真人版长这样:
博主AIみかん在自己主页中,对此次的作品做了详细介绍:
在这个频道中,我想看看用机器学习的方法,在多大程度上能够还原动漫中的人物,并进行比较。
具体而言,他所采用的方法叫做 Artbreeder。
Artbreeder其实是一个基于生成对抗网络(GAN)技术的在线图像生成网站。
GAN这项技术大家都已经非常熟悉了,自2014年被AI大牛lan Goodfellow提出后,便在机器学习界名声大噪,还衍生出了各种各样的新“玩法”。
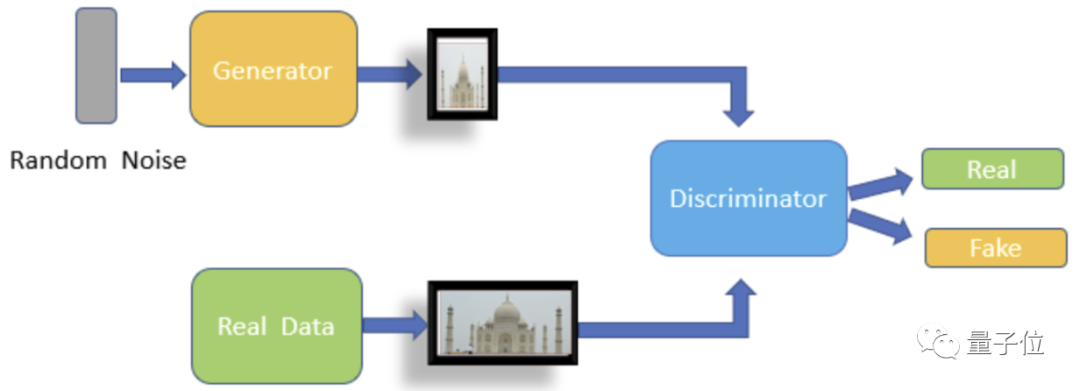
简单来说,它主要包含了生成器(Generator)和判别器(Descriminator)。
生成器的输入是一组随机的变量,输出是生成的图;判别器则负责对生成的图进行打分。
生成器所做的工作,是希望生成的图像无限逼近于真实图像;而判别器的想法却不同,它总是想把生成图像和真实图像区分开。
而Artbreeder这个网站,就是采用GAN技术来生成新图像。
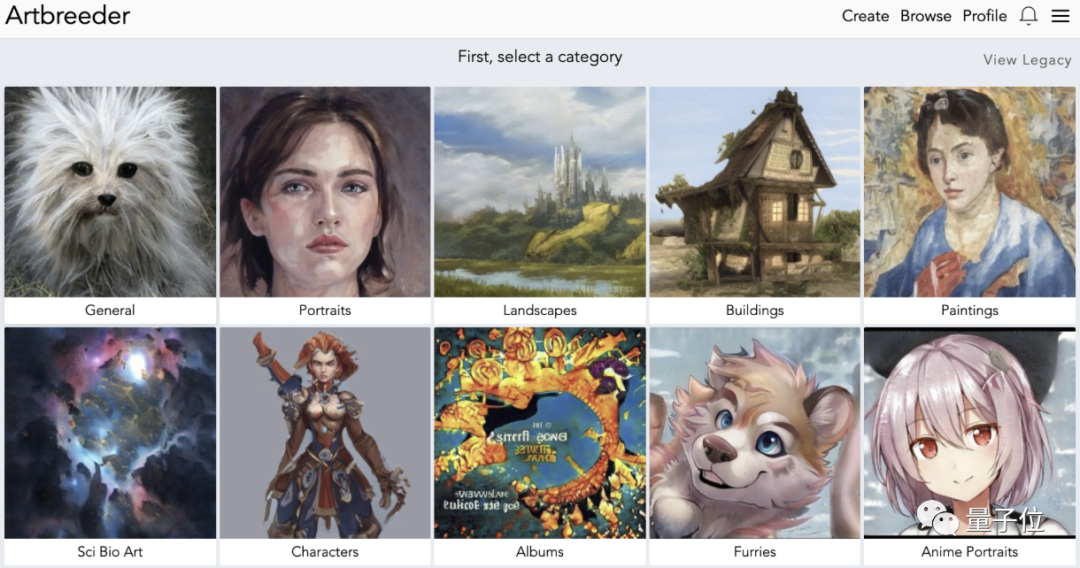
在网站中点击创作(Create)后,便可以看到它提供了10种类型的图像生成,包括肖像、动漫人物、风景、建筑等等。
然后你就可以通过调整滑块,来“捏”不同风格的人像、动画。
毕竟Artbreeder这个网站操作简单,而且还免费。
IJCAI 2021开幕:程序主席周志华揭晓热门研究主题,杰出论文等奖项出炉
北京时间 8 月 23 日晚,人工智能领域的学术顶会 IJCAI 2021 在线上开幕。
本次共有 3 篇论文获得 IJCAI 2021 杰出论文奖,1 篇论文获得荣誉提名。
论文 1:Learning Generalized Unsolvability Heuristics for Classical Planning
作者:Simon Ståhlberg (Linköping University), Guillem Francès (Universitat Pompeu Fabra), Jendrik Seipp (Linköping University)

论文链接:https://www.ijcai.org/proceedings/2021/0574.pdf
论文摘要:近来经典规划方面的研究提出了一些专用方法来检测无法解决的状态,即无法达到目标状态的状态。在本篇获奖论文中,研究者从广义规划的角度处理问题,并学习描述整个规划领域不可解性的一阶公式。此外,该研究还展示了如何将这个问题转换为一个自监督分类任务。
训练数据是通过对每个域的小实例进行详尽的探索而自动生成和标记的,候选特征是根据用于定义域的判断自动计算出来的。研究者研究了三种具有不同属性的学习算法,并将它们与文献中的启发式算法进行比较。实验结果表明,所提方法能够捕获重要的不可解状态类别,并具有较高的分类准确率。此外,启发式的逻辑形式使它们易于解释和推理,并且可以用来展示在某些域中学得的特征,可以精确地捕获域的所有不可解状态。
论文 2:On the Relation Between Approximation Fixpoint Theory and Justification Theory
作者:Simon Marynissen (KU Leuven), Bart Bogaerts (Vrije Universiteit Brussel), Marc Denecker (KU Leuven)

论文链接:https://www.ijcai.org/proceedings/2021/0272.pdf
论文摘要:AFT(Approximation Fixpoint Theory )和 JT(Justification Theory )是两个统一逻辑形式的框架。AFT 用 lattice 算子的不动点来研究语义,JT 则解释了为什么某些事实在模型中成立或不成立。虽然方法不同,但这两种框架在设计时考虑了类似的目标,即研究非单调逻辑中出现的不同语义。本篇获奖论文的第一个贡献是在这两个框架之间提供了一个正式的联系。准确地说,该研究表明每个 justification 框架都引入了一个近似器,并且这种从 JT 到 AFT 的映射保留了所有的主要语义。第二个贡献是利用这种对应关系用一类新的语义来扩展 JT,即终极语义(ultimate semantic):终极语义可以通过 justification 框架上的句法转换在 JT 中获得,本质上是对规则执行某种解析。
论文 3:Keep Your Distance: Land Division With Separation
作者:Edith Elkind (University of Oxford), Erel Segal-Halevi (Ariel University), Warut Suksompong (National University of Singapore)

论文链接:https://arxiv.org/pdf/2105.06669.pdf
论文摘要:该研究通过处理现实生活中的应用需求,让公平划分理论更接近于实际。该研究关注土地分割的两个需求:(1)每个代理人都应该获得一个可用几何形状的地块;(2)不同代理人的地块必须在物理上分开。有了这两点要求,按比例划分的经典公平概念是不切实际的,因为可能无法对其进行乘法近似。相比之下,Budish 在 2011 年提出的序数最大值共享近似(the ordinal maximin share approximation)提供了更有意义的公平保证。当可用形状为正方形、宽矩形或任意轴对齐矩形时,本篇获奖论文证明了可实现的最大共享保证的上限和下限,并探索了在此设置下找到公平划分的算法和查询复杂性。
论文:Actively Learning Concepts and Conjunctive Queries under ELdr-Ontologies
作者:Maurice Funk (University of Bremen), Jean Christoph Jung (University of Hildesheim), Carsten Lutz (University of Bremen)
论文地址:https://arxiv.org/pdf/2105.08326.pdf
业界首个高性能交互式自动标注工具——EISeg正式开源!
在人工智能行业有这么一句话:“深度学习有多智能、背后就有多少人工”。这句话直接说出了深度学习从业者心中的痛处,毕竟模型的好坏数据占着很大的因素,但是数据的标注成本却让很多从业者感到头疼。在标注中,矩形框标注还相对简单,但是对于像素级别的分割标注,往往需要大量的点将目标轮廓抠出来,这需要大量的时间和人力成本去完成。
近期PaddleSeg团队发布了业界首个高性能的交互式分割自动标注工具—EISeg,什么是交互式分割呢?它其实就是先用预训练模型对图像进行预标注,对于标注不精准、有误差的地方,再通过一系列绿色点(正点)和红色点(负点)对目标对象边缘进行精准的调整,从而实现精细化标注,高效而实用。

详细的产品体验链接,请参考:
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.2/contrib/EISeg

当然大家会好奇,交互式分割算法是怎么实现的?在这里和大家介绍一下:
交互式分割以用户的标注作为指导信息,根据用户的需求选取所需的前景或物体区域,并通过多次交互的方式得到灵活的标注结果,为图片标注提供了一种半自动化标注策略,与语义分割相比,交互式分割不仅仅需要传入图片和标签,还需要输入交互信息来进行训练。
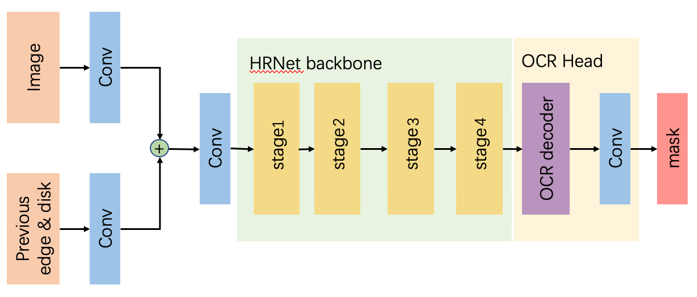
为了给大家带来更好的标注体验,开发团队在多个模型上不断尝试如何获取高精度的标注结果。经过大量测试发现,HRNet+OCRNet模型结构能够更好的将交互点击信息传入到深层的特征中,并且保留分割结果的细节信息,从而使模型对交互信息的反应更精确、更灵活。值得一提的是:为了同时保证模型的高精度和轻量化,EISeg的交互式分割算法采用HRNet18和NRNet18-Small两种Backbone,而OCRNet的通道也可以进行不同数量的配置,得到计算量大小不同的模型,更好的满足用户不同场景的需求。
深度学习精确预测RNA,仅需训练18种已知结构:斯坦福研究登上Science封面
目前,使用人工智能预测化合物分子结构是一个火热的研究课题,DeepMind 蛋白质结构预测工具 AlphaFold2 证明了这一点。但应看到,实现分子结构准确预测的背后需要庞大的数据集。斯坦福大学的一项研究打破了这一限制,他们提出的机器学习方法仅使用很少的数据即实现了准确的 RNA 结构预测。
确定生物分子的 3D 形状是现代生物学和医学发现中最困难的问题之一。许多公司和研究机构花费数百万美元来确定分子结构,却也常常无果。
来自斯坦福大学的研究团队利用机器学习的方法解决了这个难题。在计算机科学系副教授 Ron Dror 的指导下,斯坦福大学博士生 Stephan Eismann 和 Raphael Townshend 巧妙地使用机器学习技术开发了一种通过计算预测生物分子准确结构的方法。并且即使仅从少数已知结构中学习,他们的方法也能成功,使其适用于结构最难通过实验确定的分子类型。
8 月 27 日,该团队与斯坦福大学生物化学系副教授 Rhiju Das 合作的研究论文在《Science》上发表并登上封面。

论文地址:http://science.sciencemag.org/content/373/6558/1047
在此之前,去年 12 月该团队的一篇研究论文已经登上了生物医学期刊《Proteins》。

论文地址:https://onlinelibrary.wiley.com/doi/10.1002/prot.26033
在《Proteins》的论文中,研究团队介绍说:该研究建立的神经网络架构从包含数万个原子的分子结构中进行端到端的学习,其中涉及基于点的原子表示、旋转和平移的等变性、局部卷积和分层子采样操作。
两篇论文的主要作者 Townshend 说:「结构生物学是对分子形状的研究,结构决定功能。」该团队设计的算法不仅可以预测准确的分子结构,还能够解释不同分子的工作原理,该方法将适用于基础生物学研究、药物研发等。具体来讲,团队成员 Eismann 以蛋白质举例说明:「蛋白质是执行各种功能的分子机器。为了执行它们的功能,蛋白质通常会与其他蛋白质结合。如果已知一对蛋白质与疾病有关,并且知道它们在三维条件下如何相互作用,医学上就可以尝试用一种药物非常具体地针对这种相互作用。」
该研究的方法已经在蛋白质复合物和 RNA 分子方面取得了成功。正如研究团队成员 Dror 所说:「机器学习近来取得的大多数进展都需要大量数据进行训练。而该研究的方法在训练数据很少的情况下取得成功的事实意味着:相关方法可以解决许多数据稀缺的领域中未解决的问题」,因此该方法可能具有巨大潜力。
不能兼顾速度与精度,利物浦大学、牛津大学揭示梯度下降复杂度理论,获STOC 2021最佳论文
梯度下降算法具有广泛的用途,但是关于它的计算复杂度的理论研究却非常少。最近,来自利物浦大学、牛津大学的研究者从数学的角度证明了梯度下降的计算复杂度,这项研究也入选 STOC 2021 的最佳论文奖 。
当前应用研究的很多方面都依赖于一种名为梯度下降的算法。这是一个求解某个数学函数最大 / 最小值的过程(函数优化),从计算产品的最佳生产方式,到工人轮班的最佳安排方法,这一算法都能派上用场。

尽管梯度下降算法具有广泛的用途,但是关于它计算复杂度的理论研究却非常少。现在,来自利物浦大学、牛津大学等机构的研究者在论文《 The Complexity of Gradient Descent: CLS = PPAD ∩ PLS 》中给出了答案,梯度下降从本质上解决了一个非常困难的计算问题。这篇文章也入选了 STOC 2021 的最佳论文。

论文地址:https://arxiv.org/pdf/2011.01929.pdf
本文作者由牛津大学的 Paul Goldberg 、Alexandros Hollender 与利物浦大学的 John Fearnley 、 Rahul Savani 共同撰写。
更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
点击阅读原文,欢迎在飞桨论坛讨论交流~~